Kafka源码分析环境搭建
使用截止目前为止Kafka的最新版本3.3.1版本的源码进行环境搭建
Kafka源码下载
从kafka官网下载kafka-3.3.1版本的源码
http://kafka.apache.org/downloads


解压(要放到英文目录,不然会报一些奇怪的错误)

Scala安装
因为在源码中配置的scala版本是2.13.8

以我们在win上安装Scala 2.13,上官网找到2.13.8版本对应的下载地址
https://www.scala-lang.org/download/2.13.8.html

然后就可以下载win上的安装包,scala.msi,下载好之后傻瓜式安装就可以了
在cmd中输入scala如果出现如下提示则安装成功

idea版本选择与Scala插件
因为最终要使用ide来导入,同时最新版本的kafka源码构建必须是gradle是高版本,所以IDE也必须是高版本才支持高版本的 gradle,所以这里推荐使用IntelliJ IDEA 2020.3.4 版本。

从这里可以看出gradle是6.7,版本已经够支持了。
安装Scala插件。
进入IntelliJ IDEA的这个界面
左侧有一个“Plugins”,搜索scala相关的插件,此时一开始是找不到的,然后点击“search in repositories”,找到一个“Scala”插件,他的类别是“Language”,在线装即可,他会下载之后安装

Gradle的安装
接着需要安装Gradle,现在国外很多知名的开源项目,Kafka是用Gradle来进行项目的构建了,所以需要安装。
我的IDE的版本支持的是gradle是
Gradle来完成Kafka源码的构建,使用gradle 7.6,从官网下载,解压缩即可,然后配置GRADLE_HOME和PATH
https://gradle.org/releases/
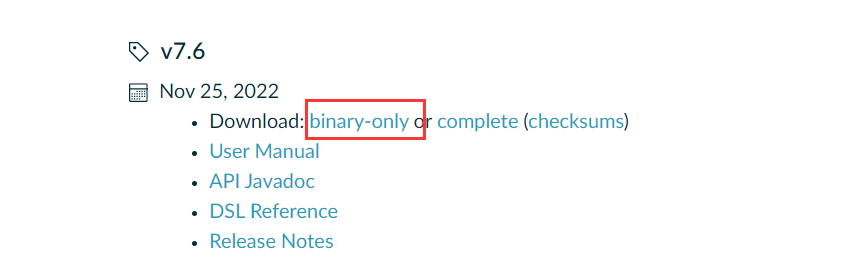
配置环境变量,新建 GRADLE_HOME 环境变量指向你的 Gradle 解压路径

然后将 %GRADLE_HOME%\bin 添加到 Path 环境变量中,然后点击确定

验证gradle是否安装成功,打开cmd命令行输入 gradle -v

最后 验证三个基础的依赖都正确安装了
java -version
scala -version
gradle -version
使用Gradle来构建Kafka源码
通过win命令行进入kafka-3.3.1-src目录下,然后执行“gradle idea”为源码导入idea进行构建
这个过程会下载大量的依赖jar包,建议配置 gradle 版本库为阿里源(不然会很慢,同时还可能抛出无法下载错误),同时也要修改对应的配置文件。
编辑Kafka源码目录下的build.gradle文件
1、修改阿里源



maven { url 'https://maven.aliyun.com/repository/public' }
2、修改配置(防止构建报错)
ScalaCompileOptions.metaClass.daemonServer=true
ScalaCompileOptions.metaClass.fork=true
ScalaCompileOptions.metaClass.useAnt=false
ScalaCompileOptions.metaClass.useCompileDaemon=false
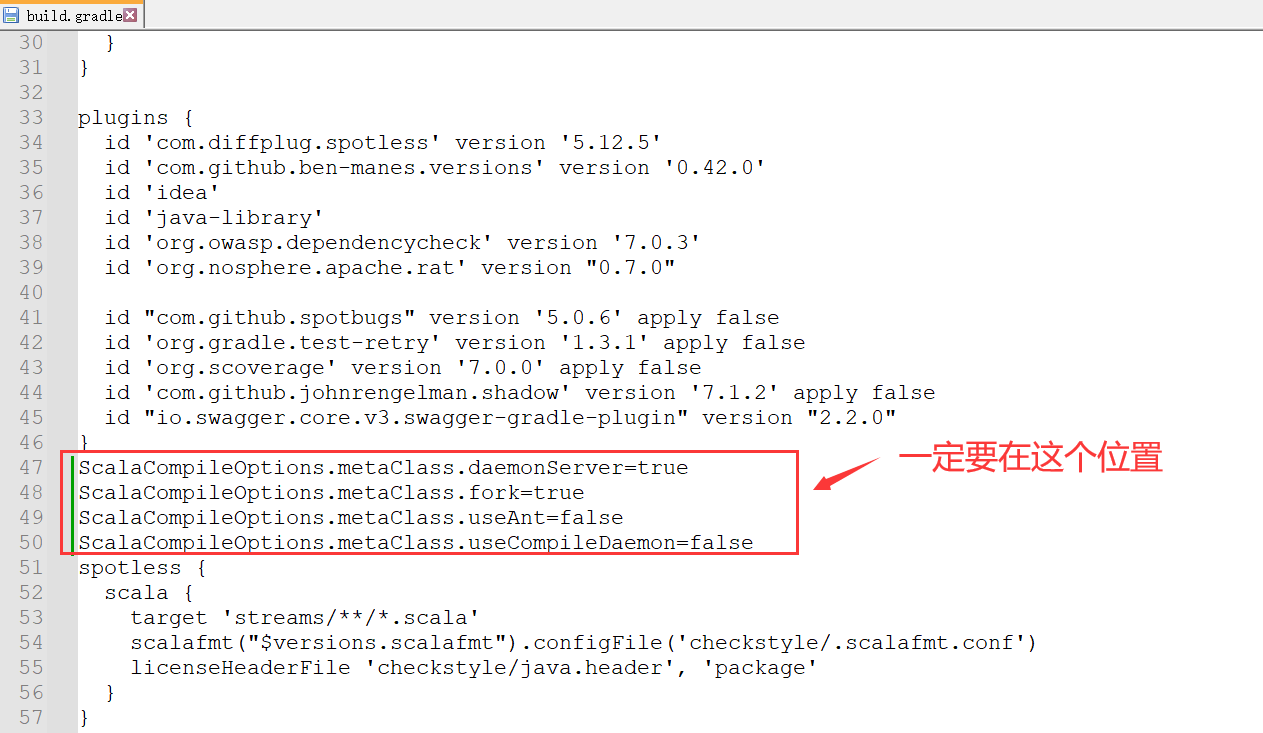
3、构建成功

安装完了在plugins里面就可以找到scala插件了,然后点击“ok”就会提示你重启intellij idea来激活安装好的插件,然后点击里面的那个Import Project按钮即可,选择你的kafka源码所在的目录,选择你构建项目的方式是“gradle”,导入的过程也需要不少的时间,需要耐心等待,会显示的是如下的图:



在IDEA中启动Kafka
我们肯定是要看到log4j输出的日志的,所以必须把config目录下的log4j.properties给放到src/main/scala目录下去,这样才能看到服务端运行起来的程序打印出来的日志
另外需要修改 config目录下的server.properties



之前IDE的Scala版本偏老,运行时会出现这个错误
那么手动更新scala的版本
https://plugins.jetbrains.com/plugin/1347-scala/versions/stable


缺少包slf4j-nop,导入该包。


slf4jnop: "org.slf4j:slf4j-nop:$versions.slf4j",

compileOnly libs.slf4jnop

1、生产者网络设计
架构设计图

2、生产者消息缓存机制
1、RecordAccumulator
将消息缓存到RecordAccumulator收集器中, 最后判断是否要发送。这个加入消息收集器,首先得从 Deque 里找到自己的目标分区,如果没有就新建一个批量消息 Deque 加进入




2、消息发送时机
如果达到发送阈值(批次发送的条件为:缓冲区数据大小达到 batch.size 或者 linger.ms 达到上限,哪个先达到就算哪个),唤醒Sender线程,
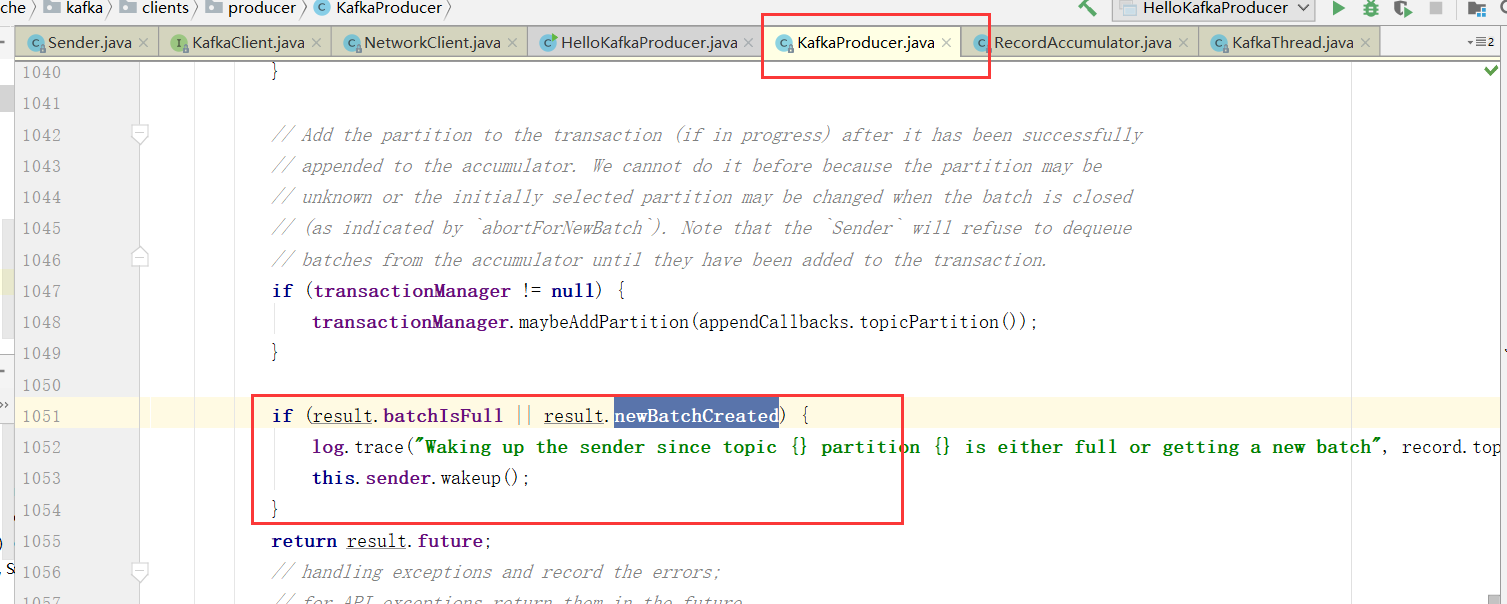
NetWorkClient 将 batch record 转换成 request client 的发送消息体, 并将待发送的数据按 【Broker Id <=> List】的数据进行归类




与服务端不同的 Broker 建立网络连接,将对应 Broker 待发送的消息 List 发送出去。
9)、


经过几轮跳转

3、Kafka通讯组件解析