贝叶斯核机器回归的简介
Bayesian Kernel Machine Regression (BKMR) 是一种贝叶斯非参数回归方法,用于建模和预测响应变量与预测变量之间的关系。在传统的回归模型中,通常假设响应变量与预测变量之间的关系是线性的,然而这种假设在实际问题中未必成立。相比于传统的线性回归模型,BKMR 提供了更大的灵活性,可以同时考虑线性和非线性关系。BKMR 使用内核函数(Kernel)来对预测变量进行非线性映射,并利用贝叶斯统计方法对模型的参数进行估计。其核心思想是将回归问题转化为在特征空间中的内积计算,通过内核函数来度量样本之间的相似性。
BKMR方法概述
数据准备:首先,需要准备输入变量(特征)和输出变量(目标)。这些数据可以是连续型、离散型或二元型。
决定核函数:为了处理非线性关系,BKMR使用核函数来转换输入变量。常用的核函数包括线性核、多项式核和径向基函数(RBF)核等。
确定先验分布:在贝叶斯框架下,需要指定先验分布来表示模型参数的不确定性。常用的先验分布包括高斯分布、拉普拉斯分布和柯西分布等。
模型构建:通过将输入变量通过核函数映射到高维空间,可以建立核机器回归模型。同时,通过贝叶斯推理方法来学习模型参数和预测后验分布。
参数估计:利用MCMC(Markov chain Monte Carlo)方法或变分推断等技术,可以对模型参数进行估计。通过抽样推断,可以获得参数的后验分布。
模型评估:对于参数估计的后验分布,可以通过计算预测分布、对数似然以及模型选择准则(如BIC、DIC等)来评估模型的性能和选择最佳模型。
BKMR计算步骤
设定先验分布:根据具体问题和模型特点,选择适当的先验分布并设定超参数。
初始化参数:对于模型中的待估计参数,根据先验分布设定初始值。
参数估计:利用MCMC或变分推断等方法,通过抽样推断来更新参数值和后验分布。
模型诊断:通过观察收敛情况、跟踪参数估计的运动轨迹和计算诊断统计量(如Rhat值)来检验模型估计的有效性。
模型选择:通过计算不同模型的对数似然和模型选择准则,进行模型比较和选择最佳模型。
预测和解释:基于估计的模型参数和后验分布,可以进行预测和解释分析,探索输入变量和输出变量之间的关系。
贝叶斯核机回归(BKMR)作为估计混合物健康效应的一种新方法
GAP
研究多重暴露对健康影响日益重要,但面临着若干挑战。首先,暴露与健康结果之间的关系往往具有非线性和非加性(如交互作用)的特点,这使得传统的统计模型难以准确估计健康效应。其次,当研究中暴露变量的数量相对于观测数据的数量增加时,高维度的暴露向量可能导致回归模型拟合不良。再者,暴露变量之间通常高度相关,这给模型构建和解释带来了困难。此外,多重暴露健康效应分析通常包含多个科学目标,包括估算混合物的整体效应、识别对健康效应有贡献的单个成分、可视化暴露-反应函数以及检测污染物之间的交互作用。
污染物之间的交互作用
污染物之间的交互作用(互动效应)指的是一个污染物对健康影响的变化,当其他所有污染物的暴露水平固定在某一特定值(例如75th百分位数)时,与所有其他污染物暴露水平固定在另一特定值(例如25th百分位数)时相比的情况。这种差异 Δm(25, 75 |75) - Δm(25, 75 |25) 表示了在多污染物混合物中,污染物间的相互作用对健康效应的影响程度。选择25th和75th百分位数只是用来说明,实际选择的值可以根据研究需求进行修改。
污染物之间的交互作用是指在多污染物混合物中,两种或多种污染物共同作用于生物体或环境时,其健康效应并非简单地相加,而是可能产生大于单独污染物效应的增强效果,或者相反,可能减少单个污染物的效应。这种非线性和非加性效应体现了污染物之间相互影响的复杂性。
BKMR模型的特点
建模的健康结果作为一个平滑的函数 h,使用核函数表示,暴露变量,调整可能的混杂因素。由于健康结果可能只取决于混合物组分的一个子集,进行变量选择,以确定这些组分中的哪一个对混合物的健康影响负责。最后,为了解决混合组分的共线性问题,Bobb开发了一个 BKMR 的分层变量选择扩展,它可以结合混合物结构的先验知识。
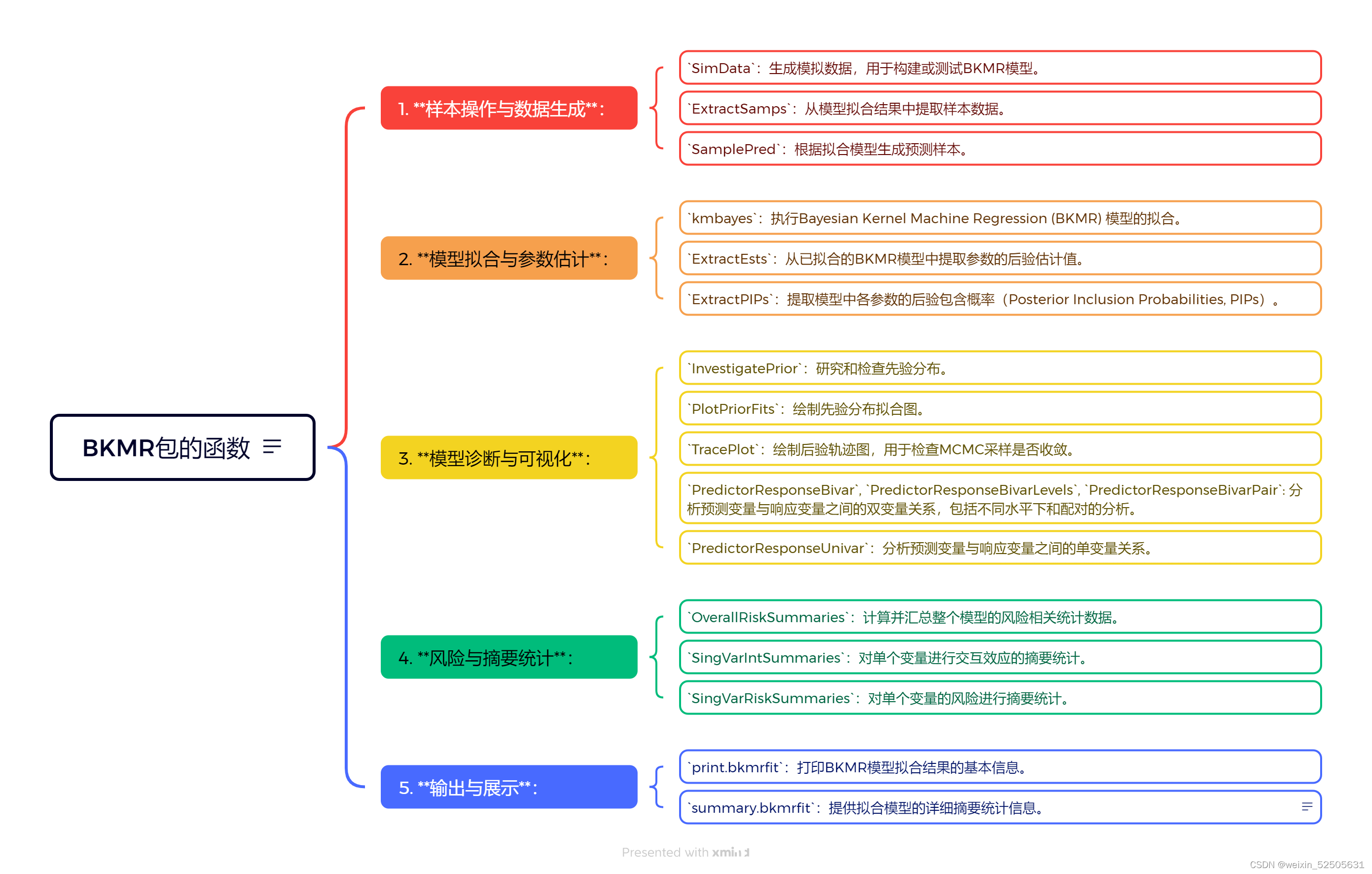
BKMR包的功能
该package 实现了贝叶斯核机器回归(Bayesian Kernel Machine Regression,BKMR),用于估计多种并发暴露对健康效应的联合影响,提供了变量选择和后验包含概率提取等功能。
额外的概念
后验包括率
后验包括率(Posterior Inclusion Probability,PIP)是指在贝叶斯统计中计算得到的模型中,某个自变量(或特征)被选择进入模型的概率。它反映了在给定数据的情况下,该自变量对目标变量的重要性或相关性。这个概率可以作为判断一个自变量是否显著的指标,如果后验包括率接近于1,说明它对目标变量的影响较大;如果接近于0,则说明它对目标变量的影响较小或不显著
调整参数
提议分布(proposal distribution)是在马尔可夫链蒙特卡洛(MCMC)算法中起关键作用的概率分布。其标准差(SD)是一个可以由用户指定的调节参数,用于控制接受率(acceptance rates)。接受率过高会导致链条混合速度缓慢,而接受率过低会阻止算法充分探索参数空间。因此,良好的接受率可以使算法更快地收敛到目标分布。
一般来说,增加提议分布的标准差会导致较低的接受率,而减小标准差则会导致较高的接受率。在算法运行时,可以通过修改主要的kmbayes函数的verbose参数来监控接受率的变化。
调整参数时,可以指定的参数
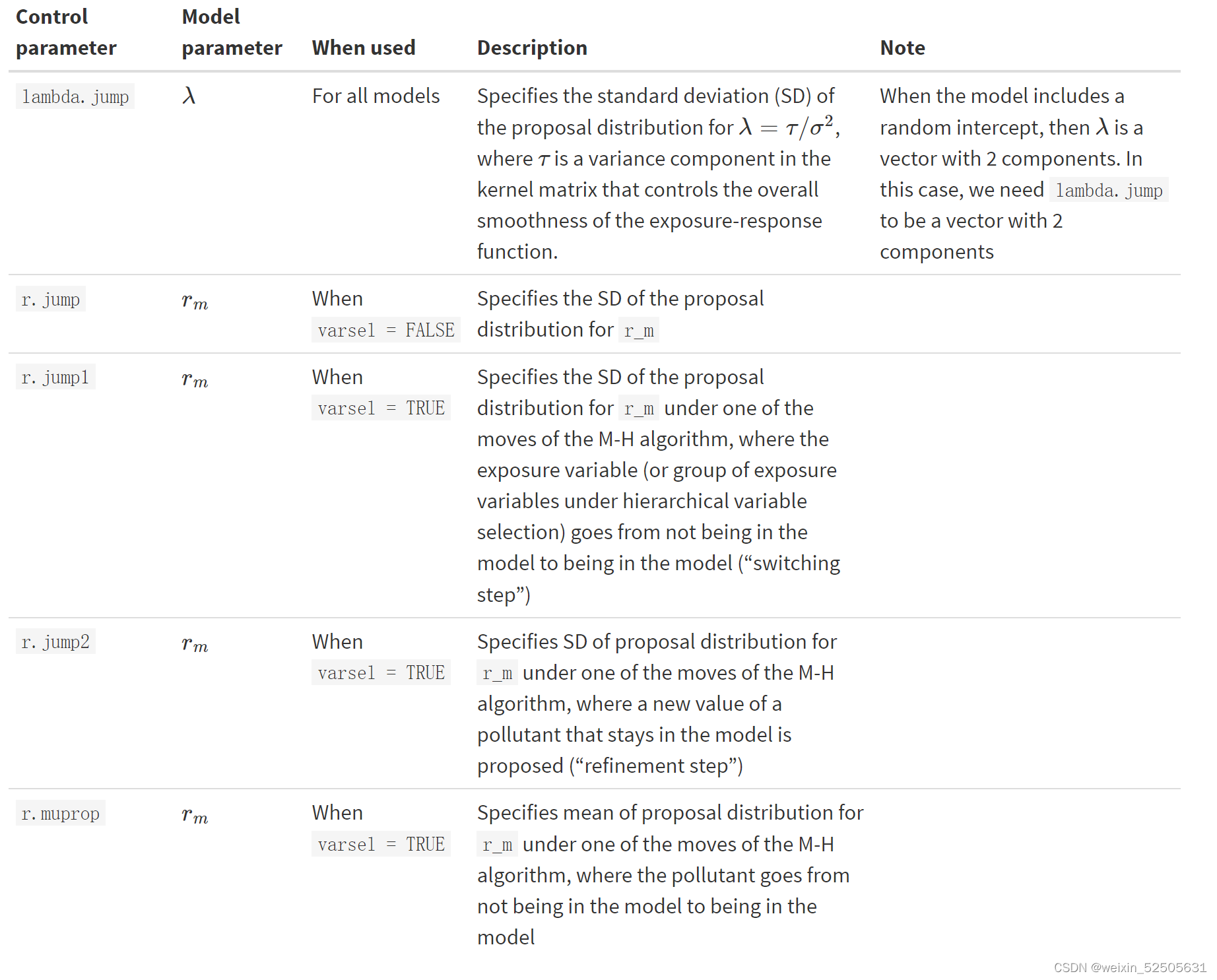
调整先验分布时,可以指定的参数
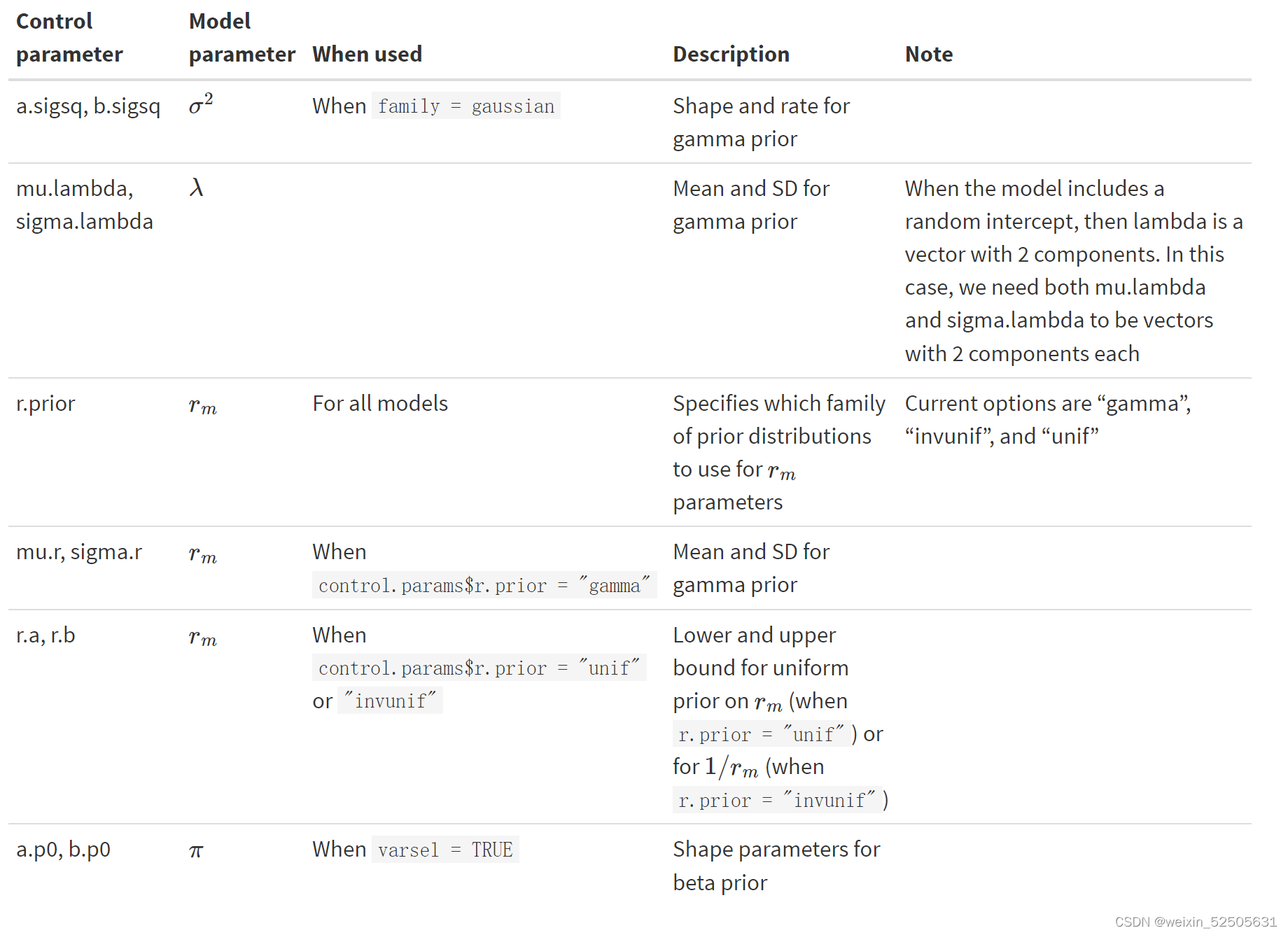
更多内容
贝叶斯核机回归估计混合物健康效应 【BKMR包】——实操篇-CSDN博客![]() https://blog.csdn.net/weixin_52505631/article/details/136218976?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22136218976%22%2C%22source%22%3A%22weixin_52505631%22%7D
https://blog.csdn.net/weixin_52505631/article/details/136218976?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22136218976%22%2C%22source%22%3A%22weixin_52505631%22%7D
贝叶斯核机回归-因果中介分析 (BKMR-CMA)causalbkmr R包-CSDN博客![]() https://blog.csdn.net/weixin_52505631/article/details/136197513?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22136197513%22%2C%22source%22%3A%22weixin_52505631%22%7D
https://blog.csdn.net/weixin_52505631/article/details/136197513?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22136197513%22%2C%22source%22%3A%22weixin_52505631%22%7D
参考文献
bkmr: Bayesian Kernel Machine Regression (r-project.org)![]() https://cran.r-project.org/web/packages/bkmr/bkmr.pdfIntroduction to Bayesian kernel machine regression and the bkmr R package (jenfb.github.io)
https://cran.r-project.org/web/packages/bkmr/bkmr.pdfIntroduction to Bayesian kernel machine regression and the bkmr R package (jenfb.github.io)![]() https://jenfb.github.io/bkmr/overview.html#changing_the_tuning_parameters_for_fitting_the_algorithm
https://jenfb.github.io/bkmr/overview.html#changing_the_tuning_parameters_for_fitting_the_algorithm
GitHub - jenfb/bkmr: Bayesian kernel machine regression![]() https://github.com/jenfb/bkmr
https://github.com/jenfb/bkmr

![第十四章[面向对象]:14.4:实例方法/类方法/静态方法](https://img-blog.csdnimg.cn/img_convert/44331a53cc789d9148e3de8a7c3d2241.jpeg)