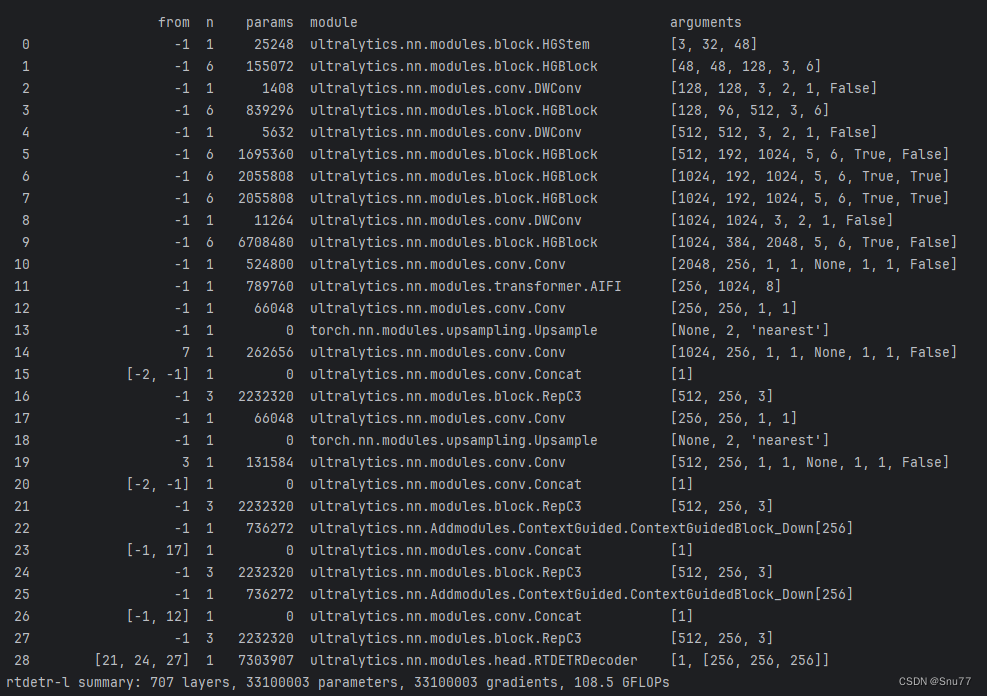
电影分析
项目背景:
- 数据集介绍:movie_lens数据集是一个电影信息,电影评分的数据集,可以用来做推荐系统的数据集
- 需求:对电影发展,类型,评分等做统计分析。
- 目标:巩固pandas相关知识点
1 数据整理
1.1 熟悉数据据知识点
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
%matplotlib inline
mv_path = r'data\ml-latest-small\movies.csv'
rating_path = r'data\ml-latest-small\ratings.csv'
tags_path = r'data\ml-latest-small\tags.csv'
df_mv = pd.read_csv(mv_path)
df_rating = pd.read_csv(rating_path)
df_tags = pd.read_csv(tags_path)
df_mv.head()
| movieId | title | genres | |
|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 1 | 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
df_rating.head()
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 |
| 1 | 1 | 3 | 4.0 | 964981247 |
| 2 | 1 | 6 | 4.0 | 964982224 |
| 3 | 1 | 47 | 5.0 | 964983815 |
| 4 | 1 | 50 | 5.0 | 964982931 |
df_tags.head()
| userId | movieId | tag | timestamp | |
|---|---|---|---|---|
| 0 | 2 | 60756 | funny | 1445714994 |
| 1 | 2 | 60756 | Highly quotable | 1445714996 |
| 2 | 2 | 60756 | will ferrell | 1445714992 |
| 3 | 2 | 89774 | Boxing story | 1445715207 |
| 4 | 2 | 89774 | MMA | 1445715200 |
1.2 缺省值判断
dfs = [df_mv, df_rating, df_tags]
for df in dfs:print(df.columns.values)print(df.isnull().sum())print('======')
['movieId' 'title' 'genres']
movieId 0
title 0
genres 0
dtype: int64
======
['userId' 'movieId' 'rating' 'timestamp']
userId 0
movieId 0
rating 0
timestamp 0
dtype: int64
======
['userId' 'movieId' 'tag' 'timestamp']
userId 0
movieId 0
tag 0
timestamp 0
dtype: int64
======
2 电影分析
分析目标:
- 电影数量
- 电影题材数量
- 电影年代
- 标签,评分
2.1 数量
df_mv.movieId.size
9742
2.2 题材分析
- 查看genres字段
df_mv.head()
| movieId | title | genres | |
|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 1 | 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
2.3 genres拆分
#设置movieId为索引
#使用前4行练习,
#切分字符串,
#行列转换
tmp = df_mv.set_index('movieId')[:4].genres.str.split('|', expand=True)
tmp
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| movieId | |||||
| 1 | Adventure | Animation | Children | Comedy | Fantasy |
| 2 | Adventure | Children | Fantasy | None | None |
| 3 | Comedy | Romance | None | None | None |
| 4 | Comedy | Drama | Romance | None | None |
t = tmp.stack()
t
movieId
1 0 Adventure1 Animation2 Children3 Comedy4 Fantasy
2 0 Adventure1 Children2 Fantasy
3 0 Comedy1 Romance
4 0 Comedy1 Drama2 Romance
dtype: object
df_genres = t.droplevel(1)
df_genres
movieId
1 Adventure
1 Animation
1 Children
1 Comedy
1 Fantasy
2 Adventure
2 Children
2 Fantasy
3 Comedy
3 Romance
4 Comedy
4 Drama
4 Romance
dtype: object
# 代码整理
tmp = df_mv.set_index('movieId').genres.str.split('|', expand=True)
t = tmp.stack()
df_genres = tmp.stack().droplevel(1)
df_genres
movieId
1 Adventure
1 Animation
1 Children
1 Comedy
1 Fantasy...
193583 Fantasy
193585 Drama
193587 Action
193587 Animation
193609 Comedy
Length: 22084, dtype: object
# 查看题材分布
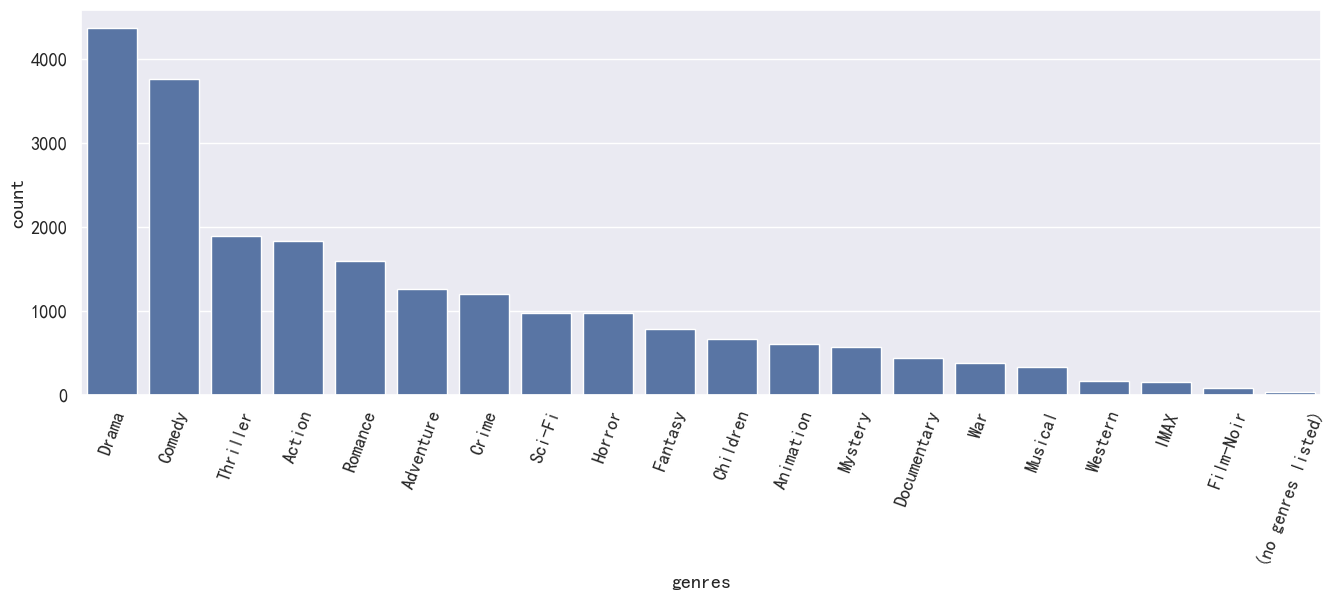
genres = df_genres.value_counts()
genres
Drama 4361
Comedy 3756
Thriller 1894
Action 1828
Romance 1596
Adventure 1263
Crime 1199
Sci-Fi 980
Horror 978
Fantasy 779
Children 664
Animation 611
Mystery 573
Documentary 440
War 382
Musical 334
Western 167
IMAX 158
Film-Noir 87
(no genres listed) 34
Name: count, dtype: int64
#列重命名
genres = genres.reset_index().rename({'index':'genres',0:'count'}, axis=1)
genres
| genres | count | |
|---|---|---|
| 0 | Drama | 4361 |
| 1 | Comedy | 3756 |
| 2 | Thriller | 1894 |
| 3 | Action | 1828 |
| 4 | Romance | 1596 |
| 5 | Adventure | 1263 |
| 6 | Crime | 1199 |
| 7 | Sci-Fi | 980 |
| 8 | Horror | 978 |
| 9 | Fantasy | 779 |
| 10 | Children | 664 |
| 11 | Animation | 611 |
| 12 | Mystery | 573 |
| 13 | Documentary | 440 |
| 14 | War | 382 |
| 15 | Musical | 334 |
| 16 | Western | 167 |
| 17 | IMAX | 158 |
| 18 | Film-Noir | 87 |
| 19 | (no genres listed) | 34 |
#设置图标格式
plt.figure(figsize=(16,5))
ax = sns.barplot(x='genres', y = 'count', data=genres)
_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=70)
UserWarning: FixedFormatter should only be used together with FixedLocator_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=70)
2.4 电影年代
- 数据:
title字段中,含有年代,使用正则表达式提取
- 目标
每个年份电影
每个年份电影题材份电影题材
t = df_mv.set_index('movieId').title
df_year = t.str.extract(r'\((\d+)\)')
#统计没有年份的电影
df_year.isnull().sum()
0 13
dtype: int64
#删除没有年份电影
year_data = df_year.dropna()
#将数据整理成DataFrame对象
year_data = year_data.reset_index().rename({0:'year'}, axis=1)
year_data.head()
| movieId | year | |
|---|---|---|
| 0 | 1 | 1995 |
| 1 | 2 | 1995 |
| 2 | 3 | 1995 |
| 3 | 4 | 1995 |
| 4 | 5 | 1995 |
# 检查数据
# 提取年份是否正确?
year_data.year.agg(['max', 'min'])
max 500
min 06
Name: year, dtype: object
# 找出异常数据
tmp = year_data[year_data.year.isin(['06','500'])]
tmp
| movieId | year | |
|---|---|---|
| 674 | 889 | 06 |
| 7074 | 69757 | 500 |
#找出异常原始数据
t = df_mv[df_mv.movieId.isin(tmp.movieId)]
t
| movieId | title | genres | |
|---|---|---|---|
| 674 | 889 | 1-900 (06) (1994) | Drama|Romance |
| 7075 | 69757 | (500) Days of Summer (2009) | Comedy|Drama|Romance |
# 问题:提取数据方式没问题,但是数据不规范,提取其他值
# 解决方式:修改正则表达式
t.title.str.extract(r'\((\d+)\)$')
| 0 | |
|---|---|
| 674 | 1994 |
| 7075 | 2009 |
# 重新提取数据
t = df_mv.set_index('movieId').title
df_year = t.str.extract(r'\((\d+)\)$')
#删除没有年份电影
year_data = df_year.dropna()
#将数据整理成DataFrame对象
year_data = year_data.reset_index().rename({0:'year'}, axis=1)
#获取最大最小值
year_data.year.agg(['max', 'min'])
max 2018
min 1902
Name: year, dtype: object
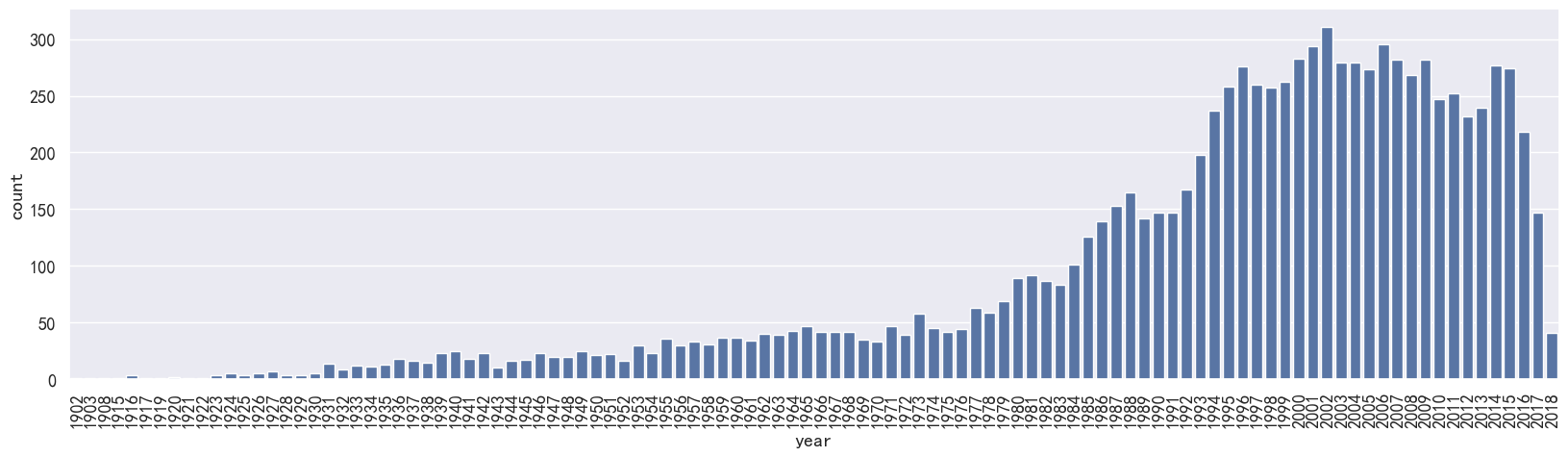
year_data = year_data.sort_values('year')
year_data
| movieId | year | |
|---|---|---|
| 5867 | 32898 | 1902 |
| 6353 | 49389 | 1903 |
| 9008 | 140541 | 1908 |
| 4743 | 7065 | 1915 |
| 8161 | 102747 | 1916 |
| ... | ... | ... |
| 9684 | 187541 | 2018 |
| 9685 | 187593 | 2018 |
| 9686 | 187595 | 2018 |
| 9672 | 184931 | 2018 |
| 9654 | 183295 | 2018 |
9718 rows × 2 columns
# 按年份进行统计
#设置图标格式
plt.figure(figsize=(20,5))
ax = sns.countplot(x='year', data=year_data)
_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
UserWarning: FixedFormatter should only be used together with FixedLocator_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
#设年份大与1970
plt.figure(figsize=(15,5))
ax = sns.countplot(x='year', data=year_data[year_data.year>'1970'])
_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
UserWarning: FixedFormatter should only be used together with FixedLocator_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
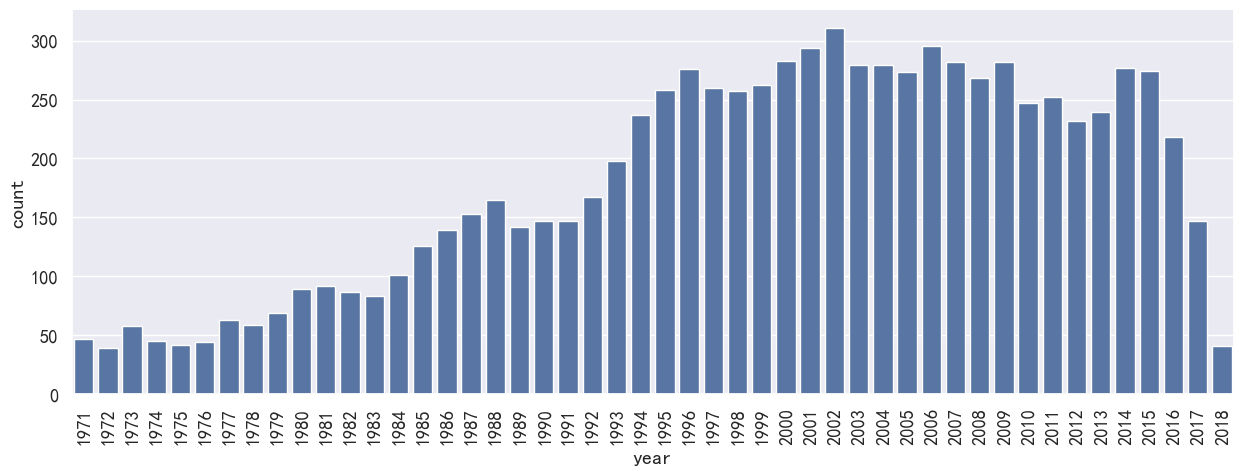
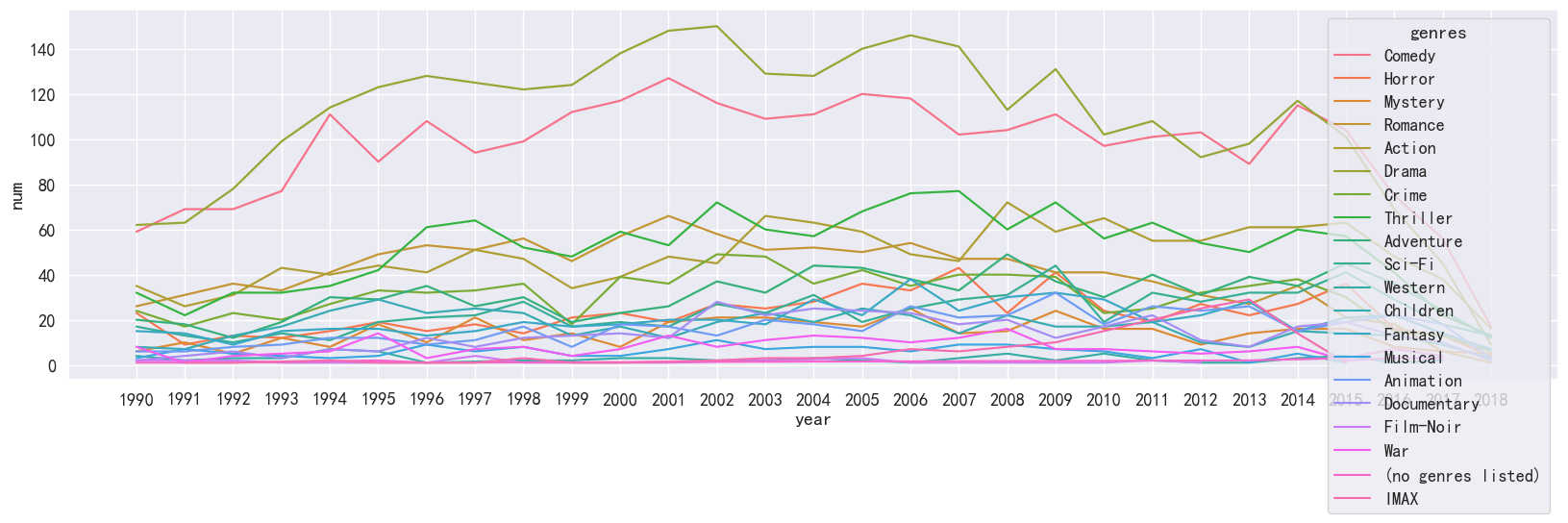
2.5 年代与题材
1990年后:每年不同题材电影数量
year_data.head()
| movieId | year | |
|---|---|---|
| 5867 | 32898 | 1902 |
| 6353 | 49389 | 1903 |
| 9008 | 140541 | 1908 |
| 4743 | 7065 | 1915 |
| 8161 | 102747 | 1916 |
#df_genres处理
genres_data = df_genres.reset_index().rename({0:'genres'},axis=1)
genres_data.head()
| movieId | genres | |
|---|---|---|
| 0 | 1 | Adventure |
| 1 | 1 | Animation |
| 2 | 1 | Children |
| 3 | 1 | Comedy |
| 4 | 1 | Fantasy |
#提取部分数据进行megre
d1 = year_data[:2]
d2 = genres_data[:10]
d1
| movieId | year | |
|---|---|---|
| 5867 | 32898 | 1902 |
| 6353 | 49389 | 1903 |
d2
| movieId | genres | |
|---|---|---|
| 0 | 1 | Adventure |
| 1 | 1 | Animation |
| 2 | 1 | Children |
| 3 | 1 | Comedy |
| 4 | 1 | Fantasy |
| 5 | 2 | Adventure |
| 6 | 2 | Children |
| 7 | 2 | Fantasy |
| 8 | 3 | Comedy |
| 9 | 3 | Romance |
#实际数据合并,只处理1990年以后数据
ydata = year_data[year_data.year>='1990']
ygdata = ydata.merge(genres_data)
ygdata.year.unique()
array(['1990', '1991', '1992', '1993', '1994', '1995', '1996', '1997','1998', '1999', '2000', '2001', '2002', '2003', '2004', '2005','2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013','2014', '2015', '2016', '2017', '2018'], dtype=object)
# 绘制柱状图
plt.figure(figsize=(100,5))
ax = sns.countplot(x='year', data=ygdata, hue="genres", orient='v')
_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
UserWarning: FixedFormatter should only be used together with FixedLocator_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)

# 绘制线形图
import numpy as np
ygdata['num']=np.ones_like(ygdata.year)
plt.figure(figsize=(20,5))
ax = sns.lineplot(x='year',y='num', data=ygdata, hue="genres", estimator='sum')
df_rating.head()
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 |
| 1 | 1 | 3 | 4.0 | 964981247 |
| 2 | 1 | 6 | 4.0 | 964982224 |
| 3 | 1 | 47 | 5.0 | 964983815 |
| 4 | 1 | 50 | 5.0 | 964982931 |
3 评分分析
- 每年评价数量
- 小时评价数量
- 月评价数量
- 电影评分数量
- 电影评分排名TOPN
3.1 时间分析
- 时间戳转时间
- 获取年月小时
获取年月小时
ts = pd.to_datetime(df_rating.timestamp.values, unit='s')
df_rating['times'] = ts
df_rating['day'] = ts.to_period('D')
df_rating['month'] = ts.map(lambda x:x.month)
df_rating['year'] = ts.to_period('Y')
df_rating['hour'] = ts.map(lambda x:x.hour)
df_rating.head()
| userId | movieId | rating | timestamp | times | day | month | year | hour | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 4.0 | 964982703 | 2000-07-30 18:45:03 | 2000-07-30 | 7 | 2000 | 18 |
| 1 | 1 | 3 | 4.0 | 964981247 | 2000-07-30 18:20:47 | 2000-07-30 | 7 | 2000 | 18 |
| 2 | 1 | 6 | 4.0 | 964982224 | 2000-07-30 18:37:04 | 2000-07-30 | 7 | 2000 | 18 |
| 3 | 1 | 47 | 5.0 | 964983815 | 2000-07-30 19:03:35 | 2000-07-30 | 7 | 2000 | 19 |
| 4 | 1 | 50 | 5.0 | 964982931 | 2000-07-30 18:48:51 | 2000-07-30 | 7 | 2000 | 18 |
ax = sns.countplot(x='year', data=df_rating, order=sorted(df_rating.year.unique()))
_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
UserWarning: FixedFormatter should only be used together with FixedLocator_ = ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
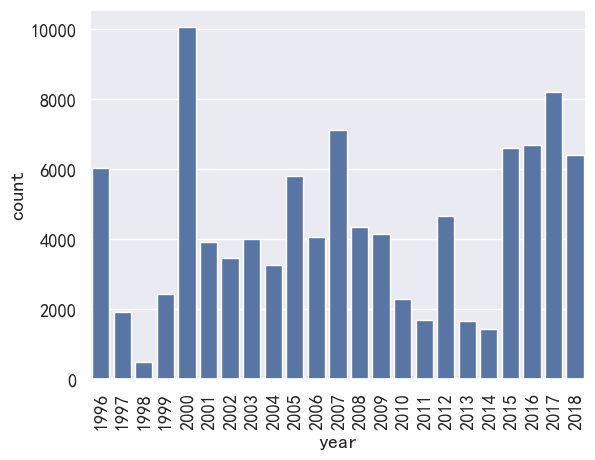
sorted(df_rating.year.unique())
[Period('1996', 'A-DEC'),Period('1997', 'A-DEC'),Period('1998', 'A-DEC'),Period('1999', 'A-DEC'),Period('2000', 'A-DEC'),Period('2001', 'A-DEC'),Period('2002', 'A-DEC'),Period('2003', 'A-DEC'),Period('2004', 'A-DEC'),Period('2005', 'A-DEC'),Period('2006', 'A-DEC'),Period('2007', 'A-DEC'),Period('2008', 'A-DEC'),Period('2009', 'A-DEC'),Period('2010', 'A-DEC'),Period('2011', 'A-DEC'),Period('2012', 'A-DEC'),Period('2013', 'A-DEC'),Period('2014', 'A-DEC'),Period('2015', 'A-DEC'),Period('2016', 'A-DEC'),Period('2017', 'A-DEC'),Period('2018', 'A-DEC')]
3.2 电影评分
3.2.1 评价数量前10
#根据movieId分组,统计数量
tmp = df_rating.groupby('movieId').year.count()
#排序,取前10
tmp.sort_values(ascending=False)[:10]
movieId
356 329
318 317
296 307
593 279
2571 278
260 251
480 238
110 237
589 224
527 220
Name: year, dtype: int64
tmp = df_rating.groupby('movieId').rating.mean()
tmp
movieId
1 3.920930
2 3.431818
3 3.259615
4 2.357143
5 3.071429...
193581 4.000000
193583 3.500000
193585 3.500000
193587 3.500000
193609 4.000000
Name: rating, Length: 9724, dtype: float64
#根据movieId分组,统计数量大于10
tmp = df_rating.groupby('movieId')['rating'].apply(lambda x: 0 if x.size <10 else x.mean())
#排序,取前10
tmp.sort_values(ascending=False)[:10]
movieId
1041 4.590909
3451 4.545455
1178 4.541667
1104 4.475000
2360 4.458333
1217 4.433333
318 4.429022
951 4.392857
1927 4.350000
922 4.333333
Name: rating, dtype: float64
3.3 用户喜好
- 用户打标签
- 思路:根据用户评分与电影题材,为用户打标签
1:获取某个用户评分所有电影
2:获取评分电影对应题材
3:统计题材数量并排序
mvids = df_rating[df_rating.userId == 1].movieId
t = genres_data[genres_data.movieId.isin(mvids)].genres.value_counts()
t
genres
Action 90
Adventure 85
Comedy 83
Drama 68
Thriller 55
Fantasy 47
Crime 45
Children 42
Sci-Fi 40
Animation 29
Romance 26
War 22
Musical 22
Mystery 18
Horror 17
Western 7
Film-Noir 1
Name: count, dtype: int64