目录
背景
实现
设置状态
存储
获取key函数
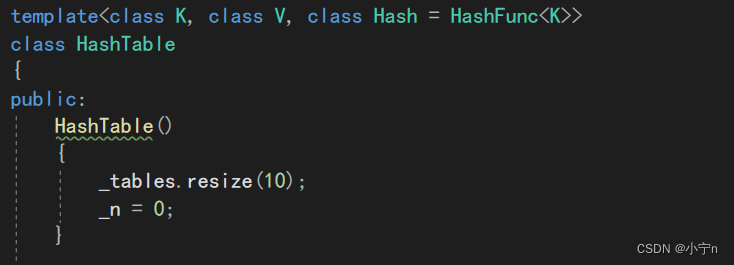
构造函数
插入
查找
删除
打印
完整代码
背景
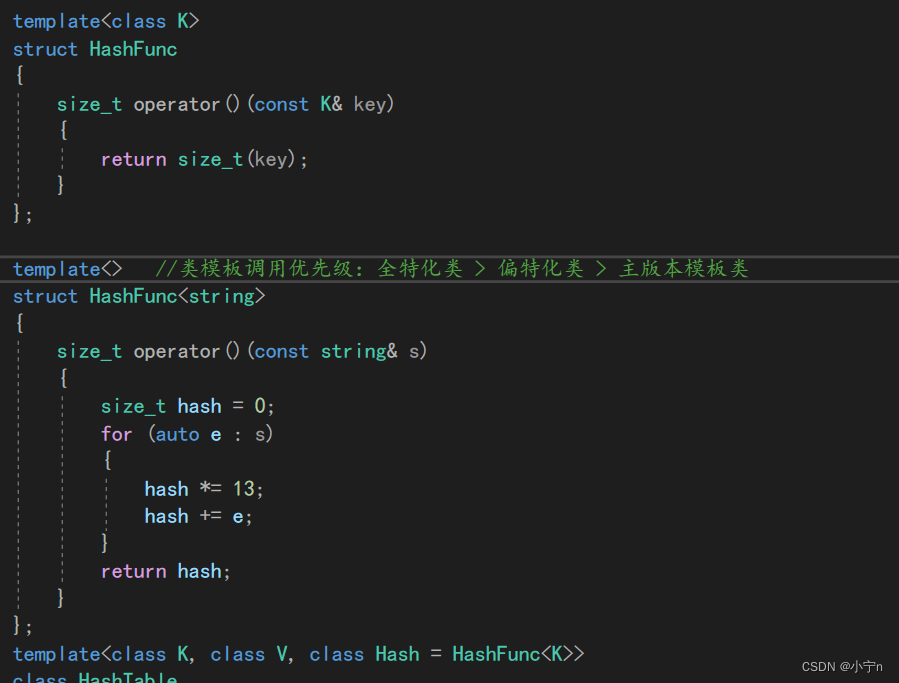
常用哈希函数
除留取余法
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希
函数:H a s h ( K e y ) = K e y % p ( p < = m ) ,将关键码转换成哈希地址。
优点:使用场景广泛,不受限制。
缺点:存在哈希冲突,需要解决哈希冲突,哈希冲突越多,效率下降越厉害。
解决冲突的方法:
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表种必然还有空位置,那么可以把产生冲突的元素存放到冲突位置的“下一个”空位置中去
当前位置被占用,开放空间里按照某种规则找一个没有被占用的位置存储
1.线性探测法:hashi+i (i>=0)
2.二次探测法:hashi+i^2 (i>=0)
实现
我们这里实现主要采用线性探测法
设置状态

存储
这里我们定义结构体来保存该位置的数据和状态,设置一个存储该结构体的·vector来实现,并用n
来保存有效元素的个数

获取key函数
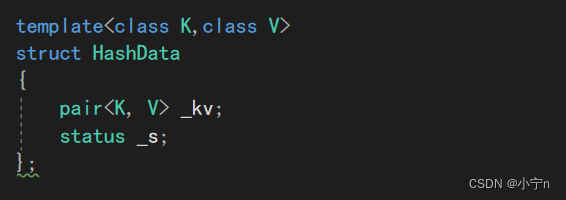
这里我们需要用key来%数组的size来获取该元素的位置,如果是int类型我们可以%,但如果是string类型我们就不能直接取模
构造函数
插入
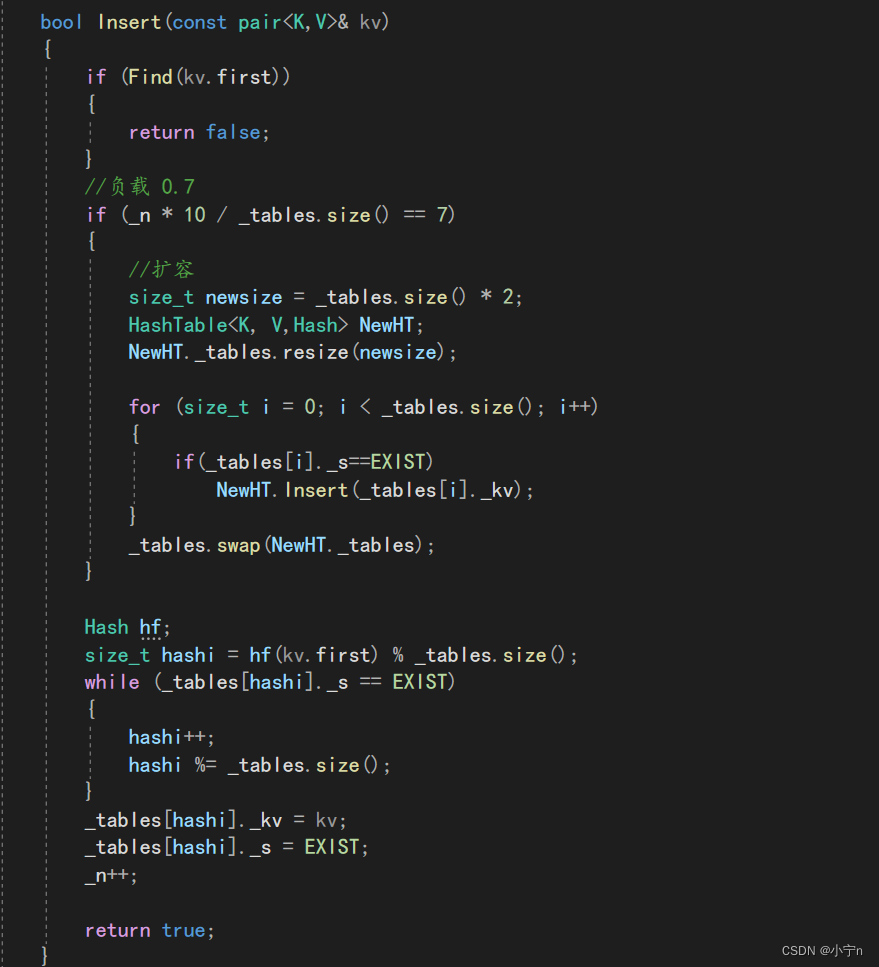
查找

删除
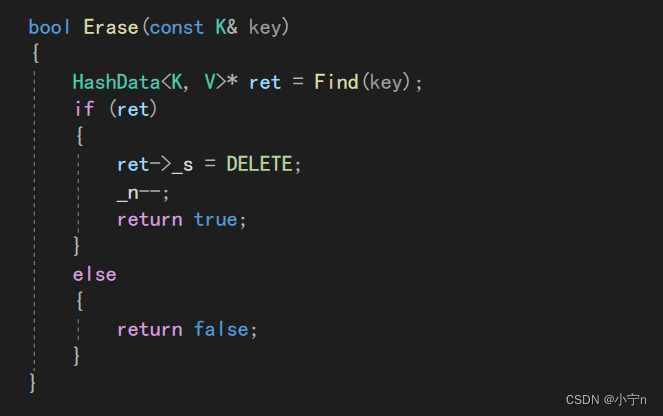
打印

完整代码
#pragma oncenamespace Hash_Close
{enum status{EMPTY, //空EXIST, //存在DELETE //删除};template<class K,class V>struct HashData{pair<K, V> _kv;status _s;};template<class K>struct HashFunc{size_t operator()(const K& key){return size_t(key);}};template<> //类模板调用优先级:全特化类 > 偏特化类 > 主版本模板类struct HashFunc<string>{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash *= 13;hash += e;}return hash;}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:HashTable(){_tables.resize(10);_n = 0;}bool Insert(const pair<K,V>& kv){if (Find(kv.first)){return false;}//负载 0.7if (_n * 10 / _tables.size() == 7){//扩容size_t newsize = _tables.size() * 2;HashTable<K, V,Hash> NewHT;NewHT._tables.resize(newsize);for (size_t i = 0; i < _tables.size(); i++){if(_tables[i]._s==EXIST)NewHT.Insert(_tables[i]._kv);}_tables.swap(NewHT._tables);}Hash hf;size_t hashi = hf(kv.first) % _tables.size();while (_tables[hashi]._s == EXIST){hashi++;hashi %= _tables.size();}_tables[hashi]._kv = kv;_tables[hashi]._s = EXIST;_n++;return true;}HashData<K, V>* Find(const K& key){Hash hf;size_t hashi = hf(key) % _tables.size();while (_tables[hashi]._s != EMPTY){if (_tables[hashi]._s == EXIST&& _tables[hashi]._kv.first == key){return &_tables[hashi];}hashi++;hashi %= _tables.size();}return NULL;}bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret){ret->_s = DELETE;_n--;return true;}else{return false;}}void Print(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._s == EXIST){cout << '[' << i << "]->" << _tables[i]._kv.first << ":" << _tables[i]._kv.second << endl;}else if (_tables[i]._s == EMPTY){printf("[%d]->\n", i);}else{printf("[%d]->D\n", i);}}cout << endl;}private:vector<HashData<K, V>> _tables;size_t _n; //存储有效元素的个数};void test1(){HashTable<int, int> ht;int a[] = { 4,14,24,34,5,7,1 };for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(3, 3));ht.Insert(make_pair(3, 3));ht.Insert(make_pair(-3, -3));ht.Print();ht.Erase(3);ht.Print();if (ht.Find(3)){cout << "3存在" << endl;}else{cout << "3不存在" << endl;}ht.Insert(make_pair(3, 3));ht.Insert(make_pair(23, 3));ht.Print();}void test2(){string arr[] = { "香蕉", "甜瓜","苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };//HashTable<string, int, HashFuncString> ht;HashTable<string, int> ht;for (auto& e : arr){//auto ret = ht.Find(e);HashData<string, int>* ret = ht.Find(e);if (ret){ret->_kv.second++;}else{ht.Insert(make_pair(e, 1));}}ht.Print();ht.Insert(make_pair("apple", 1));ht.Insert(make_pair("sort", 1));ht.Insert(make_pair("abc", 1));ht.Insert(make_pair("acb", 1));ht.Insert(make_pair("aad", 1));ht.Print();}
}




![[Java][算法 双指针]Day 02---LeetCode 热题 100---04~07](https://img-blog.csdnimg.cn/direct/ed8abce2a0224698b7127256fe909d00.png)