提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
模拟string函数的实现
浅拷贝
深拷贝
vs和g++下string结构的说明
总结
前言
模拟string函数的实现
浅拷贝
深拷贝
总结
前言
世上有两种耀眼的光芒,一种是正在升起的太阳,一种是正在努力学习编程的你!一个爱学编程的人。各位看官,我衷心的希望这篇博客能对你们有所帮助,同时也希望各位看官能对我的文章给与点评,希望我们能够携手共同促进进步,在编程的道路上越走越远!
提示:以下是本篇文章正文内容,下面案例可供参考
模拟string函数的实现
string.h#pragma once
#include <assert.h>
//string其实就是一个字符顺序表,唯一的区别就是在有效字符后面加了一个\0
namespace bit
{class string{public:typedef char* iterator;//把类型重命名成iterator,然后让类域隔开typedef const char* const_iterator;//const_iterator其实就是const char*const_iterator begin() const{return _str;}const_iterator end() const//const修饰的是this{return _str + _size;}//函数的类型是无法支持函数的重载iterator begin(){return _str;//返回的是字符串第一个字符的下标}iterator end(){return _str + _size;//返回的是'\0'的下标}//无参的构造函数//string()// :_str(nullptr)//不能给str空指针,怕返回空指针// //如果给str赋值 nullptr,采用c语言的接口,返回的字符串是空指针,打印空指针会报错的// ,_size(0)// ,_capacity(0)//{}//c++兼容c,我们要用c语言的接口:返回字符串const char* c_str() const{return _str;}所以,我们要给str开一个空间,并赋值'\0',返回字符的地址,这是可以的//string()// :_str(new char[1])// , _size(0)// , _capacity(0)//{// _str[0] = '\0';//}//带参的构造函数/*string(const char* str)//strlen:遍历字符串,遇到 \0 就停止,不易多调用:_size(strlen(str)),_str(new char[strlen(str)+1]),_capacity(strlen(str))//capacity:不包含 \0 {strcpy(_str, str);}*///以上的无参和带参的构造函数合二为一:全缺省的构造函数(即可传参,也可不传传参)//第一种情况://string(const char* str = nullptr)//如果传的是无参,strlen(str):遍历字符串时,会对指针指向的内容解引用,str指向的是空指针//第二种情况://string(const char* str = '\0')//也不能给str赋值 '\0',左右两边的类型要匹配;右边类型:char 左边类型:const char*//第三种情况://string(const char* str = "\0")//字符串是"\0",但是结束时,还会再加一个 \0//第四种情况:string(const char* str = "")//缺省值给一个空字符串:_size(strlen(str)){_capacity = _size;//capacity:存有效的字符空间,有效的字符是0个,但是还开了一个空间,用来存\0 _str = new char[_capacity + 1];strcpy(_str, str);}size_t capacity() const{return _capacity;}//遍历size_t size() const{return _size;//返回有效字符串的个数}//函数的声明和定义在一块,本质就相当于是内联char& operator[](size_t pos){assert(pos < _size);return _str[pos];//这些数据在堆区上,出来作用域也不会销毁,可以返回别名}//函数重载,上面的和下面的各用各的const char& operator[](size_t pos) const{//只能获取pos位置的字符,但是不能修改assert(pos < _size);return _str[pos];//这些数据在堆区上,出来作用域也不会销毁,可以返回别名}//s2(s1):深拷贝(拷贝构造函数)string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}//s2(s1)string(const string& s){string tmp(s._str);swap(tmp);}//赋值运算符重载(s1 = s3):也会出现浅拷贝的问题string& operator=(const string& s){char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;//把s1原来空间释放掉_str = tmp;_size = s._size;_capacity = s._capacity;return *this;}//析构函数~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}void resize(size_t n, char ch = '\0')//半缺省函数,有实参会替换缺省值{//保留前n个数据if (n <= _size){_str[n] = '\0';_size = n;}else{reserve(n);//n > capacity,就扩容for (size_t i = _size; i < n; i++){_str[i] = ch;}_str[n] = '\0';_size = n;}}void reserve(size_t n){if (n > _capacity){//手动扩容char* tmp = new char[n + 1];//开空间永远要多开一个,多开的一个是给'\0'准备的strcpy(tmp, _str);//拷贝数据delete[] _str;//释放旧空间_str = tmp;//指针指向新空间_capacity = n;}}void push_back(char ch){// 扩容2倍/*if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}_str[_size] = ch;++_size;_str[_size] = '\0';*/insert(_size, ch);//复用insert()函数}void append(const char* str){// 扩容//size_t len = strlen(str);//if (_size + len > _capacity)//{// //_size:当前字符串的长度;len:插入的字符串的长度;'\0'会单独开空间存放// reserve(_size + len);//}insert(_size, str);//复用insert()函数}string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* str){append(str);return *this;}void insert(size_t pos, char ch){assert(pos <= _size);// 扩容2倍if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}//挪动数据方法一:/*int end = _size;//while (end >= pos)//end:有符号;pos:无符号;有符号会向无符号提升while (end >= (int)pos)//这里的循环是把包括pos位置和end位置之间的数据往后挪动{//如果一个运算符两边的操作数的类型不同的时候,会发生类型提升(范围小的向范围大的提升)_str[end + 1] = _str[end];--end;}*//*_str[pos] = ch;++_size;*///挪动数据方法二:size_t end = _size + 1;while (end > pos){_str[end] = _str[end - 1];--end;}_str[pos] = ch;++_size;}void insert(size_t pos, const char* str){assert(pos <= _size);//pos=size--->就相当于尾插size_t len = strlen(str);if (_size + len > _capacity){// 扩容reserve(_size + len);}size_t end = _size + len;while (end > pos + len - 1){_str[end] = _str[end - len];end--;}strncpy(_str + pos, str, len);_size += len;}void erase(size_t pos, size_t len = npos){assert(pos < _size);//不用删除\0//if (len == npos || len + pos >= _size)//假如len == npos-1,npos是-1,是无符号整型的最大值,再加pos,可能会存在溢出的风险if (len == npos || len >= _size - pos){_str[pos] = '\0';_size = pos;}else{strcpy(_str + pos, _str + pos + len);_size -= len;}}void swap(string& s){// 我们已经用 using namespace std;将std命名空间域给展开了,为什么还要加 std:: 呢?// 将 std 命名空间域展开(相当于:小王家开了一个通告,说你们可以拿我家的菜),// 但是顺序还是不变的:局部域----->全局域----->命名空间域// 加 std::是为了防止 swap()函数在局部域找swap()函数的定义出处时,发生事故;// 不加 std:: 的话,swap()函数会先找到 swap(string& s)的,但是参数的类型不一样,会发生报错 std::swap(_str, s._str);//调用库里的模板,这里是交换了堆区空间的地址std::swap(_size, s._size);std::swap(_capacity, s._capacity);}//找字符size_t find(char ch, size_t pos = 0) const{assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == ch)return i;}return npos;}//找字符串size_t find(const char* sub, size_t pos = 0) const{assert(pos < _size);const char* p = strstr(_str + pos, sub);if (p){return p - _str;//指针 - 指针 == 两个指针之间的元素个数(返回的是下标)}else{return npos;}}string substr(size_t pos = 0, size_t len = npos){string sub;//if (len == npos || len >= _size-pos)if (len >= _size - pos){for (size_t i = pos; i < _size; i++){sub += _str[i];}}else{for (size_t i = pos; i < pos + len; i++){sub += _str[i];}}return sub;}//只清理空间中的数据,并不会缩容void clear(){_size = 0;_str[_size] = '\0';}private://初始化列表初始化的顺序和声明的顺序一样char* _str;size_t _size;size_t _capacity;public:static const int npos;//npos:是一个公有的静态成员变量};const int string::npos = -1;//string中的非成员函数void swap(string& x, string& y){x.swap(y);}//全局函数bool operator==(const string& s1, const string& s2){int ret = strcmp(s1.c_str(), s2.c_str());return ret == 0;}bool operator<(const string& s1, const string& s2){int ret = strcmp(s1.c_str(), s2.c_str());return ret < 0;}bool operator<=(const string& s1, const string& s2){return s1 < s2 || s1 == s2;}bool operator>(const string& s1, const string& s2){return !(s1 <= s2);}bool operator>=(const string& s1, const string& s2){return !(s1 < s2);}bool operator!=(const string& s1, const string& s2){return !(s1 == s2);}//流插入(必须是全局函数,没有访问类中的私有成员变量,所以不需要设置成友元函数)ostream& operator<<(ostream& out, const string& s){for (auto ch : s){out << ch;}return out;}//流提取(是一个覆盖)istream& operator>>(istream& in, string& s)//提取的字符放入string类型的对象中,所以不需要要用const来修饰{//s是s1和s2的别名,s对象中有s1或s2的字符串内容,流提取是一个覆盖;//此时流提取只会在字符串的尾部插入数据,所以我们要先把s对象中的数据清理掉s.clear();char ch;//in >> s[i];//不能这么写,对象s中还没有写入字符,还没有数据//in >> ch;//c++的cin和c语言的scanf是读元素的时候,是读不到空格和换行的//(他们认为空格或换行是多个元素之间的分割符,会自动把空格或换行符给忽略掉)//c语言应该用 getchar/getc;但是c++是不能用的//(因为c语言和c++的iostream流不是同一个,他们都有各自的缓存区)ch = in.get();//所以用它来取字符char buff[128];//1、在栈上开空间比在堆上开空间要快一些;2、出了函数作用域空间就销毁了,不会一直浪费空间size_t i = 0;//流插入和流提取遇到 空格或换行 就默认结束while (ch != ' ' && ch != '\n'){//buff:字符数组,一段一段往对象s中加buff[i++] = ch;// [0,126]if (i == 127){buff[127] = '\0';s += buff;//把前127个字符加入对象s中i = 0;}ch = in.get();}if (i > 0){buff[i] = '\0';s += buff;//把有效的数据个数加入对象s中}return in;}//流提取(是一个覆盖)//istream& operator>>(istream& in, string& s)//提取的字符放入string类型的对象中,所以不需要要用const来修饰//{// //s是s1和s2的别名,s对象中有s1或s2的字符串内容,流提取是一个覆盖;// //此时流提取只会在字符串的尾部插入数据,所以我们要先把s对象中的数据清理掉// s.clear();// char ch;// //in >> s[i];//不能这么写,对象s中还没有写入字符,还没有数据// //in >> ch;// //c++的cin和c语言的scanf是读元素的时候,是读不到空格和换行的// //(他们认为空格或换行是多个元素之间的分割符,会自动把空格或换行符给忽略掉)// //c语言应该用 getchar/getc;但是c++是不能用的// //(因为c语言和c++的iostream流不是同一个,他们都有各自的缓存区)// ch = in.get();//所以用它来取字符// s.reserve(128);// //流插入和流提取遇到 空格或换行 就默认结束// while (ch != '\n' && ch != ' ')// {// s += ch;// ch = in.get();// }// return in;//}//获取一行istream& getline(istream& in, string& s){s.clear();char ch;//in >> ch;ch = in.get();char buff[128];size_t i = 0;while (ch != '\n'){buff[i++] = ch;// [0,126]if (i == 127){buff[127] = '\0';s += buff; i = 0;}ch = in.get();}if (i > 0){buff[i] = '\0';s += buff;}return in;}
void test_string1(){string s1("hello world");string s2;cout << s1.c_str() << endl;cout << s2.c_str() << endl;for (size_t i = 0; i < s1.size(); i++){s1[i]++;}cout << endl;//遍历:下标+[]for (size_t i = 0; i < s1.size(); i++){//s1:既能调用const的函数,也可以调用非const的函数//s1.operator[](i)cout << s1[i] << "";}cout << endl;const string s3("xxxx");//只能调用const char& operator[](size_t pos) const这个函数for (size_t i = 0; i < s3.size(); i++){//s3[i]++;cout << s3[i] << " ";}cout << endl;数组的越界是很不好检查的://int a[10];数组的读是检查不出来的//a[10];//a[11];数组的写不一定能检查出来。因为数组的越界检查是一种抽查//a[10] = 1;}void test_string2(){string s3("hello world");//范围for是一个替换机制(会自动替换成迭代器,这个地方是写死的,迭代器中必须要有iterator、begin、end)://自动取对象s3里面的数据赋值给ch,自动迭代,自动加加for (auto ch : s3)//s3是普通对象,范围for替换成普通迭代器{cout << ch << " ";}cout << endl;//迭代器(像指针,但不一定是指针)string::iterator it3 = s3.begin();while (it3 != s3.end()){*it3 -= 1;cout << *it3 << " ";++it3;}cout << endl;const string s4("xxxx");string::const_iterator it4 = s4.begin();while (it4 != s4.end()){//*it4 += 3;cout << *it4 << " ";++it4;}cout << endl;//s4是const对象,范围for替换成const迭代器(class类中必须声明iterator、begin、end)for (auto ch : s4){cout << ch << " ";}cout << endl;}void test_string3(){string s3("hello world");s3.push_back('1');s3.push_back('2');cout << s3.c_str() << endl;s3 += 'x';s3 += "yyyyyy";cout << s3.c_str() << endl;string s1("hello world");s1.insert(11, 'x');cout << s1.c_str() << endl;s1.insert(0, 'x');cout << s1.c_str() << endl;}void test_string4(){string s1("hello world");cout << s1.c_str() << endl;s1.erase(6, 3);cout << s1.c_str() << endl;s1.erase(6, 30);cout << s1.c_str() << endl;s1.erase(3);cout << s1.c_str() << endl;string s2("hello world");cout << s2.c_str() << endl;s2.resize(5);cout << s2.c_str() << endl;s2.resize(20, 'x');cout << s2.c_str() << endl;}void test_string5(){string s1("hello world");cout << s1.c_str() << endl;//此时,这里是 浅拷贝/值拷贝;s1和s2中的_str所指向的空间是同一块,析构函数释放数据会释放两次,//并且改动数据,对两个都有影响string s2(s1);cout << s2.c_str() << endl;s1[0] = 'x';cout << s1.c_str() << endl;cout << s2.c_str() << endl;string s3("xxxxx");s1 = s3;cout << s1.c_str() << endl;cout << s3.c_str() << endl;}void test_string6(){string s1("hello world");cout << s1.c_str() << endl;s1.insert(6, "xxx");cout << s1.c_str() << endl;string s2("xxxxxxx");cout << s1.c_str() << endl;cout << s2.c_str() << endl;swap(s1, s2);//调用库里面的swap模板,代价:三次拷贝构造+一次析构(涉及到深拷贝,释放和申请空间的次数太多)s1.swap(s2);//高效的方法:交换两个堆区空间的地址,不需要多次释放和申请空间cout << s1.c_str() << endl;cout << s2.c_str() << endl;}void test_string7(){string url1("https://legacy.cplusplus.com/reference/string/string/substr/");string url2("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=65081411_1_oem_dg&wd=%E5%90%8E%E7%BC%80%20%E8%8B%B1%E6%96%87&fenlei=256&rsv_pq=0xc17a6c03003ede72&rsv_t=7f6eqaxivkivsW9Zwc41K2mIRleeNXjmiMjOgoAC0UgwLzPyVm%2FtSOeppDv%2F&rqlang=en&rsv_dl=ib&rsv_enter=1&rsv_sug3=4&rsv_sug1=3&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=1588&rsv_sug4=6786");string protocol, domain, uri;size_t i1 = url1.find(':');if (i1 != string::npos){protocol = url1.substr(0, i1 - 0);cout << protocol.c_str() << endl;}// strcharsize_t i2 = url1.find('/', i1 + 3);if (i2 != string::npos){domain = url1.substr(i1 + 3, i2 - (i1 + 3));cout << domain.c_str() << endl;uri = url1.substr(i2 + 1);cout << uri.c_str() << endl;}// strstr size_t i3 = url1.find("baidu");cout << i3 << endl;}void test_string8(){string s1("hello world");string s2("hello world");cout << (s1 == s2) << endl;cout << ("hello world" == s2) << endl;//左边是调用构造成员函数,类型是 const char*//左边不能是一个成员函数,他必须是一个对象,对象才能调用成员函数//(解释赋值运算符重载为什么是全局函数,如果是成员函数的话,第一个参数是 this,是对象的地址)cout << (s1 == "hello world") << endl;//单参数的构造函数可以支持隐式类型转换(const char*转换成string类型)cout << s1 << endl;cout << s2 << endl;//c++中的cout和cin的缓存区也不是同一个,所以cout出去的,不会影响cin进来的cin >> s1 >> s2;cout << s1 << endl;cout << s2 << endl;getline(cin, s1);cout << s1 << endl;}void test_string9(){string s1;cin >> s1;cout << s1.capacity() << endl;}void test_string10(){string s1("hello world");string s2(s1);cout << s1 << endl;cout << s2 << endl;}
}
test.cpp#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
#include<string>
#include"string.h"int main()
{bit::test_string1();return 0;
}//内置类型为什么支持流插入和流提取呢?
//因为库里面直接就把内置类型重载了,直接掉库里面的函数;又可以自动识别类型,是因为这些函数有互相构成了函数重载
tmp要初始化为nullptr,否则当swap交换之后,tmp指向空,出了函数的作用域之后,会调用析构函数,析构函数会对tmp局部变量销毁,如果tmp是随机值会报错,而是nullptr的话,就不会有问题。传统写法和现代写法效率基本都一样。
拷贝构造是用一个存在的对象去构造另外一个要初始化的对象,那另外一个对象是没有空间的。
赋值是两个对象都已经存在了。
栈上开空间要比堆区上开空间要快,而且成本更低。
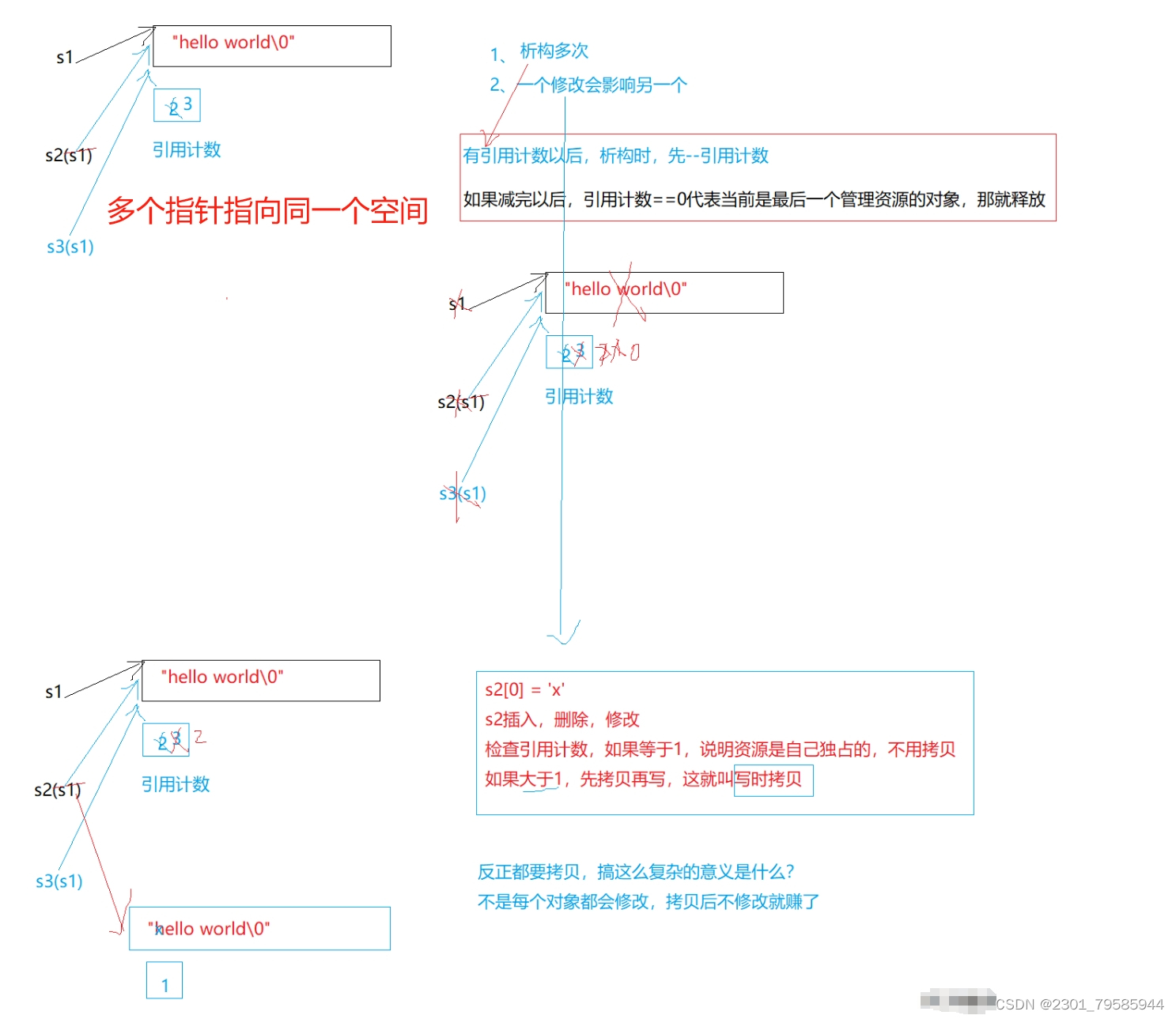
浅拷贝
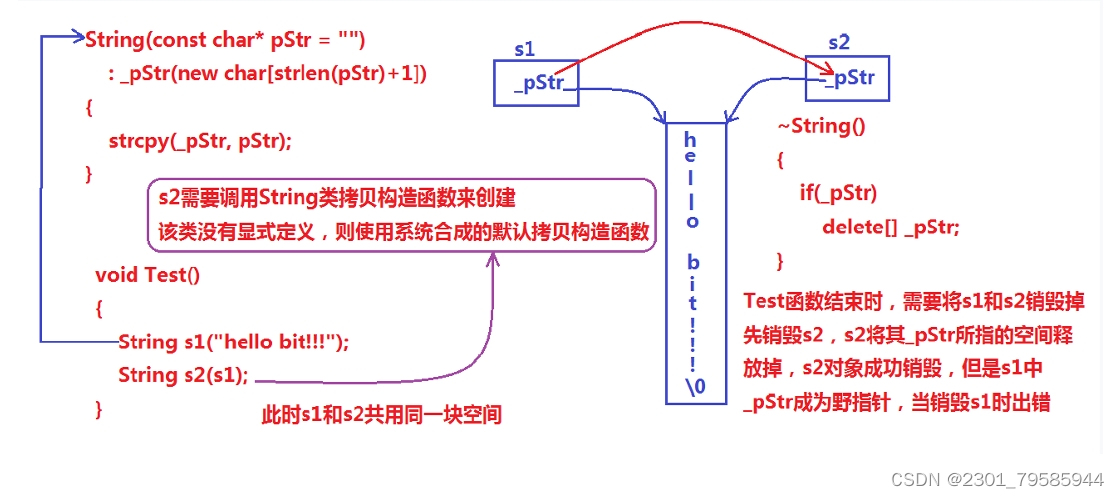
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。
说明:
上述String类没有显式定义其拷贝构造函数与赋值运算符重载,此时编译器会合成默认的,当用s1构 造s2时,编译器会调用默认的拷贝构造。最终导致的问题是,s1、s2共用同一块内存空间,在释放时同一块 空间被释放多次而引起程序崩溃,这种拷贝方式,称为浅拷贝。
深拷贝



vs和g++下string结构的说明
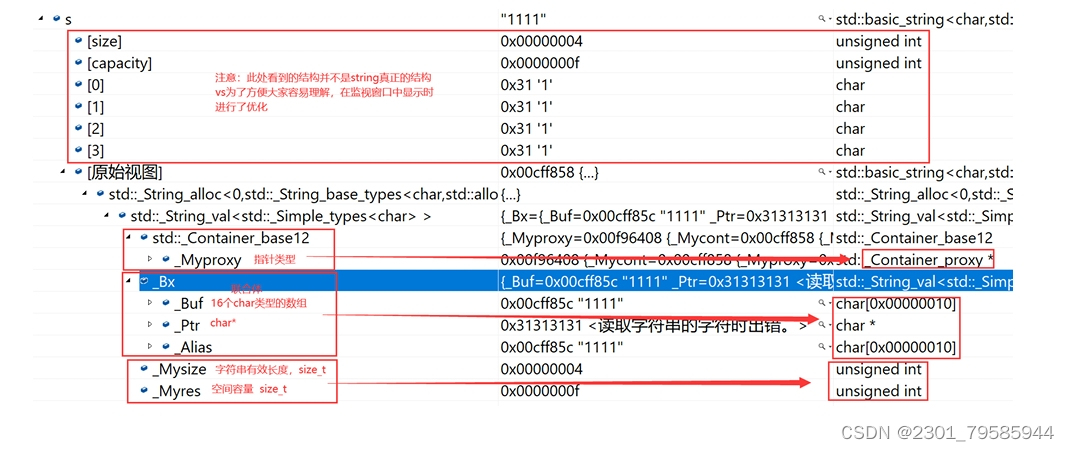
注意:下述结构是在32位平台下进行验证,32位平台下指针占4个字节。
- vs下string的结构
string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义string中字 符串的存储空间:
- 当字符串长度小于16时,使用内部固定的字符数组来存放
- 当字符串长度大于等于16时,从堆上开辟空间
union _Bxty{ // storage for small buffer or pointer to larger onevalue_type _Buf[_BUF_SIZE];pointer _Ptr;char _Alias[_BUF_SIZE]; // to permit aliasing} _Bx;这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建好之后,内 部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高。
其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的容量
最后:还有一个指针做一些其他事情。
故总共占16+4+4+4=28个字节。
- g++下string的结构
G++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包含了一个指针,该指 针将来指向一块堆空间,内部包含了如下字段:
- 空间总大小
- 字符串有效长度
- 引用计数
struct _Rep_base{size_type _M_length;size_type _M_capacity;_Atomic_word _M_refcount;};
- 指向堆空间的指针,用来存储字符串。

总结
好了,本篇博客到这里就结束了,如果有更好的观点,请及时留言,我会认真观看并学习。
不积硅步,无以至千里;不积小流,无以成江海。