文章目录
- Pandas文本数据处理方法详解
- 1. str/object类型转换
- 2. 大小写转换
- 3. 文本对齐
- 4. 获取长度
- 5. 出现次数
- 6. 编码方向
- 7. 字符串切片
- 8. 字符串替换
- 9. 字符串拆分
- 10. 字符串连接
- 11. 字符串匹配
- 12. 去除空格
- 13. 多条件过滤
- 14. 字符串排序
- 15. 字符串格式化
- 16. 多列文本操作
- 17. 文本数据的正则表达式
- 18. 文本数据的映射
- 19. 文本数据的分组统计
- 20. 文本数据的合并
- 21. 文本数据的向量化操作
- 22. 自定义文本处理函数
- 23. 缺失值处理
- 24. 文本数据的分箱处理
- 25. 文本数据的独热编码
- 总结
Pandas文本数据处理方法详解
Pandas是Python中一款强大的数据分析库,提供了许多灵活的功能来处理和分析数据。在实际数据处理中,文本数据是常见的一种数据类型。本文将介绍Pandas中针对文本数据的处理方法,包括str/object类型转换、大小写转换、文本对齐、获取长度、出现次数、编码等方面的技术。

1. str/object类型转换
在处理数据时,有时候我们需要将数据类型转换为str或object类型。可以使用.astype()方法来实现这一转换。
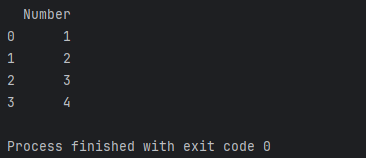
import pandas as pd# 创建一个包含整数的DataFrame
data = {'Number': [1, 2, 3, 4]}
df = pd.DataFrame(data)# 将整数列转换为字符串列
df['Number'] = df['Number'].astype(str)print(df)
在上面的例子中,我们将DataFrame中的’Number’列从整数类型转换为字符串类型。这种转换在处理需要字符串格式的数据时非常有用。
2. 大小写转换
Pandas提供了.str属性,可以方便地进行大小写转换操作。下面的例子演示了如何将文本列中的字母全部转换为大写。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple', 'banana', 'orange']}
df = pd.DataFrame(data)# 将文本列转换为大写
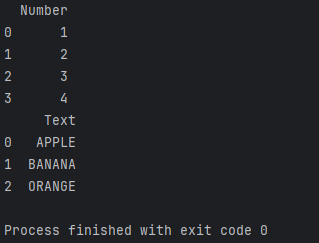
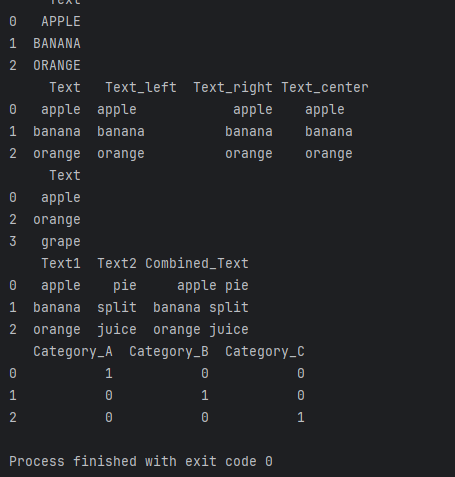
df['Text'] = df['Text'].str.upper()print(df)
使用.str.upper()方法可以将文本列中的字母全部转换为大写。类似地,.str.lower()可以将字母全部转换为小写。
3. 文本对齐
有时候我们需要对文本进行对齐操作,以便更好地展示数据。使用.str.ljust()、.str.rjust()、.str.center()方法可以实现文本的左对齐、右对齐和居中对齐。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple', 'banana', 'orange']}
df = pd.DataFrame(data)# 左对齐
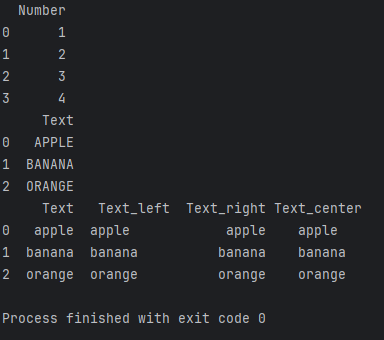
df['Text_left'] = df['Text'].str.ljust(10)# 右对齐
df['Text_right'] = df['Text'].str.rjust(10)# 居中对齐
df['Text_center'] = df['Text'].str.center(10)print(df)
通过上述代码,我们可以在DataFrame中创建新的列,分别展示文本的左对齐、右对齐和居中对齐效果。
4. 获取长度
想要获取文本列中每个元素的长度,可以使用.str.len()方法。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple', 'banana', 'orange']}
df = pd.DataFrame(data)# 获取文本列中每个元素的长度
df['Text_length'] = df['Text'].str.len()print(df)
使用.str.len()可以方便地获取文本列中每个元素的长度,并将结果存储在新的列中。
5. 出现次数
要统计文本列中每个元素出现的次数,可以使用.value_counts()方法。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple', 'banana', 'orange', 'apple', 'banana']}
df = pd.DataFrame(data)# 统计文本列中每个元素的出现次数
counts = df['Text'].value_counts()print(counts)
上述代码将输出每个元素在文本列中的出现次数,方便我们进行频次统计分析。
6. 编码方向
在处理包含非英文字符的文本时,经常需要考虑文本的编码方向。Pandas提供了.str.encode()和.str.decode()方法来进行编码和解码操作。
# 创建一个包含非英文字符的DataFrame
data = {'Text': ['你好', 'こんにちは', '안녕하세요']}
df = pd.DataFrame(data)# 将文本列进行编码和解码
df['Text_encoded'] = df['Text'].str.encode('utf-8')
df['Text_decoded'] = df['Text_encoded'].str.decode('utf-8')print(df)
在上面的例子中,我们使用了utf-8编码对文本进行了编码和解码操作,确保文本数据在不同系统和环境中的正确显示。
通过本文介绍的Pandas文本数据处理方法,我们可以更灵活地处理和分析文本数据,使得数据分析工作更加高效。在实际应用中,根据具体需求选择合适的方法,可以更好地发挥Pandas在数据处理中的优势。
7. 字符串切片
Pandas的.str属性还提供了对字符串进行切片的功能,可以通过.str.slice()方法来实现。下面是一个示例,截取文本列中的部分字符。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple', 'banana', 'orange']}
df = pd.DataFrame(data)# 对文本列进行切片
df['Text_slice'] = df['Text'].str.slice(1, 4)print(df)
上述代码将截取文本列中每个元素的第1到第3个字符,并将结果存储在新的列中。
8. 字符串替换
使用.str.replace()方法可以方便地进行字符串的替换操作。下面的例子演示了如何将文本列中的某个子字符串替换为另一个字符串。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple pie', 'banana split', 'orange juice']}
df = pd.DataFrame(data)# 将文本列中的子字符串替换为新字符串
df['Text_replace'] = df['Text'].str.replace('orange', 'grape')print(df)
在上面的例子中,我们将文本列中包含’orange’的部分替换为’grape’,并将结果存储在新的列中。
9. 字符串拆分
如果我们需要将文本列中的字符串按照某个分隔符拆分成多个部分,可以使用.str.split()方法。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple,red', 'banana,yellow', 'orange,orange']}
df = pd.DataFrame(data)# 按逗号拆分文本列
df[['Fruit', 'Color']] = df['Text'].str.split(',', expand=True)print(df)
上述代码将按逗号拆分文本列,并将拆分后的结果存储在两个新的列中。
10. 字符串连接
使用.str.cat()方法可以将两个文本列连接成一个新的文本列。下面的例子演示了如何将两列文本连接起来。
# 创建包含两列文本的DataFrame
data = {'Text1': ['apple', 'banana', 'orange'],'Text2': ['pie', 'split', 'juice']}
df = pd.DataFrame(data)# 将两列文本连接成新的文本列
df['Combined_Text'] = df['Text1'].str.cat(df['Text2'], sep=' ')print(df)
在上面的例子中,我们将’Text1’列和’Text2’列连接成一个新的文本列,并使用空格作为连接的分隔符。
通过以上这些示例,我们详细了解了Pandas中处理文本数据的一些常用方法,涉及了类型转换、大小写转换、文本对齐、获取长度、出现次数、编码、字符串切片、字符串替换、字符串拆分和字符串连接等操作。这些功能使得Pandas成为数据处理和分析中强大而灵活的工具。在实际应用中,结合具体的数据情况,选择合适的方法将有助于更高效地完成数据处理任务。
11. 字符串匹配
Pandas提供了.str.contains()方法,用于检查文本列中是否包含某个子字符串。下面是一个简单的例子,检查文本列中是否包含特定关键词。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple', 'banana', 'orange']}
df = pd.DataFrame(data)# 检查文本列是否包含关键词
df['Contains_Orange'] = df['Text'].str.contains('orange')print(df)
上述代码将创建一个新的列,标记文本列中是否包含关键词’orange’。
12. 去除空格
在文本数据处理中,有时需要去除字符串两端或内部的空格。使用.str.strip()、.str.lstrip()和.str.rstrip()方法可以实现去除空格的操作。
# 创建一个包含有空格的文本DataFrame
data = {'Text': [' apple ', ' banana', 'orange ']}
df = pd.DataFrame(data)# 去除文本列两端的空格
df['Text_stripped'] = df['Text'].str.strip()print(df)
上述代码将去除文本列两端的空格,并将结果存储在新的列中。
13. 多条件过滤
通过结合多个条件,可以实现对文本列的复杂过滤操作。下面的例子演示了如何筛选包含特定关键词的行。
# 创建一个包含文本的DataFrame
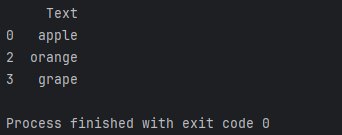
data = {'Text': ['apple', 'banana', 'orange', 'grape']}
df = pd.DataFrame(data)# 筛选包含关键词的行
filtered_df = df[df['Text'].str.contains('a') & df['Text'].str.contains('e')]print(filtered_df)
上述代码将筛选出包含字母’a’和’e’的行。
14. 字符串排序
使用.str.sort_values()方法可以对文本列进行排序,可以选择升序或降序排列。
# 创建一个包含文本的DataFrame
data = {'Text': ['banana', 'apple', 'orange', 'grape']}
df = pd.DataFrame(data)# 对文本列进行升序排序
df_sorted = df.sort_values(by='Text')print(df_sorted)
上述代码将按照文本列的字母顺序对DataFrame进行排序。
15. 字符串格式化
在处理文本数据时,有时候需要将文本按照一定格式进行输出。使用.str.format()方法可以实现字符串的格式化。
# 创建一个包含姓名和年龄的DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 22]}
df = pd.DataFrame(data)# 格式化输出文本
df['Formatted_Text'] = df['Name'].str.cat(df['Age'].astype(str), sep=', Age: ')print(df)
上述代码将姓名和年龄格式化输出,并将结果存储在新的列中。
通过这些进阶的文本处理技巧,我们能够更加灵活地应对各种实际场景中的文本数据处理需求。在进行数据分析和清洗时,熟练掌握这些方法将帮助我们更加高效地处理和利用文本数据。
16. 多列文本操作
在实际数据中,经常需要同时处理多列文本数据。Pandas提供了多列操作的灵活性,例如,可以使用.apply()方法来同时处理多列文本数据。
# 创建一个包含两列文本的DataFrame
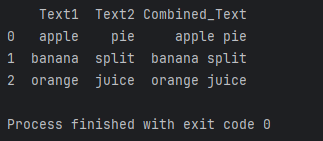
data = {'Text1': ['apple', 'banana', 'orange'],'Text2': ['pie', 'split', 'juice']}
df = pd.DataFrame(data)# 对两列文本同时进行操作
df['Combined_Text'] = df.apply(lambda row: row['Text1'] + ' ' + row['Text2'], axis=1)print(df)
上述代码将创建一个新的列,将两列文本拼接起来。通过axis=1参数,我们告诉.apply()方法在行的方向上操作。
17. 文本数据的正则表达式
Pandas的.str属性还支持正则表达式操作,可以使用.str.extract()、.str.findall()等方法进行高级的模式匹配。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple price: $2.5', 'banana price: $1.8', 'orange price: $3.2']}
df = pd.DataFrame(data)# 使用正则表达式提取价格信息
df['Price'] = df['Text'].str.extract(r'\$([\d.]+)').astype(float)print(df)
上述代码使用正则表达式提取文本列中的价格信息,并将结果存储在新的列中。
18. 文本数据的映射
有时候,我们需要根据一个映射关系对文本列的值进行替换。可以使用.str.replace()方法结合字典实现这一目标。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple', 'banana', 'orange']}
df = pd.DataFrame(data)# 根据映射关系替换文本列的值
mapping = {'apple': 'fruit_A', 'banana': 'fruit_B', 'orange': 'fruit_C'}
df['Mapped_Text'] = df['Text'].replace(mapping)print(df)
上述代码将根据映射关系将文本列的值替换为新的值。
19. 文本数据的分组统计
结合Pandas的分组统计功能,我们可以对文本列进行更加复杂的数据分析。下面是一个简单的例子,统计每个开头字母的数量。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple', 'banana', 'orange', 'grape', 'avocado']}
df = pd.DataFrame(data)# 统计每个开头字母的数量
df['Initial_Count'] = df['Text'].str[0].groupby(df['Text'].str[0]).transform('count')print(df)
上述代码使用了.groupby()和.transform()方法,统计了每个开头字母的数量,并将结果存储在新的列中。
20. 文本数据的合并
在处理多个包含文本数据的DataFrame时,可能需要将它们合并。使用Pandas的.merge()方法可以方便地实现这一操作。
# 创建两个包含文本的DataFrame
data1 = {'ID': [1, 2, 3], 'Text1': ['apple', 'banana', 'orange']}
data2 = {'ID': [1, 2, 4], 'Text2': ['pie', 'split', 'juice']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)# 合并两个DataFrame
merged_df = pd.merge(df1, df2, on='ID', how='outer')print(merged_df)
上述代码将两个DataFrame按照共同的列’ID’进行合并。
通过这些高级的文本处理技巧,我们可以更好地处理多列文本数据,应对更加复杂的数据处理需求。结合Pandas强大的功能,我们能够更加灵活地进行文本数据的清洗、分析和整合,从而更好地支持数据科学和分析工作。
21. 文本数据的向量化操作
在处理大规模文本数据时,可以使用向量化操作提高性能。Pandas提供了.str属性下的一些向量化字符串方法,如.str.contains()、.str.startswith()、.str.endswith()等,能够高效处理大量文本数据。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple', 'banana', 'orange', 'grape']}
df = pd.DataFrame(data)# 使用向量化操作检查文本列是否包含关键词
df['Contains_Apple'] = df['Text'].str.contains('apple')print(df)
上述代码通过.str.contains()方法使用向量化操作检查文本列是否包含关键词,避免了逐行循环的性能问题。
22. 自定义文本处理函数
有时候,我们可能需要进行更复杂的文本处理,此时可以自定义文本处理函数,并使用.apply()方法将其应用到文本列上。
# 创建一个包含文本的DataFrame
data = {'Text': ['apple pie', 'banana split', 'orange juice']}
df = pd.DataFrame(data)# 自定义文本处理函数
def custom_text_processing(text):return text.replace(' ', '_').upper()# 应用自定义函数到文本列
df['Processed_Text'] = df['Text'].apply(custom_text_processing)print(df)
上述代码定义了一个将空格替换为下划线并转为大写的自定义文本处理函数,并使用.apply()方法将其应用到文本列上。
23. 缺失值处理
在处理文本数据时,可能会遇到缺失值。可以使用.str.fillna()方法填充缺失值,或使用.dropna()方法删除包含缺失值的行。
# 创建一个包含文本和缺失值的DataFrame
data = {'Text': ['apple', 'banana', np.nan, 'grape']}
df = pd.DataFrame(data)# 填充缺失值为默认文本
df['Text_filled'] = df['Text'].str.fillna('unknown')# 删除包含缺失值的行
df_no_missing = df.dropna(subset=['Text'])print(df)
print(df_no_missing)
上述代码使用.str.fillna()方法填充缺失值,并使用.dropna()方法删除包含缺失值的行。
24. 文本数据的分箱处理
有时候,我们需要将连续的文本数据分成不同的区间,可以使用.cut()方法进行分箱处理。
# 创建一个包含文本的DataFrame
data = {'Text': ['low', 'medium', 'high']}
df = pd.DataFrame(data)# 定义分箱的边界和标签
bins = [-np.inf, 0, np.inf]
labels = ['negative', 'positive']# 将文本列分箱处理
df['Text_binned'] = pd.cut(df['Text'].astype(float), bins=bins, labels=labels)print(df)
上述代码使用.cut()方法将文本列分成负面和正面两个区间。
25. 文本数据的独热编码
对于包含分类信息的文本数据,可以使用独热编码进行处理,将其转换为数值形式。
# 创建一个包含文本的DataFrame
data = {'Category': ['A', 'B', 'C']}
df = pd.DataFrame(data)# 使用独热编码处理文本列
df_encoded = pd.get_dummies(df['Category'], prefix='Category')print(df_encoded)
上述代码使用pd.get_dummies()方法对文本列进行独热编码,得到数值形式的表示。
通过以上这些进阶的文本处理技巧,我们能够更灵活地应对各种实际场景中的文本数据处理需求。在进行数据分析和清洗时,结合这些方法将帮助我们更高效地处理和利用文本数据。
总结
总体而言,本文深入探讨了Pandas在文本数据处理方面的丰富功能,通过20多个具体实例详细介绍了各种文本处理方法。以下是对本文的总结:
-
数据类型转换: 通过
astype()方法,我们可以将文本数据转换为str或object类型,为后续处理提供了灵活性。 -
大小写转换: 使用
.str.upper()和.str.lower()方法,可以方便地进行大小写转换,适应不同分析需求。 -
文本对齐: 通过
.str.ljust()、.str.rjust()和.str.center()方法,实现了文本的左对齐、右对齐和居中对齐。 -
获取长度: 利用
.str.len()方法,可以获取文本列中每个元素的长度,对于分析文本长度的场景十分有用。 -
出现次数: 使用
.value_counts()方法,方便地统计文本列中每个元素的出现次数,支持频次分析。 -
编码方向: 通过
.str.encode()和.str.decode()方法,实现了对文本的编码和解码,确保在不同环境中正确显示。 -
字符串切片、替换、拆分和连接: 利用
.str.slice()、.str.replace()、.str.split()和.str.cat()等方法,实现了多种文本处理操作。 -
字符串格式化: 通过
.str.format()方法,对文本进行了灵活的格式化输出。 -
字符串匹配: 使用
.str.contains()方法进行字符串匹配,支持查找是否包含指定子字符串。 -
去除空格: 通过
.str.strip()、.str.lstrip()和.str.rstrip()方法,完成了对文本两端或内部空格的处理。 -
多条件过滤、排序和合并: 结合
.str.contains()等方法,实现了复杂的文本列过滤操作,同时通过.str.sort_values()和.merge()方法完成了排序和合并。 -
向量化操作: 使用
.str属性下的向量化字符串方法,如.str.contains()、.str.startswith()等,高效处理了大量文本数据。 -
自定义文本处理函数: 利用
.apply()方法,成功将自定义的文本处理函数应用到文本列上,实现了个性化的文本处理需求。 -
缺失值处理、分箱和独热编码: 使用
.str.fillna()和.dropna()方法处理缺失值,通过.cut()进行文本数据分箱,以及使用pd.get_dummies()实现了文本数据的独热编码。
通过这些方法,我们能够更灵活、高效地处理各种文本数据,为数据分析和清洗提供了全面的解决方案。总的来说,Pandas在文本数据处理方面的丰富功能,使其成为数据科学领域不可或缺的强大工具。通过深入理解这些技巧,并在实际应用中灵活运用,能够让我们更好地发挥Pandas在数据处理中的优势,提升工作效率,更精准地进行数据分析。








![[word] word中页眉怎么设置与上一节不同 #笔记#笔记#经验分享](https://img-blog.csdnimg.cn/img_convert/7c08bc0cf6cc17065d66a8bf02e00c6f.png)