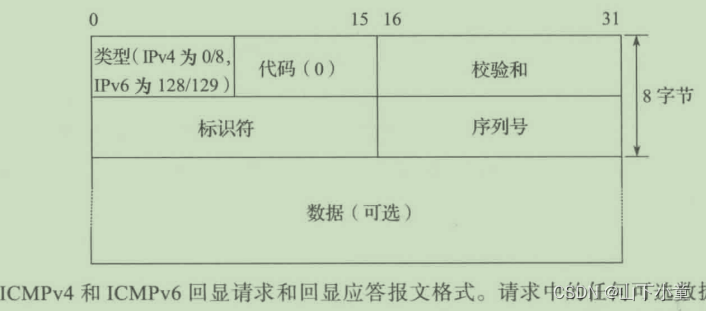
所需先验知识(没有先验知识可能会有大碍,了解的话会对D*的理解有帮助):A*算法/ Dijkstra算法
何为D*算法
Dijkstra算法是无启发的寻找图中两节点的最短连接路径的算法,A*算法则是在Dijkstra算法的基础上加入了启发函数h(x),以引导Dijkstra算法搜索过程中的搜索方向,让无必要搜索尽可能的少,从而提升找到最优解速度。这两者都可应用于机器人的离线路径规划问题,即已知环境地图,已知起点终点,要求寻找一条路径使机器人能从起点运动到终点。

但是上述两个算法在实际应用中会出现问题:机器人所拥有的地图不一定是最新的地图,或者说,机器人拥有的地图上明明是可以行走的地方,但是实际运行时却可能不能走,因为有可能出现有人突然在地上放了个东西,或者桌子被挪动了,或者单纯的有一个行人在机人运行时路过或挡在机器人的面前。

碰到这样的问题,比如机器人沿着预定路径走到A点时,发现在预先规划的路径上,下一个应该走的点被障碍物挡住了,这种情况时,最简单的想法就是让机器人停下来,然后重新更新这个障碍物信息,并重新运行一次Dijkstra算法 / A*算法,这样就能重新找到一条路。
但是这样子做会带来一个问题:重复计算。假如如下图所示新的障碍物仅仅只是挡住了一点点,机器人完全可以小绕一下绕开这个障碍物,然后后面的路径仍然按照之前规划的走。可是重复运行Dijkstra算法 / A*算法时却把后面完全一样的路径重新又计算了一遍
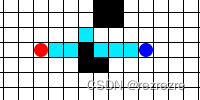
D*算法的存在就是为了解决这个重复计算的问题,在最开始求出目标路径后,把搜索过程的所有信息保存下来,等后面碰到了先验未知的障碍物时就可以利用一开始保存下来的信息快速的规划出新的路径。
顺便一提因为D*算法有上述的特性,所以D*算法可以使用在“无先验地图信息/先验地图信息不多的环境中的导航”的问题,因为只需要在最开始假装整个地图没有任何障碍,起点到终点的路径就是一条直线,然后再在在线运行时不断使用D*算法重新规划即可。
下面将开始讲述D*算法的流程。为此先提及一下算法应用的语境:
机器人已知一个地图map,在某个起点S,要前往终点E。但是机器人走着走着,突然在中途发现了地图上没有标注的障碍物(比如走着走着突然用激光雷达发现前面1米处有一些没有标注在地图上的障碍物),而这些障碍物有的挡住了机器人原本规划好的路,有的没挡住。
为了简化,我们认为机器人在栅格地图上运动,每次运动一个格子(8邻接),并且机器人为一个点,体积仅占据一个格子大小。
D*算法流程
先说明一下需要用到的类,开始运行前需要对地图中每个节点创建一个state类对象,以便在搜索中使用。
# 伪代码
class state:
# 存储了每个地图格子所需的信息,下面会说到这个类用在哪。以下为类成员变量
x # 横坐标
y # 纵坐标
t = "new" # 记录了当前点是否被搜索过(可为“new”,"open", "close",分别代表这个格子没被搜索过,这个格子在open表里,这个格子在close表里。关于什么是open表什么是close表,建议去看A*算法,能很快理解)。初始化为new
parent = None # 父指针,指向上一个state,沿着某个点的父指针一路搜索就能找到从这个点到目标点end的最短路径
h # 当前代价值(D*算法核心)
k # 历史最小代价值(D*算法核心,意义是所有更新过的h之中最小的h值)
d*算法主代码:
function Dstar(map, start, end):
# map:m*n的地图,记录了障碍物。map[i][j]是一个state类对象
# start:起点,state类对象
# end: 终点,state类对象
open_list = [ ] # 新建一个open list用于引导搜索
insert_to_openlist(end,0, open_list) # 将终点放入open_list中
# 第一次搜索,基于离线先验地图找到从起点到终点的最短路径,注意从终点往起点找
loop until (start.t == “close”):process_state() # D*算法核心函数之一
end loop
# 让机器人一步一步沿着路径走,有可能在走的过程中会发现新障碍物
temp_p = start
while (p != end) do
if ( unknown obstacle found) then # 发现新障碍物, 执行重规划
for new_obstacle in new_obstacles: # 对每个新障碍物调用modify_cost函数
modify_cost( new_obstacle ) #(D*算法核心函数之一)
end for
do
k_min = process_state()
while not ( k_min >= temp_p.h or open_list.isempty() )continue
end if
temp_p = temp_p.parent
end while
上述伪代码中核心函数为2个:modify_cost 和 process_state。我翻阅了csdn几个关于process_state的解释,发现都有挺大的错误,会让整个算法在某些情况下陷入死循环(比如D*规划算法及python实现_mhrobot的博客-CSDN博客)。而且就连原论文的伪代码都有点问题(可能原论文(Optimal and Effificient Path Planning for Partially-Known Environments,
function modify_cost( new_obstacle ):
set_cost(any point to new_obstacle ) = 10000000000 # 让“从任何点到障碍点的代价”和“从障碍点到任何点的代价” 均设置为无穷大,程序中使用超级大的数代替(考虑8邻接)
if new_obstacle.t == "close" then
insert(new_obstacle, new_obstacle.h ) # 放到open表中,insert也是d*算法中的重要函数之一
end if
下面是 Process_state函数的伪代码,注意标红那条
function process_state( ):
x = get_min_k_state(oepn_list) # 拿出openlist中获取k值最小那个state,这点目的跟A*是一样的,都是利用k值引导搜索顺序,但注意这个k值相当于A*算法中的f值(f=g+h, g为实际代价函数值,h为估计代价启发函数值),而且在D*中,不使用h这个启发函数值, 仅使用实际代价值引导搜索,所以其实硬要说,D*更像dijkstra,都是使用实际代价引导搜索而不用启发函数缩减搜索范围,D*这点对于后面发现新障碍物进行重新规划来说是必要的。
if x == Null then return -1
k_old = get_min_k(oepn_list) # 找到openlist中最小的k值,其实就是上面那个x的k值
open_list.delete(x) # 将x从open list中移除, 放入close表
x.t = "close" # 相当于放入close表,只不过这里不显式地维护一个close表
# 以下为核心代码:
# 第一组判断
if k_old < x.h then # 满足这个条件说明x的h值被修改过,认为x处于raise状态
for each_neighbor Y of X: #考虑8邻接neighbor
if y.h<k_old and x.h> y.h + cost(y,x) then
x.parent = y
x.h = y.h + cost(x,y)
end if
end for
end if
# 第二组判断
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
else: # 不满足k_old == x.h 那就是k_old < x.h
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t == "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) then
y.parent = x
insert(y, x.h + cost(x,y))
else:
if (y.parent != x and y.h >x.h + cost(x,y)) then
x.k = x.h # 注意这行!没有这行会出现特定情况死循环。在查阅大量资料后,在wikipedia的d*算法页面中找到解决办法就是这行代码。网上大部分资料,包括d*原始论文里都是没这句的,不知道为啥
insert(x, x.h)
else:
if (y.parent!=x and x.h>y.h+cost(y,x) and y.t= "close" and y.h>k_old then
insert(y,y.h)
end if
end if
end if
end for
end if
return get_min_k(oepn_list)
上面使用到的insert函数:
function insert(state, new_h)
if state.t == "new": # 将未探索过的点加入到open表时,h设置为传进来的 new_hstate.k = h_new # 因为未曾被探索过,k又是历史最小的h,所以k就是new_helif state.t == "open":state.k = min(state.k, h_new) # 保持k为历史最小的helif state.t == "close":state.k = min(state.k, h_new) # 保持k为历史最小的hstate.h = h_new # h意为当前点到终点的代价state.t = "open" # 插入到open表里所以状态也要维护成openopen_list.add(state) # 插入到open表
以上便是完整的d*算法流程。
D*流程详解
现在我们从“d*算法主代码”开始详解d*函数:
第一次搜索
首先可以看到,在最开始我们需要创建一个open list,然后将终点end加入到open list,之后不断调用process_state直到起始点start被加入到close表。open表中的东西要按照k值大小排序,每次调用process_state需要取出k值最小的一个来扩展搜索,注意open list中的东西要按照 k 值大小从小到大排序而不是h值。
第一次搜索时,对应主代码中的:
# 第一次搜索,基于离线先验地图找到从起点到终点的最短路径,注意从终点往起点找
loop until (start.t == “close”):process_state() # D*算法核心函数之一
end loop
这部分。
其实,在首次搜索时,我们可以发现每个点第一次被加入到open表中时都是从new状态加入,即每次调用insert函数时state.t 最开始都是new,所以其h值与k值其实是相等的;在搜索过程中,也即每一步调用process_state时,k_old 也一直等于x.h(k_old相当于x.k),因此每次第一组判断都不会被执行,第二组判断也总是只执行k_old == x.h这部分:
# 第二组判断
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
else:
........
而这部分中,对x的8邻接点y的判断只会有两种情况,①y.t== "new" ②y.parent != x and y.h >x.h + cost(x,y)。而第三种情况③y.parent == x and y.h !=x.h + cost(x,y) 在这时是不会出现的,因为h的意思是当前点到终点的代价,parent的意思是最短路径上当前点到终点的路径的上一个点,那么只要某个点的parent是x,那么这个点的h一定是x的h值加上从x到这个点的代价。第三种情况出现必定是因为y.h、x.h或者cost(x,y)被非正常流程中人为修改过,这在第一次搜索时是不会出现的,而是在重规划时出现,这点下面一个部分我们再谈。
也就是说,在初次搜索时其实整个process_state代码相当于如下(因为其他部分此时不会被调用):
function process_state****(初次搜索时等价于如下函数)( ):
x = get_min_k_state(oepn_list)
if x == Null then return -1
k_old = get_min_k(oepn_list)
open_list.delete(x)
x.t= "close"
# 第二组判断
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
return get_min_k(oepn_list)
可以发现,其实这就是dijkstra算法。
实际上,d*算法在初步规划时,完全退化成了dijkstra算法,也就是说如果沿着规划出来的路径运动过程中不发生障碍物变化的话,其实d*效率是要比a*低的,因为d*并没有启发式地往目标去搜索,搜索空间实际上比a*大很多。
但是d*这么做主要是为了提高在重规划时的效率,因为dijkstra算法其实实现的是“找到某个点到空间内所有点的最短路径”(注意我们是从终点开始往起点搜索的,所以找到的就是全部点到终点的最短路径)(其实也不是全部点,因为找到起点之后就停止搜索了,没搜完的都还留在open表中,也就是最短路程大于从起点到终点距离的点都没被搜。),在运行过程中碰到障碍物需要重规划时,我们就不再需要从当前点重新搜索到终点,而是找出一条路径,让我们绕开障碍物,到达附近没有障碍物的空闲点即可,而到达这个空闲点之后的路径不需要重新搜索,因为根据初次搜索,这个空闲点到目的地的最短路径我们已经有了。
重规划
接下来我们继续看主代码,第一次搜索完之后的部分(该程序默认第一次搜索能找到解,第一次无解的话就没有重规划了所以不考虑奥):
# 让机器人一步一步沿着路径走,有可能在走的过程中会发现新障碍物
temp_p = start
while (p != end) do
if ( unknown obstacle found) then # 发现新障碍物
for new_obstacle in new_obstacles: # 对每个新障碍物调用modify_cost函数
modify_cost( new_obstacle ) #(D*算法核心函数之一)
end for
do
k_min = process_state()
while not ( k_min >= temp_p.h or open_list.isempty() )continue
end if
temp_p = temp_p.parent
end while
这里让temp_p = start然后每一步都让temp_p = temp_p.partent是为了模拟机器人沿着路径一步步走的情形。当走到中途通过传感器发现了新的障碍物时,首先将发现的新障碍物信息加入到已知地图中,即执行:
for new_obstacle in new_obstacles: # 对每个新障碍物调用modify_cost函数
modify_cost( new_obstacle ) #(D*算法核心函数之一)
end for
对每个新发现的障碍物点调用 modify_cost(注意,d*无法处理某个点本来是障碍物,现在发现它不再是障碍物的情况,不考虑它,只考虑新增障碍物)
function modify_cost( new_obstacle ):
set_cost(any point to new_obstacle ) = 10000000000
if new_obstacle.t== "close" then
insert(new_obstacle, new_obstacle.h ) # 放到open表中
end if
return
首先将障碍物到周围所有点的移动代价设为无穷大。然后,如果
- 新发现的障碍物点状态是“new”,那就不用管,因为等一下执行process_state时,new点被第一次加入open表中时,这个无穷大的代价就会体现在其周围的点的h值上。实际上,如果一个点在重规划时还在new中的话,证明这个点第一次搜索并没有利用到它的信息,所以它在这次搜索过程中并不算“新成为障碍物”,因为第一次搜索时根本都不知道它是不是障碍物;
- 如果这个点的状态是“open”,也即这个点在open表中,那么也不用管,因为在open表中等下运行process_state时会被展开,然后其障碍信息会通过cost(x,y)这一项传递给周围的点。(障碍物点本身的h值不是无穷并没有关系,因为虽然这样做的话障碍物点本身能找到通往终点的路径,但是障碍物点本身并不会被机器人占领,所以不用担心。);
- 如果这个点的状态是close,那就将其原封不动(也即不用修改其h值)地移入open表,待等下执行process_state时将其障碍信息通过cost传递给附近的点即可;
在将新变成障碍物的点放入open表中后(new 的点也总归会被加入open表,如果没被加入那证明不需要它),就开始重复执行process_state, 直到找到解或者无解,即这段代码:
do
k_min = process_state()
while not ( k_min >= temp_p.h or open_list.isempty() )
其中,判断结束条件的 open_list.isempty() 如果被满足,即open表为空,意味着无解,这点和A*及dijkstra是一样的。(当然实际操作时一般不用open表为空作为条件,而是用open表中最小的k值大于等于前面设置的超大的值时就退出,或者在搜索过程中对于那些k值超过前面设置的超大值时,直接不将其加入open表。)
判断条件的 k_min >= temp_p.h 如果被满足,则代表找到解(找到从当前点到目标点的新最短路径)了。简单来说, k_min = process_state()这句, process_state()每次都是处理k值最小的点,当open表中最小的k值k_min比当前所在的点的h值还要大的时候,说明当前机器人所在的这个点temp_p已经被搜索过了。
在解释上面标绿的部分之前,需要提一下h跟k究竟具体代表什么。
h值
在重规划时,h表示搜到当前这一步的时候,当前这个点到目标点的最小代价,但是它不一定是最终找到最短路径后的最小代价,因为很可能最短路径上的点还没被搜索到呢,等会搜索到比现在这一步还短的路径时,当前点h的值自然会被修改成沿着那条更短路径到终点的代价。
k值
对于初次搜索路径时,k值的意义很明显就是跟h值是等价的,两者并无区分,具体意义参考dijkstra和A*算法的实际总代价值。
对于重规划时,k值意义较为复杂,为了理解它的作用,我们必须看回代码。因为重规划实际上也是不断调用process_state的过程,所以我们去找process_state中所有有可能修改k值的地方(注意下面代码标红处):
function process_state( ):
x = get_min_k_state(oepn_list)
if x == Null then return -1
k_old = get_min_k(oepn_list)
open_list.delete(x)
x.t= "close"
# 以下为核心代码:
# 第一组判断
if k_old < x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.h<k_old and x.h> y.h + cost(y,x) then
x.parent = y
x.h = y.h + cost(x,y) # 仅仅只会修改h,不修改k
end if
end for
end if
# 第二组判断
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y)) # 调用了insert,可能会涉及k值变化
end if
end for
else: # 不满足k_old == x.h 那就是k_old < x.h
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) then
y.parent = x
insert(y, x.h + cost(x,y)) # 调用了insert,可能会涉及k值变化
else:
if (y.parent != x and y.h >x.h + cost(x,y)) then
x.k = x.h # 直接修改了k!!!!
insert(x, x.h) # 调用了insert,可能会涉及k值变化
else:
if (y.parent!=x and x.h>y.h+cost(y,x) and y.t = "close" and y.h>k_old then
insert(y,y.h) # 调用了insert,可能会涉及k值变化
end if
end if
end if
end for
end if
return get_min_k(oepn_list)
可以看到稍微涉及到k值变化的也就上面几个标红的地方,其中4个都是insert函数。那么我们再来看insert函数:
function insert(state, new_h)if state.t == "new": # 将未探索过的点加入到open表时,h设置为传进来的 new_h
state.k = h_new # 因为未曾被探索过,k又是历史最小的h,所以k就是new_h
elif state.t == "open":
state.k = min(state.k, h_new) # 保持k为历史最小的h
elif state.t == "close":
state.k = min(state.k, h_new) # 保持k为历史最小的h
state.h = h_new # h意为当前点到终点的代价
state.t = "open" # 插入到open表里所以状态也要维护成open
open_list.add(state) # 插入到open表
在insert函数里,一个state的k值仅仅在传进来的参数new_h比k值更小的时候,k值才会被替换成新h值,这也合理,毕竟原论文中k的意义本身是“历史h值中最小的h值”嘛。
让我们再回到重规划时的process_state这个语境中。想一件事:我有一个地图,并且我一开始已经知道起点到终点的最短路径R(也即第一次搜索得到的结果)。可以肯定的是,对于这个最短路径R上的任何一个点来说,从这个点出发到目的地的最短路径肯定是前面说的这个最短路径R的从这个点开始的剩余部分。(反证:因为如果有更短的路,那最短路径R就不是从起点到终点的最短路径了呀,我完全可以走到这个点之后走那个更短的路径,这样肯定更短,这会出现矛盾)。
现在,我在原来地图的基础上额外增加新的障碍物,很可能①障碍物挡在了我原来的最短路径R上。这种情况下,我可能需要绕一条更长的路才能到达目标,也可能存在一条跟当前路径一样长的路,我可以走那条路,但不论怎么说,新的最短路径长度一定大于等于原本的最短路径R,绝对不可能比最短路径R还短(没理由障碍物多了反而我走的路更短吧)。也可能是②障碍物没挡住我,那我的最短路径一定不变。总结来说,发现新障碍物之后的最短路径一定比原本没有新障碍物时候的最短路径长,或者是一样长。
那么根据上面2段文字,我们知道,加入新障碍物后,某个点到目标点的最短路径长度,也即代价,一定是只能增不能减的。这说明什么?说明在重规划这个时候,执行insert函数时传进来的参数new_h一定不可能比原本的k值小,因为在第一次搜索结束时h跟k是相等的,都是最小代价,加入新障碍物后搜索过程中new_h “新代价”一定要比第一次搜索结束时的h“代价”要大,那也就是肯定比k都大。那也就是说,在重规划时,insert函数中,k值绝对不可能被更新。
说了3大段那么多,就是想说明一个事情:重规划时insert函数并不改变k值。那么返回到上面5处标红代码,我们可以看到,k值会被改变仅仅只有一个情况。那就是第二组判断中的某个条件下,直接修改k值那个地方(下面标红):
function process_state( ):
x = get_min_k_state(oepn_list)
if x == Null then return -1
k_old = get_min_k(oepn_list)
open_list.delete(x)
x.t= "close"
# 以下为核心代码:
# 第一组判断
if k_old < x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.h<k_old and x.h> y.h + cost(y,x) then
x.parent = y
x.h = y.h + cost(x,y) # 仅仅只会修改h,不修改k
end if
end for
end if
# 第二组判断
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y)) # 重规划过程中不修改k
end if
end for
else: # 不满足k_old == x.h 那就是k_old < x.h
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) then
y.parent = x
insert(y, x.h + cost(x,y)) # 重规划过程中不修改k
else:
if (y.parent != x and y.h >x.h + cost(x,y)) then
x.k = x.h # 唯一一个修改k的地方
insert(x, x.h) # 重规划过程中不修改k
else:
if (y.parent!=x and x.h>y.h+cost(y,x) and y.t = "close" and y.h>k_old then
insert(y,y.h) # 重规划过程中不修改k
end if
end if
end if
end for
end if
return get_min_k(oepn_list)
关于这个标红的地方的k值究竟会怎么修改,结论是:k值一定会被变大,变得比更新前的k值更大。原因在上面也说过了,在重规划过程中,所有点的代价一定比原来的大,也即这里出现的所有h值肯定都比第一次搜索结束后的k值大,那x.k=x.h这句,x.h肯定是比x.k大的。
那么什么时候一个点的k值会被修改呢?先告诉你结论:当我们找到了从这个点到目标点的,考虑了新障碍物之后的,新的最短路径newR后,这个点的k值会标修改成更大,并且这个修改后的k值代表了沿着新的最短路径newR,这个点到目标点的代价 / 实际距离。注意,如果在新的最短路径newR上某个点的代价(即到目标的距离)没有变化,那其k值也不会被改变。至于原因我们将在后面详解process_state中各判断条件时讨论。
综上所述,某个点的k值在重规划时意义如下:
- 如果某个点的k值在重规划时被修改,那么其修改后的k值就是考虑了新的障碍物之后,这个点到目标点的最短路径长度(代价)。这里需要注意,被修改k值的点不一定就在机器人接下来要走的路径上,可能是周围一大片因为加入了新障碍物导致变化的点,因为重规划可能不止运行一次,下一次运行重规划时,地图是基于此次重规划之上的,所以需要这一次运行完重规划后,地图状态是维持在dijkstra算法运行完毕,即地图上每个点都知道自己到目标点的最短路径的状态。
- 如果某个点的k值没被修改,那么其k值就有两种情况:①一是没有太大意义,硬要说的话意义就仅仅是“运行重规划前(即考虑新障碍物前),该点到目标点的最短路径代价值”;②二是不管考虑新障碍物与否,因为这个点到目标点的最短路径长度不变,所以其k值没变。
k的意义如上2种情况,但是其实2情况的①出现的点的数量正常来说是很少的,也就是说我们可以这样理解:k值的意义基本上就是重规划后某个点到目标点的最短距离。
那么可能有人会想到,即使2的①情况出现的很少,但是它还是会出现,那这难道不会影响后续又又又发现新障碍物时的重规划么?答案是不会。原因是因为这部分点其实真的非常少(说实话虽然我不太确定,但是是有可能完全不出现这些点的),而前面也说过,k值真正影响的是搜索的顺序,这部分点k值过小仅仅会影响他们在下一次重规划时优先考察,优先在他们处调用process_state。 并且在调用process_state时就会正常被处理,根据情况决定是否修正其k值,相当于使其回到1.的状态或者2.②的状态。如果看到这里不太能理解,那么建议看完下一部分之后再倒回来看看这个地方。
回到前面讨论的,结束判断条件k_min >= temp_p.h代表的意义:
从d*算法主函数中可以看到,重规划的过程实际上是不断调用process_state(),直到满足终止条件为止。每一次调用process_state()都是在从open list(open表)中抽出一个k值最小的state,然后处理它并将其移出open表,然后放入close表或者重新放回open表。也就是说不断调用process_state的过程中open list中最小的k值k_min的总体趋势是在不断增大(oepn list每次都取出一个拥有最小k值的state,并按照条件将新的节点加入open表,这些新节点固然很可能有更小的k使open list中的k_min变小,但是总体趋势上,k_min是在不断变大的)。
而对于open表来说,最小的k值k_min表示所有需要搜索的点(即所有在open表中的点),到目标点的距离都大于等于k_min这个值。从上面我们知道temp_p.h代表的意义是当前点(即机器人发现新障碍物时机器人所在的位置)的到目标点的代价(不一定是实际可行的路径中最小的,但是只要这个值不是无穷大,那证明已经找到从当前点到目标的一条路)。那么,k_min >= temp_p.h这个条件的意义就是“现在还需要继续搜索的点到目标的距离,已经大于等于现在已经找到的,当前机器人所在点到目标点的距离”,那就是说再搜索下去,即便找到新的路,其代价值也比现在已知的这条路的代价要大,所以不如现在这条路。因此可以说,达到这个条件就可以结束重规划过程了,因为已经找到最优解了。
详解process_state
为了真正理解d*算法,必须理解其核心函数process_state。该函数在第一次搜索时意义在上面已经说明,就是完全退化成dijkstgra; 下面对该函数在重规划过程中的行为进行分析。先再次将这个函数完整地放在这里方便查看:
function process_state( ):
x = get_min_k_state(oepn_list)
if x == Null then return -1
k_old = get_min_k(oepn_list)
open_list.delete(x)
x.t= "close"
# 以下为核心代码:
# 第一组判断
if k_old < x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.h<k_old and x.h> y.h + cost(y,x) then
x.parent = y
x.h = y.h + cost(x,y)
end if
end for
end if
# 第二组判断
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
else: # 不满足k_old == x.h 那就是k_old < x.h
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) then
y.parent = x
insert(y, x.h + cost(x,y))
else:
if (y.parent != x and y.h >x.h + cost(x,y)) then
x.k = x.h
insert(x, x.h)
else:
if (y.parent!=x and x.h>y.h+cost(y,x) and y.t = "close" and y.h>k_old then
insert(y,y.h)
end if
end if
end if
end for
end if
return get_min_k(oepn_list)
首先先看第一段
x = get_min_k_state(oepn_list) # 从open list中取出k值最小的state
if x == Null then return -1 # 若没取到东西证明open_list为空,也就是无解,返回-1
k_old = get_min_k(oepn_list) # 用一个变量k_old来存这个最小的k值
open_list.delete(x) # 将x移出open表并放入close表(close表不显式地维护)
x.t= "close" # 因为x被放入close表,修改其状态为close
这段表明每一次process_state都是取k值最小的一个进行搜索展开,并且被搜索展开的state会被放入close表,这跟a*、dijkstra的本质是一样的,都是根据一个值引导搜索的先后,在这里这个值是k值。
关于k_old,你没有看错,k_old就是等于取出来的x的k值,get_min_k_state 和 get_min_k两个函数中min k都指的是同一个值。为啥这么写呢?因为原论文伪代码就是这样写的,那就照抄吧,虽然感觉有点怪怪的。
障碍信息初步传递
接下来我们先讨论第二组判断。因为重规划过程中首先是对新障碍物进行modify_cost操作:
for new_obstacle in new_obstacles: # 对每个新障碍物调用modify_cost函数
modify_cost( new_obstacle ) #(D*算法核心函数之一)
end for
function modify_cost( new_obstacle ):
set_cost(any point to new_obstacle ) = 10000000000
if new_obstacle.t== "close" then
insert(new_obstacle, new_obstacle.h ) # 放到open表中
end if
return
为了便于理解,假设情况如下,机器人处于下图的情况
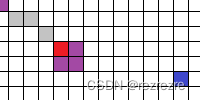
这一步之后所有障碍物点,即紫色点将被原封不动加入open表,即不改变其k值h值,直接放入open表。因为在加入这些障碍物点之前(即第一次搜索之后)open表中最小的k值肯定是大于等于起点的k值的(dijkstra算法特性),所以这些新加入的障碍物点,k值肯定比open表中其他的点的k值都小,那么在调用process_state时一定就是先被搜索。
而当process_state展开这些点时,因为没有改过其k值h值,所以第一组判断是不会进入的,而是直接进入第二组判断的前半k_old == x.h,即会执行下面这段:
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
对于每个障碍物点周围的的点y,如果:
- y是new,也即没加入过open表的点:那么因为y是第一次被搜素,将y的父节点设置为这个障碍物点,然后将其加入到open表中。注意因为障碍物点到周围所有点的代价都被设置为无穷大,所以insert这句实际上相当于insert(y,∞), 而y是第一次加入open表,那么其k值也会被设置为无穷。 在上图举例的情况里,只有整个图左上角那个紫色的点的周围的点有可能是new,而红色点附近的紫色点的8邻接点肯定不是new。如果是因为new而在这一步被把k设置成无穷大,那么这部分点是不会被后续搜索的。但是不用担心,因为出现这种情况的点是不会影响重新规划的最短路径的。
- y不是new(一般来说大部分情况下y都会是close,除非障碍物出现在上次搜索范围的边缘才会出现有open的情况,可以想象一下是怎么回事),并且y的父节点是这个新的障碍物点(y.parent == x and y.h !=x.h + cost(x,y) ):注意如果y的父节点是这个新障碍物点,那y.h !=x.h + cost(x,y)一定满足,因为本来y.h 是等于x.h + cost(x,y)的,但是x变成了障碍物之后cost(x,y)变成了无穷大,右边就不等于左边了。(不用管y.h和x.h都是无穷大的情况,这种清情况表示根本没解,不会被process_state扩展到的)满足这个条件的y都会被放入open表,但其h值要被设置为无穷大(因为相当于insert(y,∞))
- y不是new,并且y的父节点不是x,而且y当前路径的代价比“y下一步走到x再走x的最短路径” 的代价还小,即y.h >x.h + cost(x,y):不可能出现这种情况,因为cost(x,y)是无穷大,不用考虑。所以实际上这时只有上面2种情况
而其他不满足条件的点,此时也就是y的父节点不是x的点,那么这部分点是不会受到新障碍物影响的,其到终点的最短路径不会变化,所以不用加入open表重新考察。
对于上面因满足条件被加入open表的点,发生了什么变化呢?那就是这些点的h值都变成了无穷大,成为了raise状态!! 这个“障碍物点周围的点h值变为无穷”的过程,就是障碍物信息被传递的过程,这个过程还会继续不断传递下去,但是这次是通过另外的方式,我们马上就来讨论:
障碍信息消除与接力传递
在我们将障碍物信息初步传递给周围之后,如果第一次搜索得到的最短路径并没有被新发现的障碍物挡住的话,程序到这里就结束了,这也很好理解,我原本的路都没被挡,那我干嘛要找别的路?就按照原来的肯定就是最短的。但是如果挡住了,这些障碍信息就需要被处理。本来我们讨论的目的也是讨论如果出问题了会怎么样嘛,躲不开的:
对于上一步被加入了open表的点,我们知道他们的h值被设置成了无穷,他们处于raise状态。那么在process_state处理到它们时,这一次会首先从“第一组判断”开始处理,因为满足了条件:
# 第一组判断
if k_old < x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.h<k_old and x.h> y.h + cost(y,x) then
x.parent = y
x.h = y.h + cost(x,y)
end if
end for
end if
这一次x是指在上一步中被加入open表的“障碍物周围的点”,其h值x.h=无穷大,而k_old是第一次搜索时的值,是一个有限值,代表不考虑障碍物时到目标点的距离。对于x,扩展其8邻接点并考察每一个点y,如果同时满足:
- y的h值比x的k值小(y.h<k_old):首先只有x周围的,不是新发现障碍物的点的h值才会不是无穷,而这些点因为还没被重规划过程处理过,其h值仍然等于其k值。满足y.h<k_old 也就意味着,在第一次规划时,x周围的,比x更靠近终点的点(这句话需要详细捋一捋,因为在k_old就是x第一次规划时的k;y.h又等于y.k,也都是第一次规划时的值,那在第一次规划这个语境下,就是y的到终点的代价小于x的代价)。用图来理解的话,就大概是这个情况:

X标记为点x; 假设终点(蓝色)在x的右下方的话,那么粉色为满足1条件的点; - x当前代价(即无穷大),比x先走y再按y的最短路径走的代价更大(x.h> y.h + cost(y,x) ):因为x当前代价x.h是无穷大,所以这里的意思就是只要满足1的几个点里有不是障碍物的点,那x就从那边走代价肯定更低。
满足上面2个条件,也就意味着这个点虽然前往终点的路被新障碍物挡住了,但是我只要小小的拐一下就可以绕开这个障碍物,那么满足这样条件的点都会被执行:
x.parent = y
x.h = y.h + cost(x,y)
也即直接从y那边绕,也不用再往后搜索了,现在在这步就可以立刻得出到终点最短的路径。成功被这样处理的raise状态的点,h值会因为利用了第一次搜索遗留下来的信息直接下降,这被称为“初步降低代价”,同时这样相当于障碍信息被直接消除了。
至于需要大绕的点,比如说需要往后倒退两步才能绕开障碍物的情况,比如下图:
因为往回倒退这个过程会让代价相对于上一次搜索来说增大,那就设计其他栅格,就需要后续考察了,所以不能在这里直接处理。需要到第二组判断里处理

第一组判断结束后,需要进入第二组判断,如果在第一组判断中成功修改了x的h值,那么是有可能让x直接退出raise状态称为low状态的,也即让x的h值直接变回第一次搜索之后的k值,那么这里在第二组判断中,就会直接按照dijkstra的思路继续处理x及其周围的点了,也即会执行这部分:
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
因为是dijkstra,所以这部分中的 y.parent == x and y.h !=x.h + cost(x,y)这个条件是不会触发的,原因可以思考一下。提示一下:x的h值变成了第一次搜索之后的k值,也即k_old。
而如果x没有直接退出raise状态,或者x的h值并没有在第一组判断中修改,仍然是无穷,那么在这第二组判断中,就会执行后半部分,并将这个“走另一条路所以路径边长了”的信息,或者障碍信息,也即h为正无穷这个信息,传递给周围的邻格:
else:# 不满足k_old == x.h 那就是k_old < x.h
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) then
y.parent = x
insert(y, x.h + cost(x,y))
else if (y.parent != x and y.h >x.h + cost(x,y)) then
x.k = x.h
insert(x, x.h)
else:
if (y.parent!=x and x.h>y.h+cost(y,x) and y.t = "close" and y.h>k_old then
insert(y,y.h)
end if
end if
end for
# 为了方便看我又改了改else if 的逻辑,对比一下前面可以知道实际没有变化哦
在这部分,也是遍历x的8邻接点y,对y有以下情况:
-
y.t== "new" or (y.parent == x and y.h !=x.h + cost(x,y) ) :y是new表示第一次没搜索过y;y.parent == x and y.h !=x.h + cost(x,y)表示虽然y父节点指向x但是y的代价不是x的代价加上x到y的代价,这代表y的代价不正确了,它受到了x的变化带来的影响。这两种情况直接让y的父节点指向x, 再insert(y, y下一步走x的话的路径代价),放到open表里,等会搜索即可。此时如果x的h是无穷,那么相当于x的障碍信息被传递给了周围;如果x.h是有限值,但是比k_old大,那相当于将“x现在要走一条跟之前不一样长的路”这个信息传递给了周围
-
y.parent != x and y.h >x.h + cost(x,y): y的父节点不是x,但是y的当前路径长度y.h比“y先走到x再根据x的最短路径走到终点”的路径长度 还要长,那说明对y来说,有更短的路!而这个更短的路要经过x,这说明x现在已知的路值得肯定!因为会满足y.h >x.h + cost(x,y)这个条件时,x.h一定不是正无穷(好像不好说,非常极端的情况下,x.h=∞, y.h=∞+一个值,cost(x,y)=有限值但比前面那个“一个值”小的时候,因为程序中无穷大是用一个非常大的树数代替的,所以有可能出现这种情况,但是太极端了暂时没想到怎么构造这种情况,一般应该是不会出现的,先别考虑这个情况出现),那也就是说从x点已经找到新的到达终点的路了,那么现在就让x的k提升为x的h,这时,x的k值就在新障碍物存在的语境下具有了其应该具有的“最低代价”的意义。*******这也是程序中唯一一个能提升k值的地方,也正因为有这句话,在“发现的新障碍物导致最短路径会变长”这个情况下,k值,也即实际代价才能正确被提高为更大的值。很多网上的其他资料里,伪代码里都没有这句,而且d*原论文里也没有这句,我认为那是错误的,没有这句话的话,新障碍物挡住路导致新路径需要变得更长的情况是根本没办法处理的,即便第一次重规划成功,后续很可能又发现新的障碍物,那第二次重规划时的k值已经完全不再具有在第一次重规划时k值所具有的的意义了!但是对于一个迭代运行的算法,每一次运行时同样的变量应该有同样的意义才对。******
-
(y.parent!=x and x.h>y.h+cost(y,x) and y.t = "close" and y.h>k_old :我们先来讨论y.h>k_old这个条件,我们回到第一组判断里的if中,发现那里有一个“y.h<k_old ”这么样的条件,很明显在这里,y.h>k_old就是其互补条件,也就是说我们首先要挑出在第一组判断中因为“y.h<k_old ”被筛掉的点,考察这些点,那基本上用图来理解就是这样:

X标记为点x; 假设终点(蓝色)在x的右下方的话,那么粉色为满足y.h>k_old的点
在这部分点中我们再考虑剩下的条件。那么我们再考察y.t = "close" 这个条件。注意到满足那 么一大串条件(y.parent!=x and x.h>y.h+cost(y,x) and y.t = "close" and y.h>k_old)的话需要 执行的是insert(y,y.h) ,那如果y.t是“open”的话执行insert又不修改h值的话,相当于什么都没 干; 如果y.t是“new”的话,就不会到这里了,在第二组判断的一开始的“if y.t== "new" or xxx那里就执行别的事情去了。
那么这里剩下需要讨论的条件是y.parent!=x and x.h>y.h+cost(y,x): 这个条件指的是邻接点y有 不经过x的前往目标点的路径,并且x按照当前路径走所需代价比先走到y再沿着y的路径走的 代价还要大,注意跟2.一样隐含了y.h不是无穷大,也即y到目标点是有解的这么一个条件。出 现这种情况则将y放入到open表里待重新考察。可是既然x先走y再沿y的路走比按照自己的路 走更快,为什么不是修改x的父节点让其指向y(即让x.parent = y, x.h = y.h+cost(y,x))呢?因 为其实如果把y加入到open表中,下一次process_state展开这个y的时候,根据y的k和h值的 情况还是会再次考察这里的“y.parent!=x and x.h>y.h+cost(y,x)”这个条件的(相当于展开y这个 点时考察的条件 y.h>x.h+cost(x,y))。
然后我们再来考察上面没说明的最后一个条件,即第一组判断中的
if k_old == x.h then
for each_neighbor Y of X: #考虑8邻接neighbor
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) or
(y.parent != x and y.h >x.h + cost(x,y)) then
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
上述标红的条件代表的意义。
先从结论说起,上述条件会被触发必须满足前提k_old == x.h, 但是对于那些在重规划中x.h从头到尾一直等于k_old的点来说,这里是不会被触发的,因为对于这样的点来说相当于新发现的障碍物并不影响其到目标点的路径代价,所以其h值才一直不变化。只有那些受到新发现障碍物影响,导致x.h先上升了,然后经过后续搜索,修改了x.k的值使得h值与k值又相等了(通过x.k = x.h这一行)的那些点,才有可能会触发这一段。这代表着x虽然已经找到了到达目标点的新的最短路径,并且x的k值已经经过修改恢复了正确的意义,但是这个恢复并没有传递到y:y的父节点是x的话,其代价值h应该就等于x.h+cost(x,y)才对,但现在不等,所以需要将其修改正确。之所以要把y再次加入open表,是因为必须把y修改正确之后的信息继续传递给后续的栅格。简单来说这里的目的就是传递修正代价的信息
process_state函数总结
综上,我们可以得到process_state函数中,达到每个判断条件时所接受的处理的意义:
function process_state( ):
x = get_min_k_state(oepn_list)
if x == Null then return -1
k_old = get_min_k(oepn_list)
open_list.delete(x)
x.t= "close"
# 第一组判断
if k_old < x.h then
for each_neighbor Y of X:
if y.h<k_old and x.h> y.h + cost(y,x) then
# 尝试初步降低代价,仅在重规划时被使用
x.parent = y
x.h = y.h + cost(x,y)
end if
end for
end if
# 第二组判断
if k_old == x.h then
for each_neighbor Y of X:
if y.t== "new" or # ①dijkstra正常搜素流程
(y.parent == x and y.h !=x.h + cost(x,y) ) or # ②传递修正代价的信息
(y.parent != x and y.h >x.h + cost(x,y)) then # ③dijkstra正常搜素流程
# ②条件仅在重规划时会被使用,①③在全过程使用
y.parent = x
insert(y, x.h + cost(x,y))
end if
end for
else: # 不满足k_old == x.h 那就是k_old < x.h
for each_neighbor Y of X:
if y.t== "new" or
(y.parent == x and y.h !=x.h + cost(x,y) ) then
# 传递路径代价变化信息(传递的可能是障碍信息也可能是“正确路径产生变化”的信息)
y.parent = x
insert(y, x.h + cost(x,y))
else:
if (y.parent != x and y.h >x.h + cost(x,y)) then
# x点已经找到新的到达终点的路了,修正k值使之恢复“最小代价”的含义
x.k = x.h
insert(x, x.h)
else:
if (y.parent!=x and x.h>y.h+cost(y,x) and y.t = "close" and y.h>k_old then
# 该点待重新考察,重新放入open表
insert(y,y.h)
end if
end if
end if
end for
end if
return get_min_k(oepn_list)
以上便是关于d*算法,尤其是process_state的详解。
Python 实践代码
以下为实践代码,使用时请修改main函数中
NEW_OBS_STEP = 38 # 在走了多少步之后发现新障碍map_png = "./my_map.png" # 初始地图png图片obs_png = "./my_map_newobs.png" # 新增障碍物png图片,要跟初始地图相同大小,黑色认为是新障碍物上述3个变量。附带可用的地图图片如下:


(好像只要是图片就会被CSDN压,建议自己用画图软件画2个PNG文件,命名为my_map.png跟my_map_newobs.png,用黑白分别表示障碍物与空闲区域,其中my_map表示最初的地图,my_map_newobs表示走到一半发现的新障碍物,要求两个图片像素长宽一致,推荐都是100*100像素。)
将2个图片放到与以下.py文件同目录并在同目录下运行以下.py文件即可
但是上面2个图有csdn加的水印,可能自己画一张好
#!/usr/bin python
# coding:utf-8
import math
import cv2
from sys import maxsize
NEW_OBS_STEP = 38 # 在走了多少步之后发现新障碍class State(object):def __init__(self, x, y):self.x = xself.y = yself.parent = Noneself.state = "."self.t = "new"self.h = 0self.k = 0def cost(self, state):if self.state == "#" or state.state == "#" or self.state == "%" or state.state == "%":return maxsizereturn math.sqrt(pow(self.x - state.x, 2) + pow(self.y - state.y, 2))def set_state(self, state):# .普通格子 @ 新路径 # 障碍 % 新障碍 + 第一次搜索的路径 S 起点 E 终点if state not in [".", "@", "#", "%", "+", "S", "E"]:returnself.state = stateclass Map(object):def __init__(self, row, col):self.row = rowself.col = colself.map = self.init_map()def init_map(self):map_list = []for i in range(self.row):temp = []for j in range(self.col):temp.append(State(i, j))map_list.append(temp)return map_listdef get_neighbors(self, state):state_list = []for i in [-1, 0, 1]:for j in [-1, 0, 1]:if i == 0 and j == 0:continueif state.x + i < 0 or state.x + i >= self.row:continueif state.y + j < 0 or state.y + j >= self.col:continuestate_list.append(self.map[state.x + i][state.y + j])return state_listdef set_obstacle(self, point_list):for i, j in point_list:if i < 0 or i >= self.row or j < 0 or j >= self.col:continueself.map[i][j].set_state("#")class DStar(object):def __init__(self, maps):self.map = mapsself.open_list = set()def process_state(self):x = self.min_state()if x is None:return -1old_k = self.min_k_value()self.remove(x)print("In process_state:(", x.x, ", ", x.y, ", ", x.k, ")")# raise状态的点,包含两种情况:①有障碍信息,不知道怎么去终点的点 ②找到了到终点的路径,但是这条路径比最初没障碍的路径长,还要考察一下if old_k < x.h:for y in self.map.get_neighbors(x):if old_k >= y.h and x.h > y.h + x.cost(y):x.parent = yx.h = y.h + x.cost(y)# low状态的点if old_k == x.h: # 注意这个开头的if,不可以是elif,不然算法就不对了。某网上资源是有错误的for y in self.map.get_neighbors(x):if ((y.t == "new") or(y.parent == x and y.h != x.h + x.cost(y)) or(y.parent != x and y.h > x.h + x.cost(y))):y.parent = xself.insert_node(y, x.h + x.cost(y))else: # raise状态的点for y in self.map.get_neighbors(x):if (y.t == "new") or (y.parent == x and y.h != x.h + x.cost(y)):y.parent = xself.insert_node(y, x.h + x.cost(y))else:if y.parent != x and y.h > x.h + x.cost(y):x.k = x.hself.insert_node(x, x.h)else:if y.parent != x and x.h > y.h + x.cost(y) and y.t == "close" and y.h > old_k:self.insert_node(y, y.h)return self.min_k_value()def min_state(self):if not self.open_list:print("Open_list is NULL")return Noneresult = min(self.open_list, key=lambda x: x.k) # 获取openlist中k值最小对应的节点if result.k >=maxsize/2:return Nonereturn resultdef min_k_value(self):if not self.open_list:return -1result = min([x.k for x in self.open_list]) # 获取openlist表中值最小的kif result >= maxsize/2:return -1return resultdef insert_node(self, state, h_new):if state.t == "new":state.k = h_newelif state.t == "open":state.k = min(state.k, h_new)elif state.t == "close":state.k = min(state.k, h_new)state.h = h_newstate.t = "open"self.open_list.add(state)def remove(self, state):if state.t == "open":state.t = "close"self.open_list.remove(state)def modify_cost(self, state):if state.t == "close":self.insert_node(state, state.h)def run(self, start, end, obs_pic_path):self.insert_node(end, 0)while True:temp_min_k = self.process_state()if start.t == "close" or temp_min_k == -1:breakstart.set_state("S")s = startwhile s != end:s = s.parentif s is None:print("No route!")returns.set_state("+")s.set_state("E")# 添加噪声障碍点!!# rand_obs = set()# while len(rand_obs) < 1000:# rand_obs.add((int(random.random()*self.map.row), int(random.random()*self.map.row)))# 根据图片添加障碍点rand_obs = set()# new_obs_pic = cv2.imread("./my_map_newobs.png")new_obs_pic = cv2.imread(obs_pic_path)for i in range(new_obs_pic.shape[0]):for j in range(new_obs_pic.shape[0]):if new_obs_pic[i][j][0] == 0 and new_obs_pic[i][j][1] == 0 and new_obs_pic[i][j][2] == 0:rand_obs.add((i,j))temp_step = 0 # 当前机器人走了多少步(一步走一格)temp_s = startis_noresult = False # 新障碍物是不是导致了无解while temp_s != end:if temp_step == NEW_OBS_STEP:# 观察到新障碍for i, j in rand_obs:if self.map.map[i][j].state == "#":continueelse:self.map.map[i][j].set_state("%") # 新增障碍物self.modify_cost(self.map.map[i][j])k_min = self.min_k_value()while not k_min == -1:k_min = self.process_state()if k_min >= temp_s.h or k_min == -1:# 条件之所以是>=x_c.h,是因为如果从x_c找到了到达目的地的路,那么自身的h就会下降,当搜索到k_min比这个h小时,# 证明需要超过“从当前点到终点的最短路径”的代价的路径已经找完了,再搜也只会找到更长的路径,所以没必要找了,其他# 解都不如这个优。如果一直找不到解,那么x_c.h会是一直是无穷,那么就是说整个openlist都会被搜索完,导致其变为# 空。所以就是无解is_noresult = (k_min == -1)breakif is_noresult:breakif temp_step == NEW_OBS_STEP:draw_s = temp_swhile not draw_s == end:draw_s.set_state("@")draw_s = draw_s.parenttemp_s = temp_s.parenttemp_step +=1temp_s.set_state("E")if __name__ == "__main__":NEW_OBS_STEP = 38 # 在走了多少步之后发现新障碍map_png = "./my_map.png" # 初始地图png图片obs_png = "./my_map_newobs.png" # 新增障碍物png图片,要跟初始地图相同大小,黑色认为是新障碍物my_map = cv2.imread(map_png)_x_range_max = my_map.shape[0]_y_range_max = my_map.shape[1]mh = Map(_x_range_max,_y_range_max)for i in range(_x_range_max):for j in range(_y_range_max):if my_map[i][j][0] == 0 and my_map[i][j][1] == 0 and my_map[i][j][2] == 0:# png图片里黑色的点认为是障碍物mh.set_obstacle([[i,j]])start = mh.map[0][0] # 起点为(0,0),左上角end = mh.map[_x_range_max-1][_y_range_max-1] # 终点为(max_x-1,max_y-1),右下角dstar = DStar(mh)dstar.run(start, end, obs_png )for i in range(_x_range_max):for j in range(_y_range_max):if dstar.map.map[i][j].state[0] == "@": # 红色格子为发现新障碍物重规划后的路径my_map[i][j][0] = 0my_map[i][j][1] = 0my_map[i][j][2] = 255elif dstar.map.map[i][j].state[0] == "+": # 蓝色格子为第一次搜索的路径my_map[i][j][0] = 255my_map[i][j][1] = 0my_map[i][j][2] = 0elif dstar.map.map[i][j].state[0] == "%": # 紫色为新发现的障碍物my_map[i][j][0] = 255my_map[i][j][1] = 0my_map[i][j][2] = 255elif dstar.map.map[i][j].state[0] == "E": # 终点my_map[i][j][0] = 128my_map[i][j][1] = 0my_map[i][j][2] = 128cv2.imshow("xx", my_map)cv2.waitKey()cv2.imwrite("./my_map_result.png", my_map)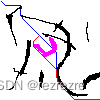
上图为运行程序后输出的结果。
其中左上角为起点,右下角为终点。蓝色路径为第一次规划的路径,紫色为走到一半发现的新障碍物,红色路径为发现新障碍物后重新规划的路径。修改程序中NEW_OBS_STEP变量可以修改走到第几步发现新的障碍物