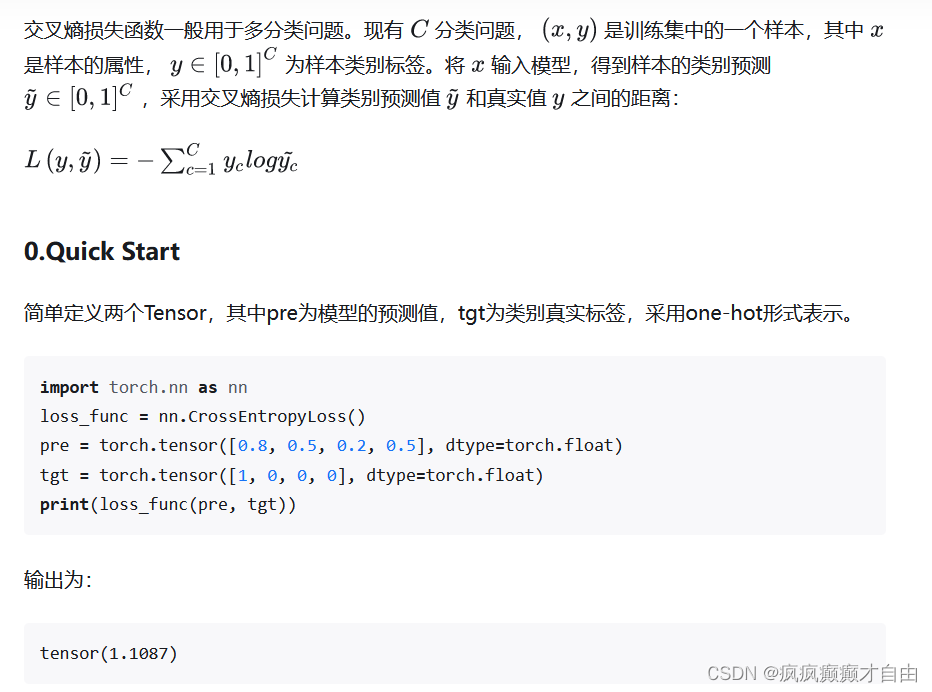
文章目录
- 1. Embedding层
- 2. Encoder层
- 3. MLP Head层
- 4. Hybrid混合模型
论文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
网址:https://arxiv.org/abs/2010.11929
Hybrid - 传统CNN和Transformer混合模型
模型架构

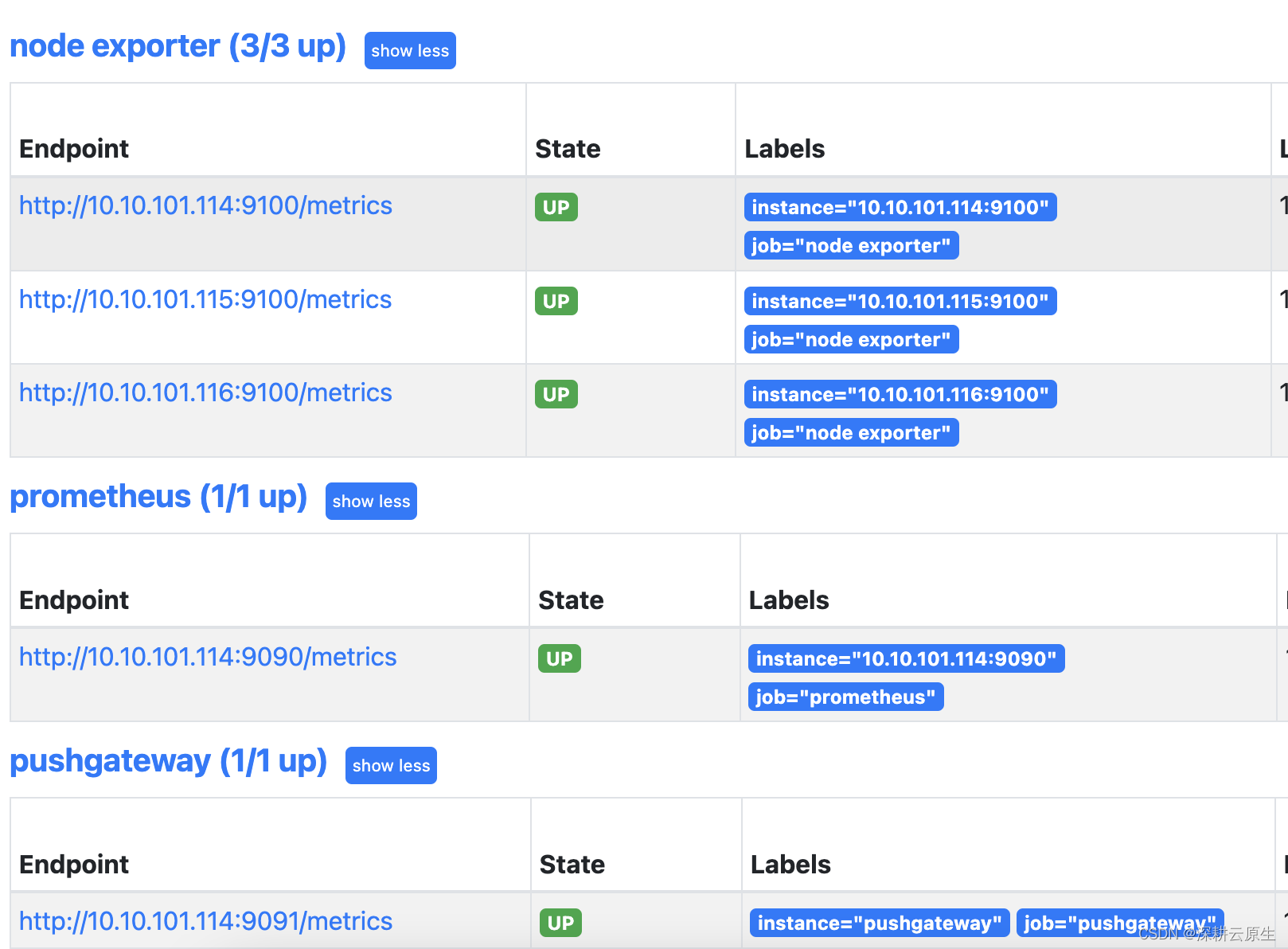
输入一张图片,首先会将其分为一个一个patches,然后将每个patches输入到embedding层(Linear Projection of Flattened Patches)。通过Embedding层后,我们就会得到一个个向量,这里我们通常将向量称为Token。我们会在这一系列Token到最前面增加一个新的Token,专门用于分类的class token。这里的class token的维度和我们刚才得到的token的维度相同。此外,我们还需要加上关于位置的信息,position embedding,对应于上图中的0,1,2,3,….
将这一系列token加上class token以及位置参数输入到Transformer Encoder之中,Transformer Encoder对应的又是右图中的Encoder Block重复堆叠L次。然后将class token所对应的进行输出。

1. Embedding层
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token,token_dim]
在代码实现中,直接通过一个卷积层来实现以VIT-B/16为例,使用卷积核大小为 16 × 16 16\times16 16×16,stride为16,卷积核个数为768。
[224,224,3]->[14,14,768]->[796,768]
在输入Transformer Encoder之前需要加上class token以及position embedding,都是可训练参数
拼接class token:Cat([1,768],[196,768])->[197,768]
叠加position embedding:[197,768]->[197,768]
对于位置编码:

使用位置编码后提升很大,但是各种位置编码之间的差异并不是很大,所以在源码中,默认使用的是1-D Position Embedding。
关于训练得到的位置编码,它的每个位置上与其他位置上的余弦相似度:

2. Encoder层

需要注意:在MLP Block中,第一个全连接层,它的节点个数是我们输入节点个数的4倍,第二个全连接层又回将节点个数还原回原来的大小。
3. MLP Head层
在Transformer Encoder前有个Dropout层,后有一个LayerNorm。
训练ImageNet21K时是由Linear+tanh激活函数+Linear
但是迁移到ImageNet1k上或者自己的数据集上时,只有一个Linear

论文中所给出的三种模型

- Layers是Transformer Encoder中重复堆叠Encoder Block的次数
- Hidden Size是通过Embedding层后每个token的dim(向量的长度)
- MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是hidden size的四倍)
- heads代表Transformer中Multi-head Attention的heads数
4. Hybrid混合模型
首先用传统的卷积神经网络去提取特征,再通过VIT模型得到最终的结果,特征提取部分采用ResNet50,但是不是采用传统的卷积层,而是使用StdConv2d,另外将所有的BatchNorm层替换成GroupNorm层,把stage4中的3个Block移至stage3中。