复杂数据结构处理:Join 小技巧:提升数据的处理速度
本文是在原本sql闯关的基础上总结得来,加入了自己的理解以及疑问解答(by GPT4)
原活动链接
用到的数据:链接
提取码:l03e
目录
- 1. 课前小问答 🔎
- 2. 开始之前的准备
- 2. JOIN 基本语法
- 2.1 关联方式 ( JOIN ) 的常见类型
- 2.1.1. INNER JOIN (JOIN)
- 2.1.2. LEFT JOIN
- 2.1.3 FULL OUTER JOIN
- 2.1.4 CROSS JOIN
- 2.2 关联列和关联条件
- ✍️ 小练习 1: 用 students 和 courses 表,写出查询 student_name 为"小小鲸"或是 course_name 是"机器学习"的 SQL 语句
- 3. 如何提升 JOIN 的效率
- 3.1 索引,索引,索引
- ✍️ 小练习 2:参考上面的代码,尝试将 query 修改成其他 JOIN 语句,观察一下图的变化。
- 3.2 谓词下推:先过滤,后计算
- 4. 小结 🥡
- 闯关题
- STEP1:根据要求完成题目:
- STEP2:将结果保存为 csv 文件
1. 课前小问答 🔎
1. 我听说 JOIN 是 SQL 当中最常用的语句,为什么现在才开始学习 JOIN ?
A:这是一个好问题,JOIN 确实是任何一种 SQL 语言(我们的教程中所用的 SQLite 仅仅是最轻量化的 SQL 语言)中最为强大的工具(或许没有之一),你肯定对于一些业务逻辑非常复杂的机构(如银行)常常需要 JOIN 几十张表格来进行 SQL 数据处理的轶事。
但尽管如此,JOIN 并非所有场景下的最优解,在后续的教程中,我们可以看到一些其他的函数能够在应用上代替部分的 JOIN ,同时 JOIN 也是一个特别考验效率的环节:代码的执行速度,可阅读性和可拓展性都是需要考量的因素
2. 学习 JOIN 需要多张表一起练习吗?
A:不需要,尽管在实际的工作场景当中,JOIN 多数的使用场景是跨表链接,但是要掌握 JOIN 的技巧只需要一张表(例如我们当前所有的泰坦尼克数据集)就可以
本系列教程所使用的 SQLite 并不支持所有类型的 JOIN
2. 开始之前的准备
在我们正式开始前,我们需要为此次的教学准备一个案例数据库,因此请完成以下内容的检查
# 导入库
from IPython.display import Markdown as md
import sqlite3
import pandas as pd
import numpy as np
import json
from copy import deepcopy
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取泰坦尼克号数据集
df = pd.read_csv('./data/train.csv')
# 将表格中 NaN 值替换为 NULL
df = df.where(pd.notnull(df), None)# 将数据写入一张名为 example_table 的表
with sqlite3.connect('example.db') as conn:df.to_sql('example_table', con=conn, if_exists='replace', index=False)# 为了下面教程的开展,我们这里需要制作一些新的表格
# 新建一个字段 "CabinType",表示 Cabin 字段的第一个字母
new_df = deepcopy(df)
new_df['CabinType'] = new_df['Cabin'].apply(lambda x: x[0] if x is not None else None)# 计算每个 CabinType 和 Pclass 分组下的平均船费和生存率
df_gb_pc_ct = new_df.groupby(['Pclass','CabinType'])[['Fare','Survived']].apply(lambda x: np.mean(x)).reset_index()# 将结果存入数据库,新建一张名为 example_table_gb 的表格
with sqlite3.connect('example.db') as conn:df_gb_pc_ct.to_sql('example_table_gb', con=conn, if_exists='replace', index=False)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
D:\Anacanda3\lib\site-packages\numpy\core\fromnumeric.py:3430: FutureWarning: In a future version, DataFrame.mean(axis=None) will return a scalar mean over the entire DataFrame. To retain the old behavior, use 'frame.mean(axis=0)' or just 'frame.mean()'return mean(axis=axis, dtype=dtype, out=out, **kwargs)
# 链接到刚刚创建好的数据库
connection = sqlite3.connect('example.db')
2. JOIN 基本语法
在SQL中,JOIN的核心作用就是将两个或多个表中的数据关联组合在一起。JOIN 的强大之处,就在于它让我们可以从多个表中检索数据,并根据不同表格之间数据的关联性丰富可以分析的维度。
如果你熟悉 Excel, JOIN 的功能和 VLOOKUP 不尽相似,当两张或者多张表格共享同一列的时候,可以通过其中一张表格的某个字段(关联字段或是关联列)去匹配的另一张表格里面的某个字段,而在 SQL 当中的 JOIN 语句则是功能更加丰富
一个简单的 JOIN 包含了 3 个基本要素:
-
关联列
-
关联方式
-
关联条件
🌰:假设我们有两个表:一个包含学生信息的 “students” 表和一个包含课程信息的 “courses” 表。
students 表:<br></br>
| student_id | student_name |
|---|---|
| a2b2c2 | 方小鲸 |
| a1b1c1 | 小小鲸 |
| course_id | student_id | course_name |
|---|---|---|
| course_1 | a1b1c1 | 机器学习 |
| course_2 | a1b1c1 | 机器学习 |
假设我们想要获取每个学生所选的课程的信息,返回课程的名称和学生的名称,下面代码中所展示的 INNER JOIN (关联方式的一种) 可以帮助我们做到这一点
query = '''
SELECT courses.course_name,students.student_name
FROM courses JOIN students -- **关联方式**: JOINON courses.student_id = students.student_id -- **关联列**: courses.student_id, students.student_id-- **关联条件**: courses.student_id = students.student_id
'''JOIN 可以关联多张表哦~ 语句是 TABLE A JOIN TABLE B ON ... JOIN TABLE C ON... JOIN TABLE D ON...
2.1 关联方式 ( JOIN ) 的常见类型
不同类型的 SQL 语言当中有各种类型的 JOIN 语句,但是最基础的 JOIN 有以下 4 种:
2.1.1. INNER JOIN (JOIN)
最常见的 JOIN 方式,本质上是,通过两张表格的关联列,取两张表格的交集,用较为熟知的 Venn 图来表示就是

图片来源: A Visual Explanation of SQL Joins
当然,如果你觉得用 Venn 图的方式来理解 JOIN 不容易记忆,别担心,你不是一个人,我们可以用另一种方式理解 INNER JOIN:
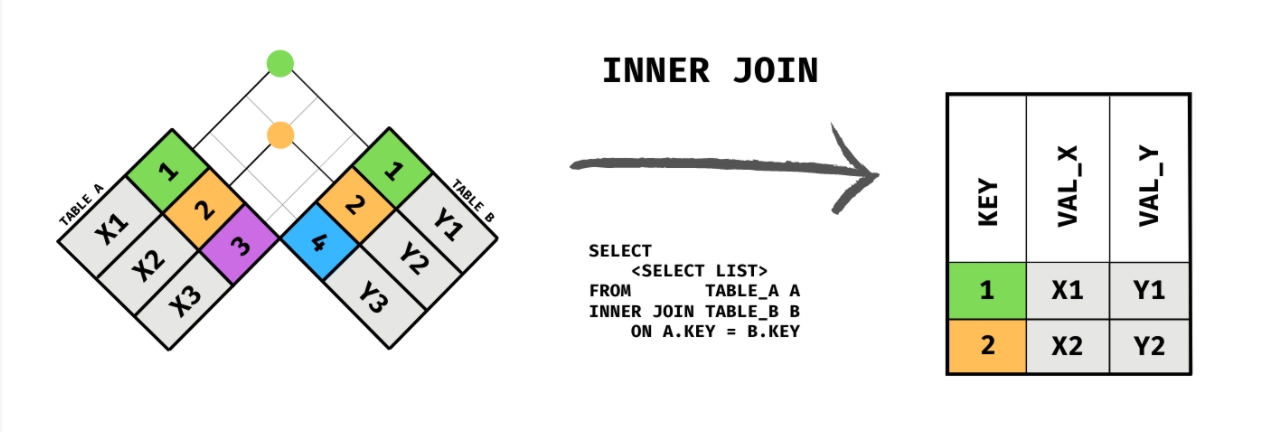
INNER JOIN : 图中有颜色的点代表关联的数据,具体的颜色对应具体的数据,有多少个点代表结果上有多少个数据
2.1.2. LEFT JOIN
使用率仅次于 INNER JOIN 的 JOIN 方式,从两张表当中选取一张表(一般是JOIN 关键字左边的表),在保留这张表里面的所有数据的前提下,去另一张表找到可以关联上的数据,如果被保留的表当中有某些数据无法匹配到另一张表(找不到匹配的数据),则对于返回 NULL 作为匹配结果
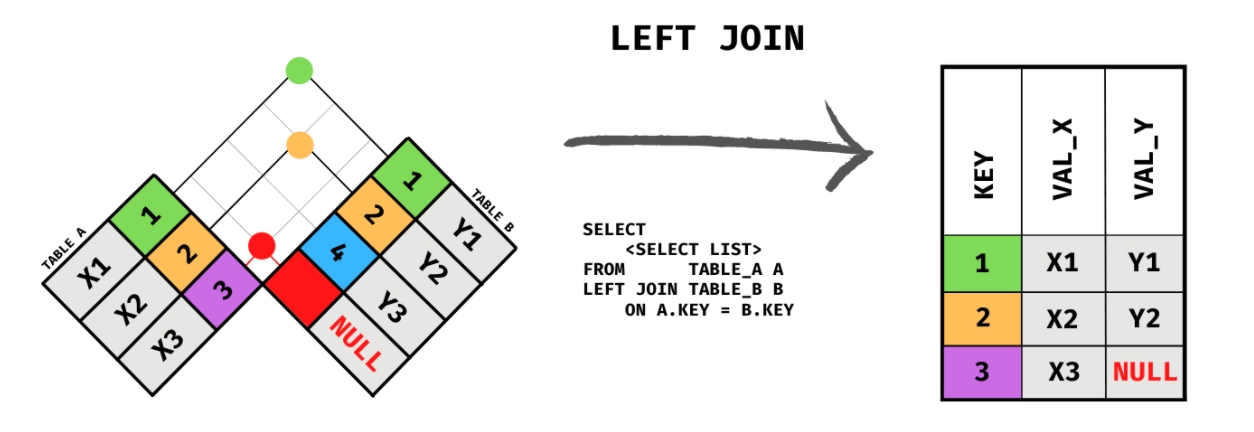
如图所示,在保留 TABLE A 的情况下,从 TABLE B 当中寻找能够匹配 TABLE A 的数据。
TABLE A 中的 X3=3 在 TABLE B 没有,则返回 NULL
2.1.3 FULL OUTER JOIN
又称全量 JOIN,基础但是比较少见的 JOIN 方式,最直观的理解方式,就是对于两张表互相各做一次 LEFT JOIN 后取并集(即把 A LEFT JOIN B 的结果 和 B LEFT JOIN A 的结果拼接后去重)
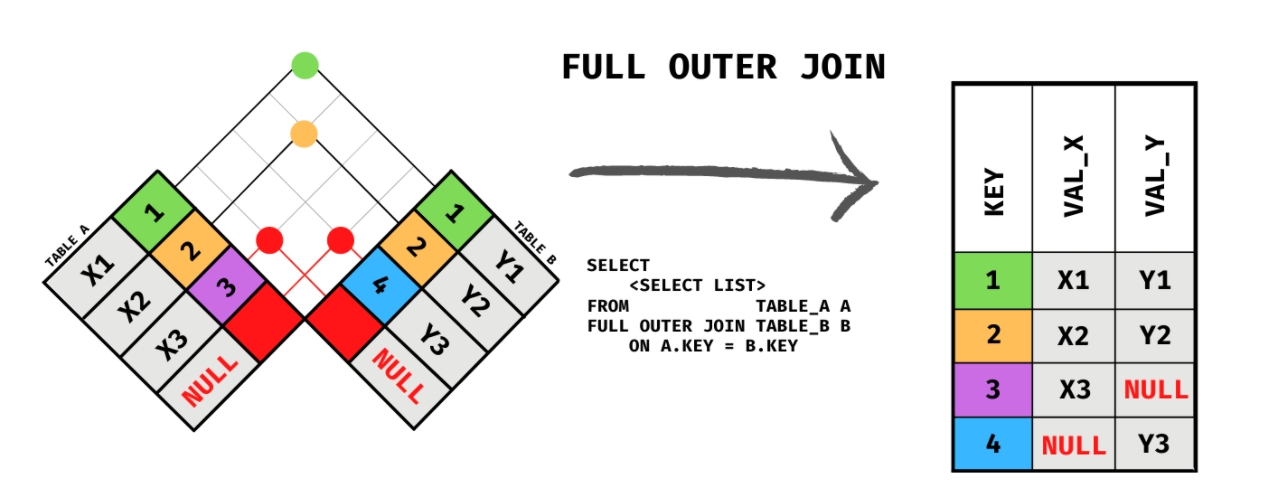
STEP 1: TABLE A LEFT JOIN TABLE B, 因为 X3=3 在 TABLE B 中没有,所以返回 NULL
STEP 2: TABLE B LEFT JOIN TABLE A, 因为 Y3=4 在 TABLE A 中没有,所以返回 NULL
STEP 3: 拼接 STEP 1 和 2 中的结果
STEP 4: 去掉重复的部分(X1=1,X2=2)
2.1.4 CROSS JOIN
一种特殊的 JOIN 形式,可以理解为没有关联条件的 JOIN ,即无论是否有关联列或是关联列是否匹配,都会返回结果
如图所示,TABLE A 中的值无论和 TABLE B 中的值是否匹配都会添加到最终的结果中
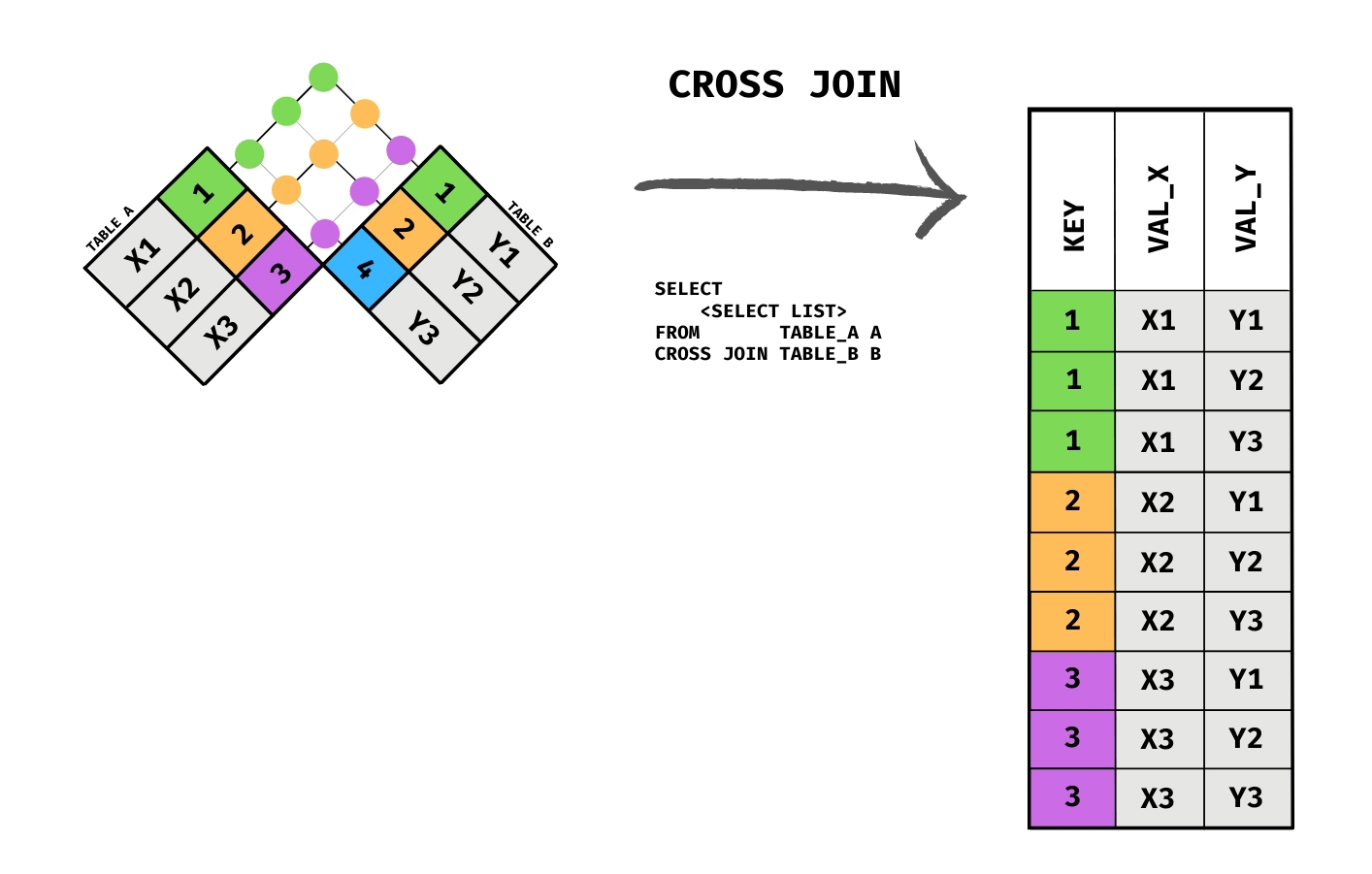
或许你听说过 RIGHT JOIN 这种方式,实际上 RIGHT JOIN 可以简单理解成 LEFT JOIN 的镜像对称,例如 TABLE A LEFT JOIN TABLE B = TABLE B RIGHT JOIN TABLE A
2.2 关联列和关联条件
关联列:一般而言是 JOIN 前后的表格的特定列,JOIN 对于关联列的要求比较宽松,可以允许 JOIN 前后只出现一个关联列或是多个关联列
关联条件:常见的运算符(=,<>,>,<,>=,<=,…)都可以使用,一些 SQL 语言自带的语法也可以用(比如 in),不同的关联条件可以通过 and 和 or 两种逻辑运算符组合构成更加复杂的条件
下面的 JOIN 示例以上文提到的 students 和 courses 两张表作为例子
students 表:<br></br>
| student_id | student_name |
|---|---|
| a2b2c2 | 方小鲸 |
| a1b1c1 | 小小鲸 |
| course_id | student_id | course_name |
|---|---|---|
| course_1 | a1b1c1 | 机器学习 |
| course_2 | a1b1c1 | 机器学习 |
### 例1:匹配 courses 表的 student_id 和 students 的student_id
query = '''
SELECT courses.course_name,students.student_name
FROM courses JOIN students -- **关联方式**: JOINON courses.student_id = students.student_id -- **关联列**: courses.student_id, students.student_id-- **关联条件**: courses.student_id = students.student_id
'''### 例2:匹配 courses 表 和 students 表, 且 student_name 是 ‘小小鲸’
###
query = '''
SELECT courses.course_name,students.student_name
FROM courses JOIN students -- **关联方式**: JOINON courses.student_id = students.student_id AND students.student_name = '小小鲸' -- AND 关键词组合两个条件-- 判断条件中可以使用常量(类似 '小小鲸')
'''### 例3:匹配 courses 表 和 students 表, 且 course_name 是 机器学习 或是 数据分析
###
query = '''
SELECT courses.course_name,students.student_name
FROM courses JOIN students -- **关联方式**: JOINON courses.student_id = students.student_id AND courses.course_name in ('机器学习','数据分析')
'''✍️ 小练习 1: 用 students 和 courses 表,写出查询 student_name 为"小小鲸"或是 course_name 是"机器学习"的 SQL 语句
# ...your code...
query = '''
SELECT courses.couse_name,students.student_name
FROM courses JOIN studentsON students.student_name = '小小鲸'OR courses.course_name = '机器学习'
'''
3. 如何提升 JOIN 的效率
-
在上一部分当中,我们熟悉了基本的 JOIN 语法和不同 JOIN 达成的效果,然而现实工作当中 JOIN 的难点往往不是“如何正确地写出 SQL 语句”,而是 “如何有效提升 JOIN 的速度”,特别是在实际工作中 JOIN 多张表的情况下进行大量数据查询的时候,把握住一些简单的原则可能就会帮助你节省很多的时间。
-
需要注意的是,JOIN 的优化和效率提升可以说是数据库语言(无论是 MySQL,Postgresql 还是其他类型的 SQL)当中最重要的事情,或许没有之一。因为 JOIN 效率的高低影响的不仅仅是你我这样通过数据查询来进行数据分析/数据科学工作的人,更有可能是开发人员的工作效率和实际用户的使用体验。同时,随着“大数据时代”的道理,数据本身的存储方式和读取方式发生了相当大的变化(例如通过 HDFS+Hive 查询数据和通过 MySQL 或是教程中提到的 SQLite 就是完全不同的存储方式 )
-
因此,在互联网上有大量的材料和内容为优化各种类型的数据库语言做细致入微的介绍,同时,不同数据库语言的设计目标和想要解决的问题是不一样的
-
基于上述原则,这里我们列出能够帮助你提升 JOIN 效率 两个 大方向:
再次强调,具体的数据库语言有具体的优化细节,想要百尺竿头更进一步🎣,你可以针对自己的数据库语言了解他们在这些方向上的实现
3.1 索引,索引,索引
毫不夸张地说,索引的使用可以说是决定了 SQL JOIN 的效率的 90%,特别是对于数据分析师 / 数据科学家的需要大量通过 SQL 查询的场景,合理且熟练的使用索引就能够大幅度提升查询效率
什么是索引,根据百度百科的定义:
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息
简单来说,可以将索引理解成一本书📚的目录(很多书甚至有单独的“索引”页),当我们想要知道某个内容在第几页的时候,我们可以:
A. 一页一页地翻书直到找到我们想要的内容 ❌
B. 随便翻开书的一页,没有找到,再随便翻开一页,直到找到为止 ❌
C. 打开目录,根据目录判断你想要找的内容在哪里,直接翻到那一页 ✅
索引在 SQL JOIN 中起到的作用,就和书的目录类似,相较于需要一条一条数据去比某个关联条件是否满足,索引可以更快地帮助我们达成目标
# 快速创建一个索引
query = '''
CREATE INDEX -- CREATE INDEX: 关键字创建一个索引
IF NOT EXISTS -- IF NOT EXISTS: 如果该索引已存在,则不执行
passengerIndex -- 索引名称,
ON example_table(PassengerId) -- 索引对象,一般是某张表的某一列,形式为 table_name(column_name)
'''
result = connection.execute(query).fetchone() # 需要注意的是,CREATE INDEX 命令不会返回任何结果集
result
在 SQLite, MySQL, 和 PostgreSQL 中,创建索引的基本语法是相似的,但是可能有一些微小的差异。下面是在这三种数据库系统中创建索引的示例。
-
SQLite:
CREATE INDEX IF NOT EXISTS passengerIndex ON example_table(PassengerId);- 在 SQLite 中,您已经正确使用了
CREATE INDEX IF NOT EXISTS语法。
- 在 SQLite 中,您已经正确使用了
-
MySQL:
CREATE INDEX passengerIndex ON example_table(PassengerId);- 在 MySQL 中,
IF NOT EXISTS选项不可用于CREATE INDEX。如果索引已经存在,这将产生一个错误。
- 在 MySQL 中,
-
PostgreSQL:
CREATE INDEX IF NOT EXISTS passengerIndex ON example_table(PassengerId);- PostgreSQL 支持
IF NOT EXISTS语法,类似于 SQLite。
- PostgreSQL 支持
注意,尽管基本语法很相似,但每种数据库都有其特定的功能和限制。例如,一些数据库可能支持特定类型的索引,如全文索引或空间索引,这些在其他数据库中可能不可用或有所不同。
在编写能够跨多个数据库平台运行的代码时,务必注意这些差异。如果您使用的是 ORM(如 SQLAlchemy),它可能会提供一些抽象,使得在不同的数据库系统之间切换更加容易,但是在底层,这些差异仍然存在。
# 如果您想要执行这个 SQL 命令并检查它是否成功,您可以尝试捕捉执行过程中可能发生的任何异常。
# 例如:
try:connection.execute(query)print("索引创建成功")
except Exception as e:print("索引创建过程中出现错误:", e)索引创建成功
# 创建完成后,我们在查询的时候可以直接利用索引,无需额外的声明
query = '''
SELECT Name
FROM example_table
WHERE PassengerId = 2
'''
result = connection.execute(query).fetchone()
result
('Cumings, Mrs. John Bradley (Florence Briggs Thayer)',)
为了比较索引带来的效果提升,这里我们为 Pclass 字段创建一个索引
对比创建前后 JOIN 的执行速度
# example_table 数据观察
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | None | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | None | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | None | S |
# example_table_gb 数据观察
df_gb_pc_ct.head()
| Pclass | CabinType | Fare | Survived | |
|---|---|---|---|---|
| 0 | 1 | A | 39.623887 | 0.466667 |
| 1 | 1 | B | 113.505764 | 0.744681 |
| 2 | 1 | C | 100.151341 | 0.593220 |
| 3 | 1 | D | 63.324286 | 0.758621 |
| 4 | 1 | E | 55.740168 | 0.720000 |
# 这里我们用 100 个相同查询的查询时间来看反映查询速度的变化# 查询语句
# 统计每个 pclass 下乘客生存率的方差
query = '''
SELECT t1.Pclass,avg((t2.Survived-t1.Survived)*(t2.Survived-t1.Survived)) AS std -- 方差计算
FROM example_table_gb AS t1JOIN example_table AS t2ON t1.Pclass = t2.Pclass
GROUP BY t1.Pclass
'''
import time
# before 记录创建索引前的执行时间
before = []
for i in range(100):start_time = time.time()_ = connection.execute(query).fetchall()before.append(time.time()-start_time)
您提供的 SQL 查询旨在计算 example_table 中每个 Pclass (乘客等级)的乘客生存率的方差。这个查询涉及到两个表:example_table 和 example_table_gb。让我们逐步分析这个查询。
数据表结构
example_table:包含乘客的详细信息,如乘客ID、是否生存、乘客等级(Pclass)、姓名、性别等。example_table_gb:是一个按Pclass分组的汇总表,包含每个Pclass的平均生存率(Survived)等信息。
SQL 查询解释
查询的目标是计算每个 Pclass 的生存率的方差。方差是衡量数据分布离散程度的一个统计量。
SQL查询分几个部分:
-
SELECT t1.Pclass, ...:选择example_table_gb中的Pclass。 -
avg((t2.Survived - t1.Survived) * (t2.Survived - t1.Survived)) AS std:这是方差的计算部分。t1.Survived是example_table_gb表中每个Pclass的平均生存率,而t2.Survived是example_table表中每个乘客的生存状态(0或1)。这个表达式计算每个乘客的生存状态与其所属Pclass的平均生存率之差的平方,然后对这些平方值求平均,得到方差。 -
FROM example_table_gb AS t1 JOIN example_table AS t2 ON t1.Pclass = t2.Pclass:这部分是表的连接(JOIN)。它将example_table_gb(别名t1)和example_table(别名t2)通过Pclass字段连接起来。这意味着,对于example_table_gb中的每个Pclass记录,查询都会找到example_table中具有相同Pclass的所有记录。 -
GROUP BY t1.Pclass:这表示查询的结果将按Pclass分组,为每个Pclass计算一个方差值。
总结
简而言之,这个查询是为了找出每个乘客等级(Pclass)中乘客生存状态与该等级平均生存率之间差异的平均平方值(即方差)。这可以帮助理解不同等级乘客生存率的一致性或波动性。
# 创建索引
add_index = '''
CREATE INDEX
IF NOT EXISTS
pclassIndex
ON example_table(Pclass);'''another_index = '''
CREATE INDEX
IF NOT EXISTS
pclassGBIndex
ON example_table_gb(Pclass);
'''
_=connection.execute(add_index)
_=connection.execute(another_index)
# after 记录创建索引后的执行时间
after=[]
for i in range(100):start_time = time.time()_=connection.execute(query).fetchall()after.append(time.time()-start_time)
# 可以通过 DROP INDEX 来移除创建好的索引
drop_index = '''
DROP INDEX
pclassIndex
'''
drop_another_index = '''
DROP INDEX
pclassGBIndex
'''
_=connection.execute(drop_index)
_=connection.execute(drop_another_index)# 通过 matplotlib 看时间分布的变化
# 蓝色为加入索引后,红色为加入索引前fig, ax = plt.subplots() # 创建一个图形和一组子图轴
ax.set_xlabel('执行时间') # 设置x轴的标签为“执行时间”
ax.set_ylabel('次数') # 设置y轴的标签为“次数”
ax.set_title(r'索引效率对比') # 设置图表的标题为“索引效率对比”plt.rcParams["figure.figsize"] = (16,8) # 设置图形的大小为16x8英寸
plt.hist(before,bins =20,alpha=0.5,color='r',label='加入索引前',density=True) # 绘制一个红色的直方图,表示加入索引前的执行时间分布。bins=20 表示将数据分成20个区间,alpha=0.5 设置透明度,density=True 表示y轴显示的是密度而不是计数。
plt.hist(after,bins = 20,alpha=0.5,color='b',label='加入索引后',density=True) # 绘制一个蓝色的直方图,表示加入索引后的执行时间分布,其它设置同上。
ax.legend(loc='right') # 在图表的右侧添加图例
plt.show() # 显示最终的图表
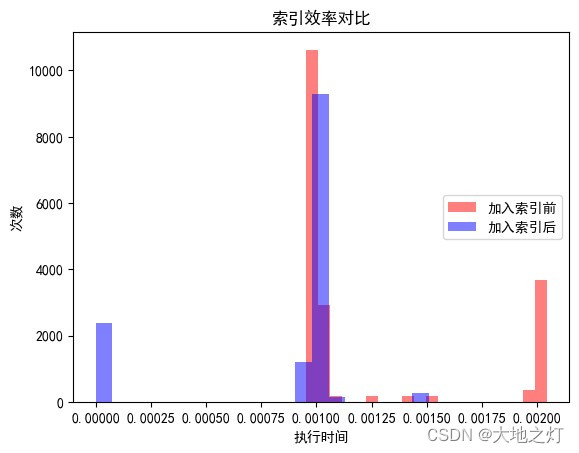
提问:循环里是记录100次的时间,为甚么图像显示次数有超过4000的情形呢
解答:您提到的问题很关键。在您的代码中,您确实记录了100次查询的执行时间,但在直方图中看到的“次数”超过了4000,这看起来不符合逻辑。原因在于您的直方图使用了 density=True 这个参数。
当 density=True 设置在 plt.hist() 函数中时,这意味着直方图显示的不是简单的计数,而是密度。换句话说,直方图的每个条形表示该区间内样本数的概率密度,而不是实际的计数。这个概率密度是这样计算的:将每个条形的计数除以总计数,然后除以条形的宽度。结果是,y轴表示的是每单位执行时间的概率密度,而不是执行次数。
如果您想要直方图显示实际的执行次数,而不是密度,您应该将 density 参数设置为 False 或者完全不设置这个参数(默认为 False)。这样,每个条形的高度将表示在那个执行时间区间内的查询次数。
修改后的代码应该是这样的:
plt.hist(before, bins=20, alpha=0.5, color='r', label='加入索引前', density=False)
plt.hist(after, bins=20, alpha=0.5, color='b', label='加入索引后', density=False)
使用这个设置,您的直方图将直接反映在每个时间区间内的查询次数,这应该与您记录的100次执行时间相匹配。
# 通过 matplotlib 看时间分布的变化
# 蓝色为加入索引后,红色为加入索引前fig, ax = plt.subplots() # 创建一个图形和一组子图轴
ax.set_xlabel('执行时间') # 设置x轴的标签为“执行时间”
ax.set_ylabel('次数') # 设置y轴的标签为“次数”
ax.set_title(r'索引效率对比') # 设置图表的标题为“索引效率对比”plt.rcParams["figure.figsize"] = (16,8) # 设置图形的大小为16x8英寸
plt.hist(before,bins =20,alpha=0.5,color='r',label='加入索引前',density=False) # 绘制一个红色的直方图,表示加入索引前的执行时间分布。bins=20 表示将数据分成20个区间,alpha=0.5 设置透明度,density=False 表示y轴显示的是计数。
plt.hist(after,bins = 20,alpha=0.5,color='b',label='加入索引后',density=False) # 绘制一个蓝色的直方图,表示加入索引后的执行时间分布,其它设置同上。
ax.legend(loc='right') # 在图表的右侧添加图例
plt.show() # 显示最终的图表
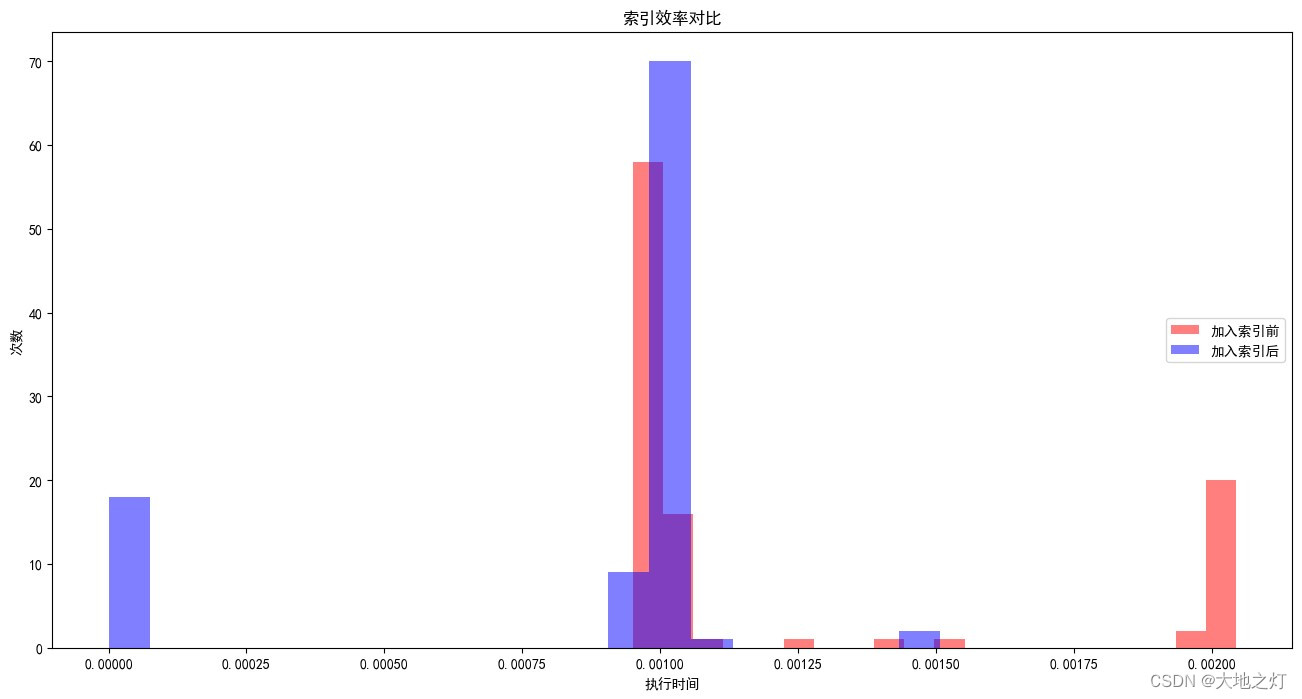
可以比较直观的发现,在引入索引后,整个语句的执行效率有了一个明显的提升,这得益于所以帮助加快了两张表的匹配和聚合的效率,当然对于我们当前所用的 Titanic 数据集而言,这个提升可能是从 0.1s 到 0.08s,但是对于体量更大或是复杂度更高的查询,哪怕是 20% 的效率的提升也可以轻松节约大量的时间
看到上图的效率提升,你可能会纳闷 既然索引有这么强的效果,为什么不把所有的列都加上索引呢?
还是用上文提到的翻书找内容为例子,容易被忽略的一个点是: 在目录上查找也是需要花时间的 !
特别是,如果书本身很薄或是目录本身过于复杂,那么直接翻书可能效率可能会更高 ,相对应的,当数据体量本身不够多,索引本身过于复杂(想象一下如果一本书的目录上每 2 页就有一条记录)
✍️ 小练习 2:参考上面的代码,尝试将 query 修改成其他 JOIN 语句,观察一下图的变化。
# ...your code...
# 略
虽然索引在效率提升上有着相当大的优势,但可惜的是,大部分时候创建索引的权力并不在我们身上(除非你也是身兼数据工程师),往往 IT 或是数据团队给到的索引列表就是我们能用到的,因此我们需要确保自己能拿到的索引要确实的用上
下面给出 2 个使用索引的好习惯,还是需要再次提醒,SQLlite 本身对于索引是有优化的,因此下面的内容更像是个人习惯上的建议:
# 1. 尽可能避免对于可索引字段进行“转化”
# “转化”包括但不限于:进行额外运算,加入函数变化,类型变化等
# 例如:若 t1.Pclass 是一个有索引的字段
query = '''
SELECT t1.Pclass,avg((t2.Survived-t1.Survived)*(t2.Survived-t1.Survived)) AS std -- 方差计算
FROM example_table_gb AS t1JOIN example_table AS t2
-- ON t1.Pclass + 1 - 1 = t2.Pclass -- ❌
-- ON t1.Pclass - t2.Pclass = 0 -- ❌
-- ON INT(t1.Pclass) = INT(t2.Pclass) -- ❌
-- ON t1.Pclass = t2.Pclass -- ✅GROUP BY t1.Pclass
'''# 2. 在 WHERE 当中慎重使用 OR 或相关表达式
# 确保 OR 语句当中的每个字段都有索引
# 尽可能避免对于索引列进行 模糊匹配(本质上是一个精炼版的 OR)
# 例如:若 t1.Pclass 和 t1.Name 是有索引的字段
query = '''
SELECT t1.Pclass
FROM example_table_gb AS t1
WHERE
-- t1.Pclass = 1 OR t1.Survived = 1 -- ❌
-- t1.Name LIKE 'John%' -- ❌
-- t1.Pclass = 1 OR t1.Name = 'John' -- ✅'''3.2 谓词下推:先过滤,后计算
谓词下推 (predicate pushdown)是一个比较专业的表达,一个比较宽泛的定义可以是:
将查询语句中具有过滤性质的表达式尽可能下推到距离数据源最近的地方,方便查询在执行时尽早完成数据的过滤,进而显著地减少数据传输或计算的开销
还是以本教程中的翻书找内容为例,假设我们需要从一架子的书中找到某个具体章节或是某些具体的内容
A. 将架子上的所有书拿下来,一本一本地翻开查找 ❌
B. 将架子上的所有书拿下来,找到其中一本相关的数据,地翻开查找 ❌
C.通过书脊上的标题/书本的样式判断哪本书可能是需要的,拿下来翻开查找 ✅
对于 JOIN 操作而言,这个表达的含义就是“尽可能将筛选的语句放在 ON 语句后,而不是 WHERE 语句上”,特别是对于 LEFT JOIN 和 RIGHT JOIN
# ✅ 推荐
query_ppd = '''
SELECT t1.Pclass,t1.Survived,t2.Survived
FROM example_table AS t1JOIN example_table AS t2ON t1.Pclass < t2.Pclass AND t1.Pclass = 1 -- 下推
'''# ⭕ 不推荐
query_no_ppd = '''
SELECT t1.Pclass,t1.Survived,t2.Survived
FROM example_table AS t1JOIN example_table AS t2ON t1.Pclass = 1
WHERE t1.Pclass < t2.Pclass -- 没有下推
'''ppd=[]
for i in range(100):start_time = time.time()_=connection.execute(query_ppd).fetchall()ppd.append(time.time()-start_time)no_ppd=[]
for i in range(100):start_time = time.time()_=connection.execute(query_no_ppd).fetchall()no_ppd.append(time.time()-start_time)# 通过 matplotlib 看时间分布的变化
# 蓝色为加入谓词下推,红色为不加入fig, ax = plt.subplots()
ax.set_xlabel('执行时间')
ax.set_ylabel('次数')
ax.set_title(r'下推效率')plt.rcParams["figure.figsize"] = (16,8)
plt.hist(no_ppd,bins =20,alpha=0.5,color='r',label='不做谓词下推')
plt.hist(ppd,bins = 20,alpha=0.5,color='b',label='谓词下推')
ax.legend(loc='right')
plt.show()
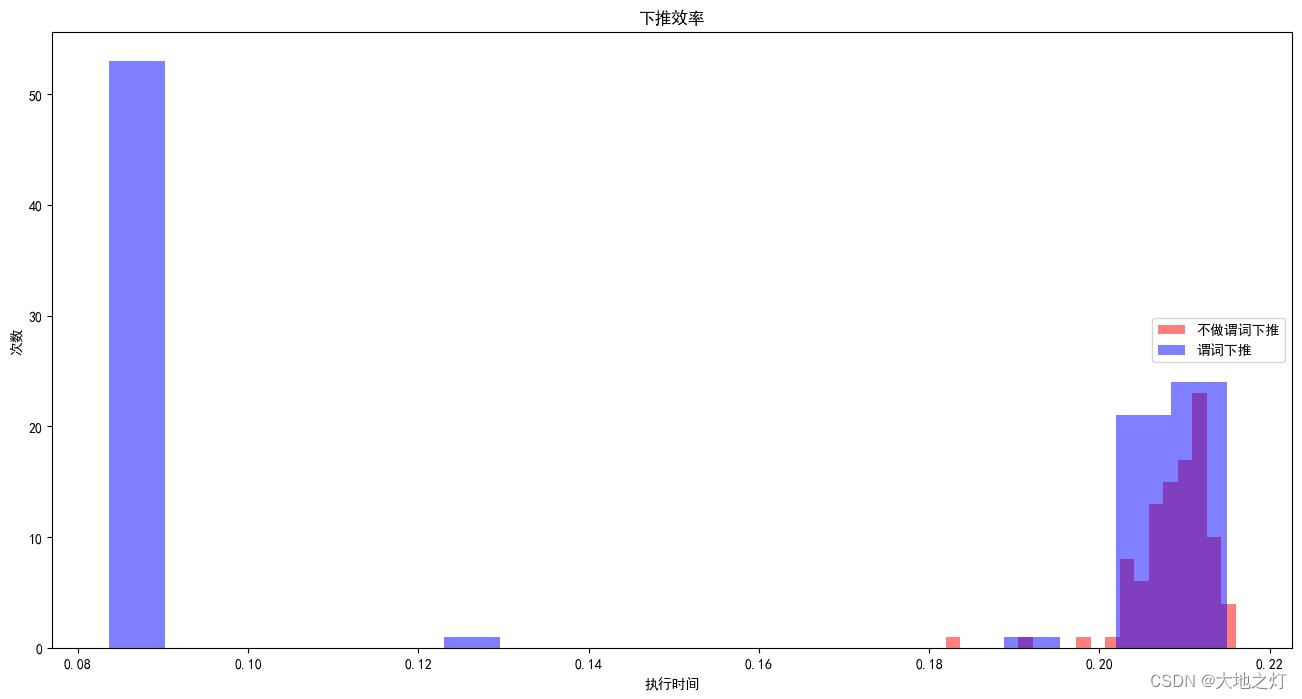
你可能发现,在这里使用谓词下推的效果并不显著(相较于加入索引而言),这是因为 SQLite 语句已经在会在执行语句的时候帮助你做下推的动作
同索引一样,谓词下推也不是总是有效的:
一方面,部分数据库实现了自动谓词下推的特性;
另一方面,对于一些语句(例如 INNER JOIN),谓词下推可能是没有额外收益的。
相较与 3.1 中使用索引,谓词下推或是其背后所代表的“先过滤,再计算”更像是一种“理念” 而非应用技巧,甚至可以说,索引的存在本身也是这一理念的产物。
和谓词下推相关的一些好习惯还有
# 1. 在任何场景下,尽力【避免】使用 *
# 例如 SELECT *, COUNT(*)
# 使用 * 意味着返回全量数据
query = '''
SELECT * -- ⭕
SELECT t1.Name,t1.Pclass,... -- ✅
FROM example_table AS t1
'''# 2. 使用子查询或视图减少参与 JOIN 的数据量
# 关于子查询,视图的用法详见后续的教程
# ⭕ 不推荐
query = '''
SELECT *
SELECT t1.Name,t1.Pclass,t2.CabinType
FROM example_table AS t1JOIN example_table_gb AS t2ON t1.Pclass = t2.Pclass
WHERE t1.PassengerId > 10
'''# ✅ 推荐
query = '''
SELECT t3.Name,t3.Pclass,t2.CabinType
FROM (SELECT t1.Name,t1.PclassFROM example_table AS t1WHERE t1.PassengerId > 10) AS t3JOIN example_table_gb AS t2ON t3.Pclass = t2.Pclass
'''# 3. 使用 CTE (Common Table Entity)
# 关于 CTE 的用法详见后续的教程# ✅ 推荐
query = '''
WITH t3 AS
(SELECT t1.Name,t1.Pclass
FROM example_table AS t1
WHERE t1.PassengerId > 10)
SELECT t3.Name,t3.Pclass,t2.CabinType
FROM t3JOIN example_table_gb AS t2ON t3.Pclass = t2.Pclass
'''
4. 小结 🥡
在本教程中,我们熟悉了 JOIN 的常见用法,并且介绍了 4 种基础的 JOIN (不同的语言有着更加多种多样的 JOIN 类型,可以自行前往查阅),他们分别是:
-
INNER JOIN
-
LEFT JOIN (RIGHT JOIN)
-
FULL OUTER JOIN
-
CROSS JOIN
同时我们介绍两个能够帮助我们在日常的工作中优化的 SQL join 的方向,分别是:
-
妥善使用索引
-
积极使用谓词下推
依然需要强调的是,在当今数据库产品的如此丰富的生态下,大部分的 SQL 语言已经在 JOIN 这个关键点上做了相当多的优化了,甚至部分的优化完全依赖于数据库的自动优化器而不需要我们手动书写 *(例如,本章没有写到的 JOIN 顺序调整,在大部分的数据库中是自动优化好的)
因此提供相较于纯粹的知识输入和技能培养,我更希望你在本关结束后能够 形成更加良好的 SQL 书写习惯,而这也是这个训练营的核心公式:
良好的习惯 + 知识 / 技能的储备 + 大量的练习 = S Q L 的进一步提升 良好的习惯 + 知识/技能的储备 + 大量的练习 = SQL 的进一步提升 良好的习惯+知识/技能的储备+大量的练习=SQL的进一步提升
希望你有所收获 🥂
闯关题
STEP1:根据要求完成题目:
Q1:假设 A 表有 5条数据,B 表有 4条数据,两张表有一共享的 id 列。下列哪种 JOIN 可能产生的数据结果最多
# ...your code...
a1 = 'C' # 在 = 后面填入你的结果,如 a1 = 'A'
Q2:假设 A 表有 5条数据,B 表有 4条数据,两张表有一共享的 id 列。下列哪种 JOIN 可能产生的数据结果最少
# ...your code...
a2 = 'D' # 在 '' 中填入你的结果,如 a2 = 'A'
Q3:下面哪个可能是 SQL JOIN 查询慢的原因
# ...your code...
a3 = 'D' # 在 '' 中填入你的结果,如 a3 = 'A'
Q4:代码参考了 3.1 中计算乘客生存率方差的语句,我们希望按照 CabinType 来统计乘客生存率方差:
query = '''
SELECT t1.CabinType,avg((t2.Survived-t1.Survived)*(t2.Survived-t1.Survived)) AS std -- 方差计算
FROM example_table_gb AS t1
/*
MISSING CODE
*/
GROUP BY t1.CabinType
'''
默认 Cabin 和 CabinType 字段都添加了索引 的情况下,下面哪段代码替换 /* MISSING CODE * / 可以实现 JOIN 的效率的最优
# A.
MISSING_CODE = '''
JOIN example_table AS t2ON t1.CabinType = t2.Cabin
'''# B.
MISSING_CODE = '''
JOIN example_table AS t2ON t1.CabinType = substr(t2.Cabin,0,1) -- substr 函数可以获取第一个字母
'''# C.
MISSING_CODE = '''
JOIN example_table AS t2ON t1.CabinType LIKE t2.Cabin -- LIKE 函数可以进行模糊匹配
'''# D.
MISSING_CODE = '''
JOIN (SELECT substr(Cabin,0,1) AS ctype,SurvivedFROM example_table) AS t2ON t1.CabinType = t2.ctype
'''# ...your code..a4 = 'D' # 在 '' 中填入你的结果,如 a4 = 'A'
STEP2:将结果保存为 csv 文件
csv 需要有两列,列名:id、answer。其中,id 列为题号,如 q1、q2;answer 列为 STEP1 中各题你计算出来的结果。💡 这一步的代码你无需修改,直接运行即可。
# 生成 csv 作业答案文件
def save_csv(answers):import pandas as pdif len(answers)!=4:raise Exception("请检查你的答案数列中是否包含了 4 道题的答案。\n")df = pd.DataFrame({"id": ["q1","q2","q3","q4"], "answer": answers})df.to_csv("answer_workflow_1_3.csv", index=None)
save_csv([a1,a2,a3,a4]) # 该csv文件在左侧文件树project工作区下,你可以自行右击下载或者读取查看