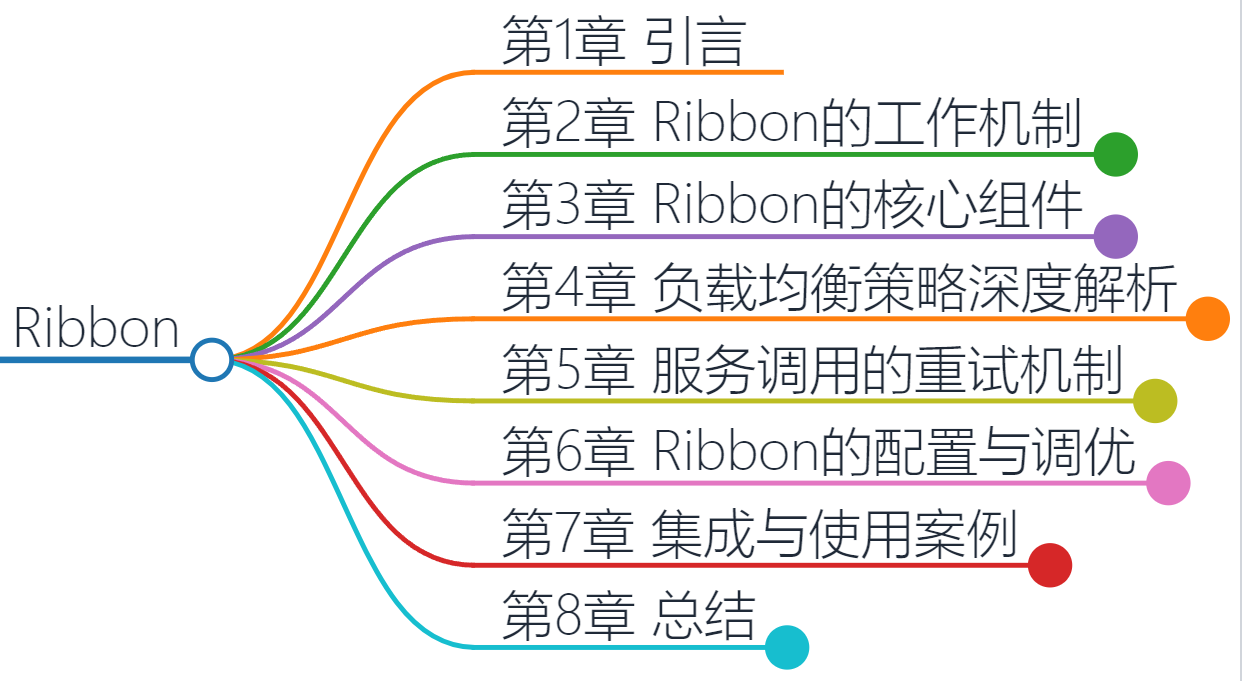
在数据分析中,了解数据的类型是非常重要的。数据类型决定了可以对数据进行哪些操作,以及如何对数据进行分析和处理。

常用的数据类型包括:
-
数值型数据:包括整数(int)和浮点数(float)。整数用于表示没有小数部分的数字,而浮点数用于表示带有小数部分的数字。
-
字符型数据:用于表示文本数据。字符型数据可以是单个字符(char)或字符串(string)。
-
逻辑型数据:用于表示真假值。逻辑型数据只有两个取值:True和False。
此外,还有一种特殊的数据类型称为缺失值。缺失值(Missing Values)指的是数据中的空值或无效值。缺失值在数据分析中很常见,可能是由于测量或记录错误导致的。
处理缺失值是数据分析的一个重要部分。常见的处理方法包括:
-
删除缺失值:如果缺失值的比例很小,可以选择删除包含缺失值的行或列。
-
替换缺失值:可以用特定的值(如均值、中位数或众数)替换缺失值,以保持数据整体的统计特性。
-
插值:以一定的方式推断缺失值,并用推断值来填充缺失值。
通过对数据类型和缺失值的了解,可以更好地理解和分析数据,从而做出准确的决策。
这是咱们这个系列文章的最后一篇,演练的数据还是从我的第三篇文章中下载:
政安晨:快速学会~机器学习的Pandas数据技能(三)(重命名与合并)![]() https://blog.csdn.net/snowdenkeke/article/details/136081348
https://blog.csdn.net/snowdenkeke/article/details/136081348
开始
在这篇文章中,你将学习如何在DataFrame或Series中进行数据类型的调查。你还将学习如何查找和替换条目。
数据类型
数据帧(DataFrame)或系列(Series)中列的数据类型被称为dtype。
您可以使用dtype属性来获取特定列的类型。例如,我们可以获取reviews数据帧中price列的dtype。
还记得吗,依旧是这段代码:
import pandas as pd
reviews = pd.read_csv("./winemag-data-130k-v2.csv", index_col=0)
pd.set_option('display.max_rows', 5)咱们加载了数据集之后,看一下它的数据类系:
reviews.price.dtype
另外,dtypes属性返回DataFrame中每一列的数据类型:
reviews.dtypes
数据类型告诉我们一些关于pandas如何在内部存储数据的信息。float64意味着它使用64位浮点数;int64表示使用类似大小的整数,依此类推。
要记住的一个特殊情况(在这里非常明显)是,完全由字符串组成的列不会获得自己的类型;相反,它们被赋予了对象类型。
可以使用astype()函数将一种类型的列转换为另一种类型,只要这种转换有意义。例如,我们可以将points列从其现有的int64数据类型转换为float64数据类型:
reviews.points.astype('float64')
DataFrame或Series索引也有自己的数据类型(dtype):
reviews.index.dtype
Pandas还支持更特殊的数据类型,如分类数据和时间序列数据。由于这些数据类型很少使用,我们将在本教程的后面部分省略它们。
缺失数据
缺失值的条目被赋予NaN的值,NaN代表“非数字”。出于技术原因,这些NaN值始终是float64数据类型。
Pandas提供了一些特定于缺失数据的方法。要选择NaN条目,可以使用pd.isnull()(或其伴侣pd.notnull())。这是为以下方式而设计的:
reviews[pd.isnull(reviews.country)]
替换缺失值是一种常见操作。Pandas提供了一个非常方便的方法来解决这个问题:fillna()。fillna()提供了几种不同的策略来处理这样的数据。例如,我们可以简单地将每个NaN替换为"Unknown":
reviews.region_2.fillna("Unknown")
或者我们可以使用在给定记录之后的第一个非空值填充每个缺失值。这被称为后向填充策略。replace()方法在这里值得一提,因为它对于替换数据集中给定某种哨兵值的缺失数据非常方便:比如“未知”,“不公开”,“无效”等等。
我们这个系列的文章暂且告一段落,大家浏览下这个系列的文章,就可以对Pandas有个概况性了解啦!