打开这篇文章,相信您已经了解了TensorFlow的一些基础知识,可以用它从头开始实现一个简单模型。
如果您对这些概念还不是太清晰,可以浏览一下我这个栏目中的相关文章:
政安晨的机器学习笔记![]() http://t.csdnimg.cn/DHcyL
http://t.csdnimg.cn/DHcyL
尤其是其中几篇关于TensorFlow和Keras的机器学习的文章。
准备环境
为了演绎这一篇Keras的概念,咱们需要准备好环境,这里我安装了Anaconda,创建了安装TensorFLow的环境,并使用Jupyter Notebook演绎Python代码。

如果大家对搭建环境有疑问,还是去看一下我上面那个机器学习笔记的栏目。
一切准备好后,咱们开始。
层:深度学习的基础模块
神经网络的基本数据结构是层。
层是一个数据处理模块,它接收一个或多个张量作为输入,并输出一个或多个张量。有些层是无状态的,但大多数层具有状态,即层的权重。权重是利用随机梯度下降学到的一个或多个张量,其中包含神经网络的知识(knowledge)。
不同类型的层适用于不同的张量格式和不同类型的数据处理。
例如,
简单的向量数据存储在形状为(samples, features)的2阶张量中,通常用密集连接层[densely connected layer,也叫全连接层(fully connected layer)或密集层(dense layer),对应于Keras的Dense类]来处理。
序列数据存储在形状为(samples, timesteps, features)的3阶张量中,通常用循环层(recurrent layer)来处理,比如LSTM层或一维卷积层(Conv1D)。
图像数据存储在4阶张量中,通常用二维卷积层(Conv2D)来处理。
你可以把层看作深度学习的乐高积木,Keras将这个比喻具象化。在Keras中构建深度学习模型,就是将相互兼容的层拼接在一起,建立有用的数据变换流程。
Keras的Layer基类
简单的API应该具有单一的核心抽象概念。
在Keras中,这个核心概念就是Layer类。Keras中的一切,要么是Layer,要么与Layer密切交互。
Layer是封装了状态(权重)和计算(一次前向传播)的对象。权重通常在build()中定义(不过也可以在构造函数__init__()中创建),计算则在call()方法中定义。
Keras的层与下面这个公式非常相似:
output = activation(dot(input, W) + b)
现在咱们演绎一个Dense层的实现(作为Layer的子类):
代码如下:
import tensorflow as tf
from tensorflow import keras# Keras的所有层都继承自Layer基类
class SimpleDense(keras.layers.Layer): def __init__(self, units, activation=None):super().__init__()self.units = unitsself.activation = activation# 在build()方法中创建权重def build(self, input_shape):input_dim = input_shape[-1]self.W = self.add_weight(# add_weight()是创建权重的快捷方法。你也可以创建独立变量,并指定其作为层属性,比如self.W = tf.Variable(tf.random.uniform(w_shape))shape=(input_dim, self.units), initializer="random_normal")self.b = self.add_weight(shape=(self.units,),initializer="zeros")# 在call()方法中定义前向传播计算def call(self, inputs):y = tf.matmul(inputs, self.W) + self.bif self.activation is not None:y = self.activation(y)return y一旦将这样的层实例化,它就可以像函数一样使用,接收一个TensorFlow张量作为输入。
(示例代码如下:)
# 将前面定义的层实例化
my_dense = SimpleDense(units=32, activation=tf.nn.relu)# 创建一些测试输入
input_tensor = tf.ones(shape=(2, 784)) # 对输入调用层,就像调用函数一样
output_tensor = my_dense(input_tensor)print(output_tensor.shape)我的演绎如下:

您可能想知道,既然最终对层的使用就是简单调用(通过层的__call__()方法),那我们为什么还要实现call()和build()呢?
原因在于我们希望能够及时创建状态。我们来看看它们是如何做到的。
自动推断形状:动态构建层
就像玩乐高积木一样,你只能将兼容的层“拼接”在一起。
层兼容性(layer compatibility)的概念具体指的是,每一层只接收特定形状的输入张量,并返回特定形状的输出张量。
看下面这个例子:
from tensorflow.keras import layers# 有32个输出单元的密集层
layer = layers.Dense(32, activation="relu")该层将返回一个张量,其第一维的大小已被转换为32,它后面只能连接一个接收32维向量作为输入的层。
在使用Keras时,往往不必担心尺寸兼容性问题,因为添加到模型中的层是动态构建的,以匹配输入层的形状,例如下面这段代码:
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential([layers.Dense(32, activation="relu"),layers.Dense(32)
])这些层没有收到任何关于输入形状的信息;相反,它们可以自动推断,遇到第一个输入的形状就是其输入形状。
实现的简单Dense层中(我们将其命名为NaiveDense),我们必须将该层的输入大小明确传递给构造函数,以便能够创建其权重,这种方法并不理想,因为它会导致模型的每个新层都需要知道前一层的形状。
model = NaiveSequential([NaiveDense(input_size=784, output_size=32, activation="relu"),NaiveDense(input_size=32, output_size=64, activation="relu"),NaiveDense(input_size=64, output_size=32, activation="relu"),NaiveDense(input_size=32, output_size=10, activation="softmax")
])如果某一层生成输出形状的规则很复杂,那就更糟糕了。如果某一层返回输出的形状是(batch, input_ size * 2 if input_size % 2 == 0 else input_size * 3),那该怎么办?
如果我们把NaiveDense层重新实现为能够自动推断形状的Keras层,那么它看起来就像前面的SimpleDense层,具有build()方法和call()方法。
在SimpleDense中,我们不再像NaiveDense示例那样在构造函数中创建权重;相反,我们在一个专门的状态创建方法build()中创建权重。这个方法接收该层遇到的第一个输入形状作为参数。第一次调用该层时(通过其__call__()方法),build()方法会自动调用。事实上,这就是为什么我们将计算定义在一个单独的call()方法中,而不是直接定义在__call__()方法中。
基层__call__()方法的代码大致如下:
def __call__(self, inputs):if not self.built:self.build(inputs.shape)self.built = Truereturn self.call(inputs)有了自动形状推断,前面的示例就变得简洁了,如下所示:
model = keras.Sequential([SimpleDense(32, activation="relu"),SimpleDense(64, activation="relu"),SimpleDense(32, activation="relu"),SimpleDense(10, activation="softmax")
])注意,自动形状推断并不是Layer类的__call__()方法的唯一功能。
它还要处理更多的事情,特别是急切执行和图执行之间的路由,以及输入掩码。
现在您只需记住:在实现您自己的层时,将前向传播放在call()方法中。
从层到模型
深度学习模型是由层构成的图,在Keras中就是Model类。到目前为止,你只见过Sequential模型(Model的一个子类),它是层的简单堆叠,将单一输入映射为单一输出。但随着深入学习,你会接触到更多类型的网络拓扑结构。
一些常见的结构包括:
双分支(two-branch)
网络多头(multihead)
网络残差连接
网络拓扑结构可能会非常复杂,下图是Transformer各层的图拓扑结构,这是一个用于处理文本数据的常见架构。
下图是Transformer架构:
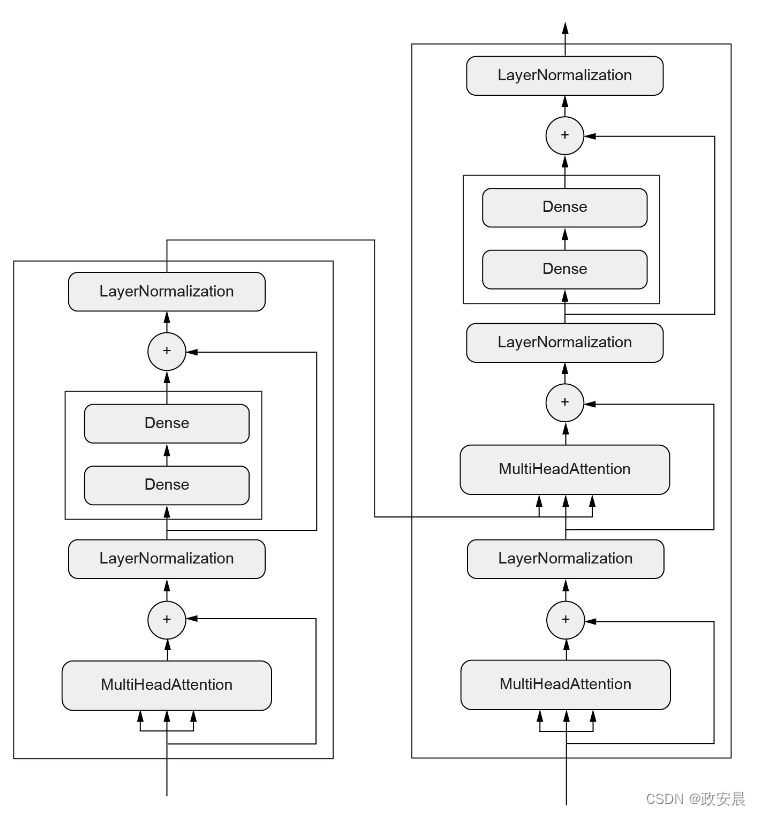
(这里面的内容会有很多,咱们以后会慢慢详解。)
在Keras中构建模型通常有两种方法:直接作为Model类的子类,或者使用函数式API,后者可以用更少的代码做更多的事情。
模型的拓扑结构定义了一个假设空间,机器学习就是在预先定义的可能性空间内,利用反馈信号的指引,寻找特定输入数据的有用表示。通过选择网络拓扑结构,你可以将可能性空间(假设空间)限定为一系列特定的张量运算,将输入数据映射为输出数据。然后,你要为这些张量运算的权重张量寻找一组合适的值。
要从数据中学习,你必须对其进行假设。这些假设定义了可学习的内容。因此,假设空间的结构(模型架构)是非常重要的。它编码了你对问题所做的假设,即模型的先验知识。如果你正在处理一个二分类问题,使用的模型由一个没有激活的Dense层组成(纯仿射变换),那么你就是在假设这两个类别是线性可分的。
选择正确的网络架构,更像是一门艺术而不是科学。虽然有一些最佳实践和原则,但只有实践才能帮助你成为合格的神经网络架构师。后面几章将教你构建神经网络的明确原则,并帮助你训练直觉,判断哪些架构对特定问题有效、哪些无效。
你将在这些问题上拥有可靠的直觉:每种类型的模型架构适合解决哪类问题?在实践中如何构建这些网络?如何选择正确的学习配置?如何调节模型,直到产生你想要的结果?
编译步骤:配置学习过程
一旦确定了模型架构,你还需要选定以下3个参数:
损失函数(目标函数)——在训练过程中需要将其最小化。它衡量的是当前任务是否成功。
优化器——决定如何基于损失函数对神经网络进行更新。它执行的是随机梯度下降(SGD)的某个变体。
指标——衡量成功的标准,在训练和验证过程中需要对其进行监控,如分类精度。与损失不同,训练不会直接对这些指标进行优化。因此,指标不需要是可微的。一旦选定了损失函数、优化器和指标,就可以使用内置方法compile()和fit()开始训练模型。此外,也可以编写自定义的训练循环。
咱们先来看一下compile()和fit() :
compile()方法的作用是配置训练过程,它接收的参数是optimizer、loss和metrics(一个列表)。
# 定义一个线性分类器
model = keras.Sequential([keras.layers.Dense(1)])model.compile(# 指定优化器的名称:RMSprop(不区分大小写)optimizer="rmsprop",# 指定损失函数的名称:均方误差loss="mean_squared_error",# 指定指标列表:本例中只有精度metrics=["accuracy"])在上面对compile()的调用中,我们把优化器、损失函数和指标作为字符串(如"rmsprop")来传递。
这些字符串实际上是访问Python对象的快捷方式。
例如,"rmsprop"会变成keras. optimizers.RMSprop()。
重要的是,也可以把这些参数指定为对象实例。
如下所示:
model.compile(optimizer=keras.optimizers.RMSprop(),loss=keras.losses.MeanSquaredError(),metrics=[keras.metrics.BinaryAccuracy()])如果你想传递自定义的损失函数或指标,或者想进一步配置正在使用的对象,比如向优化器传入参数learning_rate,那么这种方法很有用。
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=1e-4),loss=my_custom_loss,metrics=[my_custom_metric_1, my_custom_metric_2])如何创建自定义的损失函数和指标?一般来说,你无须从头开始创建自己的损失函数、指标或优化器,因为Keras提供了下列多种内置选项,很可能满足你的需求。
咱们先简单列一些这里面的术语:
优化器:
SGD(带动量或不带动量)、RMSprop、Adam、Adagrad 等等
损失函数:
CategoricalCrossentropy、SparseCategoricalCrossentropy、BinaryCrossentropy、MeanSquaredError、KLDivergence、CosineSimilarity 等等
指标:
CategoricalAccuracy、SparseCategoricalAccuracy、BinaryAccuracy、AUC、Precision、Recall 等等
选择损失函数
为问题选择合适的损失函数,这是极其重要的。
神经网络会采取各种方法使损失最小化,如果损失函数与成功完成当前任务不完全相关,那么神经网络最终的结果可能会不符合你的预期。
想象一下,利用SGD训练一个愚蠢而又无所不能的人工智能体,损失函数选择得非常糟糕:“让所有活人的平均幸福感最大化。”为了简化工作,这个人工智能体可能会选择消灭绝大多数人类,只留下几个人并专注于这几个人的幸福,因为平均幸福感并不受人数的影响。但这可能并不是你想要的结果。请记住,你构建的所有神经网络在减小损失函数时都和上述人工智能体一样无情。因此,一定要明智地选择损失函数,否则你将得到意想不到的副作用。
幸运的是,对于分类、回归和序列预测等常见问题,可以遵循一些简单的指导原则来选择合适的损失函数。
例如,
对于二分类问题,可以使用二元交叉熵损失函数;
对于多分类问题,可以使用分类交叉熵损失函数。只有在面对全新的研究问题时,你才需要自己开发损失函数。
理解fit()方法
compile()之后将是fit()。
fit()方法执行训练循环,它有以下关键参数。
要训练的数据(输入和目标):这些数据通常以NumPy数组或TensorFlow Dataset对象的形式传入。
训练轮数:训练循环应该在传入的数据上迭代多少次。
在每轮小批量梯度下降中使用的批量大小:在一次权重更新中,计算梯度所要考虑的训练样本的数量。
下面代码展示了如何对NumPy数据调用fit():
history = model.fit(# 输入样本,一个NumPy数组inputs, # 对应的训练目标,一个NumPy数组targets,# 训练循环将对数据迭代5次epochs=5,# 训练循环的批量大小为128batch_size=128
)调用fit()将返回一个History对象。
监控验证数据上的损失和指标
机器学习的目标不是得到一个在训练数据上表现良好的模型——做到这一点很容易,你只需跟随梯度下降即可。
机器学习的目标是得到总体上表现良好的模型,特别是在模型前所未见的数据上。
一个模型在训练数据上表现良好,并不意味着它在前所未见的数据上也会表现良好。举例来说,模型有可能只是记住了训练样本和目标值之间的映射关系,但这对在前所未见的数据上进行预测毫无用处。
要想查看模型在新数据上的性能,标准做法是保留训练数据的一个子集作为验证数据(validation data)。你不会在这部分数据上训练模型,但会用它来计算损失值和指标值。实现方法是在fit()中使用validation_data参数,和训练数据一样,验证数据也可以作为NumPy数组或TensorFlow Dataset对象传入。
使用validation_data参数:
model = keras.Sequential([keras.layers.Dense(1)])
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=0.1),loss=keras.losses.MeanSquaredError(),metrics=[keras.metrics.BinaryAccuracy()])indices_permutation = np.random.permutation(len(inputs))
shuffled_inputs = inputs[indices_permutation]
shuffled_targets = targets[indices_permutation]num_validation_samples = int(0.3 * len(inputs))
val_inputs = shuffled_inputs[:num_validation_samples]
val_targets = shuffled_targets[:num_validation_samples]
training_inputs = shuffled_inputs[num_validation_samples:]
training_targets = shuffled_targets[num_validation_samples:]
model.fit(training_inputs, training_targets,epochs=5,batch_size=16,validation_data=(val_inputs, val_targets)
)在验证数据上的损失值叫作“验证损失”,以区别于“训练损失”。
请注意,必须将训练数据和验证数据严格分开:验证的目的是监控模型所学到的知识在新数据上是否真的有用。如果验证数据在训练期间被模型看到过,那么验证损失和指标就会不准确。
注意,如果想在训练完成后计算验证损失和指标,可以调用evaluate()方法。
loss_and_metrics = model.evaluate(val_inputs, val_targets, batch_size=128)evaluate()将对传入的数据进行批量迭代(批量大小为batch_size),并返回一个标量列表,其中第一个元素是验证损失,后面的元素是验证指标。如果模型没有指标,则只返回验证损失(不再是列表)。
推断:在训练后使用模型
一旦训练好了模型,就可以用它来对新的数据进行预测。这叫作推断(inference)。要做到这一点,一个简单的方法就是调用该模型(__call__())。
# 接收一个NumPy数组或TensorFlow张量,返回一个TensorFlow张量
predictions = model(new_inputs)但是,这种方法会一次性处理new_inputs中的所有输入,如果其中包含大量数据,那么这种方法可能是不可行的(尤其是,它可能需要比你的GPU更大的内存)。
要想进行推断,一种更好的方法是使用predict()方法。它将小批量地迭代数据,并返回预测值组成的NumPy数组。与__call__()不同,它还可以处理TensorFlow Dataset对象。
# 接收一个NumPy数组或Dataset对象,返回一个NumPy数组
predictions = model.predict(new_inputs, batch_size=128)对于前面训练的线性模型,如果对一些验证数据使用predict(),那么我们会得到一些标量值,对应于模型对每个输入样本的预测结果:
predictions = model.predict(val_inputs, batch_size=128)
print(predictions[:10])咱们对关于Keras模型的了解就这些。