目录
1. 实战内容
2、Ajax 分析
3、爬取内容
4、存入MySQL 数据库
4.1 创建相关表
4.2 数据插入表中
5、总代码与结果
1. 实战内容
爬取Scrape | Movie的所有电影详情页的电影名、类别、时长、上映地及时间、简介、评分,并将这些内容存入MySQL数据库中。
2、Ajax 分析
根据上一篇文章5.1 Ajax数据爬取之初介绍-CSDN博客,找到详情页的数据包,如下:
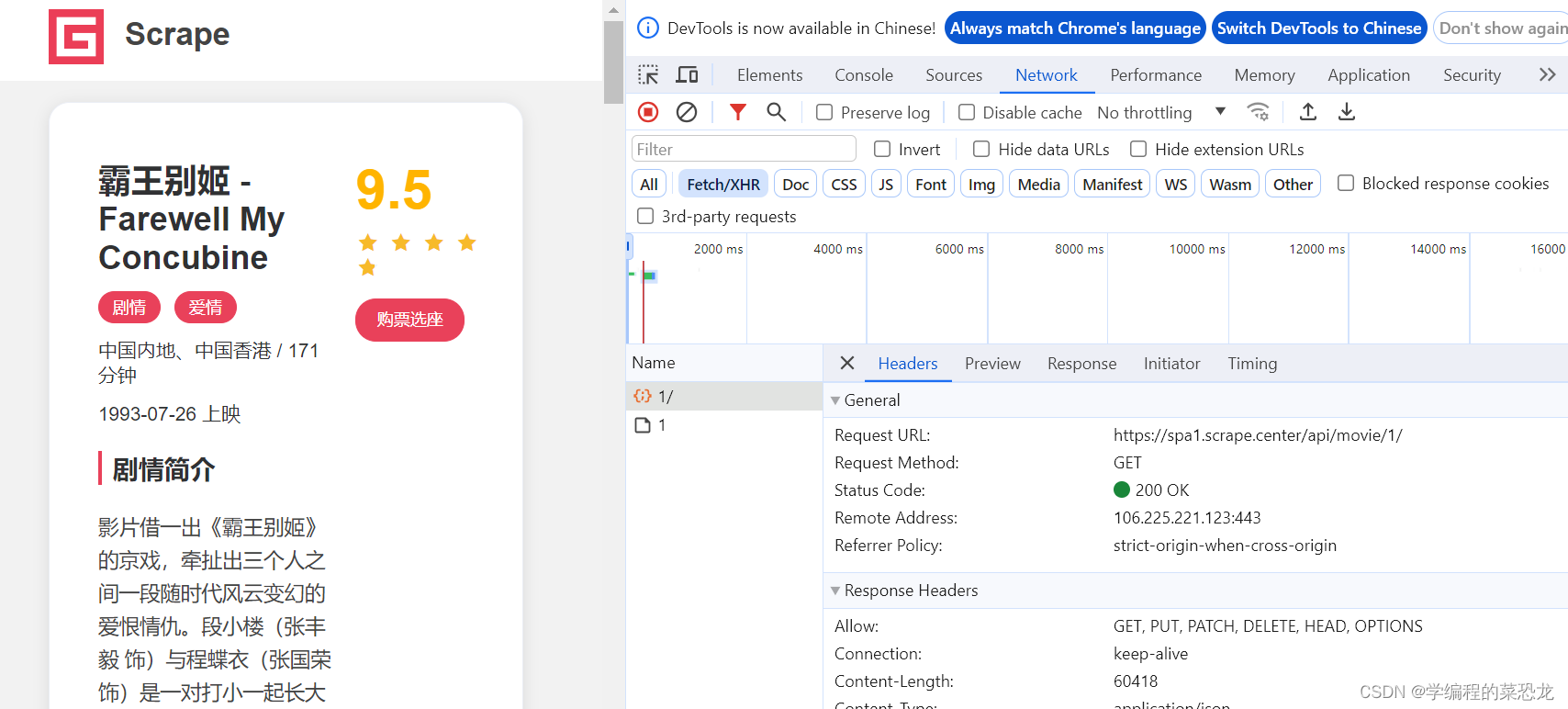
根据数据包,会发现其中 Response中有我们想要的内容。查看其及其他页的Request URL,发现其规律,只需改变后面的数字,构造链接,即可一一爬取信息。
Response中想要的内容如下(为Response部分内容截图):


等等,不难发现此内容以字典的形式呈现在我们眼前。
3、爬取内容
所以用 eval() 将字符串形式的 content 转换为字典,方便提取信息。将提取的信息汇合成字典,便于传递、存入MySQL数据库。
在爬取的过程中,会发现一些电影数据不完整,会造成错误使得程序崩溃,所以使用try...except...去避免。
import requestsdef crawler(url):response = requests.get(url)content = response.textcontent = eval(content)name = content['name']alias = content['alias'] # 外文名categories = content['categories']cate = ','.join(categories) # 电影种类regions = content['regions']region = ','.join(regions) # 地点publish_time = content['published_at']score = content['score']minute = content['minute'] # 时长drama = content['drama']# print(name, alias, cate, region, publish_time, score, minute, drama)movie_dict = {'name': name,'alias': alias,'cate': cate,'region': region,'publish_time':publish_time,'minute': minute,'score': score,'drama': drama}print(movie_dict)if __name__ == '__main__':last = 100for i in range(1, last+1):url = f'https://spa1.scrape.center/api/movie/{i}/'try:crawler(url)except NameError:print(f'链接{url}数据不完整')
以第一个详情页为例子展现输出结果:

之后,我们可以根据结果存入MySQL数据库。
4、存入MySQL 数据库
4.1 创建相关表
要存入数据库前,要根据字典的键创建相关表,之后才能存入表中。创建表可以在爬取数据之前创建,不需要每次循环创建一次。
相关代码见 create_table() 函数,**mysql_local 用法见上一篇文章5.1 Ajax数据爬取之初介绍-CSDN博客
def creat_table():conn = pymysql.connect(**mysql_local)cursor = conn.cursor()sql = ('CREATE TABLE IF NOT EXISTS movie(id INT AUTO_INCREMENT PRIMARY KEY,''name VARCHAR(100) ,''alias VARCHAR(100) ,''cate VARCHAR(100) ,''region VARCHAR(100) ,''publish_time DATE,''minute VARCHAR(100),''score VARCHAR(100),''drama TEXT)') # 文本内容cursor.execute(sql)conn.close()sql语句创建表具体可见4.4 MySQL存储-CSDN博客
4.2 数据插入表中
使用 insert_movie() 函数插入字典数据,具体解析可见4.4 MySQL存储-CSDN博客
def insert_movie(movie_dict):conn = pymysql.connect(**mysql_local)cursor = conn.cursor()keys = ','.join(movie_dict.keys())values = ','.join(['%s'] * len(movie_dict))sql = f'INSERT INTO movie({keys}) VALUES ({values})'# print(sql)# print(tuple(movie_dict.values()))cursor.execute(sql, tuple(movie_dict.values()))conn.commit()conn.close()
5、总代码与结果
import requests
import pymysql
from mysql_info import mysql_localdef creat_table():conn = pymysql.connect(**mysql_local)cursor = conn.cursor()sql = ('CREATE TABLE IF NOT EXISTS movie(id INT AUTO_INCREMENT PRIMARY KEY,''name VARCHAR(100) ,''alias VARCHAR(100) ,''cate VARCHAR(100) ,''region VARCHAR(100) ,''publish_time DATE,''minute VARCHAR(100),''score VARCHAR(100),''drama TEXT)')cursor.execute(sql)conn.close()def insert_movie(movie_dict):conn = pymysql.connect(**mysql_local)cursor = conn.cursor()keys = ','.join(movie_dict.keys())values = ','.join(['%s'] * len(movie_dict))sql = f'INSERT INTO movie({keys}) VALUES ({values})'# print(sql)# print(tuple(movie_dict.values()))cursor.execute(sql, tuple(movie_dict.values()))conn.commit()conn.close()def crawler(url):response = requests.get(url)content = response.textcontent = eval(content)# id = content['id']name = content['name']alias = content['alias'] # 外文名categories = content['categories']cate = ','.join(categories)regions = content['regions']region = ','.join(regions)publish_time = content['published_at']score = content['score']minute = content['minute']drama = content['drama']# print(name, alias, cate, region, publish_time, score, minute, drama)movie_dict = {# 'id': id,'name': name,'alias': alias,'cate': cate,'region': region,'publish_time':publish_time,'minute': minute,'score': score,'drama': drama}# print(movie_dict)insert_movie(movie_dict)if __name__ == '__main__':creat_table()last = 100for i in range(1, last+1):url = f'https://spa1.scrape.center/api/movie/{i}/'try:crawler(url)except NameError:print(f'链接{url}数据不完整')
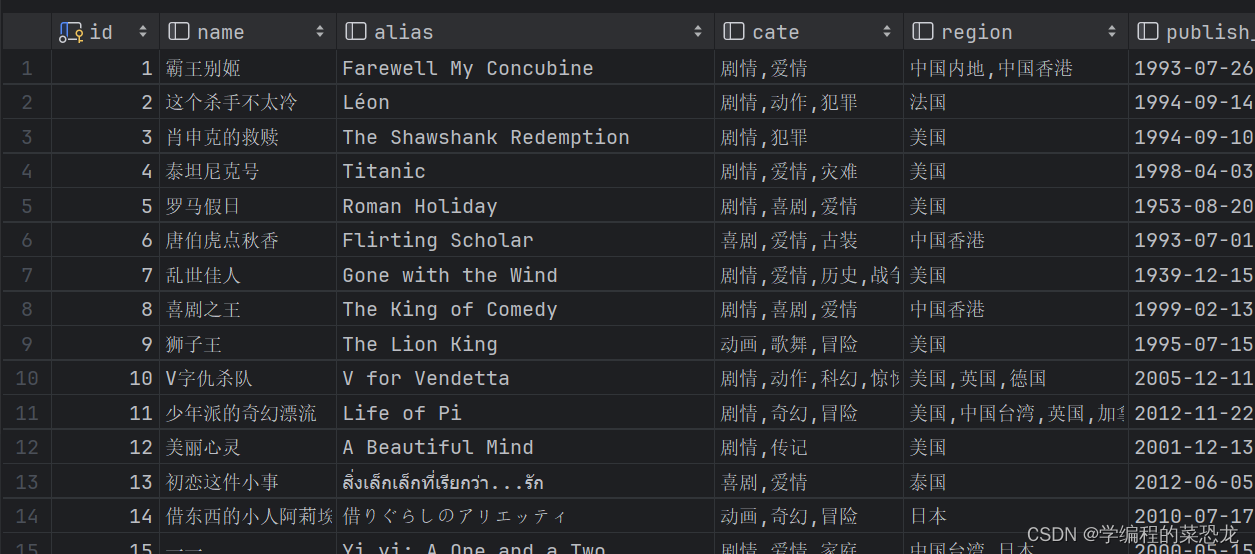
mysql数据库部分内容:
本人新手,若有错误,欢迎指正;若有疑问,欢迎讨论。若文章对你有用,点个小赞鼓励一下,谢谢,一起加油吧!