1. 初识Jedis
Jedis的官网地址:https://github.com/redis/jedis
1.1 快速入门
使用步骤:
注意:如果是云服务器用户使用redis需要先配置防火墙!
-
引入maven依赖
<dependencies><!-- 引入Jedis依赖 --><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>5.0.0</version></dependency><!-- 引入单元测试 --><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.10.1</version><scope>test</scope></dependency> </dependencies> -
建立连接
@BeforeEach void setUp() {jedis = new Jedis("114.55.236.21:22", 6379);jedis.auth("123456");jedis.select(0); } -
测试String类的方法
@Test void testString() {// 1. 尝试set方法jedis.set("name", "wjj");// 2. 尝试get方法String name = jedis.get("name");System.out.println(name); } -
释放连接
@AfterEach void tearDown() {if (jedis != null) {jedis.close();} }
运行结果:


2. 使用Jedis连接池
由于Jedis是线程不安全的,并且频繁创建销毁线程具有很大开销,因此我推荐使用连接池的方式使用Jedis
使用步骤:
-
使用连接池创建连接工厂类
/*** 基于连接池实现连接工厂类*/ public class JedisConnectionFactory {private static final JedisPool jedisPool;static {// 1. 创建连接池配置JedisPoolConfig config = new JedisPoolConfig();config.setMaxTotal(8); // 最大连接数config.setMaxIdle(8); // 最大空闲连接数config.setMinIdle(0); // 最小空闲连接数config.setMaxWaitMillis(200); // 最长等待时间// 2. 创建JedisPool连接池jedisPool = new JedisPool(config, "114.55.236.21", 6379, 1000, "123456");}public static Jedis getConnection() {return jedisPool.getResource();} } -
编写测试类测试Hash类型方法
public class TestJedisPool {private Jedis jedis;@BeforeEachvoid setUp() {jedis = JedisConnectionFactory.getConnection();}@Testvoid testHash() {// 1. 使用hset方法jedis.hset("user:1", "name", "rice");jedis.hset("user:1", "age", "22");// 2. 使用hgetAll方法Map<String, String> map = jedis.hgetAll("user:1");System.out.println(map);}@AfterEachvoid tearDown() {if (jedis != null) {jedis.close();}} }
运行结果:


2. 使用SpringBoot整合Redis
现在基于SpringBoot整合Redis已经成为企业的标配,其中SpringDataRedis就是专门用来操作Redis的集成模块,其具有以下特点:
- 提供了对不同客户端的整合,比如Jedis和Lettuce
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis的哨兵和集群
- 支持Lettuce的响应式编程
- 支持基于JDK、JSON、String等对象的序列化和反序列化
- 支持基于Redis的JDKCollection实现
2.1 SpringDataRedis快速入门
使用步骤:
-
引入maven依赖
<!-- redis依赖 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!-- 连接池依赖 --> <dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.11.1</version> </dependency> -
在
application.yml中配置相关参数# 配置redis spring:data:redis:host: 114.55.236.21port: 6379password: 123456lettuce:pool:max-active: 8max-idle: 8min-idle: 0max-wait: 200由于Spring官方默认使用lettuce作为客户端,因此如果想要使用Jedis的配置,还需要引入Jedis的maven依赖
-
在测试类中自动装配RedisTemplate对象
@Autowired private RedisTemplate redisTemplate; -
创建测试类测试redisTemplate的使用
@SpringBootTest class SpringDataRedisDemoApplicationTests {@Resourcepublic RedisTemplate redisTemplate;@Testpublic void testString() {System.out.println(redisTemplate);// 1. 存入String类型数据redisTemplate.opsForValue().set("id", "1");// 2. 取出String类型数据Object id = redisTemplate.opsForValue().get("id");System.out.println(id);}}
运行结果:


但是我们发现其中插入了一个\xac\xed\x00\x05t\x00\x02id这样不知名的key,但是貌似是我们在代码中插入的key值id,但是怎么会以这样的方式呈现呢?

我们追溯源码可以发现RedisTemplate中使用默认的序列化器就是JDK序列化器,其接收Object类型参数并转换成字节数组存入Redis中,但是我们发现具有以下问题:
- 可读性差
- 内存占用较大
因此我们更加建议使用String类型序列化器作为keySerializer,而使用JSON序列化器作为valueSerializer
2.2 使用自定义序列化器
使用步骤:
-
创建Redis配置类
RedisConfig.java@Configuration public class RedisConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();// 设置连接工厂redisTemplate.setConnectionFactory(connectionFactory);// 设置序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// key和hashKey使用StringSerializerredisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setHashKeySerializer(RedisSerializer.string());// value和hashValue使用GenericJackson2JsonRedisSerializerredisTemplate.setValueSerializer(jsonRedisSerializer);redisTemplate.setHashValueSerializer(jsonRedisSerializer);return redisTemplate;} } -
编写测试类
TestJsonSerializer.java@SpringBootTest public class TestJsonSerializer {@Autowiredprivate RedisTemplate<String, Object> redisTemplate;@Testpublic void testJsonSerializer() {// 存放idredisTemplate.opsForValue().set("id", "2");// 取出idObject id = redisTemplate.opsForValue().get("id");System.out.println(id);} }
如果出现如下异常(莫慌,这是正常的!):

只要引入如下依赖即可:
<!-- 引入jackson-databind依赖 -->
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.14.1</version>
</dependency>
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.14.1</version>
</dependency>
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-annotations</artifactId><version>2.14.1</version>
</dependency>
运行结果:


此时可以发现id正常显示!
但是如果我们尝试将value设置为Java的对象,就会出现一定问题:
使用步骤:
-
创建pojo包下的实体类
User.java@Data @NoArgsConstructor @AllArgsConstructor public class User {private Integer id;private String name;private Integer age; } -
在测试类中新增测试方法
@Test public void testJsonObjectSerializer() {// 创建User类对象User user = new User(1, "zhangsan", 22);// 存放User对象redisTemplate.opsForValue().set("user:1", user);// 取出User对象User getUser = (User) redisTemplate.opsForValue().get("user:1");System.out.println(getUser); }
上述方法尝试将一个User类对象作为value,由于之前我们自定义了value的序列化器为JSON序列化器,因此其内部会自动进行序列化和反序列化
运行结果:

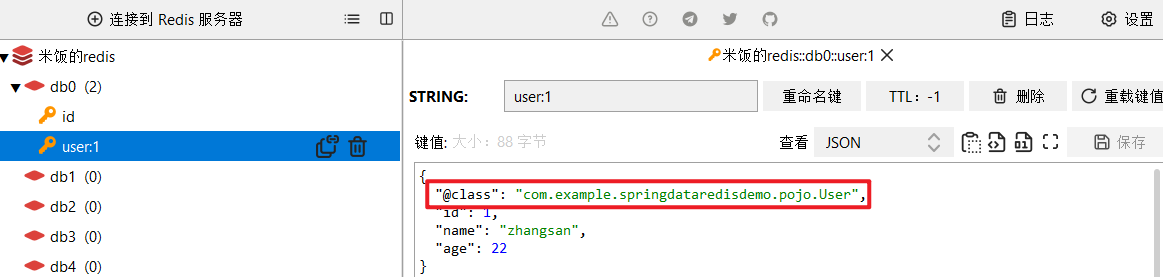
我们需要重点关注其中的@class的字段内容,不难发现,RedisTemplate自动进行序列化和反序列化的依据就是利用Java的反射机制,因此需要保存类信息,但是这也引入了一个严重的问题:
- 如果有上千万的数据量,每条信息都需要保存对应的类信息,会极大浪费内存空间!
因此我们还是建议使用手动序列化的方式进行存取!
2.3 手动序列化
使用步骤:
-
引入JSON工具依赖
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.35</version> </dependency> -
编写测试类手动序列化
@Test public void testMyJSON() {// 1. 创建User对象User user = new User(2, "lisi", 22);// 2. 手动序列化为JSON格式数据String jsonString = JSONObject.toJSONString(user);redisTemplate.opsForValue().set("user:2", jsonString);// 3. 取出数据并手动序列化为User对象String userJSONString = (String) redisTemplate.opsForValue().get("user:2");User toUser = JSONObject.parseObject(userJSONString, User.class);System.out.println(toUser); }
运行结果:


此时我们就实现了手动序列化的方式存储Java对象,一切大功告成!