目录
1.结构体
1.1 结构的基础知识
1.2 结构的声明
1.2.1特殊的声明(匿名结构体类型)
1.3结构体变量的定义
1.4关于匿名结构体类型的补充
1.5结构体的自引用
1.6结构体变量的初始化
2.结构体内存对齐(重点)
2.1偏移量补充
2.2对齐规则
2.3为什么会有对齐
2.4修改默认对齐数
3.结构体传参
4.位段
4.1什么是位段
4.2位段的内存分配
4.3 位段的跨平台问题
4.4位段的应用
1.结构体
1.1 结构的基础知识
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
对比数组,数组是同类型数据的集合
1.2 结构的声明
struct tag //首先给了一个struct的结构体关键字,tag是标签名我们可以自己自定义想取什么名字就取什么名字。
{
member-list;//成员列表,每一个成员都是成员变量,可以是不同的类型
}variable-list;//这是变量列表,到底在怎么用,我们来看实际例子,来上手定义一个学生例子。
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}; //分号不能丢
1.2.1特殊的声明(匿名结构体类型)
在声明结构的时候,可以不完全的声明。将标签名省略的结构体
struct
{
int a;
char b;
float c;
};
1.3结构体变量的定义
当我们有了结构体类型,我们来看一下如何定义结构体变量。
①在创建结构体的时候直接在类型后面定义结构体变量:
struct Stu
{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号
}s1,s2; //分号不能丢
s1,s2就是定义的结构体变量。
②声明好了结构体类型后单独利用类型创建变量
struct Stu
{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号
}; //分号不能丢struct Stu s1,s2;③匿名结构体变量的定义只能在声明或者创建结构体类型的时候就定义,因为没有标签名就无法单独创建。
struct
{int a;char b;float c;
}a[20], *p;上述代码定义了结构体类型的数组和指针。
1.4关于匿名结构体类型的补充
我们来看这两段代码:
struct
{int a;char b;float c;
}x;
struct
{int a;char b;float c;
}a[20], *p;这两段代码由于都没有标签名,在我们看来那结构体类型似乎是一模一样的
但是两个结构体本质上是不同的,所以在使用的时候不可以第二个结构体定义的指针指向第一个结构体创建的变量:
p = &x;//错误写法编译器会把上面的两个声明当成完全不同的两个类型。 所以是非法的
1.5结构体的自引用
在结构体中包含一个类型为该结构体本身的成员。
一定用结构体指针的形式看如下解释
补充数据结构知识:
数据结构:描述的是数据在内存中的组织结构
线性数据结构:
①.顺序表:
假如我要在内存中存储1,2,3,4,5
我就可以在内存中找一块连续的存储空间,比如找一个数组来存储:这就是顺序表
②.链表:我们也可以不找联系存储的空间来存放数据,不过我们可以这样通过1可以找到,2可以找到3这种方式比如:
我们把1,2,3这样的位置叫做链表的节点,每个节点中包含了自身的数据和下一个节点。这就是我们要讲的结构体的自引用:
那么要实现这个链表,有些伙伴可能就会这样去实现:
struct Node {int data;struct Node next; };这样对吗?
当我们这样写,那我们能求出那sizeof(struct Node)是多少吗?
所以这种写法从本质上来说是错误的。
正确的实现方式是,前一个节点里面存储下一个节点的内容。我们来看一下实现方式:
struct Node {int data;struct Node* next; };存放数据的一般叫做数据域,存放数据,指针叫做指针域
补充一个思考:
我们有些伙伴可能会这样写:
typedef struct {int data;Node* next; }Node;对匿名结构体类型重定义为Node可以,但是:
我们对一个类型进行重定义的时候他必须先是一个完整的类型,这段代码就相当于,我还没有创建好Node这个类型就已经在使用了是不对的,
如果要这样用,我们可以这样写:不使用匿名结构体类型
typedef struct Node {int data;struct Node* next; }Node;



1.6结构体变量的初始化
①直接对变量赋值
struct SN {char c;int i; }sn1 = { 'q',100 };②利用点操作符进行赋值:.
struct SN {char c;int i; }sn2 = { .i = 200,.c = 'w' };//当用点初始化的时候可以不在意顺序③结构体嵌套初始化
struct Point {int x;int y; };struct Node {int data;struct Point p;struct Node* next; }n1 = {10, {4,5}, NULL}; //结构体嵌套初始化 struct Node n2 = {20, {5, 6}, NULL};//结构体嵌套初始化
2.结构体内存对齐(重点)
题型考察结构体的大小,我们来看一下例子引入,请问如下这段代码输出分别为什么:
struct S1 {char c1;int i;char c2; }; struct S2 {char c1;char c2;int i; }; int main() {printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));return 0; }
明明是两个一样的结构体,为什么却不一样大,要知道答案我们就要知道结构体的大小是如何计算的,结构体大小的计算并不是单单就靠结构体内部元素的类型大小来决定,让我们来看一下:

2.1偏移量补充

offsetof() 这个宏可以计算结构体某一个成员相较于起始位置的偏移量
头文件:stddef.h
需要在宏中传入的是:结构体类型和结构体变量名,下面我们来计算一下结构体s1中成员的偏移量和S2结构体的偏移量
struct S1 {char c1;int i;char c2; }; struct S2 {char c1;char c2;int i; }; int main() {/*printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));*/printf("%d\n", offsetof(struct S1, c1));printf("%d\n", offsetof(struct S1, i));printf("%d\n", offsetof(struct S1, c2));return 0; }


2.2对齐规则
1. 第一个成员在与结构体变量偏移量为0的地址处。
2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。 VS中默认的值为8 Linux中没有默认对齐数,对齐数就是成员自身的大小
3. 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。所有成员对齐数的最大值。
4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整 体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
我们来看一下图解S1的对齐:

对对齐规则第四条的解释:
让我们来看一下结构体嵌套的对齐算法:
如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整 体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
看一下这段代码输出风别为多少
struct S3
{double d;char c;int i;
};struct S4
{char c1;struct S3 s3;double d;
};int main()
{printf("%d\n", sizeof(struct S3));printf("%d\n", sizeof(struct S4));return 0;
} 

如果出行数组,就当做多个同类型数据处理
2.3为什么会有对齐
大部分的参考资料都是如是说的:
1. 平台原因(移植原因): 不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。比如某些平台规定整型必须存放在4的整数倍地址处。
2. 性能原因: 数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访 问。
虽然浪费了一些空间,但是换来了访问效率的提升
总体来说: 结构体的内存对齐是拿空间来换取时间的做法。 那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到: 让占用空间小的成员尽量集中在一起。

2.4修改默认对齐数
一般将对齐数设置为2^n次方,之前我们见过了 #pragma 这个预处理指令,这里我们再次使用,可以改变我们的默认对齐数。
例如:
#pragma pack(8)//设置默认对齐数为8
#pragma pack()//取消设置的默认对齐数,还原为默认
pragma pack(1)//设置默认对齐数为1
#pragma pack(1)//设置默认对齐数为1 struct S2 {char c1;int i;char c2; }; #pragma pack()//取消设置的默认对齐数,还原为默认 int main() {printf("%d\n", sizeof(struct S1));return 0; }
结论: 结构在对齐方式不合适的时候,我们可以自己更改默认对齐数。
后续更新到宏的讲解的时候会补充实现offsetof的实现

3.结构体传参
结构体作为函数传参有两种方式,传地址和传形参如下:
struct S
{int data[1000];int num;
};
struct S s = {{1,2,3,4}, 1000};
//结构体传参
void print1(struct S s)
{printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{printf("%d\n", ps->num);
}
int main()
{print1(s); //传结构体print2(&s); //传地址return 0;
}

函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。 如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的 下降。所以首选地址传参
4.位段
结构体讲了就得讲讲结构体实现 位段 的能力。
4.1什么是位段
位段的声明和结构是类似的,有两个不同:
1.位段的成员必须是 int、unsigned int 或signed int 。
2.位段的成员名后边有一个冒号和一个数字。
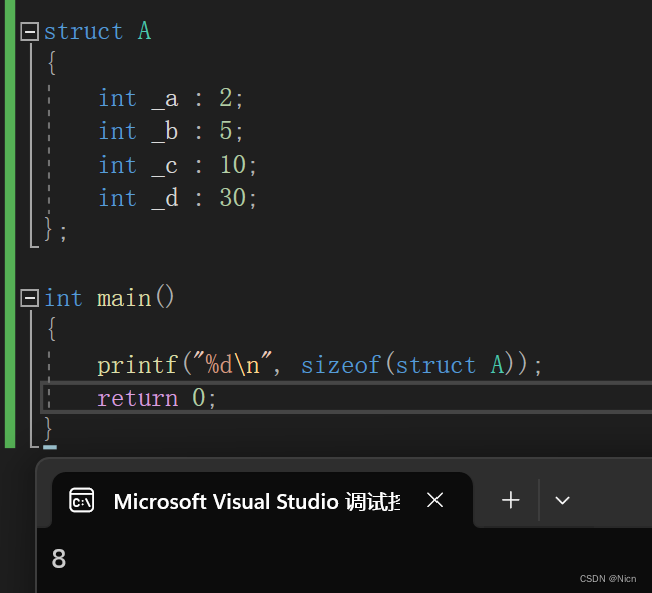
例如:以下就是一个位段类型
struct A {int _a:2;int _b:5;int _c:10;int _d:30; };我们来看一下位段的大小是多少:
这里为什么打印8,我们来往下了解:
为什么存在位段来这样分配空间:
有的时候比如0/1、2、3这几个数只用三个二进制位就可以表示出来:
000 0001 010 011
2个比特位就够了,如果分配四个字节就会浪费30个比特位。

4.2位段的内存分配
1. 位段的成员可以是 int unsigned int signed int 或者是 char (属于整形家族)类型
2. 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
3. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
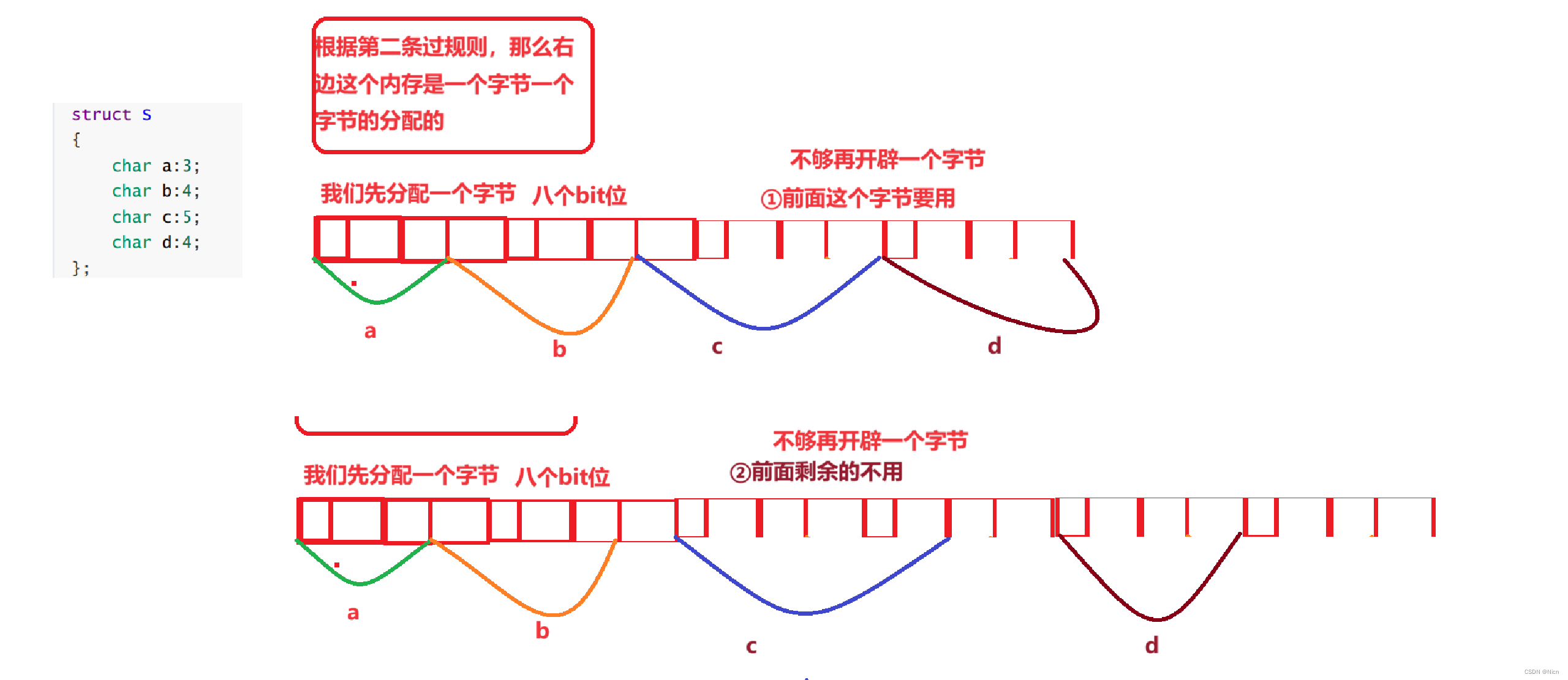
比如给上述位段中的-a开辟内存到底从左开辟还是从右开辟,当开辟不够的时候是从新使用一块空间还是补充使用就行,c语言也没有规定。

我们来验证一下当前我们的环境下是如何开辟的
我们先看一下可能的内存分配方式:
接着我们给位段创建变量并复制:
那我们就知道了当前环境下的位段的内存开辟形式。

4.3 位段的跨平台问题
1. int 位段被当成有符号数还是无符号数是不确定的。
2. 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机 器会出问题。:如果位段类型是int,如果在早期16位机器上,int是16位比特位,两个字节
3. 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
4. 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是 舍弃剩余的位还是利用,这是不确定的。
总结:
跟结构相比,位段可以达到同样的效果,并且可以很好的节省空间,但是有跨平台的问题存在。
4.4位段的应用
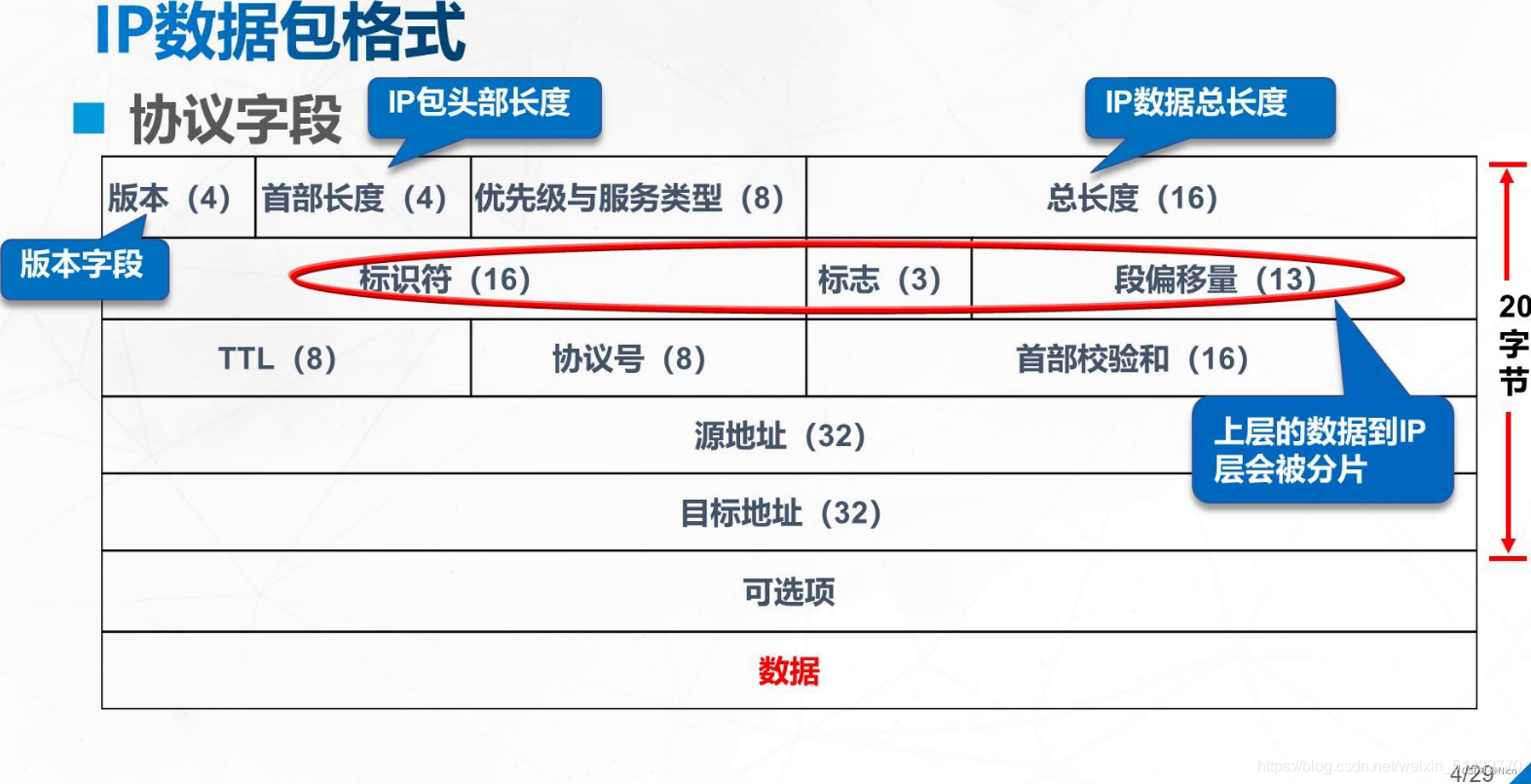
网络底层中的ip数据包
、设计成位段,好设计也方便,网络传输数据越小越好,传输速率快。
5.结语
以上就是本期的所有内容,知识含量蛮多,大家可以配合解释和原码运行理解。创作不易,大家如果觉得还可以的话,欢迎大家三连,有问题的地方欢迎大家指正,一起交流学习,一起成长,我是Nicn,正在c++方向前行的奋斗者,感谢大家的关注与喜欢。




![[计算机提升] 还原系统:系统映像](https://img-blog.csdnimg.cn/direct/965cba3c6faf4de8bd90fc955ba207be.png)