CHiME 挑战赛已经正式开启,今天分享下 CHiME 的子任务MMCSG(智能眼镜多模态对话),欢迎大家投稿报名!
赛事官网:https://www.chimechallenge.org/current/task3/index
CHiME (Computational Hearing in Multisource Environments)挑战赛是由法国计算机科学与自动化研究所、英国谢菲尔德大学、美国三菱电子研究实验室等知名研究机构所于2011年发起的一项重要国际赛事,重点围绕语音研究领域极具挑战的远场语音处理相关任务,今年已举办到第八届。
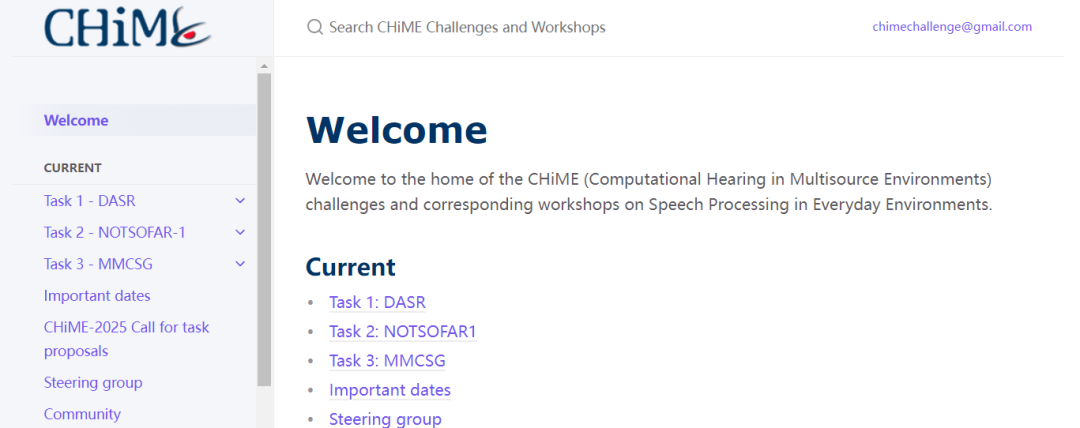
MMCSG(智能眼镜多模态对话)数据集,记录了使用Aria眼镜的双向对话,包括多通道音频、视频、加速度计和陀螺仪数据等多模态信息。适用于自动语音识别、活动检测和说话者分离等领域的研究。支持多模态数据分析,例如结合音频与惯性传感器数据进行分析,以解决说话者识别、活动检测和语音识别等问题。数据集经人工标注,保护了参与者隐私,旨在支持合法的研究目的。
The CHiME-8 MMCSG task involves natural conversations between two people recorded with smart glasses. The goal is to obtain speaker-attributed transcriptions in streaming fashion, using audio, video, and IMU input modalities. See the dedicated pages to learn more about the data, rules and evaluation and the baseline system.
This challenge focuses on transcribing both sides of a conversation where one participant is wearing smart glasses equipped with a microphone array and other sensors. The conversations represent natural spontaneous speech of two conversation participants, some of which include noise. Given the use case of real-time captioning, both transcription and diarization need to happen in a streaming fashion with an as short as possible latency.
Rules
Summary of the rules for systems participating in the challenge:
-
For building the system, it is allowed to use the training subset of MMCSG dataset and external data listed in the subsection Data and pre-trained models. If you believe there is some public dataset missing, you can propose it to be added until the deadline as specified in the schedule.
-
The development subset of MMCSG can be used for evaluating the system throughout the challenge period, but not for training or automatic tuning of the systems.
-
Pre-trained models are listed in the “Data and pre-trained models” subsection. Only those pre-trained models are allowed to be used. If you believe there is some model missing, you can propose it to be added until the deadline as specified in the schedule.
-
The submitted systems must be streaming, i.e. process its inputs sequentially in time and specify latency for each emitted word, as described in detail in the subsection Evaluation. It must not use any global information from a recording before processing it in temporal order. Such global information could include global normalizations, non-streaming speaker identification or diarization, etc. This requirement on streaming processing applies to all modalities (audio, visual, accelerometer, gyroscope, etc).
-
The details of the streaming nature of the system, including any lookahead, chunk-based processing, other details that would impact latency, and an explicit estimate of the average algorithmic and emission latency itself should be clearly described in a section of the submitted system description with the heading “Latency”.
-
For evaluation, each recording must be considered separately. The system should not be in any way fine-tuned on the entire evaluation set (e.g. by computing global statistics, gathering speaker information across multiple recordings). If your system does not comply with these rules (e.g. by using a private dataset or having only a partially streaming method), you may still submit your system, but we will not include it in the final rankings.
Baseline System
The baseline system is provided at Github. Please refer to the README therein for information about how to install and run the system.
The baseline system roughly follows the scheme in (Lin et al, 2023). It comprises of:
-
Fixed NLCMV beamformer (Feng et al, 2023) which uses 13 beams into 12 directions uniformly spaced around the wearer + 1 direction for the mouth of the wearer. The beamformer coefficients are derived from acoustic transfer functions (ATF) recorded in anechoic rooms with the Aria glasses. We release both the beamforming coefficients and the original ATFs.
-
Extraction of log-mel features from each of the 13 beams.
-
ASR model processing the multi-channel features and estimating serialized-output-training (SOT) (Kanda et al, 2022) transcriptions.

The ASR model is based on a publicly available pre-trained streaming model - FastConformer Hybrid Transducer-CTC model. By default, this model is a single-speaker, single-channel model. We modify this model by prepending the beamformer, extending its input to multiple channels, extending the tokenizer with speaker tokens »0, »1 (for SELF and OTHER, respectively), and fine-tuning it to provide the SOT transcriptions. The fine-tuning is done on the training subset of the MMCSG dataset.
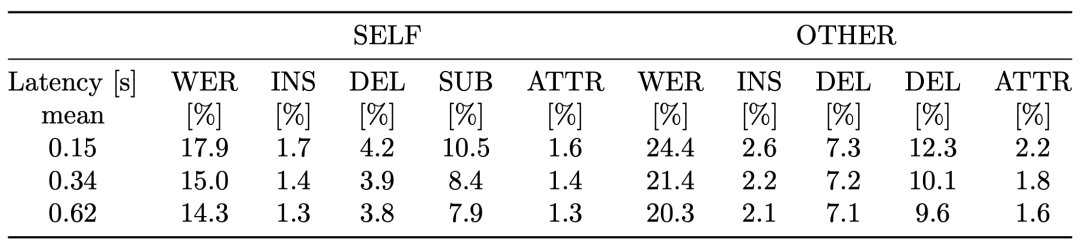
The results achieved by the baseline system on the dev subset of MMCSG with several different latency settings are summarized in the following table:
Submission
The details of the submission will be defined soon.
During the submission, we ask the participants to submit:
-
the word error rates (including the break-down into substitutions, insertions, deletions and speaker attributions) for SELF and OTHER on dev and eval subsets
-
the computed mean latency on dev and eval subsets
-
the hypotheses files for each recording of dev and eval subsets
-
the hypotheses files from the timestamp test on perturbed and unperturbed files
Important dates
| 2024.2.15 | Challenge begins; release of train and dev datasets and baseline system |
| 2024.3.20 | Deadline for proposing additional public datasets and pre-trained models |
| 2024.6.15 | Evaluation set released |
| 2024.6.28 | Deadline for submitting results |
| 2024.6.28 | Deadline for submitting technical reports |
| 2024.9.6 | CHiME-8 Workshop |