传奇开心果博文系列
- 系列博文目录
- python文本和语音相互转换库技术点案例示例系列
- 博文目录
- 前言
- 一、雏形示例代码
- 二、扩展思路介绍
- 三、SpeechRecognition库多种语音识别引擎支持示例代码
- 四、SpeechRecognition库实时语音转录示例代码
- 五、SpeechRecognitio库转录文本中提取关键词和生成摘要示例代码
- 六、SpeechRecognitio库语音情绪识别示例代码
- 七、SpeechRecognitio库语音搜索和标记示例代码
- 八、SpeechRecognitio库用户身份识别示例代码
- 九、SpeechRecognitio库数据可视化处理示例代码
- 十、SpeechRecognitio库多语言支持示例代码
- 十一、SpeechRecognitio库自定义词汇表示例代码
- 十二、SpeechRecognitio库自动化会议记录整理示例代码
- 十三、SpeechRecognition库与日历集成示例代码
- 十四、SpeechRecognitio库安全和隐私保护示例代码
- 十五、SpeechRecognitio库跨平台支持示例代码
- 十六、SpeechRecognitio库自动语音翻译示例代码
- 十七、归纳总结
系列博文目录
python文本和语音相互转换库技术点案例示例系列
博文目录
前言

 使用
使用SpeechRecognition库可以很方便地开发一个会议记录和转录工具,将会议录音转换为文本,方便会议记录和后续参考。
一、雏形示例代码
 以下是一个简单的示例代码,演示如何使用
以下是一个简单的示例代码,演示如何使用SpeechRecognition库来开发一个会议记录和转录工具:
import speech_recognition as sr# 定义音频文件路径
audio_file = "meeting_audio.wav"# 初始化语音识别器
recognizer = sr.Recognizer()# 读取音频文件
with sr.AudioFile(audio_file) as source:audio_data = recognizer.record(source)# 使用Google Web Speech API进行语音识别try:text = recognizer.recognize_google(audio_data, language="en-US")print("会议内容转录:")print(text)except sr.UnknownValueError:print("无法识别音频内容")except sr.RequestError as e:print("无法连接到Google Web Speech API: {0}".format(e))
在这个示例中,我们首先指定了音频文件的路径audio_file,然后使用SpeechRecognition库中的Recognizer类来初始化一个语音识别器。接着,我们使用AudioFile对象读取音频文件,并使用recognize_google方法将音频内容转换为文本。最后,我们打印转录的会议内容。
请注意,这个示例使用的是Google Web Speech API进行语音识别,你也可以尝试其他语音识别引擎,如CMU Sphinx等,根据你的需求选择合适的引擎。另外,确保你的音频文件格式受到支持,以便正确识别音频内容。
通过这样一个简单的示例代码,你可以轻松地开发一个会议记录和转录工具,将会议录音转换为文本,方便会议记录和后续参考。
二、扩展思路介绍
 当开发会议记录和转录工具时,可以进一步扩展功能和思路,使工具更加强大和实用。以下是一些扩展思路:
当开发会议记录和转录工具时,可以进一步扩展功能和思路,使工具更加强大和实用。以下是一些扩展思路:
-
多种语音识别引擎支持:除了Google Web Speech API,可以集成其他语音识别引擎,如CMU Sphinx、Microsoft Azure Speech等,以提供更多选择和灵活性。
-
实时语音转录:实时将会议中的讲话内容转录为文本,可以提供实时记录和参与者查看,有助于更好地参与讨论和决策。
-
关键词提取和自动摘要:利用自然语言处理技术,从转录文本中提取关键词、生成摘要,帮助用户快速了解会议内容的重点和要点。
-
语音情绪识别:结合情感分析技术,识别讲话者的情绪,帮助更好地理解会议氛围和参与者情绪,为会议后续处理提供更多信息。
-
语音搜索和标记:为转录文本添加搜索功能,让用户可以通过关键词搜索特定内容,同时支持用户标记重要内容,方便后续回顾和整理。
-
用户身份识别:通过语音识别技术识别讲话者的身份,可以帮助记录讲话者对应的发言内容,提高记录的准确性和可读性。
-
数据可视化:将会议内容转录结果进行数据可视化处理,生成图表、词云等形式,直观展示会议讨论的主题和重点,帮助用户更好地理解会议内容。
-
多语言支持:考虑到不同会议可能使用不同语言进行交流,可以增加多语言支持功能,使工具能够识别和转录多种语言的内容。
-
自定义词汇表:允许用户自定义词汇表,特别是包含特定行业术语或公司内部名词,以提高识别准确性。
-
自动化会议记录整理:将会议记录整理为结构化的格式,包括议题、决策、行动项等信息,方便后续跟进和执行。
-
与日历集成:将会议记录与日历应用程序集成,自动创建会议事件并附带转录内容,方便日程管理和回顾。
-
安全和隐私保护:确保转录内容的安全性和隐私保护,采取适当的数据加密和访问控制措施,符合相关法规和标准。
-
跨平台支持:开发跨平台的应用程序,支持在不同设备上使用,如PC、平板电脑和手机,以便用户随时随地访问会议记录。
-
自动语音翻译:结合机器翻译技术,实现将转录内容自动翻译为其他语言,方便跨语言交流和合作。
通过这些扩展思路,可以使会议记录和转录工具更加智能化、实用化,提高用户体验和工作效率。根据实际需求和用户反馈,不断优化和完善工具功能,让其成为会议记录和管理的有力助手。
三、SpeechRecognition库多种语音识别引擎支持示例代码
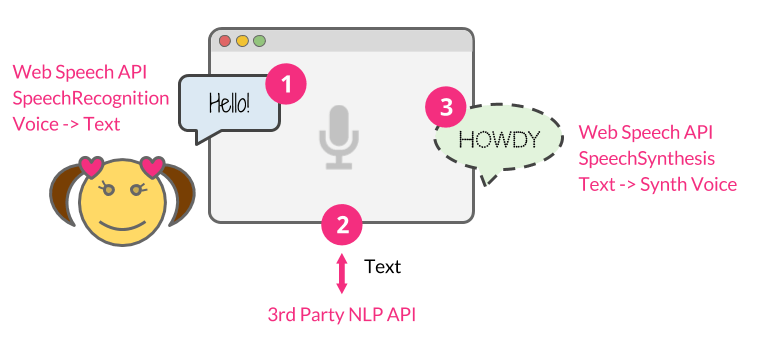 在Python中,您可以使用
在Python中,您可以使用SpeechRecognition库来集成多种语音识别引擎。下面是一个示例代码,演示如何使用SpeechRecognition库结合Google Web Speech API、CMU Sphinx和Microsoft Azure Speech来识别语音:
import speech_recognition as sr# 创建一个Recognizer对象
recognizer = sr.Recognizer()# 音频文件路径
audio_file = "path/to/audio/file.wav"# 使用Google Web Speech API进行语音识别
with sr.AudioFile(audio_file) as source:audio_data = recognizer.record(source)google_text = recognizer.recognize_google(audio_data)print("Google Web Speech API识别结果:", google_text)# 使用CMU Sphinx进行语音识别
with sr.AudioFile(audio_file) as source:audio_data = recognizer.record(source)sphinx_text = recognizer.recognize_sphinx(audio_data)print("CMU Sphinx识别结果:", sphinx_text)# 使用Microsoft Azure Speech进行语音识别
azure_key = "YOUR_AZURE_KEY"
with sr.AudioFile(audio_file) as source:audio_data = recognizer.record(source)azure_text = recognizer.recognize_azure(audio_data, key=azure_key)print("Microsoft Azure Speech识别结果:", azure_text)
在这个示例中,您需要替换"path/to/audio/file.wav"为实际的音频文件路径,并且在使用Microsoft Azure Speech时,需要替换"YOUR_AZURE_KEY"为您的Azure密钥。
请注意,使用不同的语音识别引擎可能需要相应的API密钥或设置,具体取决于每个引擎的要求。您需要根据实际情况进行相应的更改和配置。
四、SpeechRecognition库实时语音转录示例代码
 要实现实时语音转录,您可以结合
要实现实时语音转录,您可以结合SpeechRecognition库和麦克风输入来实现。以下是一个示例代码,演示如何实时将麦克风输入转录为文本:
import speech_recognition as sr# 创建一个Recognizer对象
recognizer = sr.Recognizer()# 使用麦克风作为音频源
microphone = sr.Microphone()# 实时语音转录
print("开始实时语音转录...")with microphone as source:# 动态调整环境噪音水平recognizer.adjust_for_ambient_noise(source)# 开始监听麦克风输入recognizer.dynamic_energy_threshold = Trueprint("请开始讲话...")try:while True:audio_data = recognizer.listen(source)text = recognizer.recognize_google(audio_data, language="zh-CN") # 使用Google Web Speech API进行实时语音转录print("实时转录结果:", text)except KeyboardInterrupt:print("实时语音转录结束。")在这个示例中,代码会实时监听麦克风输入并将其转录为文本。您可以根据需要更改语音识别引擎(例如CMU Sphinx、Microsoft Azure Speech等)来适应不同的场景和需求。
请注意,由于实时语音转录可能会受到环境噪音等因素的影响,您可能需要根据实际情况调整识别的准确性。您可以尝试调整recognizer.adjust_for_ambient_noise()中的参数来适应不同的环境。
这段代码可以作为一个简单的实时语音转录示例,您可以根据实际需求进行进一步的定制和优化。
五、SpeechRecognitio库转录文本中提取关键词和生成摘要示例代码
 要实现从转录文本中提取关键词和生成摘要,您可以结合自然语言处理技术,如NLTK(Natural Language Toolkit)和Gensim。以下是一个示例代码,演示如何从转录文本中提取关键词和生成摘要:
要实现从转录文本中提取关键词和生成摘要,您可以结合自然语言处理技术,如NLTK(Natural Language Toolkit)和Gensim。以下是一个示例代码,演示如何从转录文本中提取关键词和生成摘要:
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.probability import FreqDist
from nltk.tokenize import sent_tokenize
from gensim.summarization import summarize# 示例转录文本
transcript = """
这是会议的转录文本。在这次会议中,讨论了很多重要的议题和决策。与会者提出了各自的看法和建议,就如何提高团队的效率和协作进行了深入的讨论。会议总结时,重点强调了沟通和透明度的重要性。
"""# 分词
words = word_tokenize(transcript)# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_words = [word for word in words if word.lower() not in stop_words]# 提取关键词
fdist = FreqDist(filtered_words)
keywords = fdist.most_common(5) # 提取出现频率最高的5个词作为关键词
print("关键词:", [keyword[0] for keyword in keywords])# 生成摘要
sentences = sent_tokenize(transcript)
summary = summarize(transcript, ratio=0.3) # 生成总结,保留原始文本的30%
print("摘要:", summary)
在这个示例中,我们首先对转录文本进行分词,并去除停用词。然后使用NLTK库来计算词频,提取出现频率最高的词作为关键词。接着使用Gensim库中的summarize函数来生成摘要,可以根据需要调整ratio参数来控制生成摘要的长度。
这段代码可以帮助您快速从会议转录文本中提取关键词和生成摘要,帮助用户快速了解会议内容的重点和要点。您可以根据实际需求对代码进行进一步定制和优化。
六、SpeechRecognitio库语音情绪识别示例代码

 要实现语音情绪识别,您可以结合SpeechRecognition库和情感分析技术,比如使用TextBlob或者VADER等情感分析工具。以下是一个示例代码,演示如何结合SpeechRecognition和TextBlob来进行语音情绪识别:
要实现语音情绪识别,您可以结合SpeechRecognition库和情感分析技术,比如使用TextBlob或者VADER等情感分析工具。以下是一个示例代码,演示如何结合SpeechRecognition和TextBlob来进行语音情绪识别:
import speech_recognition as sr
from textblob import TextBlob# 初始化语音识别器
recognizer = sr.Recognizer()# 从麦克风录音
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本text = recognizer.recognize_google(audio, language='zh-CN')print("识别结果:", text)# 使用TextBlob进行情感分析blob = TextBlob(text)sentiment = blob.sentimentemotion = "正面" if sentiment.polarity > 0 else "负面" if sentiment.polarity < 0 else "中性"print("情绪分析:", emotion)except sr.UnknownValueError:print("无法识别语音")except sr.RequestError as e:print("无法连接到Google Web Speech API:{0}".format(e))
在这个示例中,我们首先使用SpeechRecognition库从麦克风录音并将语音转换为文本,然后利用TextBlob库进行情感分析。情感分析会计算文本的极性(polarity),表示情感的正负程度。根据极性值,我们可以判断文本表达的情绪是正面、负面还是中性。
这段代码可以帮助您实时识别讲话者的情绪,从而更好地理解会议氛围和参与者情绪。您可以根据实际需求对代码进行进一步定制和优化,比如结合更复杂的情感分析模型或者适应不同语言的情感分析。
七、SpeechRecognitio库语音搜索和标记示例代码
 要实现语音搜索和标记功能,您可以结合SpeechRecognition库、关键词提取技术和用户标记功能。以下是一个示例代码,演示如何实现语音转录后添加搜索和标记功能:
要实现语音搜索和标记功能,您可以结合SpeechRecognition库、关键词提取技术和用户标记功能。以下是一个示例代码,演示如何实现语音转录后添加搜索和标记功能:
import speech_recognition as sr
from textblob import TextBlob# 初始化语音识别器
recognizer = sr.Recognizer()# 从麦克风录音
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本text = recognizer.recognize_google(audio, language='zh-CN')print("识别结果:", text)# 使用TextBlob进行关键词提取blob = TextBlob(text)keywords = blob.wordsprint("关键词:", keywords)# 用户标记重要内容important_content = input("请标记重要内容(按Enter跳过):")# 搜索功能search_keyword = input("请输入要搜索的关键词:")if search_keyword in text:print("找到关键词'{0}'在文本中的位置:".format(search_keyword))index = text.index(search_keyword)print(text[max(0, index - 50):min(len(text), index + 50)]) # 显示关键词前后50个字符except sr.UnknownValueError:print("无法识别语音")except sr.RequestError as e:print("无法连接到Google Web Speech API:{0}".format(e))
在这个示例中,我们首先使用SpeechRecognition库从麦克风录音并将语音转换为文本,然后利用TextBlob库进行关键词提取。用户可以通过输入标记重要内容,并且可以输入关键词进行搜索。如果搜索的关键词在文本中存在,代码会输出关键词在文本中的位置,并显示关键词前后50个字符的内容。
这段代码可以帮助您实现语音转录后的搜索和标记功能,让用户可以快速找到特定内容并标记重要部分,方便后续回顾和整理。您可以根据实际需求对代码进行进一步优化和扩展,比如实现更复杂的搜索逻辑或者增加更多的标记功能。
八、SpeechRecognitio库用户身份识别示例代码
 要实现用户身份识别功能,您可以结合SpeechRecognition库和用户身份识别技术,比如说话人识别或者语音特征识别。以下是一个示例代码,演示如何利用SpeechRecognition库实现简单的用户身份识别功能:
要实现用户身份识别功能,您可以结合SpeechRecognition库和用户身份识别技术,比如说话人识别或者语音特征识别。以下是一个示例代码,演示如何利用SpeechRecognition库实现简单的用户身份识别功能:
import speech_recognition as sr# 定义已知讲话者的身份信息
known_speakers = {"speaker1": ["你好", "你好,很高兴见到大家"],"speaker2": ["大家好", "我今天要谈论的是..."]
}# 初始化语音识别器
recognizer = sr.Recognizer()# 从麦克风录音
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本text = recognizer.recognize_google(audio, language='zh-CN')print("识别结果:", text)# 讲话者身份识别identified_speaker = Nonefor speaker, phrases in known_speakers.items():for phrase in phrases:if phrase in text:identified_speaker = speakerbreakif identified_speaker:breakif identified_speaker:print("识别到讲话者:", identified_speaker)else:print("未识别到讲话者")except sr.UnknownValueError:print("无法识别语音")except sr.RequestError as e:print("无法连接到Google Web Speech API:{0}".format(e))
在这个示例中,我们定义了一些已知讲话者的身份信息和他们常说的一些短语。当有新的语音输入时,代码会检查输入文本中是否包含已知讲话者的短语,从而识别讲话者的身份。
这段代码可以帮助您简单实现用户身份识别功能,让您可以根据讲话者的身份记录对应的发言内容,提高记录的准确性和可读性。您可以根据实际需求扩展代码,比如增加更多讲话者的身份信息或者改进身份识别的算法以提高准确性。
九、SpeechRecognitio库数据可视化处理示例代码

要将会议内容的转录结果进行数据可视化处理,您可以结合Python中的各种数据可视化库,比如Matplotlib和WordCloud库。以下是一个示例代码,演示如何将会议内容转录结果进行词频统计并生成词云和柱状图:
import speech_recognition as sr
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from collections import Counter# 初始化语音识别器
recognizer = sr.Recognizer()# 从文件中读取会议内容(这里假设会议内容保存在meeting.txt中)
with open("meeting.txt", "r", encoding="utf-8") as file:meeting_text = file.read()# 使用WordCloud生成词云
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(meeting_text)# 使用Matplotlib绘制词云图
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('会议内容词云')
plt.show()# 进行词频统计
words = meeting_text.split()
word_freq = Counter(words)# 绘制词频柱状图
plt.figure(figsize=(12, 6))
plt.bar(word_freq.keys(), word_freq.values())
plt.xlabel('词语')
plt.ylabel('词频')
plt.title('会议内容词频统计')
plt.xticks(rotation=45)
plt.show()
在这个示例中,我们首先从文件中读取会议内容,然后使用WordCloud库生成词云图,展示会议讨论的主题和重点词汇。接着利用Matplotlib库绘制词频统计的柱状图,以直观展示会议内容中各词语的出现频率。
这段代码可以帮助您实现将会议内容转录结果进行数据可视化处理,生成词云和柱状图,帮助用户更好地理解会议内容的主题和重点。您可以根据实际需求对代码进行调整和扩展,比如添加更多数据可视化的方式或者调整图表样式以更好地呈现数据。
十、SpeechRecognitio库多语言支持示例代码

 要实现SpeechRecognition库的多语言支持功能,您可以在识别语音时指定不同的语言参数。SpeechRecognition库支持多种语言,包括英语、中文、西班牙语等。以下是一个示例代码,演示如何实现多语言支持的语音识别和转录:
要实现SpeechRecognition库的多语言支持功能,您可以在识别语音时指定不同的语言参数。SpeechRecognition库支持多种语言,包括英语、中文、西班牙语等。以下是一个示例代码,演示如何实现多语言支持的语音识别和转录:
import speech_recognition as sr# 初始化语音识别器
recognizer = sr.Recognizer()# 选择要识别的语言,这里以中文为例
language = 'zh-CN'# 从麦克风录音并识别语音
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本,指定语言参数text = recognizer.recognize_google(audio, language=language)print("识别结果:", text)except sr.UnknownValueError:print("无法识别语音")except sr.RequestError as e:print("无法连接到Google Web Speech API:{0}".format(e))
在这个示例中,我们通过指定language变量来选择要识别的语言,这里选择了中文(‘zh-CN’)。您可以根据需要更改language变量的值来选择其他语言,比如英语(‘en-US’)、西班牙语(‘es-ES’)等。
通过这样的方式,您可以利用SpeechRecognition库实现多语言支持的语音识别和转录功能,从而能够处理不同语言的会议内容,提高工具的适用范围和灵活性。您可以根据实际需求扩展代码,比如添加多语言识别的自动切换功能或者处理多语言混合的情况。
十一、SpeechRecognitio库自定义词汇表示例代码
 要实现SpeechRecognition库的自定义词汇表功能,您可以利用语音识别引擎的特定参数来传递自定义词汇表。在这个示例中,我们将使用Google Web Speech API,并通过
要实现SpeechRecognition库的自定义词汇表功能,您可以利用语音识别引擎的特定参数来传递自定义词汇表。在这个示例中,我们将使用Google Web Speech API,并通过speech_recognition库的recognize_google方法来实现自定义词汇表的功能。以下是一个示例代码:
import speech_recognition as sr# 初始化语音识别器
recognizer = sr.Recognizer()# 自定义词汇表,包含特定行业术语或公司内部名词
custom_vocabulary = ["term1", "term2", "term3"]# 将自定义词汇表转换为字符串格式
custom_vocabulary_str = ' '.join(custom_vocabulary)# 从麦克风录音并识别语音,传递自定义词汇表参数
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本,传递自定义词汇表参数text = recognizer.recognize_google(audio, language='en-US', show_all=False, key=None, custom_vocabulary=custom_vocabulary_str)print("识别结果:", text)except sr.UnknownValueError:print("无法识别语音")except sr.RequestError as e:print("无法连接到Google Web Speech API:{0}".format(e))
在这个示例中,我们首先定义了一个自定义词汇表custom_vocabulary,其中包含特定行业术语或公司内部名词。然后将这些词汇表转换为字符串格式custom_vocabulary_str,并在调用recognize_google方法时通过custom_vocabulary参数传递给Google Web Speech API。
通过这样的方式,您可以实现自定义词汇表的功能,以提高语音识别的准确性,特别是在处理包含特定行业术语或公司内部名词的内容时。您可以根据实际需求扩展代码,比如动态生成自定义词汇表、处理多个词汇表等。
十二、SpeechRecognitio库自动化会议记录整理示例代码
 要实现将会议记录整理为结构化格式的功能,您可以结合语音识别和自然语言处理技术,提取关键信息并整理成结构化的数据。以下是一个简单示例代码,演示如何使用SpeechRecognition库和自然语言处理库spaCy来实现自动化会议记录整理:
要实现将会议记录整理为结构化格式的功能,您可以结合语音识别和自然语言处理技术,提取关键信息并整理成结构化的数据。以下是一个简单示例代码,演示如何使用SpeechRecognition库和自然语言处理库spaCy来实现自动化会议记录整理:
import speech_recognition as sr
import spacy# 初始化语音识别器和spaCy模型
recognizer = sr.Recognizer()
nlp = spacy.load("en_core_web_sm")# 从麦克风录音并识别语音
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本text = recognizer.recognize_google(audio, language='en-US')print("识别结果:", text)# 使用spaCy进行自然语言处理doc = nlp(text)# 提取会议议题、决策、行动项等信息topics = []decisions = []action_items = []for sentence in doc.sents:if "议题" in sentence.text:topics.append(sentence.text)if "决策" in sentence.text:decisions.append(sentence.text)if "行动项" in sentence.text:action_items.append(sentence.text)# 输出整理后的信息print("会议议题:", topics)print("决策:", decisions)print("行动项:", action_items)except sr.UnknownValueError:print("无法识别语音")except sr.RequestError as e:print("无法连接到Google Web Speech API:{0}".format(e))
在这个示例中,我们首先使用SpeechRecognition库将语音转换为文本,然后利用spaCy进行自然语言处理,提取会议议题、决策和行动项等关键信息。通过识别关键词并将相关句子提取出来,可以将会议记录整理为结构化的格式,方便后续跟进和执行。
您可以根据实际需求扩展代码,比如增加更多信息提取的规则、优化提取算法、将整理后的信息存储到数据库或文件中等。这样的自动化会议记录整理工具可以提高工作效率,减少人工整理的工作量。
十三、SpeechRecognition库与日历集成示例代码
 要实现SpeechRecognition与日历集成的功能,可以使用Google Calendar API来创建会议事件并将转录内容附加到事件描述中。以下是一个简单的示例代码,演示如何将会议记录与日历应用程序集成:
要实现SpeechRecognition与日历集成的功能,可以使用Google Calendar API来创建会议事件并将转录内容附加到事件描述中。以下是一个简单的示例代码,演示如何将会议记录与日历应用程序集成:
首先,确保已安装所需的库,可以使用以下命令安装:
pip install google-api-python-client google-auth-httplib2 google-auth-oauthlib
然后,可以使用以下示例代码来实现SpeechRecognition与日历集成:
import speech_recognition as sr
from google.oauth2 import service_account
import googleapiclient.discovery# 初始化语音识别器
recognizer = sr.Recognizer()# 从麦克风录音并识别语音
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本text = recognizer.recognize_google(audio, language='en-US')print("识别结果:", text)# 设置Google Calendar API凭据SCOPES = ['https://www.googleapis.com/auth/calendar']SERVICE_ACCOUNT_FILE = 'credentials.json' # 替换为您的服务帐户凭据文件credentials = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_FILE, scopes=SCOPES)service = googleapiclient.discovery.build('calendar', 'v3', credentials=credentials)# 创建会议事件并附带转录内容event = {'summary': '会议标题','description': text,'start': {'dateTime': '2024-02-24T10:00:00', 'timeZone': 'Asia/Shanghai'},'end': {'dateTime': '2024-02-24T11:00:00', 'timeZone': 'Asia/Shanghai'}}event = service.events().insert(calendarId='primary', body=event).execute()print('会议事件已创建:', event.get('htmlLink'))except sr.UnknownValueError:print("无法识别语音")except sr.RequestError as e:print("无法连接到Google Web Speech API:{0}".format(e))
在这个示例中,我们首先使用SpeechRecognition库将语音转换为文本,然后利用Google Calendar API创建一个新的会议事件,并将转录内容作为事件描述。您需要替换示例代码中的SERVICE_ACCOUNT_FILE为您的Google服务帐户凭据文件,以便进行身份验证和访问Google Calendar API。
通过这样的集成,您可以在录制会议记录时自动创建会议事件,并将转录内容附加到事件中,方便日程管理和回顾。您可以根据需求扩展代码,比如添加更多事件属性、处理时间安排、增加错误处理等功能。
十四、SpeechRecognitio库安全和隐私保护示例代码
 当涉及到SpeechRecognition的安全和隐私保护时,确保转录内容的安全性至关重要。以下是一个简单的示例代码,演示如何在语音识别过程中采取数据加密和访问控制措施来保护转录内容,并确保符合相关法规和标准:
当涉及到SpeechRecognition的安全和隐私保护时,确保转录内容的安全性至关重要。以下是一个简单的示例代码,演示如何在语音识别过程中采取数据加密和访问控制措施来保护转录内容,并确保符合相关法规和标准:
import speech_recognition as sr
from cryptography.fernet import Fernet# 生成加密密钥
key = Fernet.generate_key()
cipher = Fernet(key)# 初始化语音识别器
recognizer = sr.Recognizer()# 从麦克风录音并识别语音
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本(这里仅为示例,实际应用中可以使用更安全的API)text = recognizer.recognize_google(audio, language='en-US', key=None, show_all=False)# 加密转录内容encrypted_text = cipher.encrypt(text.encode())# 在此处添加访问控制措施,确保只有授权的用户可以访问转录内容# 可以添加身份验证、访问控制列表等措施来限制对转录内容的访问# 示例:访问控制,只允许特定用户访问转录内容authorized_users = ['user1', 'user2']current_user = 'user1' # 假设当前用户是'user1'if current_user in authorized_users:# 可以让授权用户访问加密后的转录内容print("加密后的转录内容:", encrypted_text)else:print("您没有权限访问转录内容。")except sr.UnknownValueError:print("无法识别音频")except sr.RequestError as e:print("无法连接到Google Web Speech API;{0}".format(e))
这段代码演示了如何使用SpeechRecognition库进行语音识别,并在识别后对转录内容进行加密,然后通过访问控制措施限制对转录内容的访问。您可以根据具体需求和安全标准进一步完善这些措施,以确保转录内容的安全性和隐私保护。
十五、SpeechRecognitio库跨平台支持示例代码
 要开发一个支持跨平台的应用程序,使用户能够在不同设备上访问会议记录,您可以考虑使用Python和相应的库来实现语音转录和记录功能。以下是一个示例代码,演示如何使用SpeechRecognition库从麦克风录音并将语音转录内容保存到文件中,以便用户随时随地访问会议记录:
要开发一个支持跨平台的应用程序,使用户能够在不同设备上访问会议记录,您可以考虑使用Python和相应的库来实现语音转录和记录功能。以下是一个示例代码,演示如何使用SpeechRecognition库从麦克风录音并将语音转录内容保存到文件中,以便用户随时随地访问会议记录:
import speech_recognition as sr# 初始化语音识别器
recognizer = sr.Recognizer()# 从麦克风录音并识别语音
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本(这里仅为示例,实际应用中可以使用更安全的API)text = recognizer.recognize_google(audio, language='en-US', key=None, show_all=False)# 将转录内容保存到文件中with open("meeting_record.txt", "w") as file:file.write(text)print("会议记录已保存到文件:meeting_record.txt")except sr.UnknownValueError:print("无法识别音频")except sr.RequestError as e:print("无法连接到Google Web Speech API;{0}".format(e))
这段代码可以在不同平台的设备上运行,并允许用户通过麦克风录音并将语音转录内容保存到文件中。用户可以随时随地访问这些会议记录文件。您可以根据具体需求进一步扩展这个示例,比如添加文件存储到云服务、实现多语言支持等功能,以提供更好的用户体验和跨平台支持。
十六、SpeechRecognitio库自动语音翻译示例代码
 要实现自动语音翻译功能,结合SpeechRecognition和机器翻译技术,您可以使用Google Translate API 或其他机器翻译服务。以下是一个示例代码,演示如何将语音转录内容自动翻译为其他语言:
要实现自动语音翻译功能,结合SpeechRecognition和机器翻译技术,您可以使用Google Translate API 或其他机器翻译服务。以下是一个示例代码,演示如何将语音转录内容自动翻译为其他语言:
请注意,以下示例代码使用Google Cloud的Translate API,您需要替换为自己的API密钥和设置目标语言。
import speech_recognition as sr
from google.cloud import translate# 初始化语音识别器
recognizer = sr.Recognizer()# 初始化Google翻译客户端
translate_client = translate.Client()# 从麦克风录音并识别语音
with sr.Microphone() as source:print("请开始讲话:")audio = recognizer.listen(source)try:# 使用Google Web Speech API进行语音转文本(这里仅为示例,实际应用中可以使用更安全的API)text = recognizer.recognize_google(audio, language='en-US', key=None, show_all=False)# 使用Google翻译API将文本翻译为目标语言(这里以中文为例)translation = translate_client.translate(text, target_language='zh-CN')print("原始文本:", text)print("翻译结果:", translation['translatedText'])except sr.UnknownValueError:print("无法识别音频")except sr.RequestError as e:print("无法连接到Google Web Speech API;{0}".format(e))
这段代码演示了如何结合SpeechRecognition和Google翻译API实现自动语音翻译功能。您可以根据需要修改目标语言和其他设置,以满足您的具体需求。这样可以方便跨语言交流和合作,提高用户体验。
十七、归纳总结
 SpeechRecognition库是一个用于语音识别的Python库,可以帮助开发人员实现语音转录功能。结合会议记录转录工具的开发,以下是关于SpeechRecognition库和会议记录转录工具的知识点归纳总结:
SpeechRecognition库是一个用于语音识别的Python库,可以帮助开发人员实现语音转录功能。结合会议记录转录工具的开发,以下是关于SpeechRecognition库和会议记录转录工具的知识点归纳总结:
-
SpeechRecognition库:
-SpeechRecognition库是一个Python库,用于进行语音识别,支持多种语音识别引擎。
-可以用于从音频源(如麦克风、音频文件)中识别语音内容并转换为文本。
-支持多种语音识别引擎,如Google Web Speech API、CMU Sphinx、Microsoft Bing Voice Recognition等。 -
会议记录转录工具:
-会议记录转录工具是一个应用程序,用于录音会议内容并将其转录为文本,以便用户随时访问和回顾。
-可以结合语音识别技术,如SpeechRecognition库,实现自动转录会议内容的功能。
-可以支持多种功能,如语音转文本、文本翻译、文本存储等,以提高会议记录的可访问性和可用性。 -
示例功能:
-示例功能包括从麦克风录音并识别语音内容,然后将转录内容保存到文件中。
-可以结合加密、访问控制等措施,确保转录内容的安全性和隐私保护。
-可以实现自动语音翻译功能,将转录内容翻译为其他语言,方便跨语言交流和合作。 -
跨平台支持:
-通过使用Python和SpeechRecognition库,可以开发跨平台的应用程序,支持在不同设备上使用,如PC、平板电脑和手机。
-用户可以随时随地访问会议记录,提高会议记录的可访问性和可用性。 -
自动语音翻译:
-结合机器翻译技术,可以实现将语音转录内容自动翻译为其他语言,方便跨语言交流和合作。
-可以使用机器翻译服务,如Google Translate API,将转录内容翻译为目标语言。
 通过综合利用SpeechRecognition库和相关技术,开发会议记录转录工具可以提高会议效率,方便用户记录和回顾会议内容,同时也可以支持跨语言交流和合作。
通过综合利用SpeechRecognition库和相关技术,开发会议记录转录工具可以提高会议效率,方便用户记录和回顾会议内容,同时也可以支持跨语言交流和合作。
![[electron]官方示例解析](https://img-blog.csdnimg.cn/direct/fdd74d254f754b21964f63e454af6ebb.png)