文章目录
- 引言
- 1. 蒸馏
- 1)白盒蒸馏
- DistilBERT
- Patient Knowledge Distillation
- TinyBERT 2020
- MiniLLM
- 2)黑盒蒸馏
- Stanford alpaca
- Vicuna
- Wizardlm
- Instruction tuning with gpt-4
- Minigpt-4
- 2. 剪枝
引言
本文中所有文章来源于综述综述文章
《Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems》
文章内容丰富,本文主要针对 Knowledge Distillation 和 Network Pruning相关部分参考文献进行汇总。
-
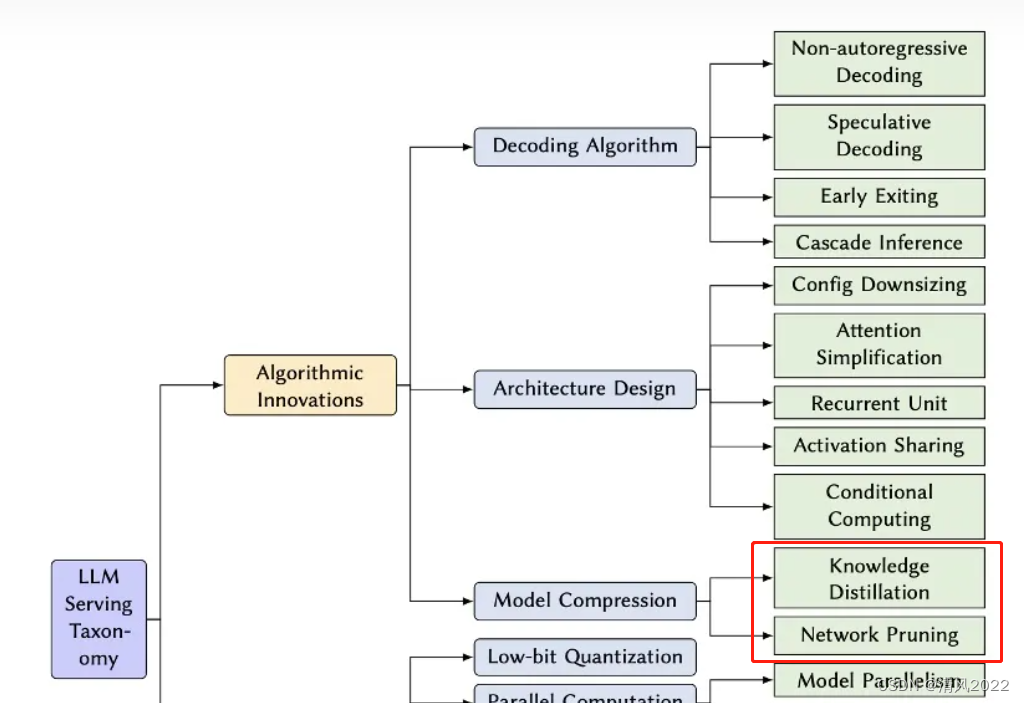
知识蒸馏:这类方法以大型的教师模型为监督,训练一个小型的学生模型。
- 白盒蒸馏:
大多数之前的方法都在探索白盒蒸馏,需要访问整个教师模型的参数。
- 黑盒蒸馏:
由于基于API的LLM服务(如ChatGPT)的出现,一些黑盒蒸馏模型吸引了很多关注,这些模型通常具有更少的模型参数,与原始LLMs(如GPT-4)相比,在各种下游任务上表现出了相当的性能。
-
网络剪枝:过去几年中,网络剪枝方法已被广泛研究,但并非所有方法都可以直接应用于LLMs,需要考虑重新训练可能带来的过高计算成本,以及评估剪枝是否可以在底层系统实现上取得效率提升。
大致上可以分为
-
结构化剪枝
-
半结构化稀疏
-
1. 蒸馏
1)白盒蒸馏
DistilBERT
《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.》2019
随着迁移学习在NLP领域越来越普及,在有限的GPU算力下用大型的model进行training or inference仍是一项具有挑战性的工作。
在本文的工作中,我们提出了一种更加通用的更轻型的pre-trained language model,DistilBERT。对比其他的大型Model,DistilBERT在下游的fine-tune 任务中,仍具有很好的效果。
前人的大多数研究都是基于蒸馏技术,构建某个具体领域的任务。而在本文的工作中在Pretrained 阶段利用了知识蒸馏技术,在保留97%的模型语言理解能力的条件下,减轻了40%模型的参数量,并且模型的推理速度提升了60%。
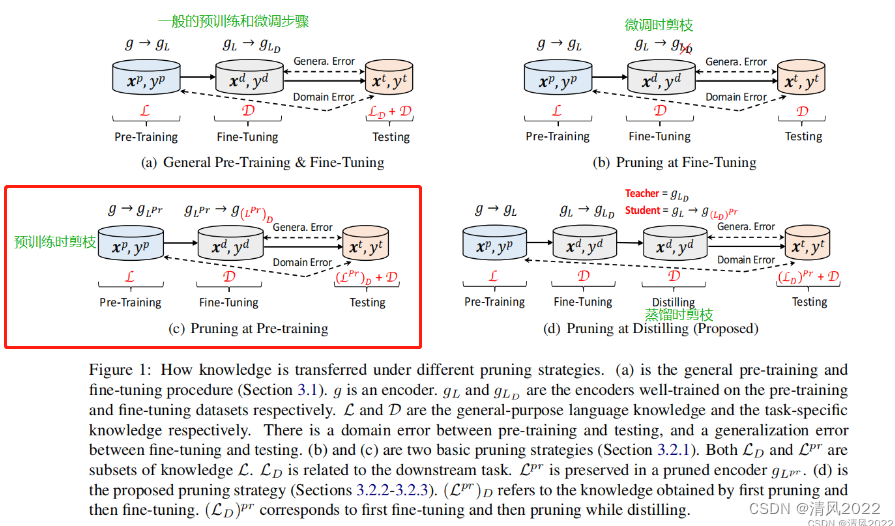
预训练时剪枝,不易复现
知乎笔记
Patient Knowledge Distillation
《Patient Knowledge Distillation for BERT Model Compression》
2019
文章介绍了一种bert模型压缩蒸馏的方法, 在vanilla 知识蒸馏方法的基础上,通过学习teacher网络中间层信息提高student网络表现。
摘要
预训练语言模型,如BERT,已被证明在自然语言处理(NLP)任务中非常有效。然而,在训练中对计算资源的需求很高,因此阻碍了它们在实践中的应用。
为了缓解大规模模型训练中的这种资源需求,本文提出一种Patient知识蒸馏, 将原始(老师)模型变成同样有效的轻量级浅网络(学生)。
以往的知识蒸馏方法:只使用教师网络的最后一层的输出。
不同于之前的方法,本文中学生模型耐心地从教师模型的多个中间层中学习,以实现增量知识提取,遵循以下两种策略:
(i) PKD-Last: 从最后k个中学习层;
(ii) PKD-Skip: 从每k层中学习。
这两个patient蒸馏方案能够利用教师网络隐藏层中的丰富信息,并鼓励学生模型耐心学习从和模仿老师通过一个多层次的蒸馏过程。
实验证明, 这转化为在多个方面的改进结果在不牺牲模型精度的情况下,显著提高训练效率的NLP任务。
知乎笔记
TinyBERT 2020
《TinyBERT:Distilling BERT for Natural Language Understanding》
论文
源码
这项工作的主要贡献如下:
1)我们提出了一种新的Transformer蒸馏方法,以鼓励将以BERT teacher编码的语言知识适当地转移给TinyBERT;
2)我们提出了一个新颖的两阶段学习框架,该框架在预训练和微调阶段 均执行提议的transformer蒸馏,从而确保TinyBERT可以吸收teacherBERT的一般领域知识和特定任务知识。
第一阶段:使用原始的BERT模型做完teacher,在通用语料上进行蒸馏得到 通用的 TinyBert
第二阶段: 在特定领域 增强的数据集上 使用finetune 后的BERT模型做为teacher, 继续进行蒸馏训练,得到最终的Tiny BERT
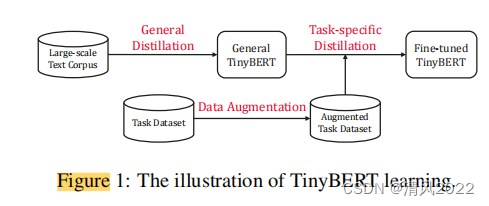
3)我们在实验中证明,我们的TinyBERT4可以在GLUE任务上实现teacher BERTBASE的性能超过96.8%,而参数(〜13.3%)和推理时间(〜10.6%)却少得多,并且明显优于其他有4层BERT蒸馏的最先进的基线.
4)我们还展示了6层TinyBERT可以与GLUE上的BERTBASE teacher媲美。
知乎笔记
MiniLLM
github: MiniLLM
《Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers》2020
《Minilm: 预训练语言模型通用压缩方法》
https://aka.ms/MiniLLM
预训练模型太大。模型太大对于微调和部署阶段的挑战主要有2点:推理时延大和占用内存空间大。
文章的模型压缩方法做到了通用性。现有方法很多是面向特定任务,而文章所提出的方法可以直接对预训练模型蒸馏,蒸馏后的模型可以直接在下游任务上微调。
提出了一种将基于Transformer预训练模型压缩成较小预训练模型的通用方法:MiniLM。这是一种深度自注意力知识蒸馏(Deep Self-Attention Distillation)方法,核心点:
(1)蒸馏teacher模型最后一层Transformer的自注意力模块
(2)在自注意模块中引入值之间的点积
(3)引入助教帮助模型蒸馏
在各种参数尺寸的student模型中,MiniLM的单语模型优于各种最先进的baselines。
在 SQuAD 2.0和GLUE的多个任务上以一半的参数和计算量,并保持99% accuracy。此外,将深度自注意力蒸馏方法应用到多语种预训练模型上也取得不错的结果。
实验
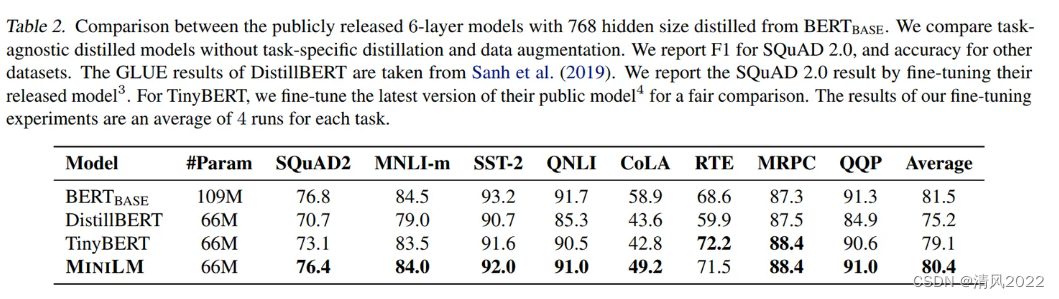
从实验结果可以看出,在多数任务上MiniLM都优于DistillBERT和TinyBERT。特别是在SQuAD2.0数据集和CoLA数据集上,MiniLM分别比最先进的模型高出3.0个F1值和5.0个accuracy。不同模型大小的推理时间对比可以参考Table 4。
亮点:直接对预训练模型蒸馏
知乎笔记
《Knowledge Distillation of Large Language Models》2023
知识蒸馏(KD)是一种很有前途的技术,可以减少大型语言模型(LLM)的高计算需求。
然而,以前的KD方法主要应用于白盒分类模型或训练小模型来模仿像ChatGPT这样的黑盒模型API。
本文主要研究如何有效地从白盒生成LLM中提取知识。
论文提出了MINILLM,它从生成的较大语言模型中提取较小的语言模型。
首先将标准KD方法中的前向Kullback-Leibler散度(KLD)目标替换为更适合生成语言模型上的KD的反向KLD,以防止学生模型高估教师分布的低概率区域。
然后,推导出一种有效的优化方法来学习这个目标。在指令跟随设置中的大量实验表明,MINILLM模型生成更精确的响应,具有更高的整体质量、更低的曝光偏差、更好的校准和更高的长文本生成性能。
论文方法也适用于具有120M到13B参数的不同模型族。我们将在https://aka.ms/MiniLLM发布我们的代码和模型检查点
实验
可以看出 miniLLM 的效果还是可以的,提高了 1~3 个点。
官方仓库说的是 16 * 32V100,比较费卡,还是很难复现的
参考资料
知乎笔记
CSDN博客
2)黑盒蒸馏
Stanford alpaca
《Stanford alpaca: An instruction-following llama model.》2023
项目代码
参考博客资料
Alpaca 是 LLaMA-7B 的微调版本,使用Self-instruct[2]方式借用text-davinct-003构建了52K的数据,同时在其构建策略上做了一些修改。
性能上作者对Alpaca进行了评估,与openai的text-davinct-003模型在self-instruct[2]场景下的性能表现相似。所以比起成本来看,Alpaca更便宜。
https://link.zhihu.com/?target=https%3A//crfm.stanford.edu/2023/03/13/alpaca.html)
Vicuna
《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.》2023
相关资料
https://zhuanlan.zhihu.com/p/618389519
https://lmsys.org/blog/2023-03-30-vicuna/
Wizardlm
《Wizardlm: Empowering large language models to follow complex instructions.》2023
利用开放域的指令数据训练大语言模型(LLM)取得了巨大成功。然而,手动创建此类指令数据非常耗时费力。此外,人类可能难以生成高难度的指令。
本文展示了一种利用 LLM 代替人类创建具有不同复杂度的大量指令数据的方法。
从一组初始指令开始,我们使用提出的 Evol-Instruct 逐步将其重写为更复杂的指令。
然后,我们混合所有生成的指令数据,对 LLaMA 进行微调。
我们将生成的模型称为 WizardLM。
在复杂性平衡的测试集和 Vicuna 的测试集上进行的人工评估表明,来自 Evol-Instruct 的指令优于人工创建的指令。
通过分析高难度部分的人工评估结果,我们证明了 WizardLM 的输出结果优于 OpenAI ChatGPT 的输出结果。
在 GPT-4 自动评估中,WizardLM 在 29 个技能中的 17 个技能上实现了超过 ChatGPT 90% 的能力。尽管 WizardLM 在某些方面仍落后于 ChatGPT,但我们的研究结果表明,使用 AI 改进的指令进行微调是增强 LLM 的一个有前途的方向
[论文笔记] WizardLM: Empowering Large Language Models to Follow Complex Instructions
Instruction tuning with gpt-4
《 Instruction tuning with gpt-4.》
2023
Minigpt-4
《Minigpt-4: Enhancing vision-language understanding with advanced large language models.》2023
《CoRR abs/2303.08774 》(2023)
相关资料
https://doi.org/10.48550/arXiv.2303.08774
https://zhuanlan.zhihu.com/p/627671257
2. 剪枝
16个注意力头比一个好吗
《 Are sixteen heads really better than one? Advances in neural information processing systems * 32》
(2019)
自Vaswani等人提出transformer模型以来,transformer模型已经成为NLP研究的主要内容。它们被用于机器翻译,语言模型,并且是最新最先进的预训练模型。典型的transformer架构由堆叠的块组成,图1中显示了其中的一块。这种块由一个多头部注意层和一个每个位置的2层前馈网络组成,并与残差连接和层归一化连接在一起。多头注意机制的普遍应用可以说是transformer的核心创新。
在这篇博客文章中,我们将仔细研究这种多头注意力机制,试图理解多头实际上有多重要。
Transformer中16个注意力头一定要比1个注意力头效果好吗?
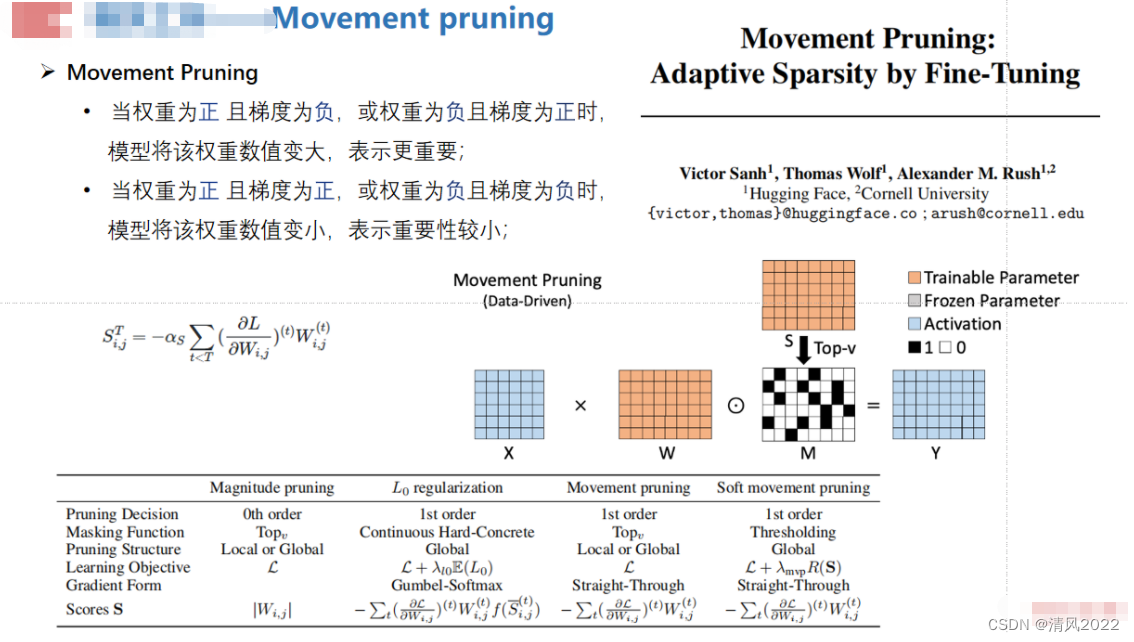
Movement pruning
《Movement pruning: Adaptive sparsity by fine-tuning. Advances in Neural Information Processing Systems* 33 》(2020)
1)结构化剪枝
Transformer压缩
《Reducing Transformer Depth on Demand with Structured Dropout》2019
这篇paper是做Transformer压缩的,但其实bert的核心也就是transformer,这篇paper的实验里也做了bert的压缩。作者的主要工作是提出了LayerDrop的方法,即一种结构化的dropout的方法来对transformer模型进行训练,从而在不需要fine-tune的情况下选择一个大网络的子网络。
这篇paper方法的核心是通过Dropout来去从大模型中采样子网络,但是这个dropout是对分组权重进行dropout的,具体而言,这篇paper是layerwise的dropout,可见下图:
作者提出的方法是用LayerDrop的方法只 训练一遍网络 ,然后在测试的时候可以根据不同的需求来选择不同的深度。
论文阅读:Reducing Transformer Depth On Demand With Structured Dropout
Ziplm
《 Ziplm: Hardware-aware structured pruning of language models.》2023
LLM-Pruner
《 LLM-Pruner: On the Structural Pruning of Large LanguageModels. 》 2023
剪枝+少量数据+少量训练 = 高效的Large Language Models压缩
大语言模型(LLMs, Large Language Models)在各种任务上展现出了强大的能力,这些能力很大程度上来自于模型巨大的参数量以及海量的训练语料。为了应对这些规模上存在的挑战,许多研究者开始关注大语言模型的轻量化问题。
本文主要讨论一种基于结构化剪枝的方案,它能够“物理地”移除冗余的结构和参数,同时保留大部分原模型已经学习到的参数,实现高效的大语言模型压缩。
NeurIPS 2023 | LLM-Pruner: 大语言模型的结构化剪枝
GUM
《What Matters In The Structured Pruning of Generative Language Models? 》
2023
自回归大语言模型GPT-3 需要巨大的计算资源,这样会导致巨大的经济损失和环境影响。
结构化的剪枝方法传统上减少资源使用,然而这些剪枝方法对生成语言模型的应用和有效性还没有被研究。
我们分析了gpt这类模型中模型中MLP层的剪枝带来magnitude, random, and movement 方面的影响。
我们发现对这些模型movement 可能表现不佳,而随机剪枝几乎与最好的方法匹配。
移动对这些模型来说可能表现不佳,而随机剪枝几乎可以达到最好的方法。
通过检查神经元水平的冗余量,我们发现了movement 不会根据神经元与其他神经元相比的独特性来选择,因此会留下多余的冗余。
鉴于此,我们引入Globally Unique Movement (GUM),全局独特运动,根据独特性和敏感性来选择神经元。
我们还讨论了这些技术在不同冗余量上的作用,并进行了详细的比较和消融实验。
Deja vu
《Deja vu: Contextual sparsity for efficient llms at inference time》2023
https://github.com/FMInference/DejaVu.
Deja Vu利用上一个layer的activations来预测下一层(实际上为了隐藏这个predictor的开销,文章提到了是异步地预测下层,但是原理上取下层没问题)的sparsity,决定需要保留MLP blocks的哪些neuros和attention block的heads。
该方法是dynamic selection而不是static pruning,比一些unstructured pruning 方法(比如SparseGPT和Wanda)针对hardware有更多的优化。
与最先进的FasterTransformer相比,在OPT-175B上Deja vu可降低2倍的推理时间,
与目前广泛使用的Hugging Face相比,降低6倍的推理时间,同时保证模型的质量。
2)半结构化稀疏
FastBERT
《Exponentially Faster Language Modelling》
github地址
2023
本文提出一种BERT变体FastBERT,在推理时只使用0.3%的神经元,但性能与类似的BERT模型相当。用快速前馈网络(FFFs)替换前馈网络,同时有选择地使用每层12个神经元。虽然目前还没有真正高效的实现方法能够完全释放条件神经执行(CNE)的加速潜力,但作者提供了高效的CPU代码,该代码相对于优化的基础前馈实现(feedforward implementation)可以提升78倍的速度,同时作者还提供了一个PyTorch实现,该实现相对于等效的批量前馈推理(batched feedforward inference)可以提升40倍的速度。

训练阶段:we train every model for 1 day on a single A6000 GPU
SparseGPT
《SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot》2023
本文提出了首个可以在千亿参数模型上高效准确工作的一次性剪枝算法——SparseGPT。该方法将剪枝问题简化为极大规模的稀疏回归问题,并设计了一个新的近似稀疏回归求解器,也解决分层剪枝问题。
SparseGPT 可以在最大的开源 GPT 模型(1750 亿参数)上仅用单个 GPU 耗时几小时就完成剪枝。同时,在无需任何微调的情况下,修剪上千亿(50~60%)参数后模型的精度几乎不变(甚至提升)。SparseGPT 还可以轻松地推广到半结构化剪枝(2:4 和 4:8),并且与权重量化方法结合。
GPT-3剪枝算法来了!无需微调,1750亿参数模型剪50%还提点
《 A Simple and Effective Pruning Approach for Large Language Models. 》
2023
在人工智能研究中,大型语言模型(LLM)的优化仍然是一个重大挑战,对于推进该领域的实际应用和可持续性至关重要。本文以麻省理工学院宋瀚教授实验室的基础工作为基础,介绍了一种通过上下文剪枝开发 Mini-GPT 的新方法。我们的方法策略性地修剪了传统法学硕士的计算架构,专注于保留核心功能,同时大幅减小模型大小。我们在各种复杂的数据集上采用该技术,包括美国法律、医学问答、天际对话、英台翻译和经济学文章。结果强调了上下文修剪的效率和有效性,不仅作为一个理论概念,而且作为开发特定领域、资源高效的法学硕士的实用工具。上下文修剪是构建特定领域法学硕士的一种有前途的方法,这项研究是未来发展的基石,具有更多的硬件计算、精细的微调和量化。
Mini-GPTs
《 Mini-GPTs: Efficient Large Language Models through Contextual Pruning》2023
在人工智能研究中,优化大型语言模型(LLMs)仍然是一个重大挑战,对于推进该领域的实际应用和可持续性至关重要。本文在麻省理工学院韩松教授实验室的基础研究基础上,介绍了一种通过上下文修剪来开发Mini-GPTs的新方法。我们的方法有策略地修剪传统LLMs(如Phi-1.5)的计算架构,重点保留核心功能,同时大幅减小模型大小。我们在包括美国法律、医学问答、天际之城对话、英台翻译和经济文章等多样复杂的数据集上采用了这种技术。结果强调了上下文修剪的效率和有效性,不仅仅是一个理论概念,而是一个开发特定领域、资源高效的LLMs实用工具。上下文修剪是构建特定领域LLMs的一种有前途的方法,本研究是未来更多硬件计算、精细调整和量化开发的基石。
Compress, Then Prompt
《 Compress, Then Prompt: Improving Accuracy-Efficiency Trade-off of LLM Inference with Transferable Prompt》2023
虽然LLM模型巨大的参数量带来优秀的性能,但这种大规模使它们低效且需要内存。
因此, LLM模型很难部署在商用硬件上,例如单个GPU。
给定内存和设备的功耗限制,模型压缩方法被广泛采用,可以以降低功耗模型大小和推理延迟,这本质上在模型精度和模型效率做了权衡。
因此想要在普通硬件上的部署,优化这种精度-效率的权衡对LLM至关重要。
本文引入了一种新的视角来优化压缩模型。
具体来说,我们首先注意到针对特定的问题,压缩的LLM的生成质量可以通过添加精心设计的硬提示 显著提高,但并非所有问题都是如此。
基于这样的观察,本文提出一种soft prompt学习方法,针对提示学习过程暴露压缩模型,目的是提高prompt的性能。
实验结果表明,soft prompt策略极大地提高了8×文本的性能压缩的lama - 7b模型(具有联合的4位量化和50%的权重修剪压缩),使它们能够在流行的基准上匹配未压缩的对应模型。
此外,证明了这些学习到的提示可以在各种数据集之间迁移,任务和压缩级别。
因此,有了这种可迁移性,可以将soft prompt缝合到一种新的压缩模型以"原地"的方式提高测试时的精度。