文章目录
- 0 前言
- 1 课题背景
- 2 物流大数据平台的架构与设计
- 3 智能车货匹配推荐算法的实现
- **1\. 问题陈述**
- **2\. 算法模型**
- 3\. 模型构建总览
- **4 司机标签体系的搭建及算法**
- **1\. 冷启动**
- 2\. LSTM多标签模型算法
- 5 货运价格预测
- 6 总结
- 7 部分核心代码
- 8 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学习大数据物流平台
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
根据研究报告,中国拥有全球最大的道路运输市场,2020年市场规模为人民币6.2万亿元。其中整车(FTL)和零担(LTL)运输占中国公路运输市场的大部分,2020年到达了人民币5.3万亿元。
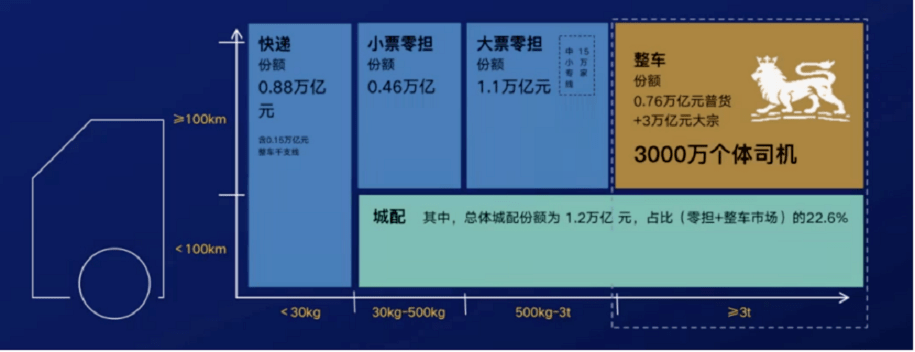
整个物流市场由物流公司、专项车队、司机等角色组成。一个普通物流订单由货主,物流公司,车队和司机通过逐层人工订单传递完成。物流中还有计划外的货运需求,需要由调度人员通过人工电话联系各个下级的承运方进行承运。另外,物流行业中还有许多地方需要人工支持,如车辆的在途信息、货运单据以及财务结算。可见,人工支持在物流行业中占有较高比例。
较高的人工支持占比导致物流企业在运营过程中无法针对一些具体的情况或者突发事件进行快速的反应和决策,使得一些中小企业在市场竞争中处于劣势。因此,物流公司需要一个智能高效的数字化物流平台,使其拥有信息化、数据处理以及算法能力,形成一个高效的物流生态。
2 物流大数据平台的架构与设计
物流大数据平台通过数字化各个物流环节,使得各流程实时衔接,提升物流系统的效率。随着车辆的移动、票据资金的流转以及交易的完成,所有业务数据都会沉淀到物流大数据平台。接着,通过大数据平台的计算能力,对数据进行整理,归类和分析,将数据提供给物流平台中的各个应用模块。同时,平台引入算法(机器学习和深度学习),在海量数据中不断接近业务问题的全局最优解,借助算法决策使得收益最大化。
目前,物流大数据技术平台主要是由应用层,算法平台,数据仓库和数据平台组成。
最上层的是 应用层 ,包括销售管理、智能调度、货源推荐、图片资料审核等,提供了平台所需要的核心功能,其实现应用了很多算法。这些算法是在算法平台上开发的。
算法平台 提供丰富的算法以及模型来支撑整个平台的运转。
算法层的下一层是 数据仓库 ,存放了集团所有的业务数据。只有基于这些丰富的数据,算法才能够能够为上层应用提供服务。
最底层是整个 大数据平台基础设施 ,包含CDH集群(Hadoop/ spark/
Impala)、Doris集群和监控系统。它们实现了海量数据的基础存储和计算能力,对批量数据进行秒级的统计分析,让企业的业务人员和分析人员能实时掌握企业的运营情况。
应用案例
① 车辆在途追踪
数据平台可追踪到任意一台已经安装了特定GPS设备的车辆。GPS设备每三十秒给数据中心传输一条经纬度位置的数据,从而让数据平台获取车辆的实时位置。连续的实时位置可构成行车记录,用于判断车辆在货运的途中是否正常行驶、是否偏离方向、是否超速行驶等。
② 实时调度中心
实时调度中心可以实时地计算出物流平台上各时间段内累计的货运单量、活跃司机数、货主数、交易金额等,便于业务决策。
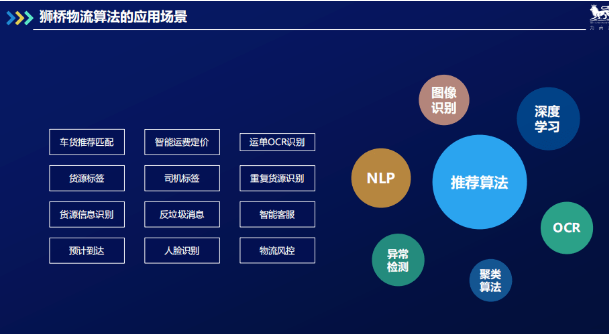
3 智能车货匹配推荐算法的实现
1. 问题陈述
智能车货匹配推荐算法的应用场景分为两种:一是人找货,二是货找人。人找货是货运司机通过浏览货运信息找到想要运输的货物;货找人是发货人下单后调度人员推送货源信息给货运司机。两个场景均涉及三个变量:司机、货物、环境。(具体涵盖如下图所示)
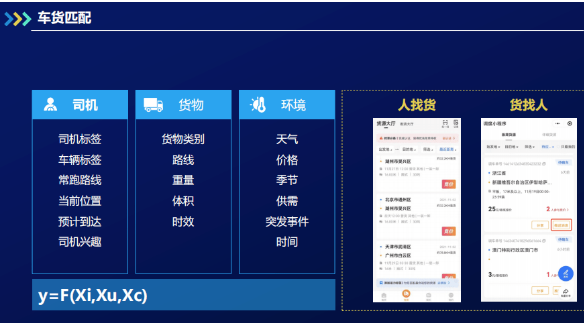
唯有合理运用这三个变量,才能计算出合理的车货匹配度。问题可以被抽象地用数学表达为 y=F(Xi, Xu,
Xc),其中y表示匹配程度,Xi指的是我们的item货物,Xu指的是货运司机user,Xc指的是环境context。
不妨将该问题变成点击率预测问题。当司机查看一个货源列表的时候,如果他点击了某条货源信息,就表示该司机对这条货源信息比较感兴趣;如果他没有点击,则假设他对这条货源信息不感兴趣。通过点击数据,我们可以把每一条货源信息标记为0和1,点击是1,未点击是0。从而,根据司机、货物以及环境所有的属性特征,我们预测该货源信息最终是否发生点击(变成了一个二分类问题)。
2. 算法模型
在实际应用中,解决是否点击问题经常引用的模型是DeepFM。DeepFM是深度学习和FM模型结合的一个框架,比单个深度学习模型或FM模型要表现好。
① FM模型
FM (Factorization Machine) 主要是为了解决数据稀疏的情况下,特征怎样组合的问题,也就是特征两两组合的问题。数学表达式如下:
其中n表示样本的特征数。这里的特征是离散化后的特征。与线性模型相比,FM的模型多了特征两两组合的部分。
② DeepFM构建
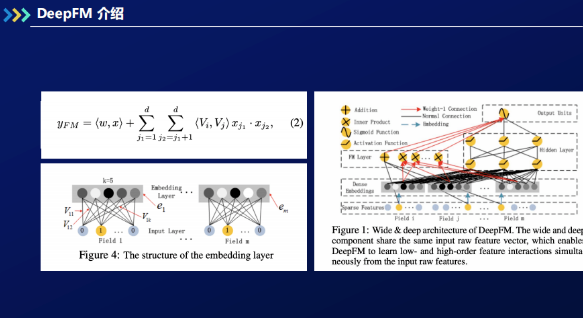
DeepFM模型包含FM和DNN两部分,FM模型可以抽取low-order特征,DNN可以抽取high-
order特征,因而无需人工特征工程。FM模块进行一阶和二阶的特征进行组合并学习到低阶特征;深度模型模块可以让模型学到更高阶的特征组合。最终,通过激活函数,预测点击概率。DeepFM具体框架如上图右半部分所示。首先,DeepFM对所有输入的稀疏特征进行embedding向量化,并对不同的特征之间进行交叉,生成新特征。FM
layer实现了上图左上的公式(2),把变量的二阶的特征交叉进行线性累加;Hidden
layer(DNN)实现了特征多重交叉,获得更高阶的特征交叉。FM模型和DNN模块共享特征embedding。通过FM和DNN,模型同时学习低阶和高阶的一个特征组合。
③ 模型评估
我们先用AUC评价并筛选出最优DeepFM模型。除此以外,还有其它离线指标评判模型是否能上线。
离线指标(Top10) : 根据回溯数据 ,模型算出司机(用户)前十适配的货源信息,前十适配的货源里有哪些货源被点击,从而计算出离线的前十点击率;
CTR: 货源展现点击率;
CVR: 订单成交转化率;
订单量: 由对应推荐位。
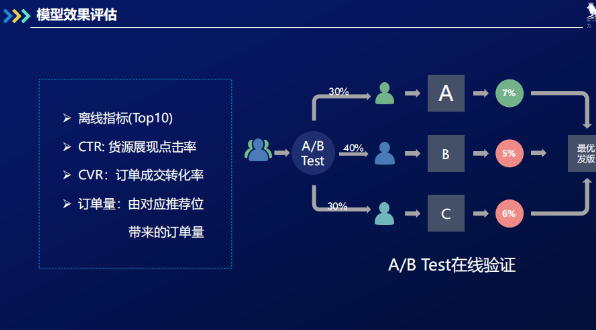
经过评估,如果该模型比之前的模型离线效果更好,我们就可以上线这个模型,再对其进行基于AB
test的线上效果评估。如下图所示,我们先将用户随机分成三组,占比30%,40%和30%。根据三组的线上CTR和CVR情况,平台抉择出最优版本进行发布。抉择可基于数值,也可基于统计学的假设检验。
3. 模型构建总览
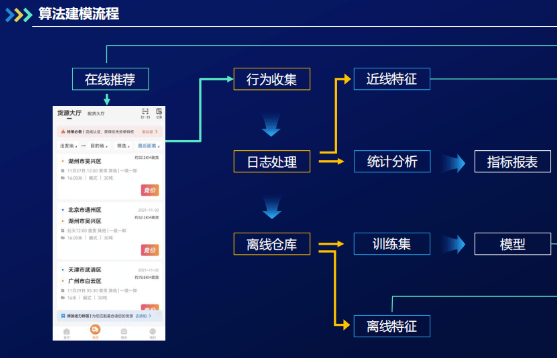
平台收集到用户行为数据后,通过实时计算框架,对行为数据进行处理并存到离线仓库,以制作模型训练集。模型给用户提供线上推荐。根据离线仓库里的数据,我们计算出一些离线特征。将离线仓库数据按日处理获得日志,其中包括统计分析以及近线特征。根据统计分析可以提炼出指标报表,为业务与模型训练提供指引;近线特征是指通过司机最近的行为计算其近期特征,可加入推荐模型以获得更好的推荐效果。
4 司机标签体系的搭建及算法
推荐车货匹配系统需要用到很多司机的标签特征,而且公司的产品和运营也需要良好的标签体系的辅助。接下来我们介绍司机的标签体系。
马玉潮:物流平台的车货匹配推荐算法及标签体系搭建
司机的标签体系主要有发货地、目的地、车型、车长、货物等。我们需要通过司机用户的历史行为,包括当前坐标、浏览货源筛选、报价等,做出标签预测。
1. 冷启动
前期数据匮乏时,我们需要经历一个冷启动的阶段。此时我们需要通过一些人工规则方式给司机打标签。例如,当司机访问一个货源时,若这个货源上面有标签,最简单的方法就是把这个货源上的标签打到这个司机身上。但司机的货运需求是变化的。例如,司机A之前更加关注轻工业产品的货运信息,但现在他比较关注普通商品的货运信息。可见,司机的近期的行为才更能代表其目前需求。
对于这个问题,我们借鉴了牛顿冷却定律的思想提出了解决方案。牛顿冷却定律指出物体的冷却速度与它当前温度与室温之间的温差成正比。将该公式映射到推荐场景中,则为距离当前时间越远的行为其权重越低。权重公式:
冷启动下的标签规则为,基于权重公式和人工规定的阈值,通过司机点击行为来给司机打上标签。
2. LSTM多标签模型算法
当累积一定的司机数据后,不仅平台会预测司机标签,司机用户也会自己维护标签。之后我们可以拿完整的司机数据(如标签完整度大于80%且其在app中交互行为超过一定阈值的司机数据)作为训练集,训练模型以预测司机的标签情况。

这里提出LSTM多标签模型,因为循环神经网络可以处理不定长的用户行为输入。具体框架示意如下:
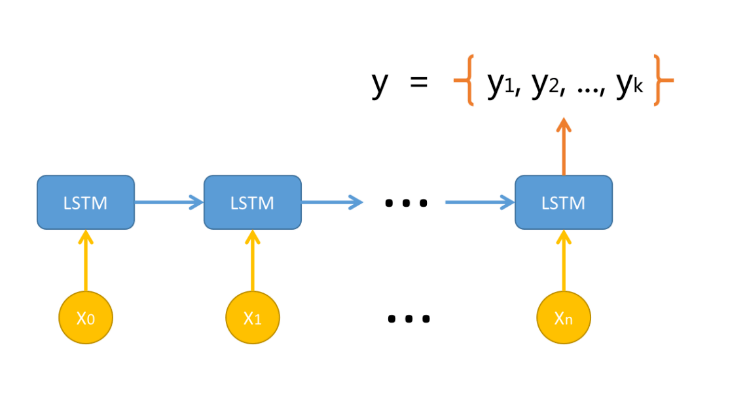
X表示的司机行为数据,例如X0表示司机的一次点击行为,X1表示司机的一次电话联系行为。X是不可预测的。司机用户每发生一种行为,都会被构建成输入,并被输入到LSTM模型当中。经过一系列行为后,模型输出对该司机的多标签预测。框架最后一层其实是对每一个标签做二分类,生成了一个多标签模型。
模型评价标准有精确度(Precision)以及召回率(Recall):
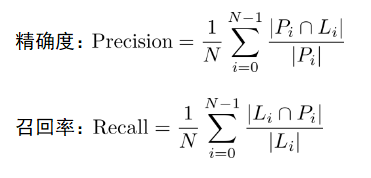
此处L是用户实际标签,P是模型预测标签。
这个模型现在还有以下几点待实现和解决:
- 预测出来的标签都可以作为推荐模型的一个输入;
- 司机车型、发货地和卸货地的预测困难,当前司机的车型标签比较少且固定,但司机对于发货地卸货地需求变化多端,因而我们需要更多数据才能更加准确地预测;
- 召回率与精确度平衡问题,比如给司机推送消息需要更高精确性以减少不必要的打扰。
5 货运价格预测
货运价格一方面可以作为模型的输入,另一方面可为系统整体运作提供提示和参考,尤其是需要知道整体市场价格的调度人员。因此,需要有模型来对货运价格进行预测。若要建模,首先要把货运价格通过专业知识拆分出固定的成本,如过路费、邮费、司机劳务费用、车辆折旧费用等等。另外,针对一些返程空车情况严重的路线,我们还需要考虑供需关系对于价格的影响。基础的货运价格公式和价格模型如下图所示。
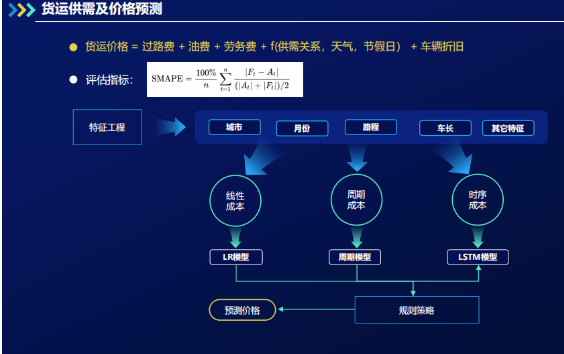
要搭建模型,首先要做特征工程,得到城市、月份、路程、车长以及其他特征。成本分为三种:线性成本、周期成本与时序成本。对于不同成本,我们施与不同的模型策略。线性成本是可以根据货运距离和油价计算出来的成本,例如过路费和邮费,因此使用线性回归模型进行学习。周期成本是跟天气相关、季节相关的。时序成本,如司机劳务费,是随着当地环境因素(如:收入水平)是在动态变化的。因此,通过连续的成本模型LSTM模型去进行预测。对于突发状况,模型则应用规则策略。规则策略主要是靠人工观察市场行情,并调参以调整价格模型。那么随着逐步收集市场数据,模型中可加入市场行情模型实现自动价格调整以及价格预测。
价格模型的评估指标为SMAPE(对称平均绝对值百分比误差),以处理高价带来的高方差。正常来说,模型对价格预测在实际价格上下10%波动,可以达到85%左右的准确率。
6 总结
物流大数据平台通过大量业务数据沉淀,训练出基于DeepFM的车货匹配系统模型,基于LSTM的司机标签体系模型,以及货运价格预测模型,从而成功建造了一个高效的物流生态。
7 部分核心代码
import scipy.io as sio
import numpy as np
import torch
from torch import nn
import matplotlib.pyplot as plt
import matplotlib
import pandas as pd
from torch.autograd import Variable
import math
import csv# Define LSTM Neural Networks
class LstmRNN(nn.Module):"""Parameters:- input_size: feature size- hidden_size: number of hidden units- output_size: number of output- num_layers: layers of LSTM to stack"""def __init__(self, input_size, hidden_size=1, output_size=1, num_layers=1):super().__init__()self.lstm = nn.LSTM(input_size, hidden_size, num_layers) # utilize the LSTM model in torch.nnself.linear1 = nn.Linear(hidden_size, output_size) # 全连接层def forward(self, _x):x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size)s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size)x = x.view(s * b, h)x = self.linear1(x)x = x.view(s, b, -1)return xif __name__ == '__main__':# checking if GPU is availabledevice = torch.device("cpu")if (torch.cuda.is_available()):device = torch.device("cuda:0")print('Training on GPU.')else:print('No GPU available, training on CPU.')# 数据读取&类型转换data_x = np.array(pd.read_csv('Data_x.csv', header=None)).astype('float32')data_y = np.array(pd.read_csv('Data_y.csv', header=None)).astype('float32')# 数据集分割data_len = len(data_x)t = np.linspace(0, data_len, data_len)train_data_ratio = 0.8 # Choose 80% of the data for trainingtrain_data_len = int(data_len * train_data_ratio)train_x = data_x[5:train_data_len]train_y = data_y[5:train_data_len]t_for_training = t[5:train_data_len]test_x = data_x[train_data_len:]test_y = data_y[train_data_len:]t_for_testing = t[train_data_len:]# ----------------- train -------------------INPUT_FEATURES_NUM = 5OUTPUT_FEATURES_NUM = 1train_x_tensor = train_x.reshape(-1, 1, INPUT_FEATURES_NUM) # set batch size to 1train_y_tensor = train_y.reshape(-1, 1, OUTPUT_FEATURES_NUM) # set batch size to 1# transfer data to pytorch tensortrain_x_tensor = torch.from_numpy(train_x_tensor)train_y_tensor = torch.from_numpy(train_y_tensor)lstm_model = LstmRNN(INPUT_FEATURES_NUM, 20, output_size=OUTPUT_FEATURES_NUM, num_layers=1) # 20 hidden unitsprint('LSTM model:', lstm_model)print('model.parameters:', lstm_model.parameters)print('train x tensor dimension:', Variable(train_x_tensor).size())criterion = nn.MSELoss()optimizer = torch.optim.Adam(lstm_model.parameters(), lr=1e-2)prev_loss = 1000max_epochs = 2000train_x_tensor = train_x_tensor.to(device)for epoch in range(max_epochs):output = lstm_model(train_x_tensor).to(device)loss = criterion(output, train_y_tensor)optimizer.zero_grad()loss.backward()optimizer.step()if loss < prev_loss:torch.save(lstm_model.state_dict(), 'lstm_model.pt') # save model parameters to filesprev_loss = lossif loss.item() < 1e-4:print('Epoch [{}/{}], Loss: {:.5f}'.format(epoch + 1, max_epochs, loss.item()))print("The loss value is reached")breakelif (epoch + 1) % 100 == 0:print('Epoch: [{}/{}], Loss:{:.5f}'.format(epoch + 1, max_epochs, loss.item()))# prediction on training datasetpred_y_for_train = lstm_model(train_x_tensor).to(device)pred_y_for_train = pred_y_for_train.view(-1, OUTPUT_FEATURES_NUM).data.numpy()# ----------------- test -------------------lstm_model = lstm_model.eval() # switch to testing model# prediction on test datasettest_x_tensor = test_x.reshape(-1, 1,INPUT_FEATURES_NUM)test_x_tensor = torch.from_numpy(test_x_tensor) # 变为tensortest_x_tensor = test_x_tensor.to(device)pred_y_for_test = lstm_model(test_x_tensor).to(device)pred_y_for_test = pred_y_for_test.view(-1, OUTPUT_FEATURES_NUM).data.numpy()loss = criterion(torch.from_numpy(pred_y_for_test), torch.from_numpy(test_y))print("test loss:", loss.item())# ----------------- plot -------------------plt.figure()plt.plot(t_for_training, train_y, 'b', label='y_trn')plt.plot(t_for_training, pred_y_for_train, 'y--', label='pre_trn')plt.plot(t_for_testing, test_y, 'k', label='y_tst')plt.plot(t_for_testing, pred_y_for_test, 'm--', label='pre_tst')plt.xlabel('t')plt.ylabel('Vce')plt.show()
8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate