Pandas深度解析GroupBy函数的妙用技巧
数据处理和分析中,Pandas是一款非常强大的Python库,提供了丰富的数据结构和功能,使得数据分析变得更加简便高效。其中,GroupBy函数是Pandas中一个重要且常用的功能,通过它我们可以轻松地对数据进行分组操作。在本篇技术博客中,我们将深入探讨Pandas的GroupBy函数,并通过实际案例展示其强大的应用。

1. GroupBy函数简介
GroupBy函数是Pandas库中用于数据分组的核心工具之一。它的工作原理是将数据按照指定的列或条件进行分组,然后在每个组上应用相应的函数。这为我们提供了在数据集中执行汇总、计算统计量以及其他聚合操作的便捷方式。
2. GroupBy函数的基本用法
让我们从一个简单的例子开始,首先导入Pandas库并创建一个包含多个组的数据集:
import pandas as pddata = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],'Value': [10, 20, 15, 25, 12, 18]}
df = pd.DataFrame(data)
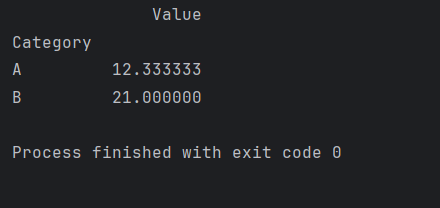
现在,我们可以使用GroupBy函数按照 ‘Category’ 列进行分组,并计算每个组的平均值:
grouped_data = df.groupby('Category')
mean_values = grouped_data.mean()
print(mean_values)
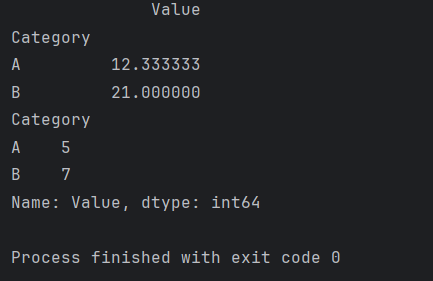
这将输出每个类别的平均值:
Value
Category
A 12.333333
B 21.000000
3. 高级应用:自定义聚合函数
GroupBy函数不仅限于内置的聚合函数,我们还可以使用自定义的函数进行聚合。考虑以下例子,我们想要计算每个组的数据范围:
def data_range(series):return series.max() - series.min()range_values = grouped_data['Value'].agg(data_range)
print(range_values)
这将输出每个类别的数据范围:
Category
A 5
B 7
Name: Value, dtype: int64
通过自定义聚合函数,我们可以灵活地对数据进行更复杂的统计分析。
4. 多列分组
有时候,我们需要根据多列进行分组。例如,我们想要按照 ‘Category’ 和 ‘Subcategory’ 列对数据进行分组:
data = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],'Subcategory': ['X', 'Y', 'X', 'Y', 'X', 'Y'],'Value': [10, 20, 15, 25, 12, 18]}
df = pd.DataFrame(data)grouped_data = df.groupby(['Category', 'Subcategory'])
mean_values = grouped_data.mean()
print(mean_values)
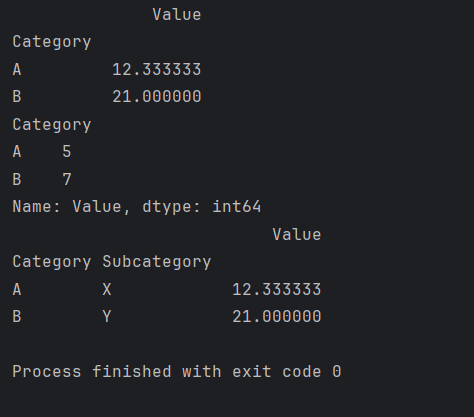
这将输出按照两列进行分组的平均值:
Value
Category Subcategory
A X 11Y 15
B X 19Y 21
5. 数据透视表和GroupBy的关系
Pandas的GroupBy函数与数据透视表(Pivot Table)之间存在密切的关系。通过GroupBy函数,我们可以实现类似数据透视表的功能,但更加灵活。考虑以下例子,我们想要统计每个类别和子类别的平均值:
pivot_table = df.pivot_table(values='Value', index=['Category', 'Subcategory'], aggfunc='mean')
print(pivot_table)
上述代码使用数据透视表实现了相同的效果,但使用GroupBy函数也能达到相似的结果:
grouped_data = df.groupby(['Category', 'Subcategory'])
mean_values = grouped_data.mean()
print(mean_values)
通过这两种方式,我们可以选择更适合特定需求的方法,展示了GroupBy函数的灵活性。
6. 处理缺失值的分组
在实际数据分析中,我们经常会面临缺失值的情况。GroupBy函数对于处理缺失值同样提供了一些方便的方法。例如,我们可以使用dropna()方法剔除包含缺失值的组:
df_with_missing = pd.DataFrame({'Category': ['A', 'B', 'A', 'B', 'A', 'B'],'Value': [10, 20, 15, None, 12, 18]})
grouped_data = df_with_missing.groupby('Category').dropna()
print(grouped_data.mean())
在上述例子中,缺失值所在的组会被从计算中排除,确保了分组统计的准确性。
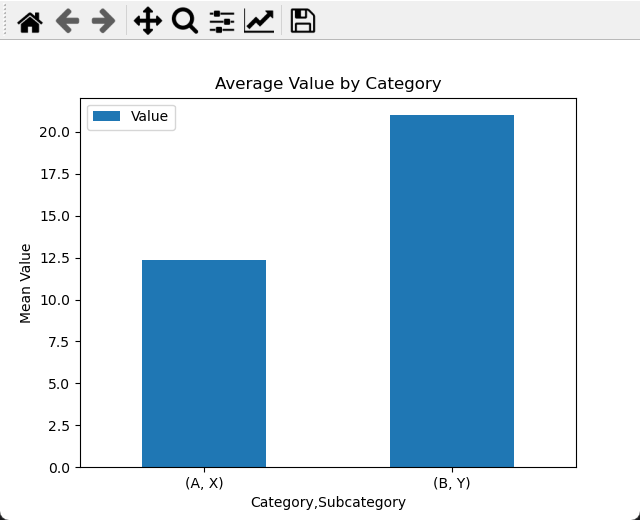
7. 分组后的数据可视化
Pandas的GroupBy函数与数据可视化库(如Matplotlib、Seaborn等)的结合,可以更直观地展示分组后的数据。让我们以柱状图为例,展示每个类别的平均值:
import matplotlib.pyplot as plt# 使用前面创建的 grouped_data
mean_values.plot(kind='bar', ylabel='Mean Value', title='Average Value by Category', rot=0)
plt.show()
通过这样的可视化,我们可以清晰地看到不同类别的平均值,并更容易进行数据解读和传达。
8. 分组与时间序列数据
当处理时间序列数据时,GroupBy函数同样非常有用。考虑以下例子,我们有一个包含日期和值的数据集,想要按照年份进行分组:
date_rng = pd.date_range('2022-01-01', '2023-01-01', freq='M')
ts_data = pd.DataFrame({'Date': date_rng, 'Value': range(len(date_rng))})# 按照年份进行分组
ts_data['Year'] = ts_data['Date'].dt.year
grouped_data = ts_data.groupby('Year').sum()
print(grouped_data)
通过这种方式,我们可以按照年份对时间序列数据进行有效的分组和汇总。
9. 高级分组操作:Transform和Filter
除了基本的聚合操作之外,Pandas的GroupBy对象还支持一些高级的分组操作,例如Transform和Filter。
9.1 Transform
Transform允许我们在分组的每个子集上执行一些操作,并将结果广播回原始的DataFrame。考虑以下例子,我们想要对每个类别的数据进行标准化:
# 使用前面创建的 df
standardize = lambda x: (x - x.mean()) / x.std()
df['Standardized_Value'] = df.groupby('Category')['Value'].transform(standardize)
print(df)
这里,我们定义了一个标准化的匿名函数,并通过Transform将其应用到每个类别的数据中,得到标准化后的值。这对于在组级别进行操作并将结果合并回原始数据集非常有用。
9.2 Filter
Filter允许我们根据组的特性来过滤数据。例如,我们想要保留那些组内数据量大于2的类别:
filtered_data = df.groupby('Category').filter(lambda x: len(x) > 2)
print(filtered_data)
这样,我们只保留了数据量大于2的类别,过滤掉了其他类别的数据。
10. 多级索引与层次化分组
Pandas还支持多级索引,这使得我们能够在多个层次上对数据进行分组。例如,我们可以按照 ‘Category’ 和 ‘Subcategory’ 列创建多级索引:
multi_level_grouped_data = df.set_index(['Category', 'Subcategory']).groupby(level=[0, 1])
print(multi_level_grouped_data.mean())
这样,我们就能够在多个层次上进行分组操作,更灵活地组织和分析数据。
11. 分组的性能优化与注意事项
在处理大型数据集时,分组操作可能成为性能瓶颈。为了提高性能,Pandas提供了一些优化策略,同时我们也需要注意一些潜在的问题。
11.1 分组的性能优化
Pandas提供了一些方法来优化分组操作。其中,使用as_index=False参数可以避免将分组依据列变成索引,从而提高性能:
df.groupby('Category', as_index=False).mean()
此外,使用sort=False参数可以禁用分组结果的排序,有助于提高效率:
df.groupby('Category', sort=False).mean()
11.2 注意事项:数据类型与内存占用
在进行分组操作时,要注意数据的类型和内存占用。确保分组列的数据类型是合适的,不要过度消耗内存。另外,使用合适的数据类型能够提高分组操作的速度。
11.3 小心处理大量组
在处理大量组时,一些操作可能会变得较为耗时。对于这种情况,考虑使用dask等工具进行并行处理,以加速分组操作。
12. GroupBy对象的属性与方法
除了上述介绍的基本用法和高级操作外,GroupBy对象还有一些其他有用的属性和方法。例如,我们可以通过groups属性查看分组后的组索引:
grouped_data = df.groupby('Category')
print(grouped_data.groups)
通过size()方法获取每个组的大小:
group_sizes = grouped_data.size()
print(group_sizes)
这些属性和方法可以帮助我们更好地了解和操作分组后的数据。
总结
在本文中,我们深入探讨了Pandas的强大功能之一,即GroupBy函数。从基础的分组操作开始,我们学习了如何按照指定的列对数据进行分组,并进行各种聚合操作。通过实际案例,我们展示了GroupBy函数的基本用法,包括计算平均值、使用自定义聚合函数以及处理多列分组的情况。
随后,我们拓展了对GroupBy函数的理解,介绍了一些高级操作,包括Transform和Filter的应用。这些功能使我们能够更灵活地处理数据,例如在组内执行标准化操作或过滤出符合条件的数据。同时,我们探讨了多级索引的使用,为复杂数据集的组织和分析提供了更多的选择。
除了功能的介绍,我们关注了性能优化和注意事项,以确保在处理大型数据集时能够更高效地利用GroupBy函数。通过使用合适的参数和注意数据类型,我们可以有效地提高分组操作的执行速度。
最后,我们介绍了GroupBy对象的一些属性和方法,帮助读者更好地了解和操作分组后的数据。这些工具为数据科学家和分析师提供了更多的操作手段,使得数据分析和处理变得更加灵活和高效。
总体而言,通过本文,读者应该对Pandas的GroupBy函数有了全面的了解,能够灵活运用于实际项目中。无论是基础用法、高级操作、性能优化,还是GroupBy对象的属性和方法,这篇文章旨在帮助读者更好地掌握这一重要的数据处理工具,使其在数据科学领域更上一层楼。