【需求背景】
由于某个服务在访问量不大的情况下,出现频繁的 full gc,配置内存为 1.5g,但是还是不够用,经常占用在 1.3g 左右。
【内存分析】
1、使用 MAT 对 dump 日志进行分析

通过 dominator-tree 可以看出 java.lang.Thread 和 org.apache.dubbo.common.threadlocal.InternalThread 占用内存过高。
其中 java.lang.Thread 有 2000 多个,org.apache.dubbo.common.threadlocal.InternalThread 线程居然有 6000 多个。
2、其中 org.apache.dubbo.common.threadlocal.InternalThread 线程每个占用 0.05M,算比较合理,只需要根据业务需求适当调整线程数即可。

3、以下:进一步分析 java.lang.Thread 为啥占用这么高。
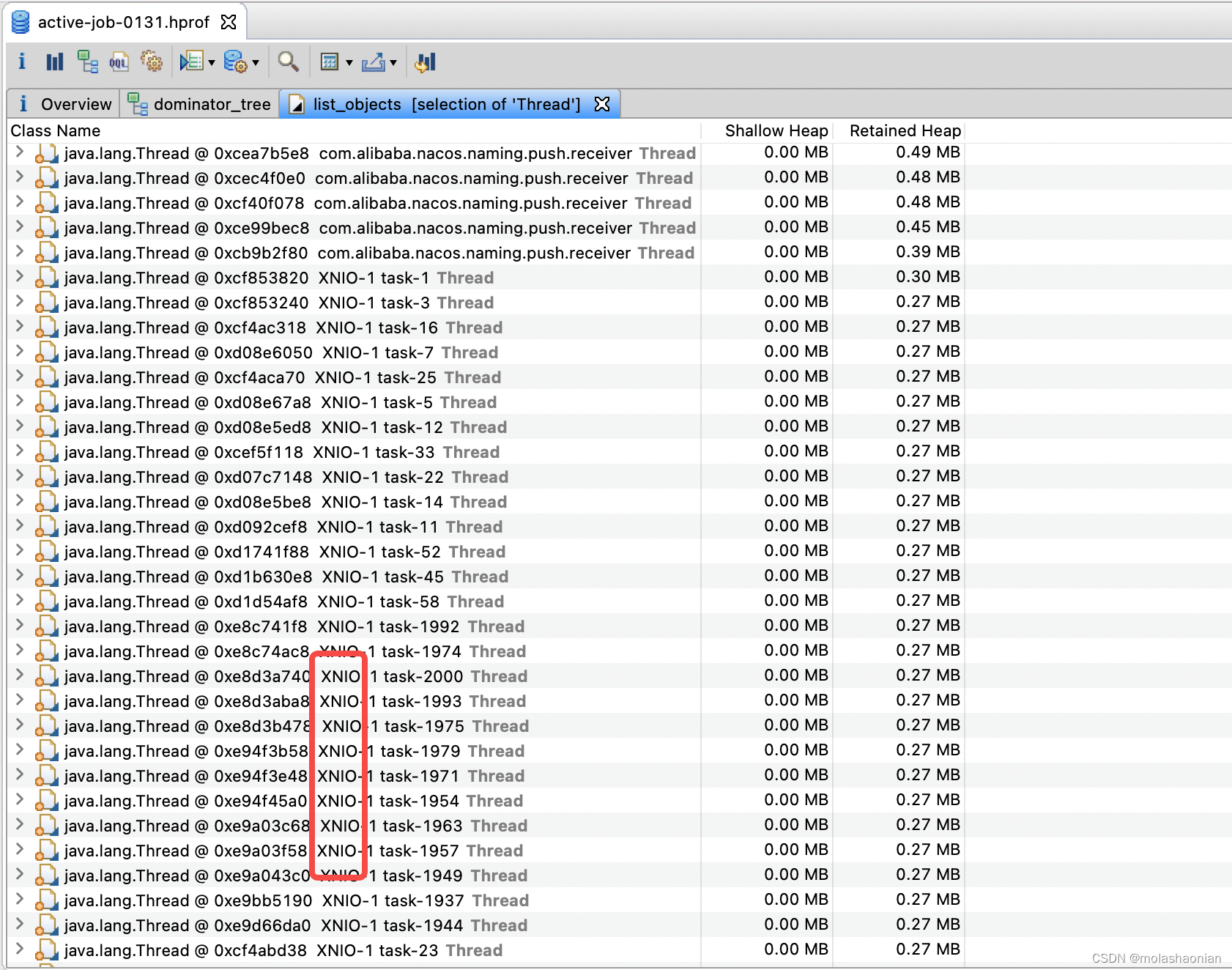
其中以 XNIO 为主,这个线程是通过:server.undertow.worker-threads=2000 这个参数配置的。
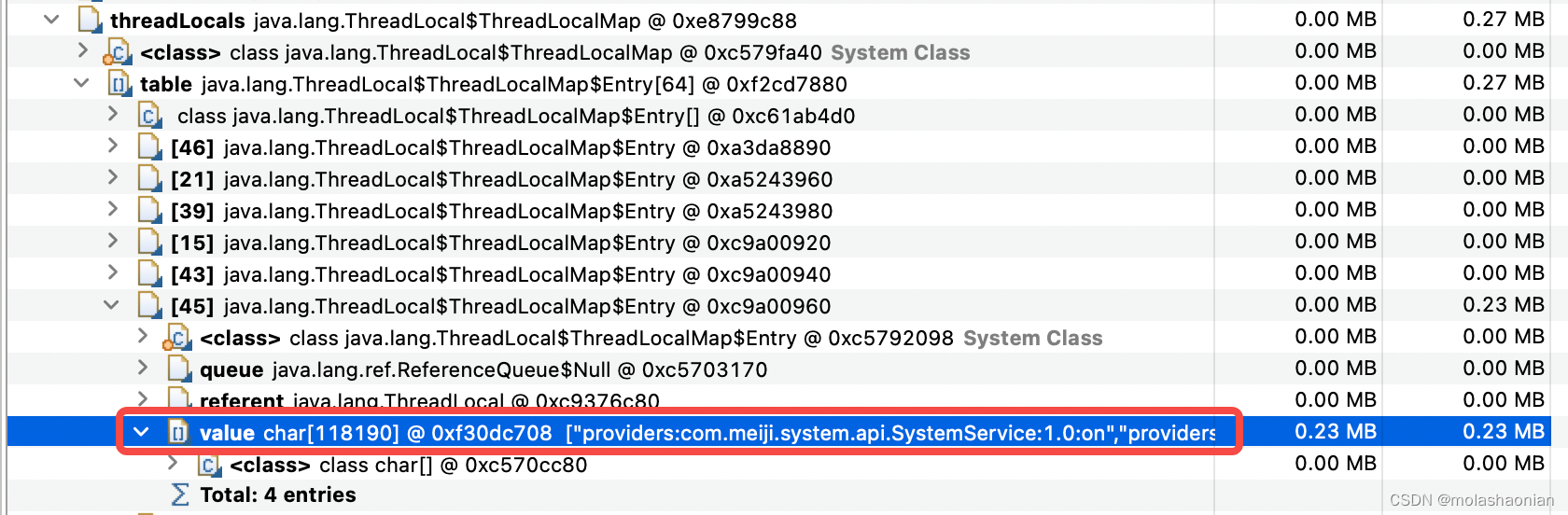
以这个 ThreadLocalMap 最大了,保存的是服务列表信息。
通过分析最终定位到是 org.springframework.cloud.client.discovery.health.DiscoveryClientHealthIndicator#health 这个方法引起的,这里有返回了 services 的信息。

这里是调用 /actuator/health 这个接口返回的,这个接口会在 k8s 心跳探测:/api/status/ready 时调用
解决办法:通过配置参数 spring.cloud.discovery.client.health-indicator.enabled=false 可以关闭服务列表的返回。(由于我们使用 nacos 是 AP 模式,因此不需要强制依赖服务列表的健康检查,因此可以考虑关掉)
【解决方案】
1、通过配置参数 dubbo.provider.threads=2000 调整线程数,降低 dubbo 生产者线程数。
2、通过配置参数 spring.cloud.discovery.client.health-indicator.enabled=false 关闭心跳探测时,对服务列表的返回。
【优化效果】
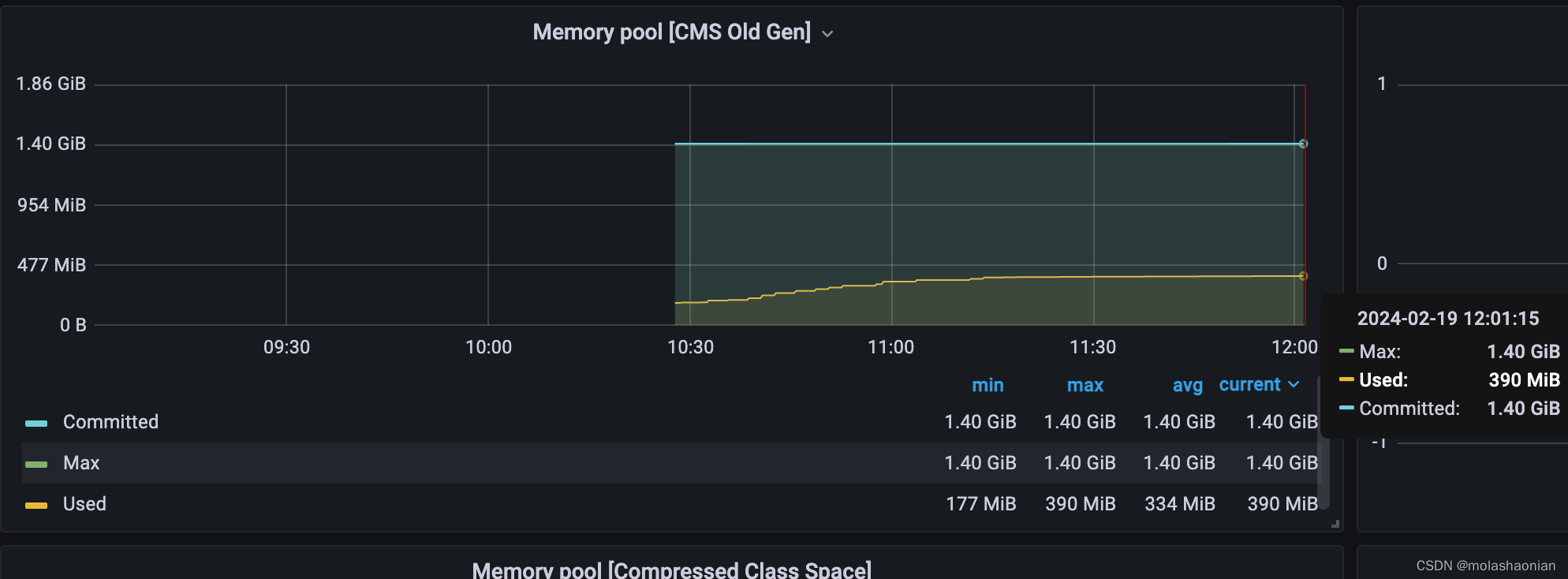
内存由原来占用 1.3g 变成了 400M 左右了。