一、前言:
云雀 (Skylark) 是字节内部团队研发的大规模预训练语言模型系列,目前有 lite, plus 和 pro 三个不同规模的版本。
Skylark-chat跟豆包版本对齐(版本更新有1天左右延迟)。
说明:
1、该模型会跟进豆包,更新信息不会主动通知用户;
2、如果业务需要稳定的模型,可以使用skylark-lite/plus/pro等。
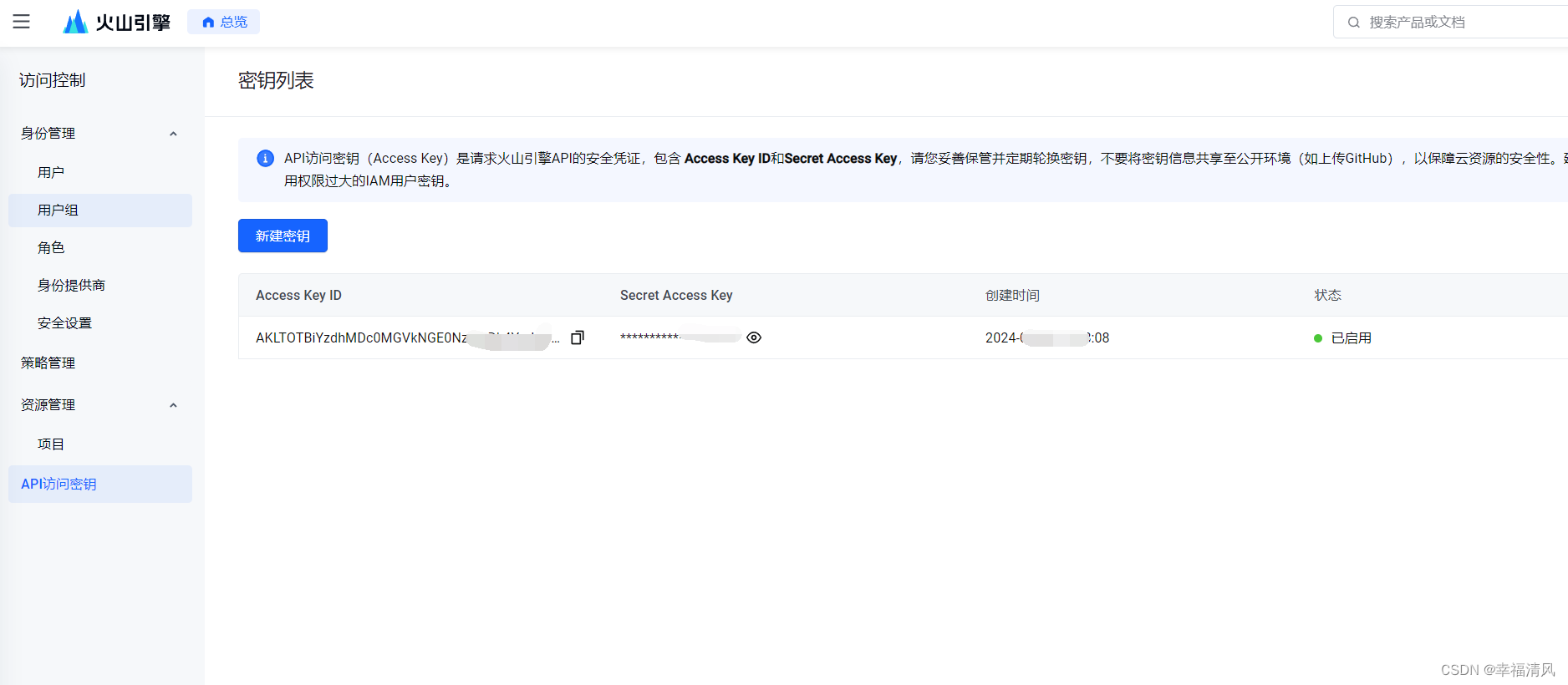
二、获取API Key:
1、打开网址:火山引擎-云上增长新动力 注册账号登录
2、登录——控制台——右上角(个人头像)——API访问秘钥


三、Python示例:
注意:目前仅支持 python>=3.5。
'''
Usage:1. python3 -m pip install --user volcengine
2. VOLC_ACCESSKEY=XXXXX VOLC_SECRETKEY=YYYYY python main.py
'''
import os
from volcengine.maas import MaasService, MaasException, ChatRoledef test_chat(maas, req):try:resp = maas.chat(req)print(resp)print(resp.choice.message.content)except MaasException as e:print(e)def test_stream_chat(maas, req):try:resps = maas.stream_chat(req)for resp in resps:print(resp)print(resp.choice.message.content)except MaasException as e:print(e)if __name__ == '__main__':maas = MaasService('maas-api.ml-platform-cn-beijing.volces.com', 'cn-beijing')# 填写自己密钥信息maas.set_ak(os.getenv("VOLC_ACCESSKEY"))maas.set_sk(os.getenv("VOLC_SECRETKEY"))# document: "https://www.volcengine.com/docs/82379/1099475"req = {"model": {"name": "skylark-chat",},"parameters": {"max_new_tokens": 1000, # 输出文本的最大tokens限制"temperature": 0.7, # 用于控制生成文本的随机性和创造性,Temperature值越大随机性越大,取值范围0~1"top_p": 0.9, # 用于控制输出tokens的多样性,TopP值越大输出的tokens类型越丰富,取值范围0~1"top_k": 0, # 选择预测值最大的k个token进行采样,取值范围0-1000,0表示不生效},"messages": [{"role": ChatRole.USER,"content": "天为什么这么蓝?"}, {"role": ChatRole.ASSISTANT,"content": "因为有你"}, {"role": ChatRole.USER,"content": "花儿为什么这么香?"},]}test_chat(maas, req)test_stream_chat(maas, req)四、API说明:
Chat
主要参考 OpenAI 和 HuggingFace
Parameters 记录可选控制参数,具体哪些参数可用依赖模型服务(模型详情页会描述哪些参数可用)
Input
| 字段 | 类型 | 描述 | 默认值 |
|---|---|---|---|
| model (required) | object | json
| None |
| messages (required) | list | json
| None |
| stream | boolean | 是否流式返回。如果为 true,则按 SSE 协议返回数据 | false |
| parameters.max_new_tokens | integer | 最多新生成 token 数(不包含 prompt 的 token 数目),和 | 2000(依赖模型默认配置) |
| parameters.temperature | number | 采样温度,(0, 1.0] | 1.0 |
| parameters.top_p | number | 核采样,[0, 1.0] | 1.0 |
| parameters.top_k | integer | top-k-filtering 算法保留多少个 最高概率的词 作为候选,正整数。 | 0 |
| parameters.stop | list | 用于指定模型在生成响应时应停止的标记。当模型生成的响应中包含这些标记时,生成过程将停止 | [] |
Output
| 字段 | 类型 | 描述 |
|---|---|---|
| req_id | string | 请求 id |
| choice | object | json
|
| usage | object | json
|
| error(optioanl) | object | json
|
在 stream 模式下,基于 SSE (Server-Sent Events) 协议返回生成内容,每次返回结果为生成的部分内容片段:
-
内容片段按照生成的先后顺序返回,完整的结果需要调用者拼接才能得到;
-
如果流式请求开始时就出现错误(如参数错误),HTTP返回非200,方法调用也会直接返回错误;
-
如果流式过程中出现错误,HTTP 依然会返回 200, 错误信息会在一个片段返回。









![[c++] char * 和 std::string](https://img-blog.csdnimg.cn/direct/41d882545669454391caf4a37bc6e6dd.png)
