NeuScraper:神经网络抓取工具,从网页中提取主要内容
- 提出背景
- 流程框架
- 精细拆解
- 效果对比
提出背景
论文:https://arxiv.org/pdf/2402.14652.pdf
代码:https://github.com/OpenMatch/NeuScraper
假设我们需要从一个新闻网站上抓取文章内容,用于语言模型的预训练。
这个网页包含了文章的正文内容、图片、广告、导航栏以及各种社交媒体分享按钮。
传统Web抓取工具:
-
使用规则或启发式方法:传统工具依赖于预定义的规则或启发式方法来确定哪些HTML元素包含需要的文章内容。
例如,可能会搜索特定的
<div>或<article>标签。 -
规则的脆弱性:如果网站的布局发生变化(这在现代Web开发中很常见),规则可能会失效,导致抓取到的内容包含广告或完全错过关键信息。
-
人力成本:需要不断更新规则以适应网页的变化,这是一个持续的人力投入过程。
NeuScraper(神经网络抓取工具):
- 使用神经网络和布局信息:NeuScraper利用神经网络来理解页面的整体布局和内容结构,自动识别并提取文章的正文内容。
- 它通过分析页面元素的视觉和结构特征来判断哪些内容是主要文章,而忽略广告和其他非目标内容。
优势:
- 自适应性:即使网页布局发生变化,NeuScraper也能够通过其训练过的模型适应这些变化,继续准确提取内容。
- 降低人力成本:减少了持续维护和更新规则的需要,因为模型能够学习和适应新的页面结构。
- 提高数据质量:能够更准确地区分正文内容和非目标内容(如广告),提高了抓取数据的质量。
NeuScraper与传统Web抓取工具的主要区别在于其对复杂Web页面内容的处理能力。
NeuScraper通过神经网络和布局信息的综合分析,提供了一种更为高效、自适应且需要更少人力干预的解决方案。
这不仅降低了数据预处理的工作量,还显著提高了为语言模型预训练所准备数据集的质量。
流程框架
使用NeuScraper提取网页主要内容的流程:
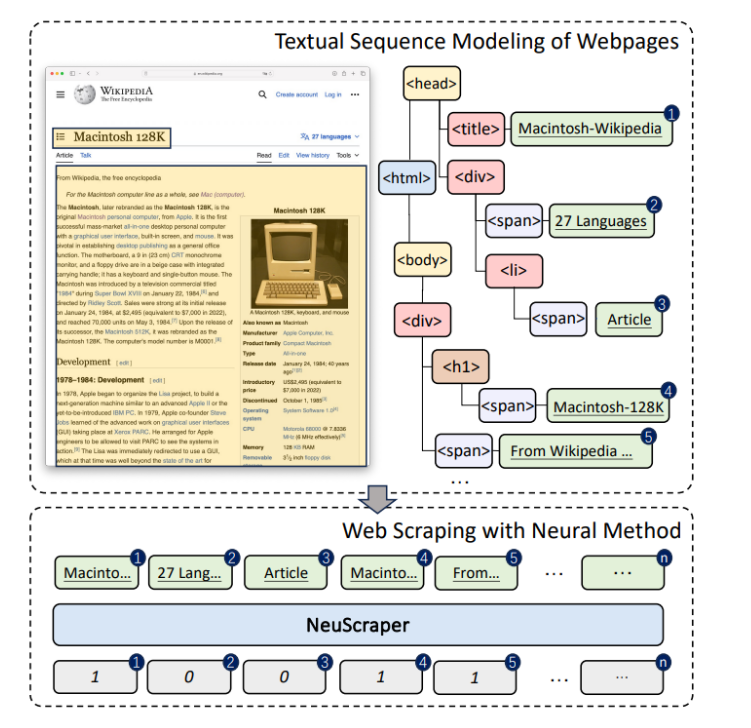
首先将网页转化为文本序列模型,然后通过神经方法进行Web抓取。
在示例中,它标出了要提取的文本区域,例如标题和正文,并将它们转换成了相应的标签和序列。
精细拆解
NeuScraper = 特征1(文本序列的生成)+ 特征2(文本编码)+ 特征3(节点表示的获取)+ 特征4(标签预测)
- 特征1(文本序列的生成):之所以使用文本序列的生成,是因为它允许NeuScraper准确地保留网页的结构和内容信息,为后续的神经网络处理提供基础。
- 特征2(文本编码):使用XLM-Roberta模型的第一层进行文本编码是因为它能有效地将DOM节点的文本内容转换为高维表示,便于进一步分析。
- 特征3(节点表示的获取):通过3层Transformer模型获取节点表示,是因为Transformer能够处理序列数据的依赖关系,提高内容分类的准确性。
- 特征4(标签预测):使用Sigmoid函数和MLP进行标签预测的方法是因为它们可以有效地从节点表示中计算出每个节点属于特定类别的概率,支持多标签分类问题。
比如抓取在线购物网站,我们可以使用NeuScraper来提取产品页面的关键信息,如产品标题、描述、价格和用户评论。
-
特征1(文本序列的生成):
- 网页上的HTML代码通过NeuScraper转换为文本序列,以便后续处理。
- 例如,产品页面的HTML结构会被转换为表示DOM节点顺序的序列。
-
特征2(文本编码):
- 使用NeuScraper中的XLM-Roberta模型的第一层来编码每个DOM节点的文本内容。
- 比如,产品名称
<h1>Awesome Widget</h1>会被转换为768维的向量表示。
-
特征3(节点表示的获取):
- 这些文本编码后的向量会被输入到一个3层Transformer模型中。
- 在这个例子中,Transformer模型可能会识别出产品描述的段落由于其文本密度和结构上的特点与其他内容(如导航菜单或页脚)不同。
-
特征4(标签预测):
- 最后,通过Sigmoid函数和MLP网络对每个节点进行标签预测,以确定它是否包含关键信息。
- 在这个例子中,模型可能会预测
<h1>标签包含的是产品标题,而包含价格信息的<span class="price">标签则被标记为价格信息。
使用NeuScraper,我们可以自动化地从大量产品页面中提取和分类信息,用于建立产品数据库、价格监测、市场分析或推荐系统。
减少了人工标注的需求,并提高了处理大规模数据集时的效率和准确性。
效果对比
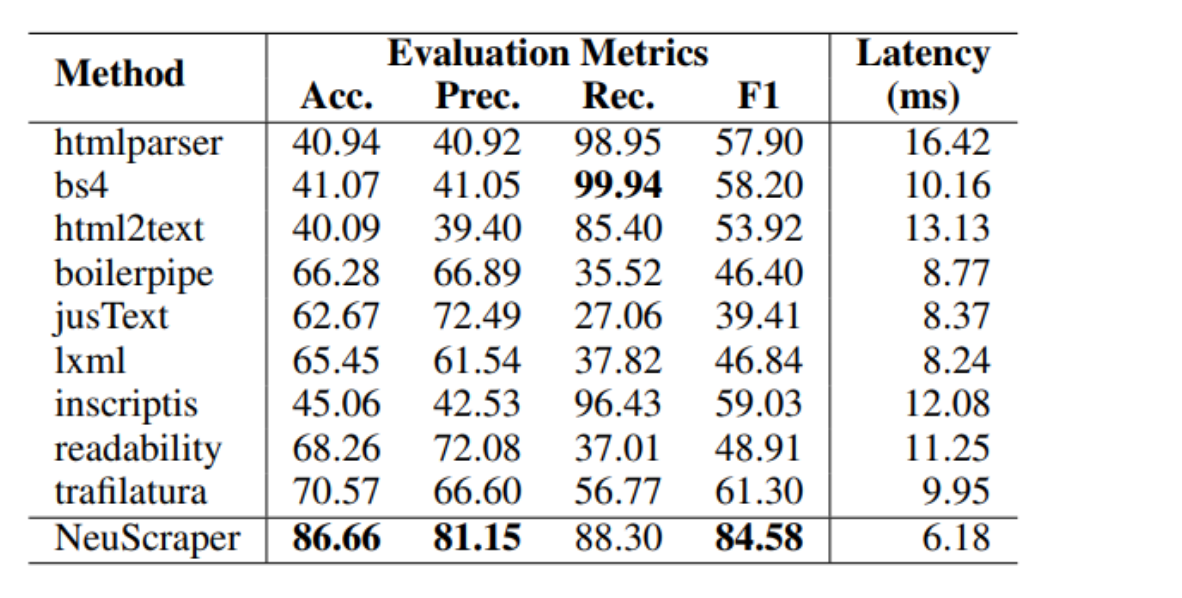
NeuScraper与其他方法在准确度(Acc.)、精确度(Prec.)、召回率(Rec.)、F1得分和延迟(Latency)这些评价指标上的总体性能对比。
NeuScraper在所有指标上都有较高的得分,特别是在F1得分上相比其他方法有显著提高,并且在延迟上也有优势,只有6.18ms。
专为大模型设计,神经网络抓取比基础抓取工具,涨幅超20%!