LongQLoRA
- 核心问题
- 子问题1: 预定义的上下文长度限制
- 子问题2: 训练资源的需求高
- 子问题3: 保持模型性能
- 分析不足
- LongQLoRA方法拆解
- 子问题1: 上下文长度限制
- 子问题2: 高GPU内存需求
- 子问题3: 精确量化导致的性能损失
- 分析不足
- 效果
论文:https://arxiv.org/pdf/2311.04879.pdf
代码:https://github.com/yangjianxin1/LongQLoRA
核心问题
为了扩展大型语言模型(如LLaMA系列)的上下文长度,本文介绍一个有效且高效的方法——LongQLoRA。
子问题1: 预定义的上下文长度限制
- 背景: LLaMA系列模型(例如LLaMA和LLaMA2)在训练时设置了预定义的上下文长度(如2048和4096个token),使用的位置编码(RoPE)在超出预定义长度时性能急剧下降。
- 相关联想: 在多文档问答、书籍摘要、长对话摘要等任务中,长输入上下文常常是必需的,这些任务因为上下文长度限制而难以达到最佳性能。
- 子解法: Position Interpolation和Shift Short Attention结合,通过位置插值技术和短注意力偏移来扩展模型处理的上下文长度,无需大规模重新训练。
子问题2: 训练资源的需求高
- 背景: 扩展上下文长度的直接方法如进一步预训练需要大量的GPU资源和较长的收敛时间,对于大多数研究者来说是不现实的。
- 相关联想: 比如Meta的Position Interpolation技术虽然有效但需要32个A100 GPUs,而Focused Transformer(FOT)需要128个TPUs,这对普通研究者来说是不可承受的。
- 子解法: LongQLoRA采用了QLoRA的量化微调方法,通过将预训练的大型语言模型量化为4比特来减少模型内存占用,并添加少量的可学习低秩适配器权重,大大减少了对训练资源的需求。
子问题3: 保持模型性能
- 背景: 在减少模型训练资源需求的同时,保持或提升模型在长上下文任务上的性能是一个挑战。
- 相关联想: 通常,减少模型大小或简化训练过程可能会牺牲模型性能。
- 然而,有效的上下文长度扩展不仅需要减轻资源负担,还要确保模型能够有效处理长文本输入。
- 子解法: LongQLoRA通过结合QLoRA、Position Interpolation和Shift Short Attention,不仅减少了对资源的需求,还通过在所有层添加低秩适配器权重,优化了模型结构以提高处理长上下文输入的能力,从而在PG19和Proof-pile数据集上展现出了优异的性能。
分析不足
LongQLoRA方法的全流程分析显示,该方法在扩展LLaMA系列模型的上下文长度方面既高效又有效。
它通过精心设计的结合了几种关键技术,使得在单个V100 GPU上就能将LLaMA2的上下文长度从4096扩展到8192甚至更长,同时在性能上不仅超越了LongLoRA,还接近于经过大量资源训练的MPT-7B-8K模型。
然而,尽管LongQLoRA在资源效率和性能上取得了显著进步,但它依赖于特定的硬件配置(如32GB内存的V100 GPU),这可能限制了它在不同研究和开发环境中的应用。
此外,尽管已经在PG19和Proof-pile数据集上进行了评估,但在更广泛的NLP任务和更多样化的数据集上的表现仍然是一个开放的问题。
LongQLoRA方法拆解
子问题1: 上下文长度限制
- 背景: LLaMA系列模型使用基于RoPE的位置编码,其在预定义的上下文长度之外性能急剧下降,限制了模型处理长文本的能力。
- 子解法: 位置插值(Position Interpolation)。
- Meta提出的位置插值技术通过在预定义的位置空间内进行位置编码插值,扩展了LLaMA模型的上下文窗口大小,无需直接训练即可将上下文长度从2048扩展到32768。
- 例子: 使用位置插值,仅需1000步的微调,就能显著提升LLaMA模型在长文本处理(如PG19数据集)上的性能。
子问题2: 高GPU内存需求
- 背景: 标准自注意力机制的计算复杂度为O(n^2),导致高GPU内存消耗。
- 子解法: 短程注意力偏移(Shift Short Attention)。
- LongLoRA提出的短程注意力偏移是一种稀疏的局部注意力机制,通过将输入token分组并单独计算每组内的注意力(以及邻近组之间的注意力),显著降低了GPU内存需求。
- 例子: 假设输入token被分成g组,计算复杂度可以从 O ( n 2 ) O(n^2) O(n2)降低到O((n/g)^2),有效减少了GPU内存消耗。
子问题3: 精确量化导致的性能损失
- 背景: 在限制GPU资源的情况下,如何在保证模型性能的同时减少模型的内存占用成为一个挑战。
- 子解法: QLoRA。
- QLoRA通过将预训练模型的权重量化为4位,并添加可学习的低秩(LoRA)适配器权重,既减少了GPU内存占用又保留了全精度微调任务的性能。
- 例子: QLoRA使得在单个48GB GPU上微调LLaMA 65B模型成为可能,同时保留了与全精度微调相当的性能水平。
分析不足
LongQLoRA通过结合位置插值、短程注意力偏移和QLoRA的优势,有效解决了大型语言模型在处理长上下文时的挑战。
首先,使用位置插值扩展LLaMA2的上下文长度;然后,通过QLoRA的权重量化和低秩适配器减少GPU内存需求;最后,利用短程注意力偏移进一步节省内存,并在所有层添加LoRA适配器以恢复由于量化而损失的性能。
然而,这种方法的一个潜在不足是它依赖于特定技术的组合,这可能限制了它在不同模型和任务上的通用性和灵活性。
例如,虽然短程注意力偏移在节省GPU内存方面非常有效,但它可能需要针对特定的任务和数据集进行调整。
此外,尽管QLoRA在减少内存占用方面表现出色,但量化策略的选择和适配器权重的调整可能需要根据具体情况进行细微调整,以最大化性能。
效果
基于LongQLoRA实验部分的讨论,可以得出以下结论:
-
上下文长度扩展有效性:通过位置插值技术,LongQLoRA成功将LLaMA2和Vicuna模型的上下文长度从4096扩展到8192,实验证明了该方法在扩展大型语言模型处理长文本的能力方面的有效性。
-
内存效率与性能保持:通过QLoRA的权重量化和LoRA适配器的添加,LongQLoRA在仅使用单个V100 GPU的条件下实现了模型的微调,既节约了GPU内存,又保持了模型性能,证明了在资源受限情况下进行模型优化的可行性。
-
微调策略的优化:实验表明,在微调阶段使用短程注意力偏移和在推理阶段使用标准全局注意力的策略有效提高了模型的性能和兼容性。这种策略在提高计算效率的同时,确保了模型在长文本处理任务上的优异表现。
-
模型性能对比:与其他方法(如LongLoRA和MPT-7B-8K)相比,LongQLoRA在PG19和Proof-pile数据集上的困惑度评估中表现出更优或接近的性能。特别是在8192上下文长度的评估中,LongQLoRA的性能与最先进的方法相当,甚至略有优势。
-
资源效率的显著提高:LongQLoRA的实现仅需单个V100 GPU,与需要多个A100 GPUs或TPUs的方法相比,大大降低了对训练资源的需求,展示了在有限资源下扩展和优化大型语言模型的高效途径。
-
微调步骤与LoRA秩的影响:通过不同LoRA秩的对比实验和微调步骤的分析,发现适当增加LoRA秩和微调步骤能够进一步降低模型的困惑度,表明微调策略的细微调整对模型性能有显著影响。
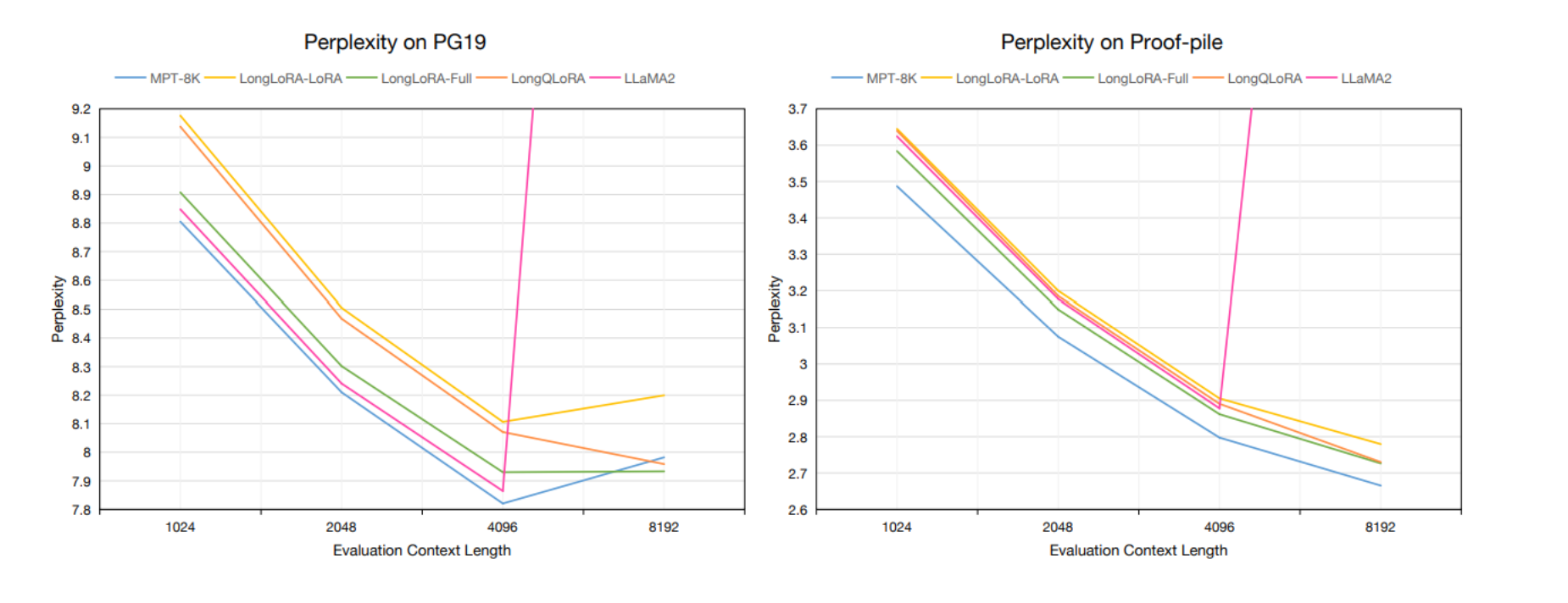
这张图展示了在不同上下文长度下,不同模型在PG19验证集和Proof-pile测试集上的困惑度(Perplexity)表现。
困惑度是衡量语言模型性能的一个标准指标,困惑度越低,模型的性能通常认为越好。
-
左侧图表(Perplexity on PG19):
- 展示了在PG19数据集上,从1024到8192的不同评估上下文长度下,MPT-7B-8K、LongLoRA-LoRA、LongLoRA-Full、LongQLoRA和LLaMA2-7B模型的困惑度。
- 在8192长度下,LongQLoRA的困惑度与LongLoRA-Full非常接近,且比MPT-7B-8K表现得更好。
-
右侧图表(Perplexity on Proof-pile):
- 展示了在Proof-pile数据集上,相同上下文长度变化下的困惑度表现。
- 在这个图表中,LongQLoRA在所有上下文长度下都略微优于LongLoRA-LoRA,并在8192长度下与LongLoRA-Full几乎持平。
两个图表都显示,所有模型在推理时均以4-bit进行量化。
LongQLoRA模型是基于Redpajama数据集在单V100 GPU上微调1000步得到的。
这两个图表还强调了LLaMA2-7B模型在超出其预定义上下文长度8192时性能下降的情况。
相比之下,LongQLoRA能够在更长的上下文长度上维持低困惑度,表明其扩展上下文长度的有效性。
LongQLoRA在1024到8192的上下文长度范围内超越了LongLoRA-LoRA,并在8192的长度上极接近LongLoRA-Full,甚至在PG19数据集上的表现优于MPT-7B-8K。