目录
AbstractUnsafe.write [注:AbstractUnsafe为Netty定制的Unsafe,非jdk原生的Unsafe]
高低水位线补充
ChannelOutboundBuffer总览 & 高低水位线的剖析
AbstractUnsafe.write [注:AbstractUnsafe为Netty定制的Unsafe,非jdk原生的Unsafe]
Netty定制封装了jdk原生的Unsafe。Netty中使用的Unsafe并不是原生jdk的Unsafe类(suns.misc.Unsafe),而是做了定制优化的Unsafe。Unsafe专门针对于网络通信IO读写的底层操作,read 或 write。
Unsafe:
1.线程不安全的。所以我们要做到线程独享数据
2.Netty需要使用Unsafe去做网络通信IO:I即read(NioByteUnsafe),O即write(AbstractUnsafe)


ctx.writeAndFlush方法:
该方法是写出数据到网卡中,发送给对端。
但是该方法的底层很值得深究,分为两步:
1.write写出 : 把数据写入到应用层面的ByteBuffer缓冲区
2.flush刷新: 把ByteBuffer缓冲区的数据flush刷新到socket内核缓冲区,socket内核缓冲区的数据最终被操作系统写出到网卡设备,进而发送给对端服务器
- debug所使用的代码
package com.messi.netty_source_03.class_04;import io.netty.bootstrap.Bootstrap;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.logging.LoggingHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.net.InetSocketAddress;
import java.nio.charset.Charset;public class MyNettyClient {private static final Logger log = LoggerFactory.getLogger(MyNettyClient.class);public static void main(String[] args) throws InterruptedException {log.debug("myNettyClientStarter------");EventLoopGroup eventLoopGroup = new NioEventLoopGroup();Bootstrap bootstrap = new Bootstrap();bootstrap.channel(NioSocketChannel.class);Bootstrap group = bootstrap.group(eventLoopGroup);//32 ---> 1 IO操作 31线程bootstrap.handler(new ChannelInitializer<NioSocketChannel>() {@Overrideprotected void initChannel(NioSocketChannel ch) throws Exception {ch.pipeline().addLast(new LoggingHandler());ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){@Overridepublic void channelActive(ChannelHandlerContext ctx) throws Exception {if (ctx.channel().isWritable()) {ByteBufAllocator alloc = ctx.alloc();ByteBuf buffer = alloc.buffer();buffer.writeCharSequence("xiaohei", Charset.defaultCharset());ctx.writeAndFlush(buffer);}}});}});Channel channel = bootstrap.connect(new InetSocketAddress(8000)).sync().channel();channel.closeFuture().sync();}
}package com.messi.netty_source_03.class_04;import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.Channel;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.EventLoopGroup;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.logging.LoggingHandler;public class NettyServer {public static void main(String[] args) throws InterruptedException {EventLoopGroup eventLoopGroup = new NioEventLoopGroup();ServerBootstrap serverBootstrap = new ServerBootstrap();serverBootstrap.channel(NioServerSocketChannel.class);serverBootstrap.group(eventLoopGroup);serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {@Overrideprotected void initChannel(NioSocketChannel ch) throws Exception {ch.pipeline().addLast(new LoggingHandler());}});Channel channel = serverBootstrap.bind(8000).sync().channel();channel.closeFuture().sync();}
}
- write 和 flush的总流程:【AbstractUnsafe】
1.channel.write() 把应用程序的数据写入到ByteBuf这一应用层缓冲区中
2.channel.flush() 把ByteBuf应用层缓冲区的数据刷新到send-socket发送方缓冲区
AbstractUnsafe.write 对应等价于 channel.write()。
下面就详细剖析一下write 和 flush的流程:
1.启动服务端
2.debug方式启动客户端
3.

4.

5.
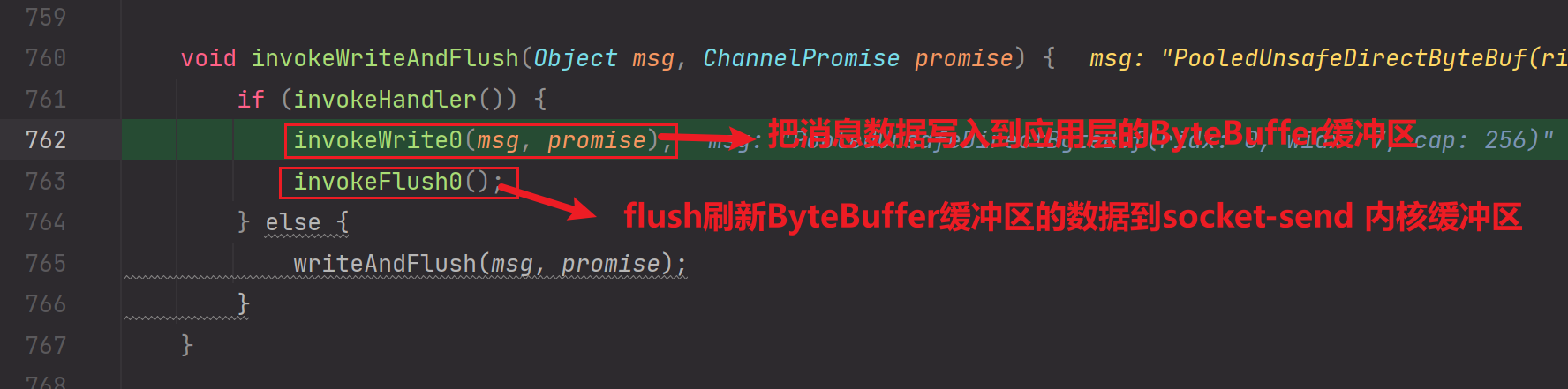
6.

7.
8.使用Netty封装的定制Unsafe去写

9.

详细剖析一下filterOutboundMessage方法:
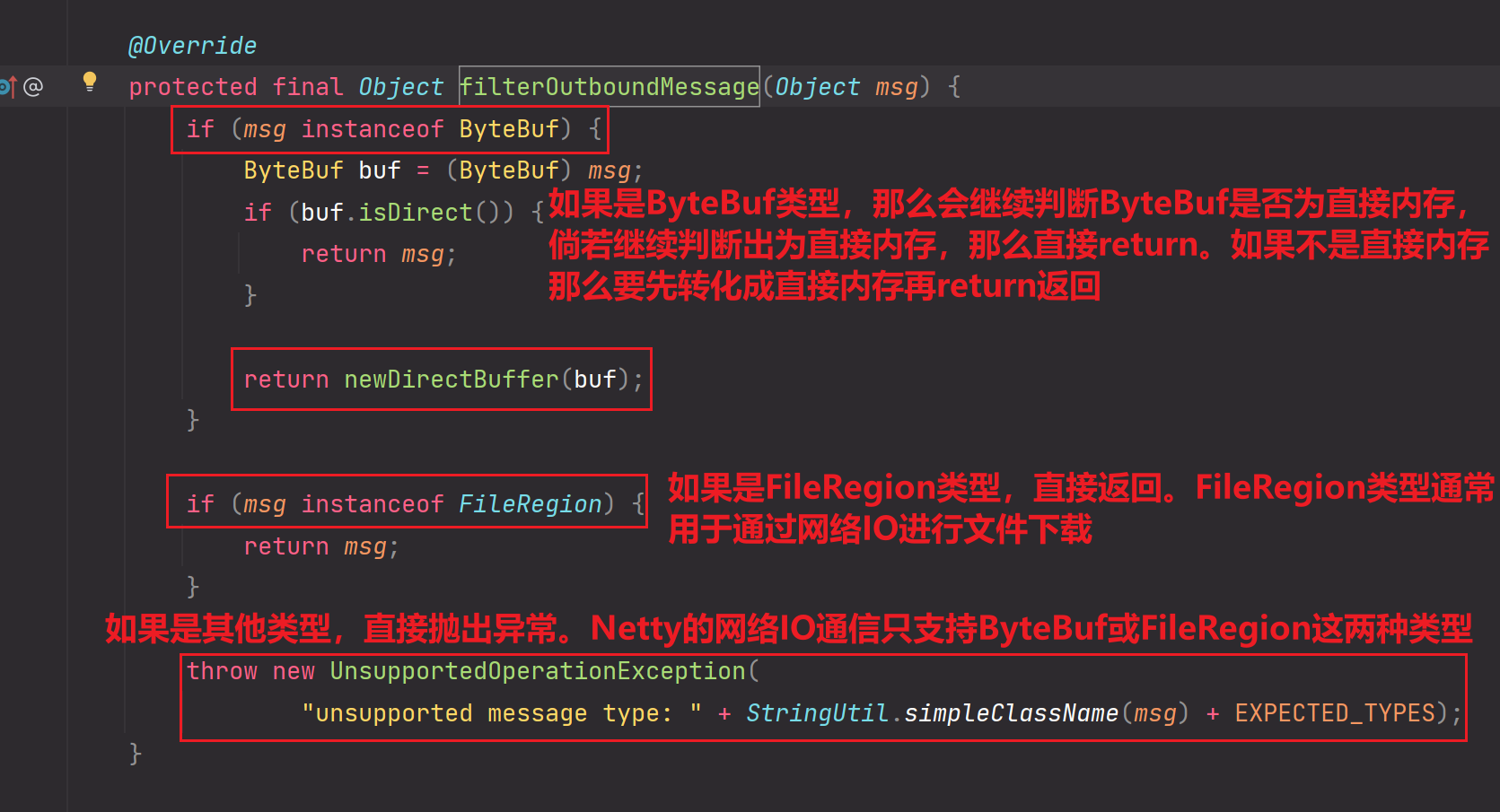
如果既不是1也不是2的话,那么Netty就不会采用直接内存了。因为非池化的直接内存要比堆内存慢10倍以上。
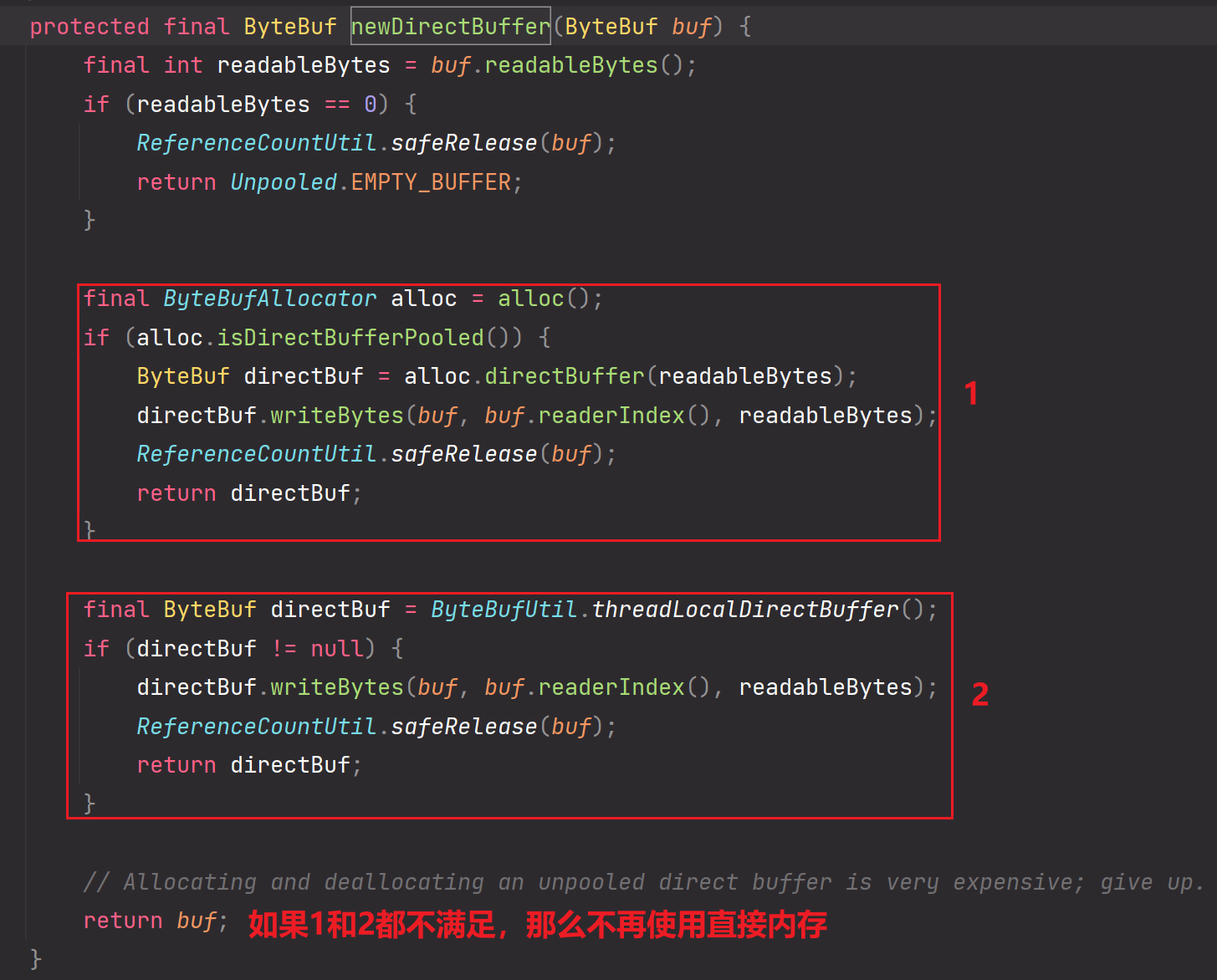

所以说:并不是调用了该newDirectBuffer(buf)就一定会申请直接内存,只是有可能会申请直接内存【1或2】
1和2都是使用?如下:
1是池化的直接内存
2是通过ThreadLocal构建的Stack对象池的直接内存。二者都是池化的,因为非池化的直接内存申请起来是极其耗费性能的,要比堆内存慢10倍以上。
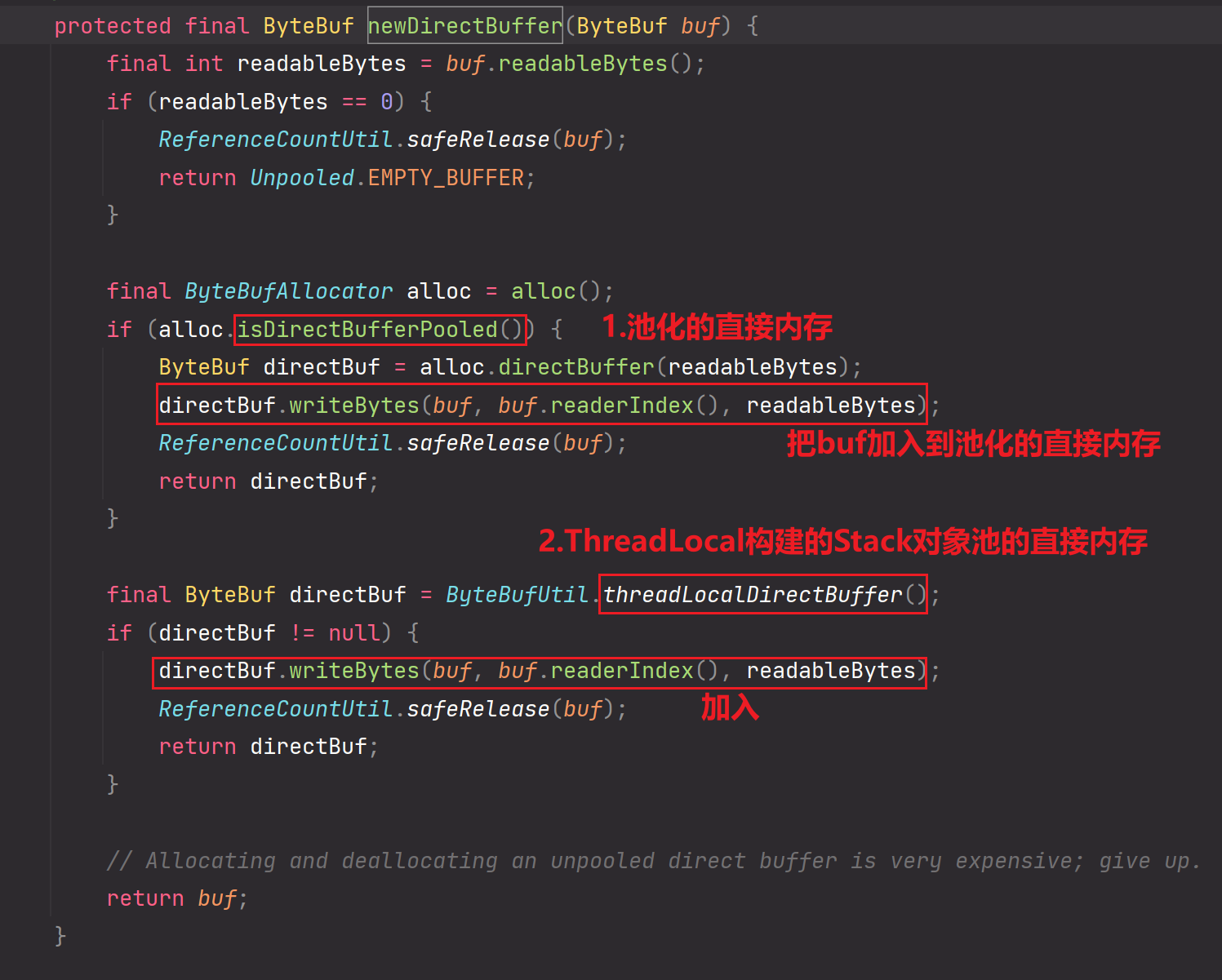
ThreadLocalDirectBuffer()也属于池化的直接内存,但是它是属于线程独享局限性的池化。它是在通过当前线程所独享的内存空间通过ThreadLocal这一工具类去维护的Stack对象池来存储对象。
详细分析一下ThreadLocalDirectBuffer():
【但是默认情况下我们是不使用ThreadLocalDirectBuffer的,我们需要显示指定jvm参数:io.netty.threadLocalDirectBuffer=true,这样才会创建ThreadLocal-Stack对象池的直接内存】
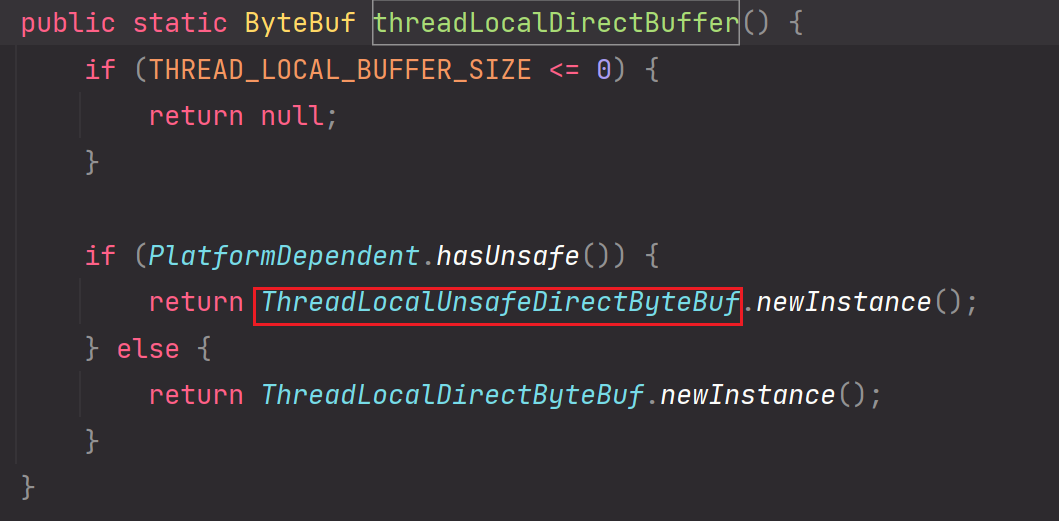

进入ObjectPool:
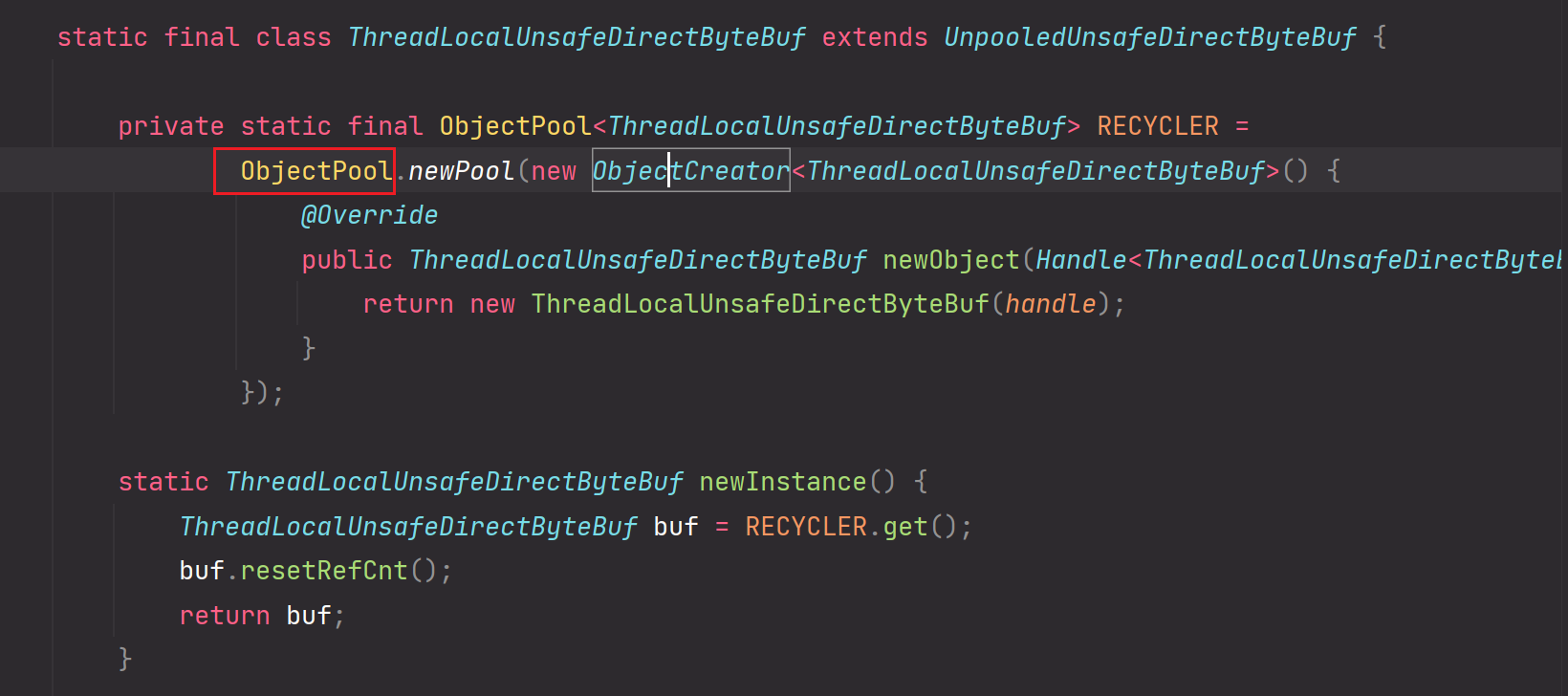
进入Recycler:
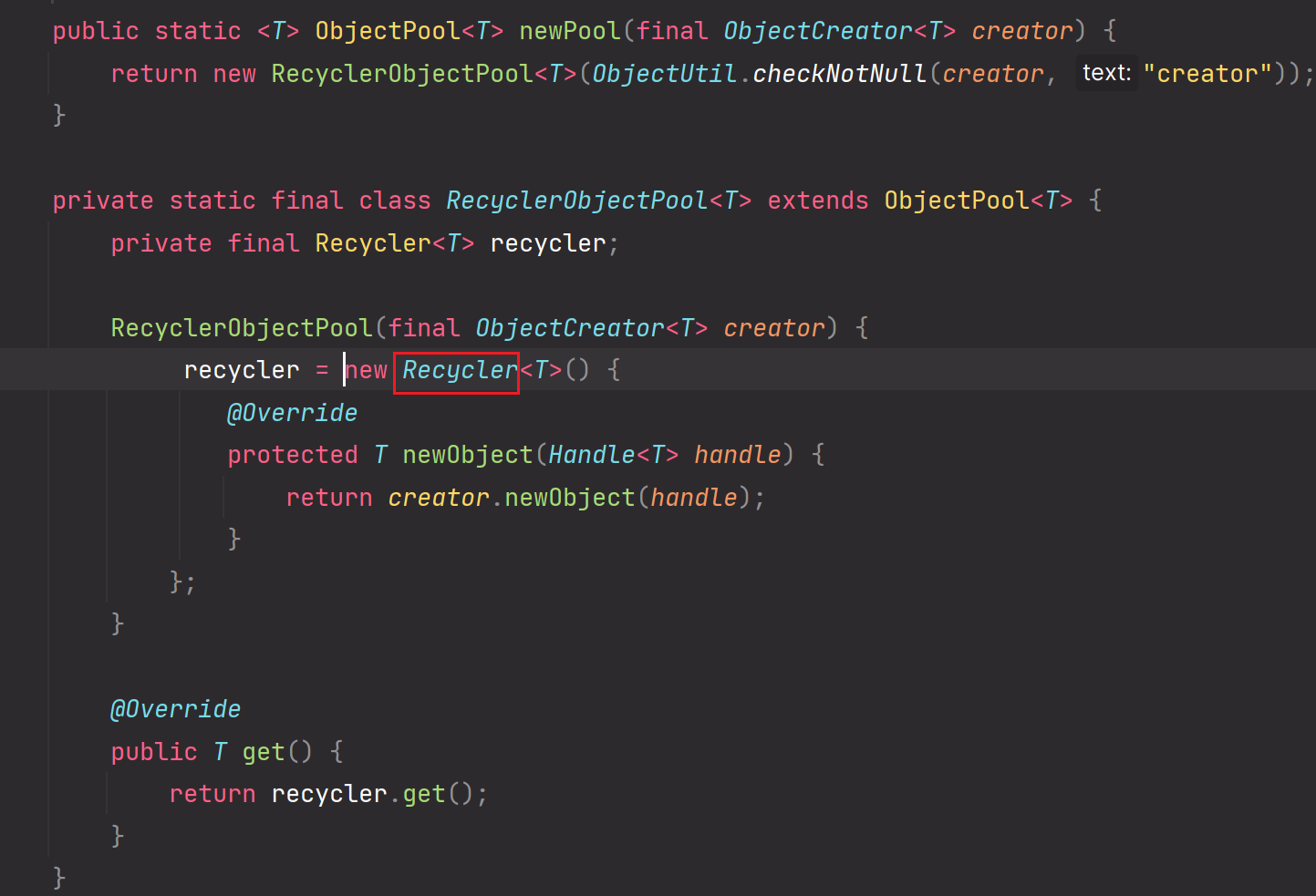
当前线程独享的对象池,对象池由Stack维护的,维护的都是创建完成的ByteBuf直接内存。便于当前线程后续高性能的收发使用池化的ByteBuf直接内存。

详细剖析一下outboundBuffer.addMessage方法:
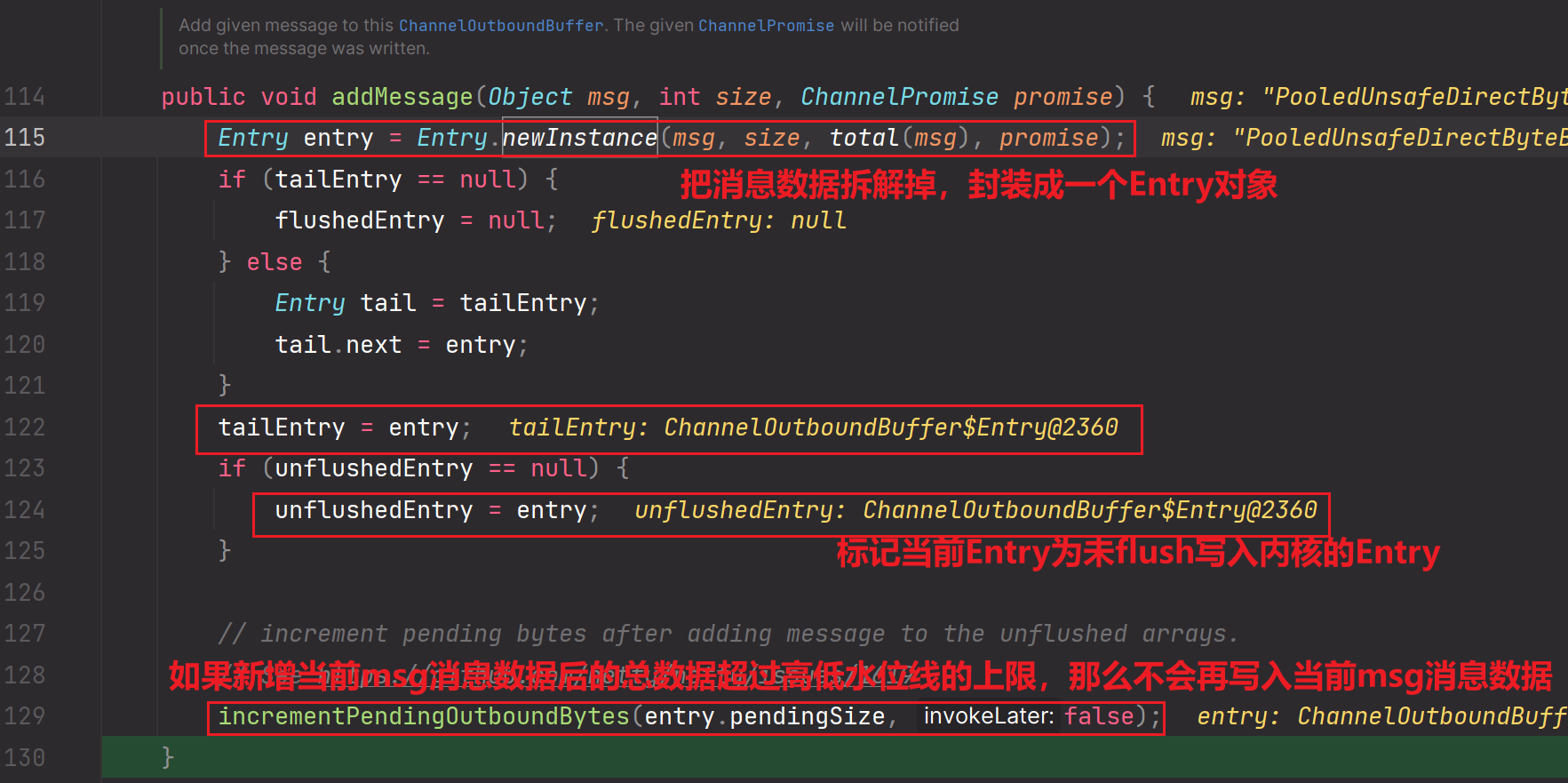
Entry.newInstance(xxx):
entry.pendingSize:为实际传输的消息数据大小加上一个固定死的头部字段长度
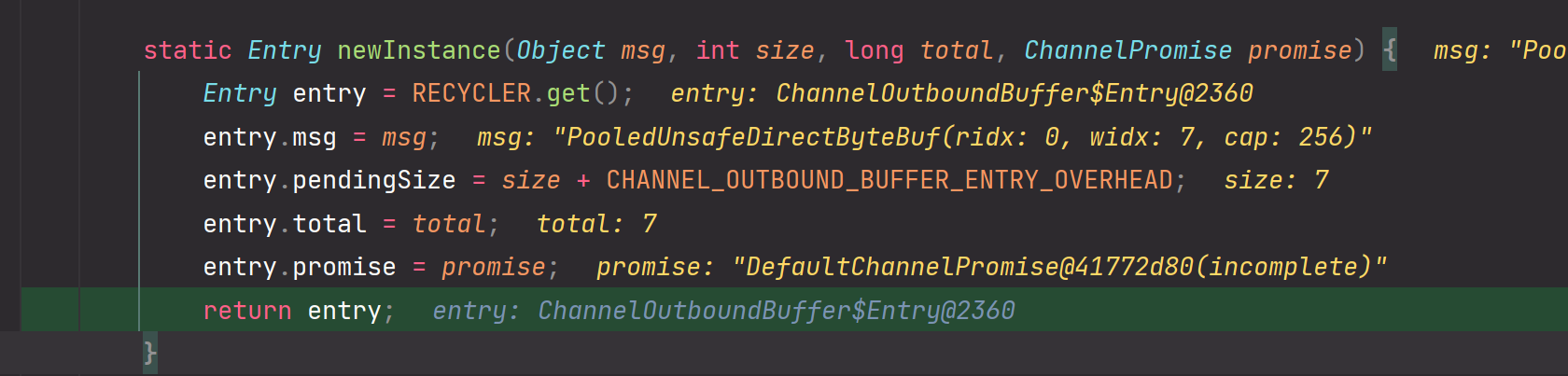
核心逻辑:高低水位线处理
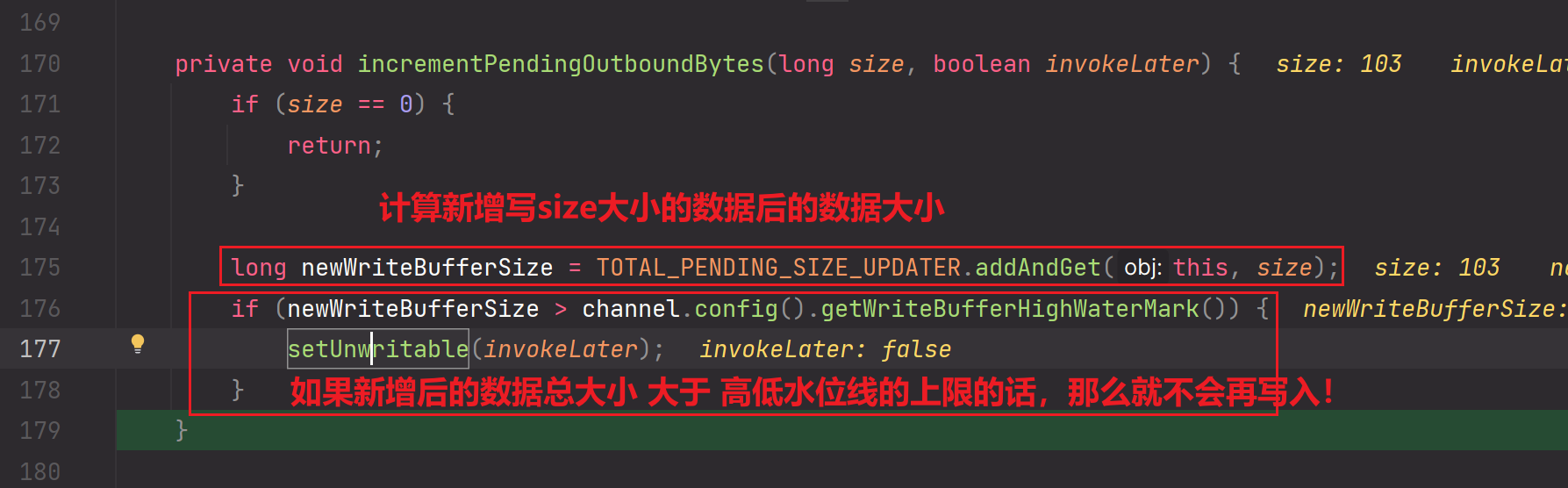
到此为止,write的逻辑分析完毕,如果新增后msg总数据不高于高低水位线的上限,那么已经把msg写入到ByteBuffer缓冲区(应用层)啦。ByteBuffer缓冲区属于JVM级别的内存。
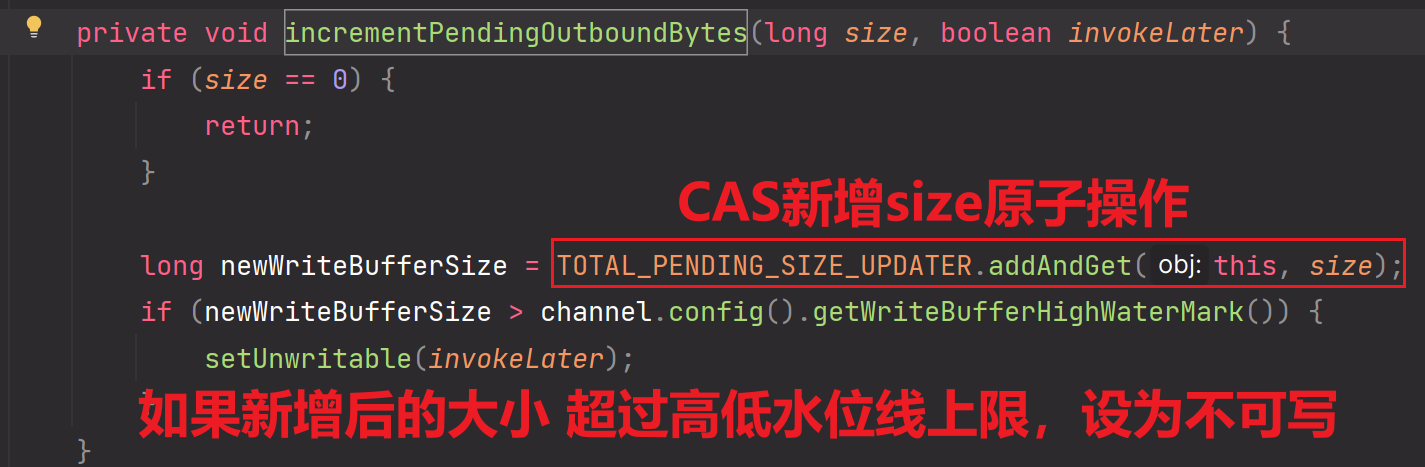
补充:为什么要设计一个高低水位线?Netty为了防止消息的堆积,设置了一个高低水位线,后续每一个在往缓冲区里面写数据时,都会做累加计算,与高水位线进行比较,如果超过高水位线了,那么就不能再继续写了,并且会通知NioSocketChannel。
10.接下来该分析flush的逻辑啦


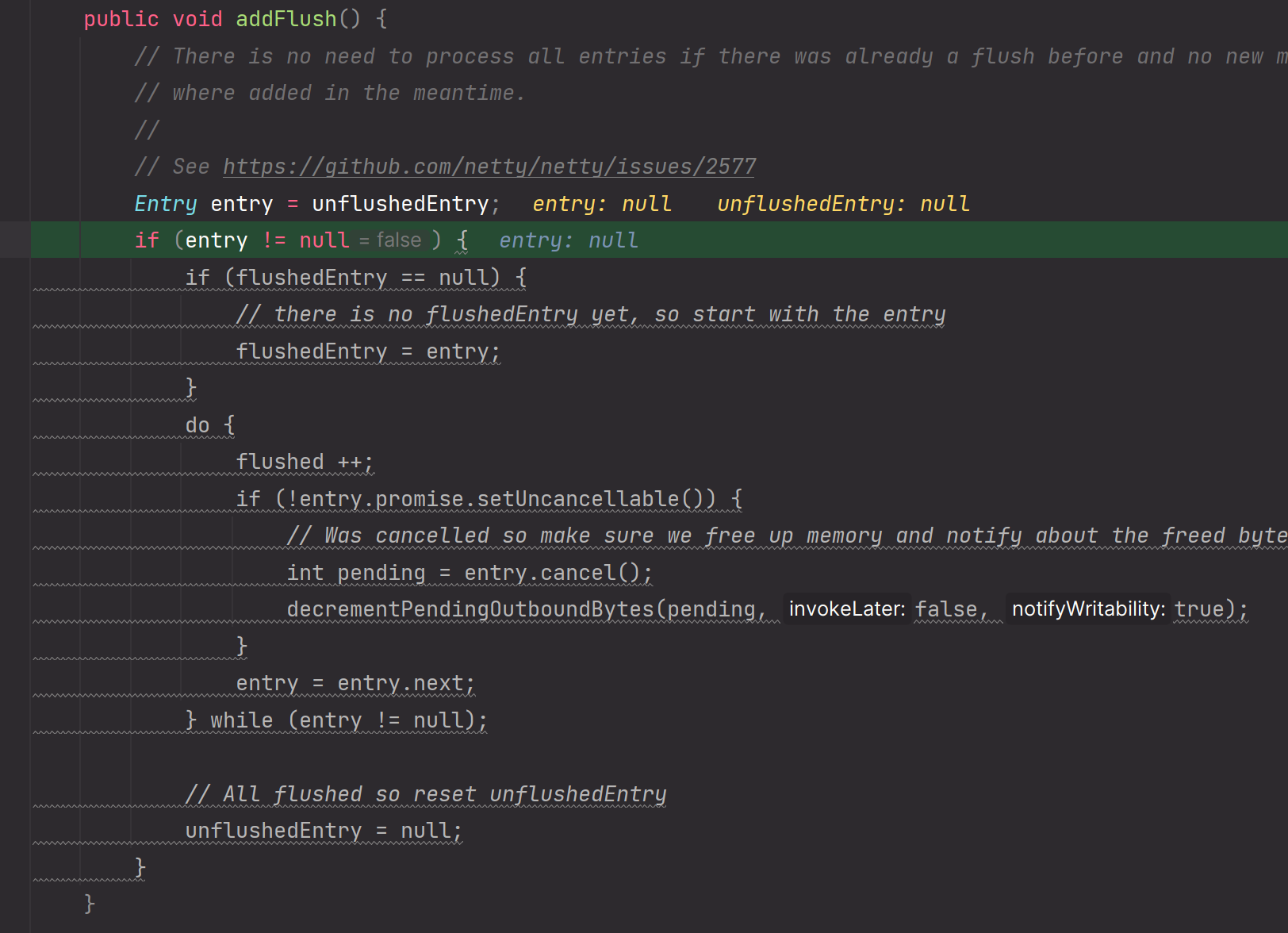
flush0方法:

核心逻辑:
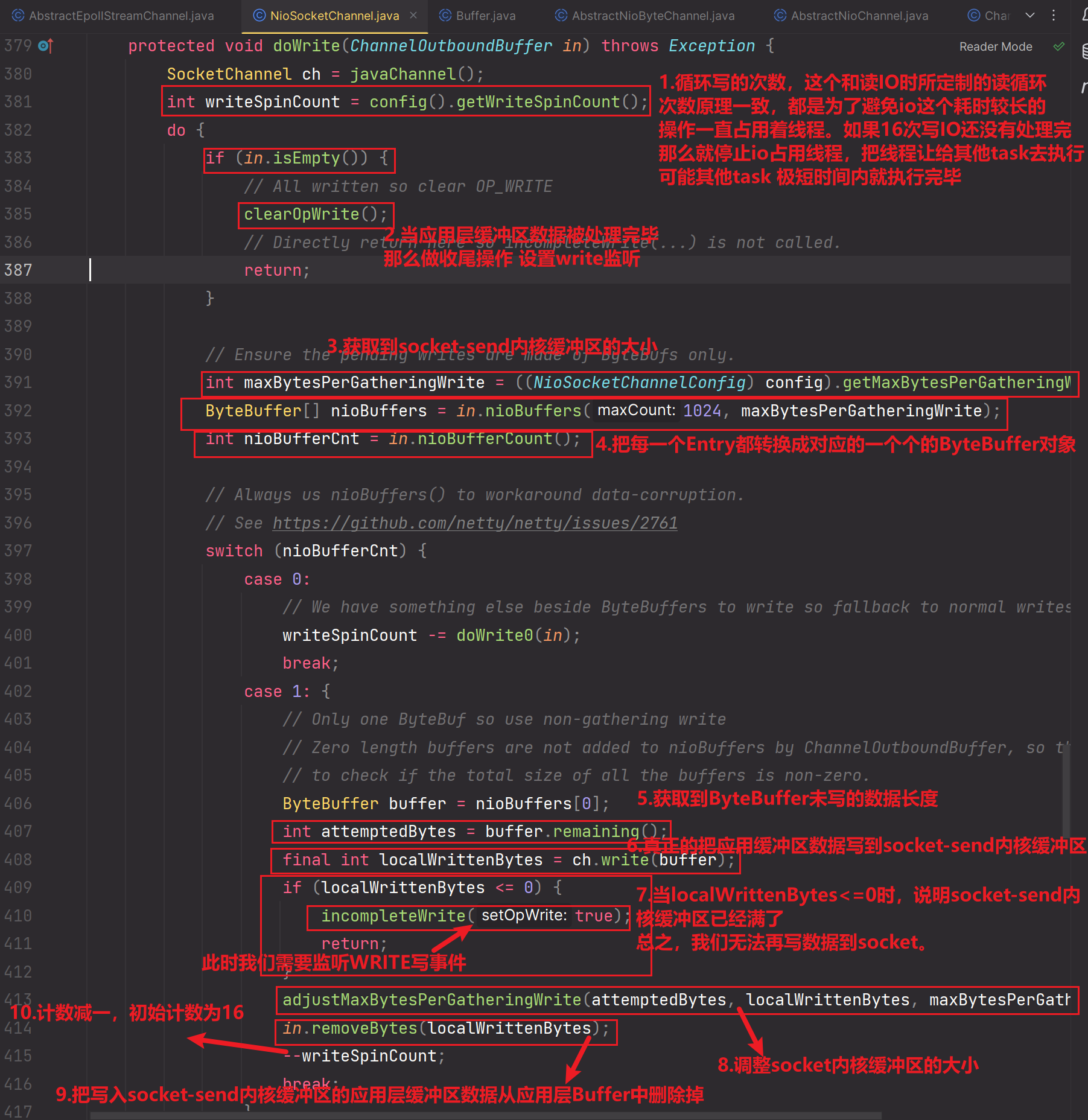
以下是doWrite方法中所调用的方法的分析,后续还会继续细致分析:
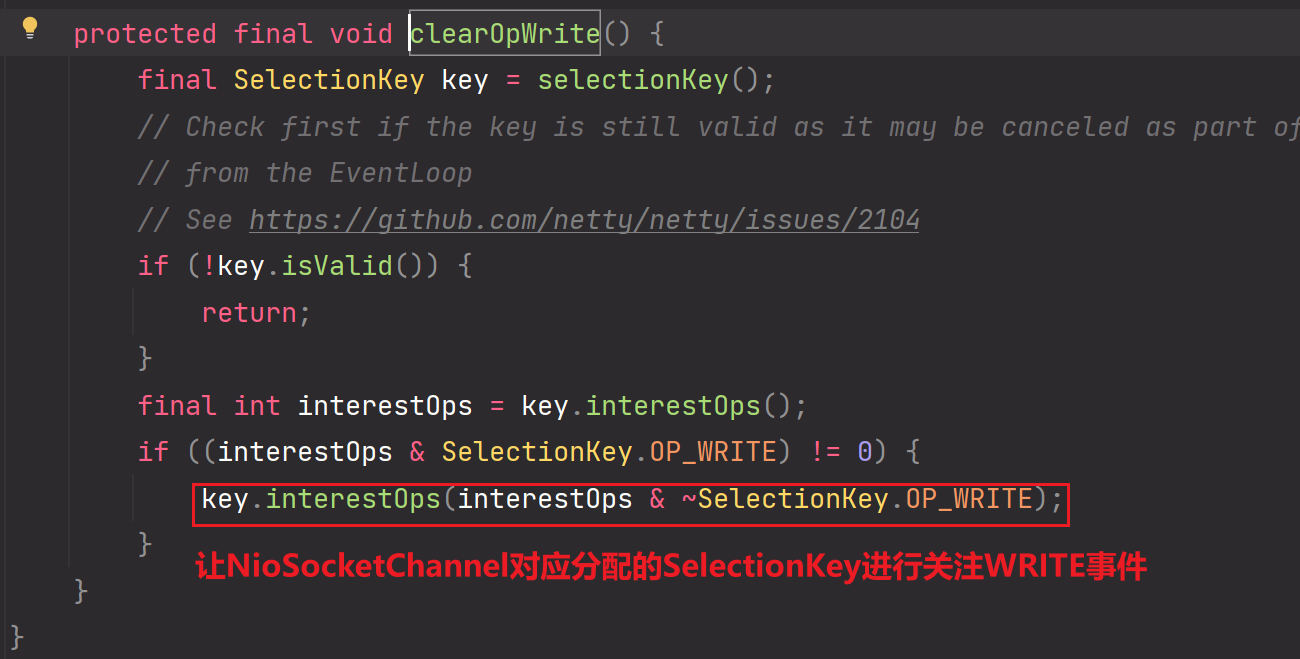
clearOpWrite方法:
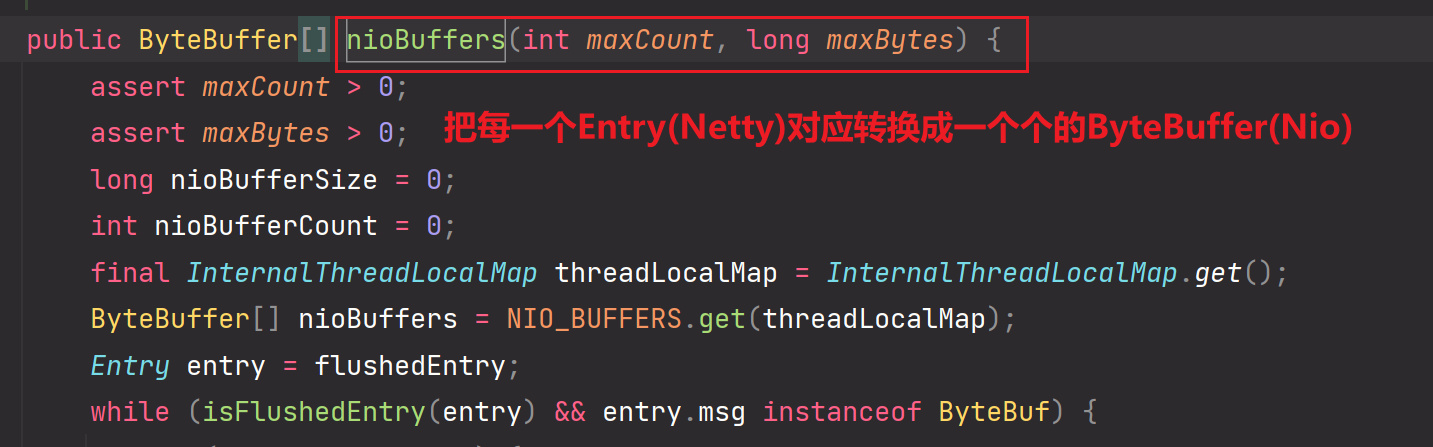
nioBuffers方法:
为什么要一个Entry对应转化成一个独立的ByteBuffer?
因为这样容易操作,如果把多个Entry放到同一个ByteBuffer,也不是不可以,而是Netty需要特别复杂的通过flip(),write()等各种NIO方法进行调配,还不如一个Entry对应一个ByteBuffer,这样容易编写逻辑,不用纠结细节的各种指针的转换
nioBufferCount方法:获取到我们转换出来的ByteBuffer缓冲区的个数,便于后续真正的把ByteBuffer缓冲区数据写入到socket内核缓冲区

adjustMaxBytesPerGatheringWrite方法:
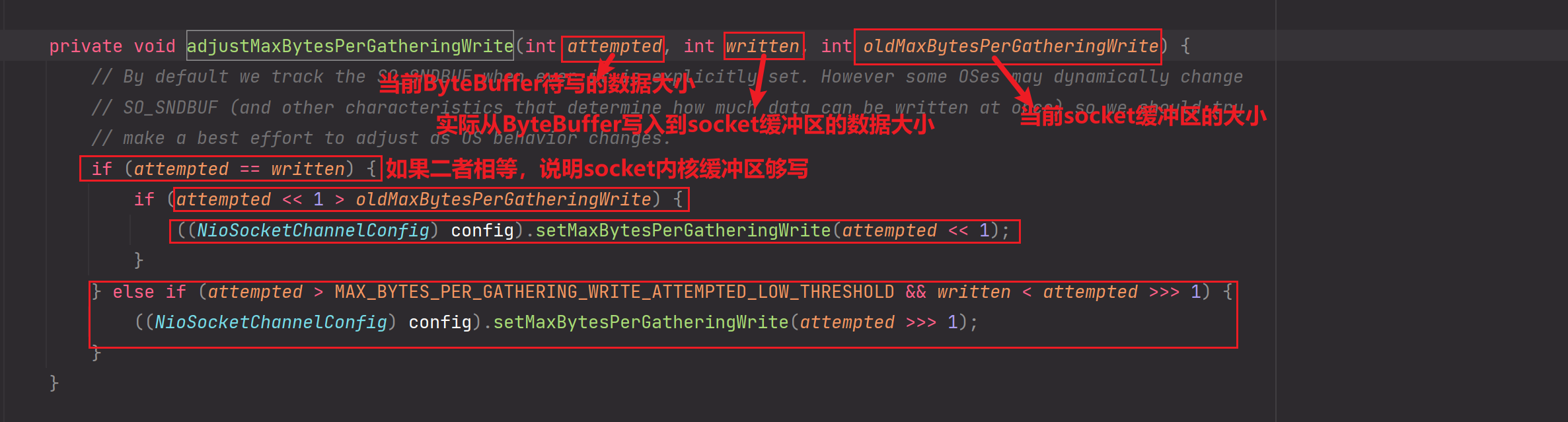
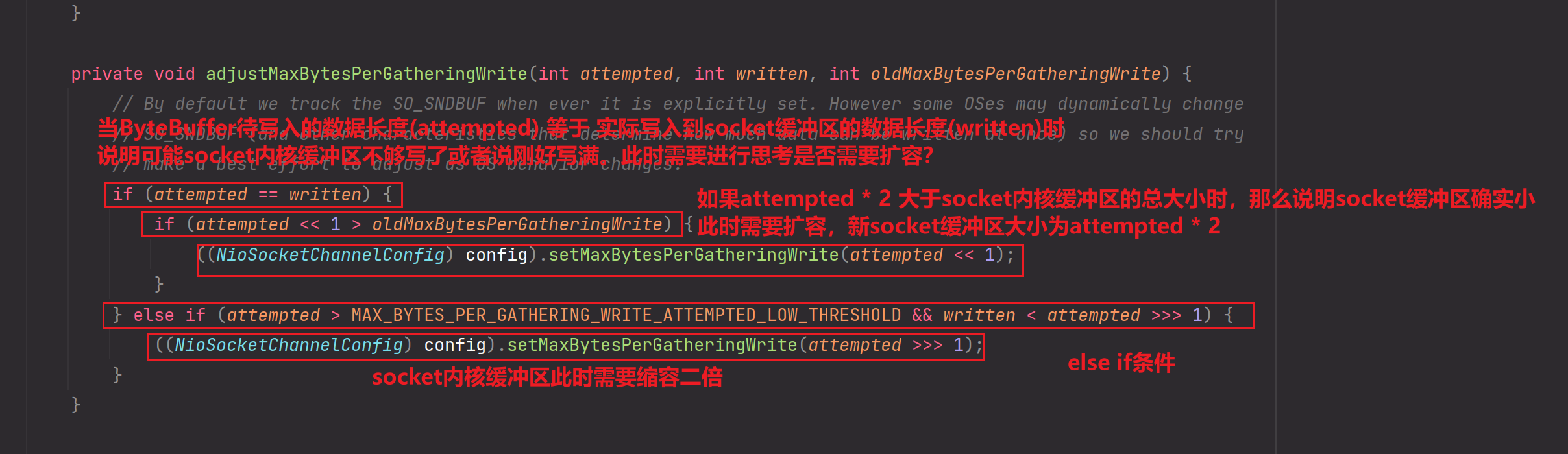
补充上图中的else-if条件的逻辑分析:
当attempted大于MAX_BYTES_PER_GATHERING_WRITE_ATTEMPTED_LOW_THRESHOLD且written小于尝试写入字节数的一半时(written < attempted >>> 1),表示实际写入的字节数较少。在这种情况下,将socket内核缓冲区的大小设置为尝试写入字节数的一半,并更新到NioSocketChannel的配置中。
这个逻辑的目的是根据实际写入字节数的情况来动态调整socket内核缓冲区的大小。当尝试写入的字节数较大而实际写入的字节数较少时,减小socket内核缓冲区的大小可以避免过度分配内存和网络资源,提高写操作的效率。
需要注意的是:MAX_BYTES_PER_GATHERING_WRITE_ATTEMPTED_LOW_THRESHOLD为socket内核缓冲区大小所对应attempted值的最低阈值!!如果attempted值小于该阈值,那么else if条件逻辑也不会成立!
这段代码中的常量MAX_BYTES_PER_GATHERING_WRITE_ATTEMPTED_LOW_THRESHOLD是一个预定义的阈值,用于控制何时触发socket内核缓冲区的大小的调整。具体的阈值大小和适用场景可能需要根据实际情况进行调整。
- 下面对Unsafe#write方法 或 flush方法中的细节进行继续剖析
Unsafe#write:
1、outboundBuffer.addMessage方法:

按步骤分析:

第一步:

RECYCLER.get():

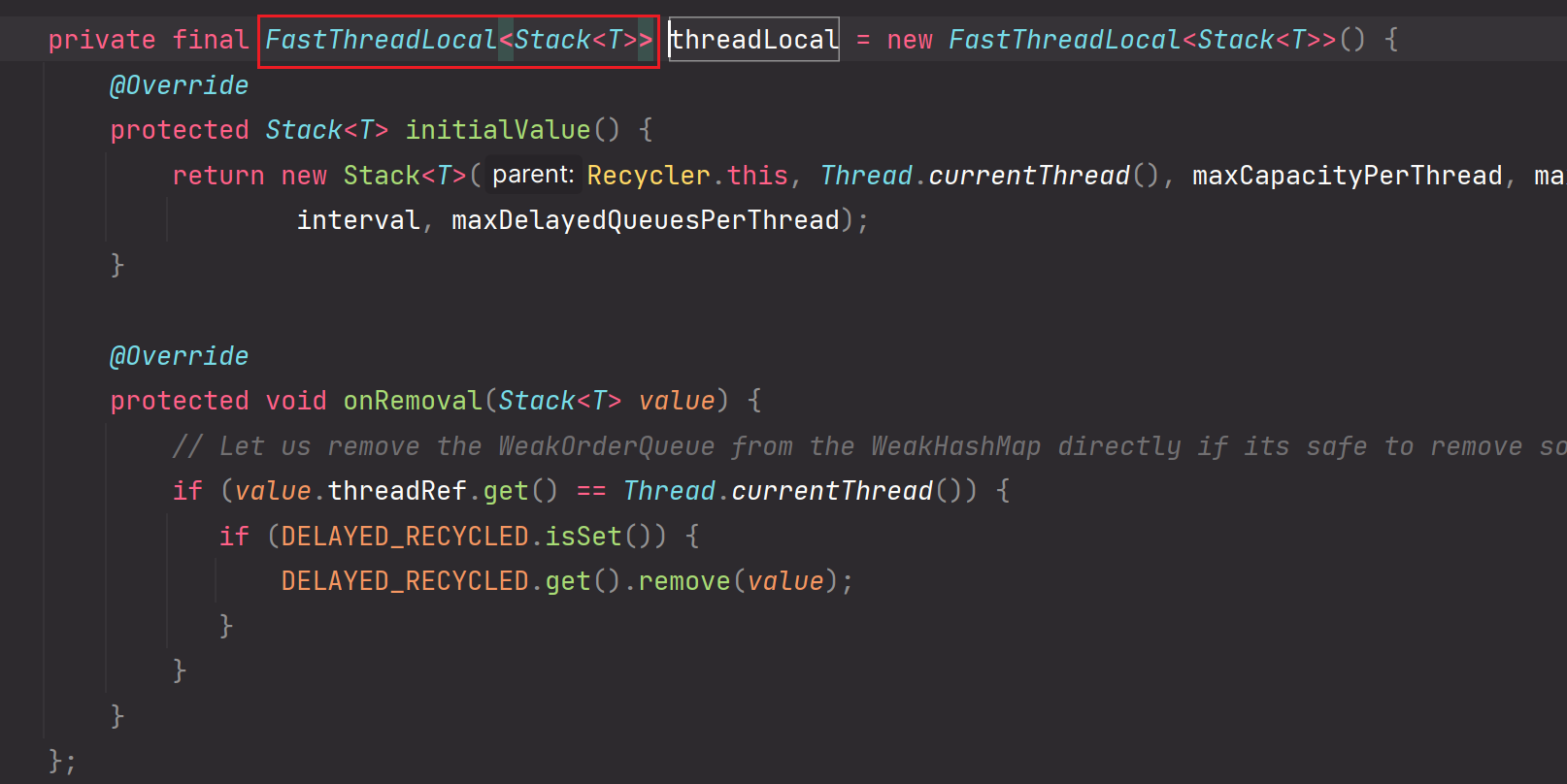
jdk原生的ThreadLocal or Netty定制的FastThreadLocal:
其实都是通过工具类xxxThreadLocal,把对象预先存储到线程所对应的内存中。
FastThreadLocal是对java原生ThreadLocal的优化,可能在对象存取方面性能变得更加优秀了。但是最终还是会保存在线程所对应的内存中的。
使用FastThreadLocal有什么好处吗?
我们是预先把对象数据存储到线程内存中的,在应用层面我们就是维护了一个对象池。我们知道,一个客户端连接到服务端,我们服务端都会分配一个线程来处理该客户端的各种操作【当然,线程NioEventLoop可以复用,如何复用的?肯定是通过Selector复用器,以及Reactor架构来共同完成复用的!Selector是复用的基础,Reactor就是多个线程对应多个独立的Selector,分治处理,如何分治处理的?一个或两个线程[一个或两个Selector]来处理Accept连接事件,多个线程来处理IO事件】。无论何时,只要是某一个客户端来连接上服务端,服务端都会甄别出该客户端所对应的线程,该线程可以通过FastThreadLocal这个数据结构进行取出对象池中预先存储好的ByteBuffer对象,这样效率极高。
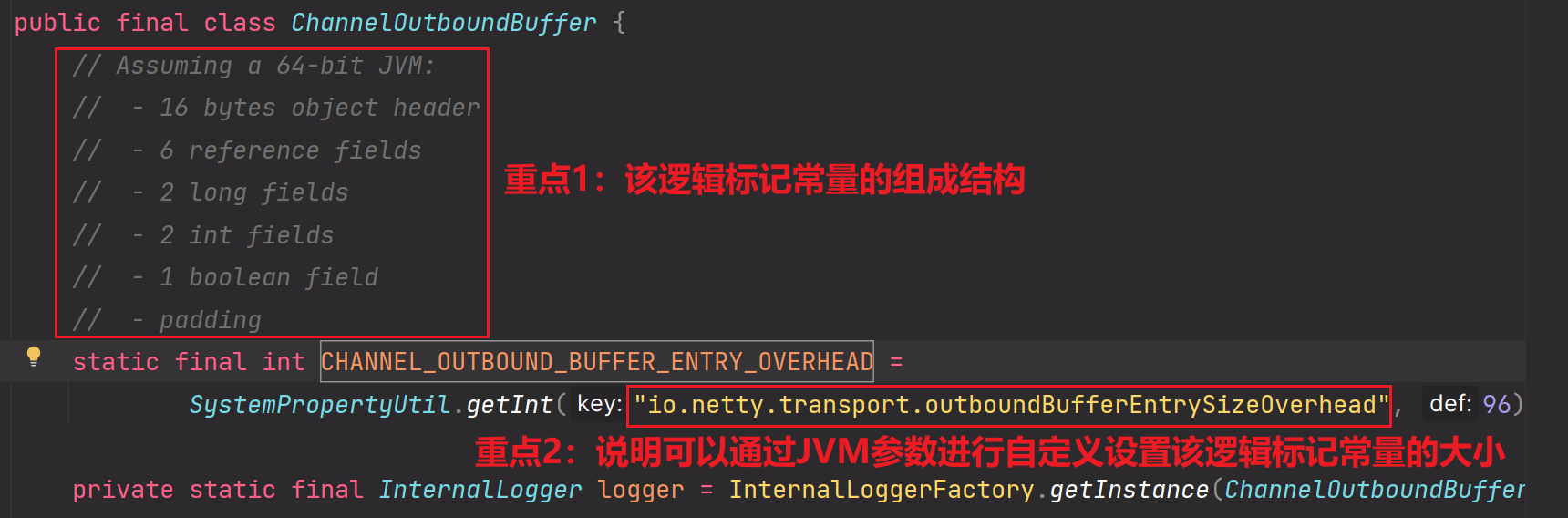
CHANNEL_OUTBOUND_BUFFER_ENTRY_OVERHEAD:
CHANNEL_OUTBOUND_BUFFER_ENTRY_OVERHEAD这个常量标识其实就是记录着Entry这个类的所有属性所对应的元数据信息记录。
为什么该常量值可以通过JVM参数进行自定义设置?
灵活性是肯定的。
情况1:96字节是相对64bit计算机对应的JVM来说的,如果是32bit的计算机所对应JVM,肯定不会是96字节这么大。
情况2:如果使用了一些对象压缩技术进行存储msg对象(Entry),那么Entry所对应的属性值什么的肯定都会被压缩,那么96字节肯定使用不了这么多,肯定需要变化。
// Assuming a 64-bit JVM:
// - 16 bytes object header 16字节的头信息数据
// - 6 reference fields 6个引用类型属性
// - 2 long fields 2个long类型属性
// - 2 int fields 2个int类型属性
// - 1 boolean field 1个boolean类型属性
// - padding 空白填充数据【JVM要求类数据长度大小是8字节的整数倍,所以要padding填充】
CHANNEL_OUTBOUND_BUFFER_ENTRY_OVERHEAD的结构所对应到Entry属性如下:
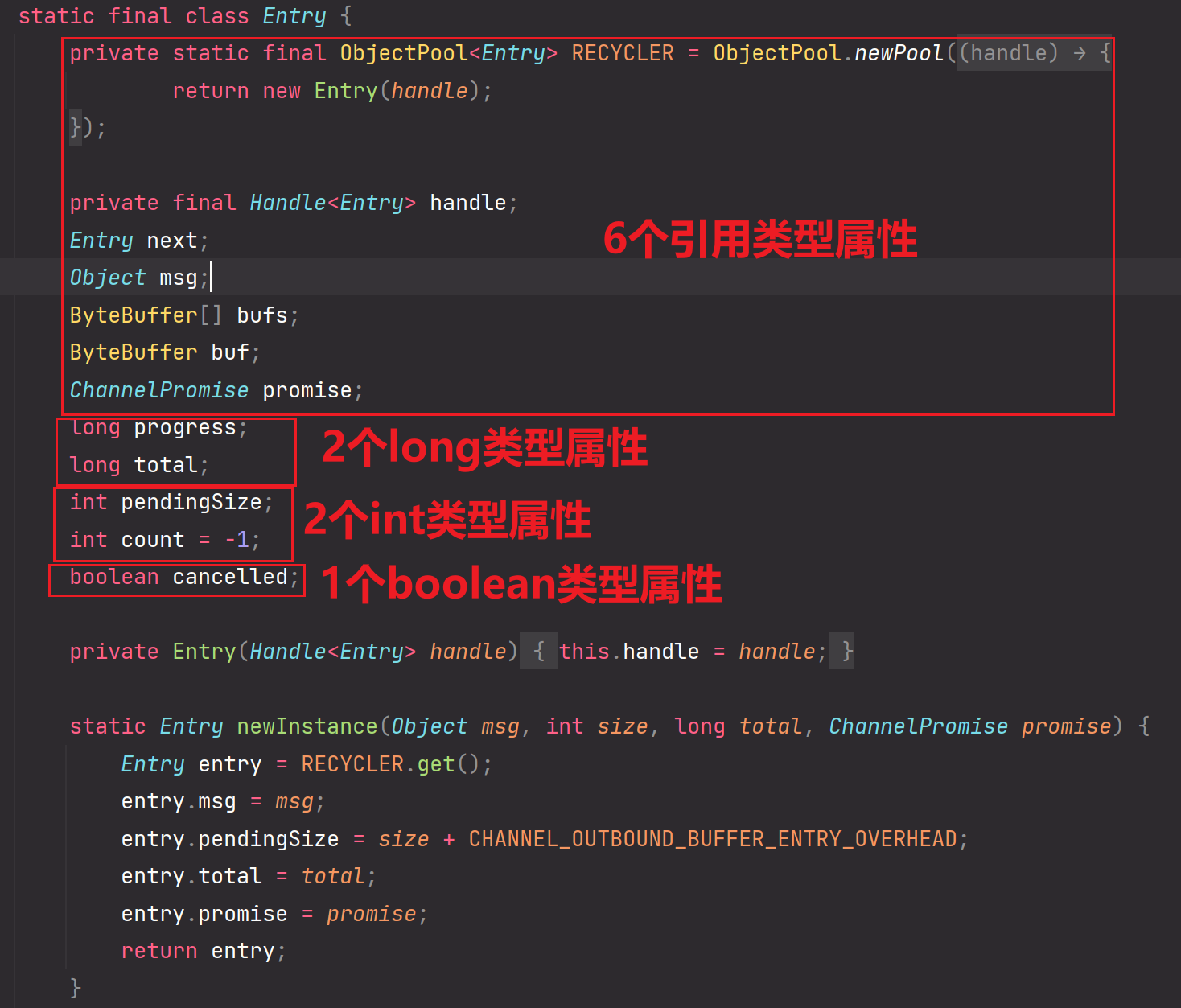
经过计算:
2 long 8*2 = 16字节
2 int 4*2 = 8字节
1boolean 1 个字节
6 个引用 8*6 = 48个字节 【假设为64位,最大一个引用类型为8字节大小】
对象头信息 16字节 【对象头信息存储包含着Mark Word(32位机器占4字节,64位占8字节) 和 类的指针(32位机器占4字节,64位占8字节),假设是64位,那么对象头信息一共占用16字节大小】
以上加起来一共有89字节
padding 对齐填充 7字节
以上一共加起来就是默认的96字节大小!

JVM虚拟机 对象占用的内存都是8个字节的整数倍,所以96字节符合要求
第二步:
当加入一个msg时:当前msg会被封装成Entry0
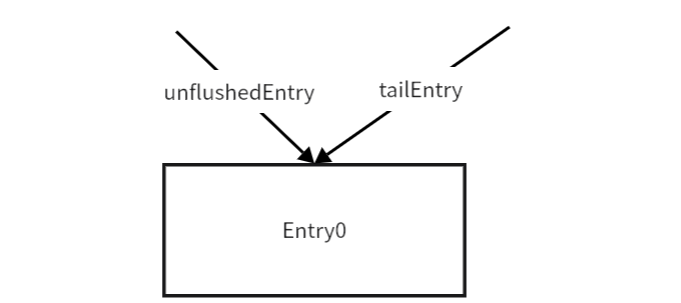
当再加入一个msg时:当前msg被封装成Entry1
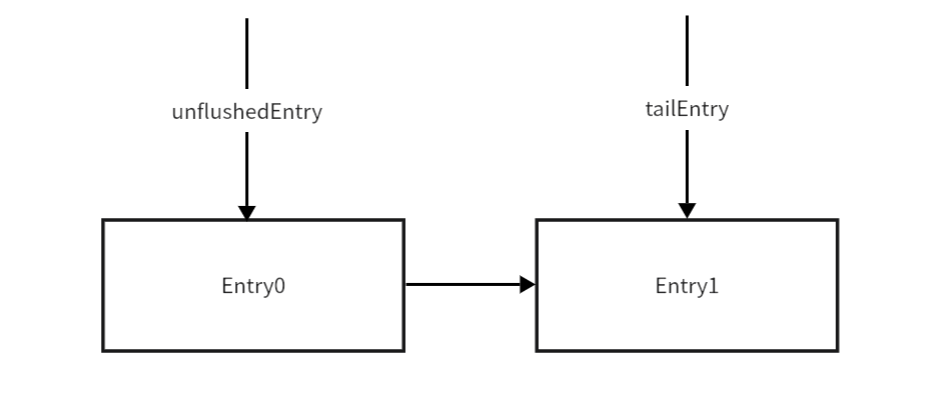
当再加入一个msg时:当前msg被封装成Entry2
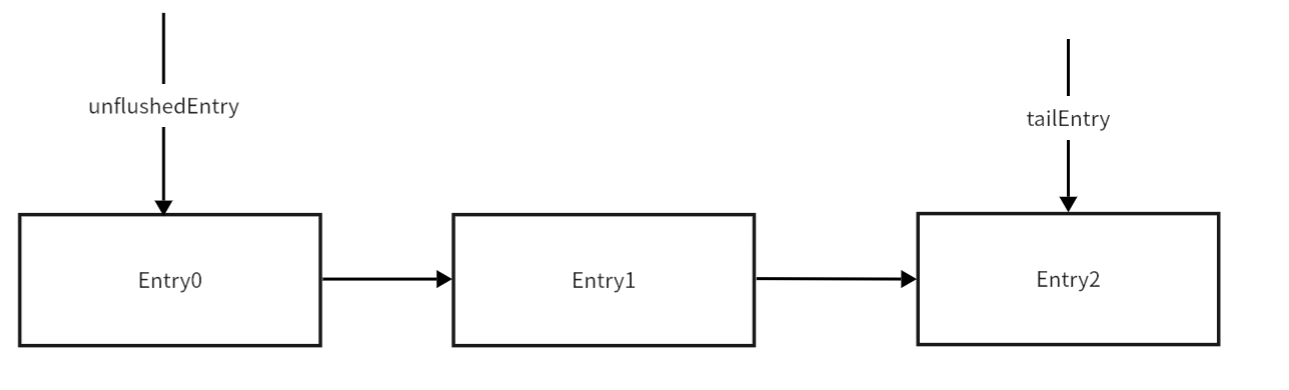
总览图:

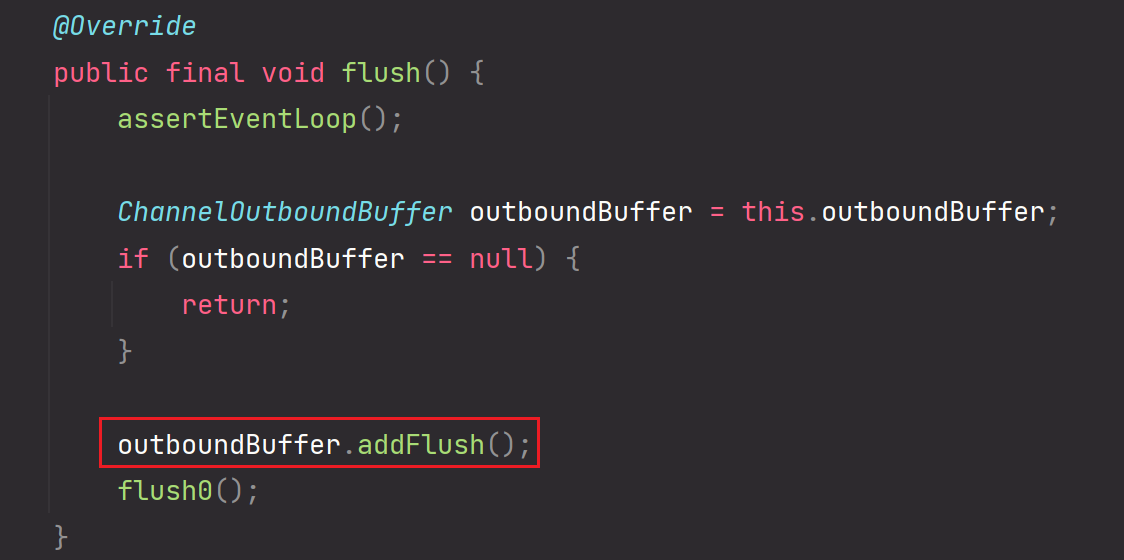
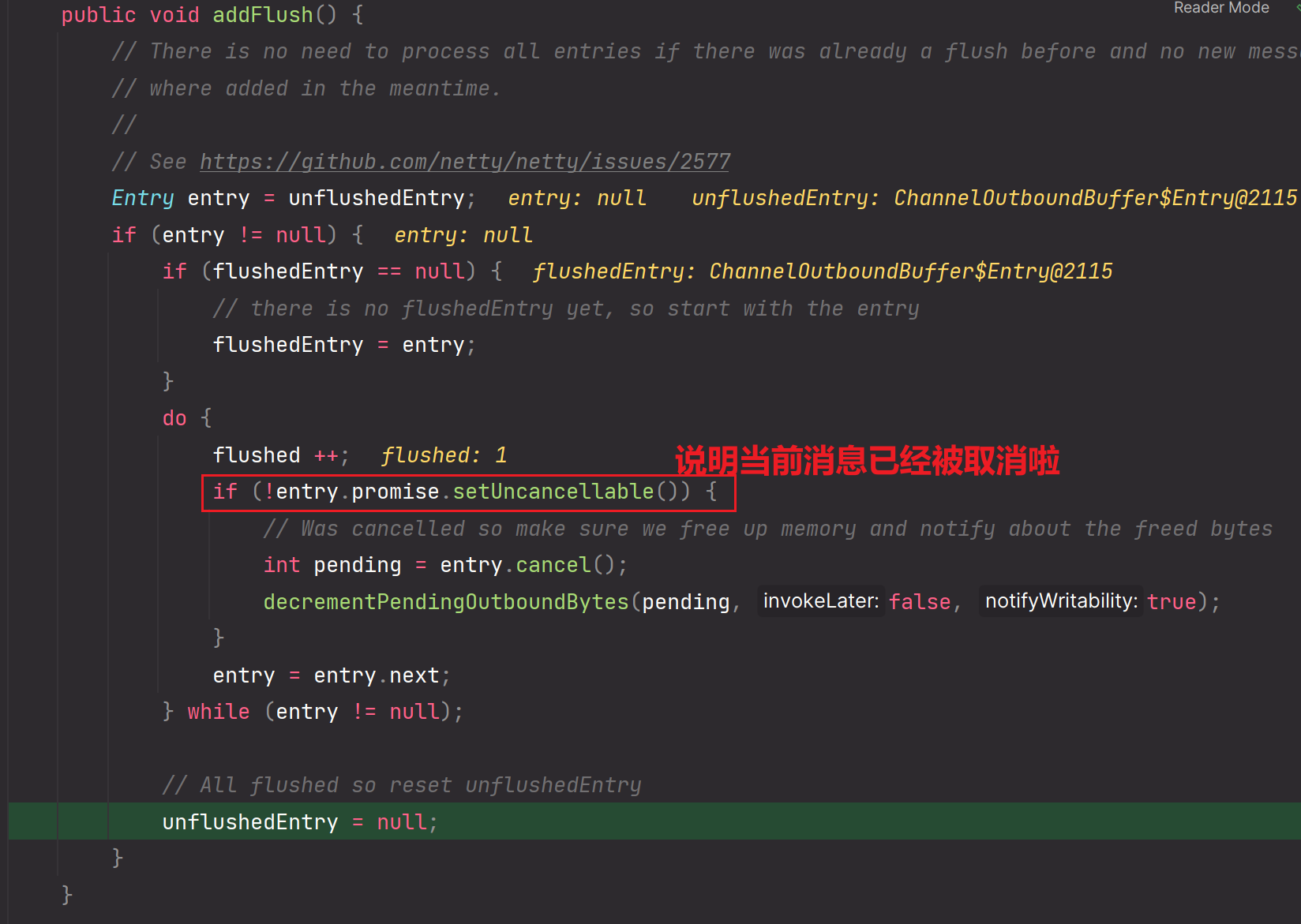
扩展:当执行到Unsafe#flush过程后,调用addFlush方法后会怎么样?
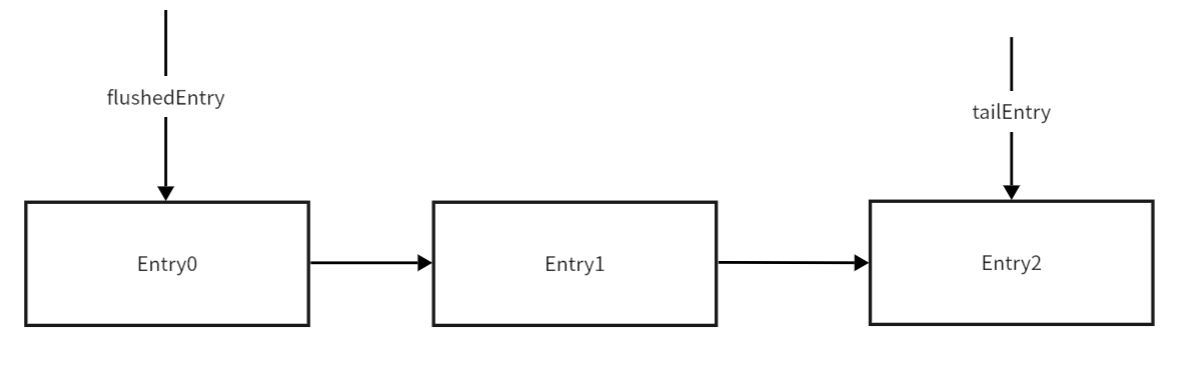
其实还是操作这个Entry链表,只不过会改变unflushedEntry为flushEntry

上图Entry链表变为如下所示:
单纯只是把unflushedEntry 变为 flushedEntry,其余一概不变,使用的还是原先的Entry链表
第三步:
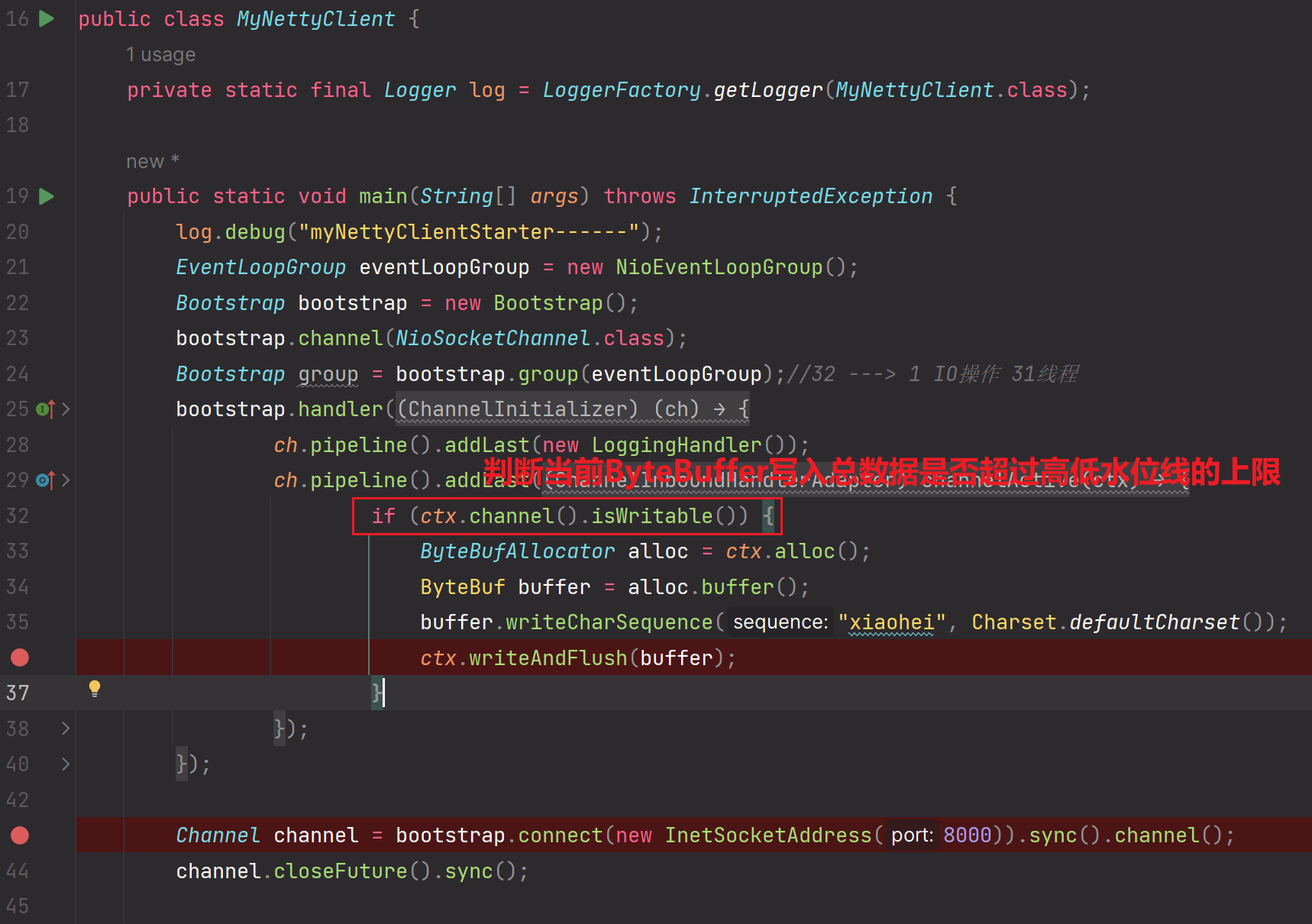
实际开发过程中,如何使用到高低水位线来甄别是否可以写数据到ByteBuffer缓冲区?
使用API:ctx.channel().isWritable()
if (ctx.channel().isWritable()) {
//该方法isWritable()如果为true,说明没有超过高低水位线的上限,那么可以写到ByteBuffer缓冲区。如果为false,说明超过高低水位线的上限,那么设为不可写。
eg:
高低水位线补充
参考文章:https://blog.51cto.com/u_11259325/3055544
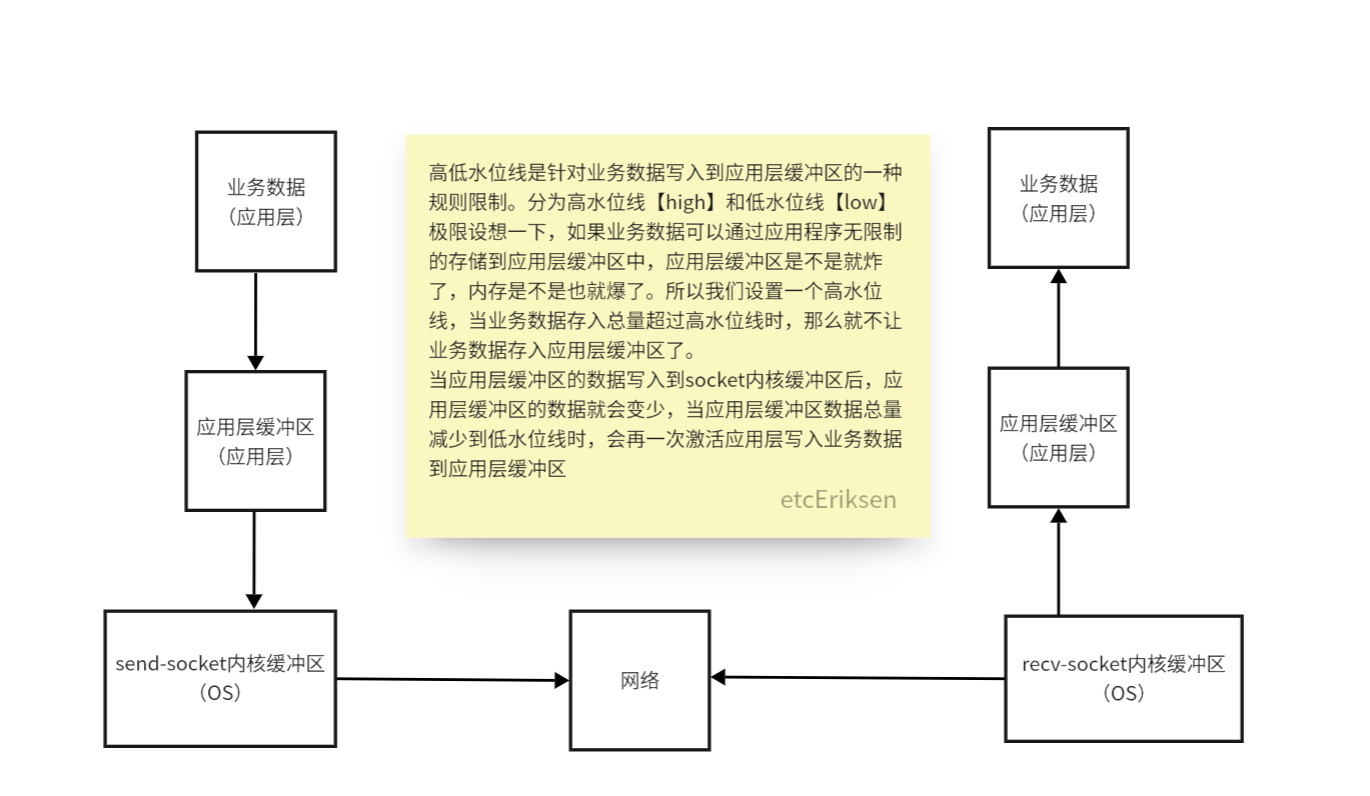
总结:高低水位线是针对应用程序是否可以写数据到应用层缓冲区的一种规则限制!进而实现流控,避免应用层缓冲区爆裂导致内存不足。
- 高低水位线在Netty中的应用
在下一点中会介绍到
ChannelOutboundBuffer总览 & 高低水位线的剖析
其实在前面总结Unsafe#write and flush中已经对ChannelOutboundBuffer这一部分进行了重复性内容的分析,这里会再一次总览一下。
ChannelOutboundBuffer就是应用层缓冲区Buffer的一个具体实现!
1.write方法
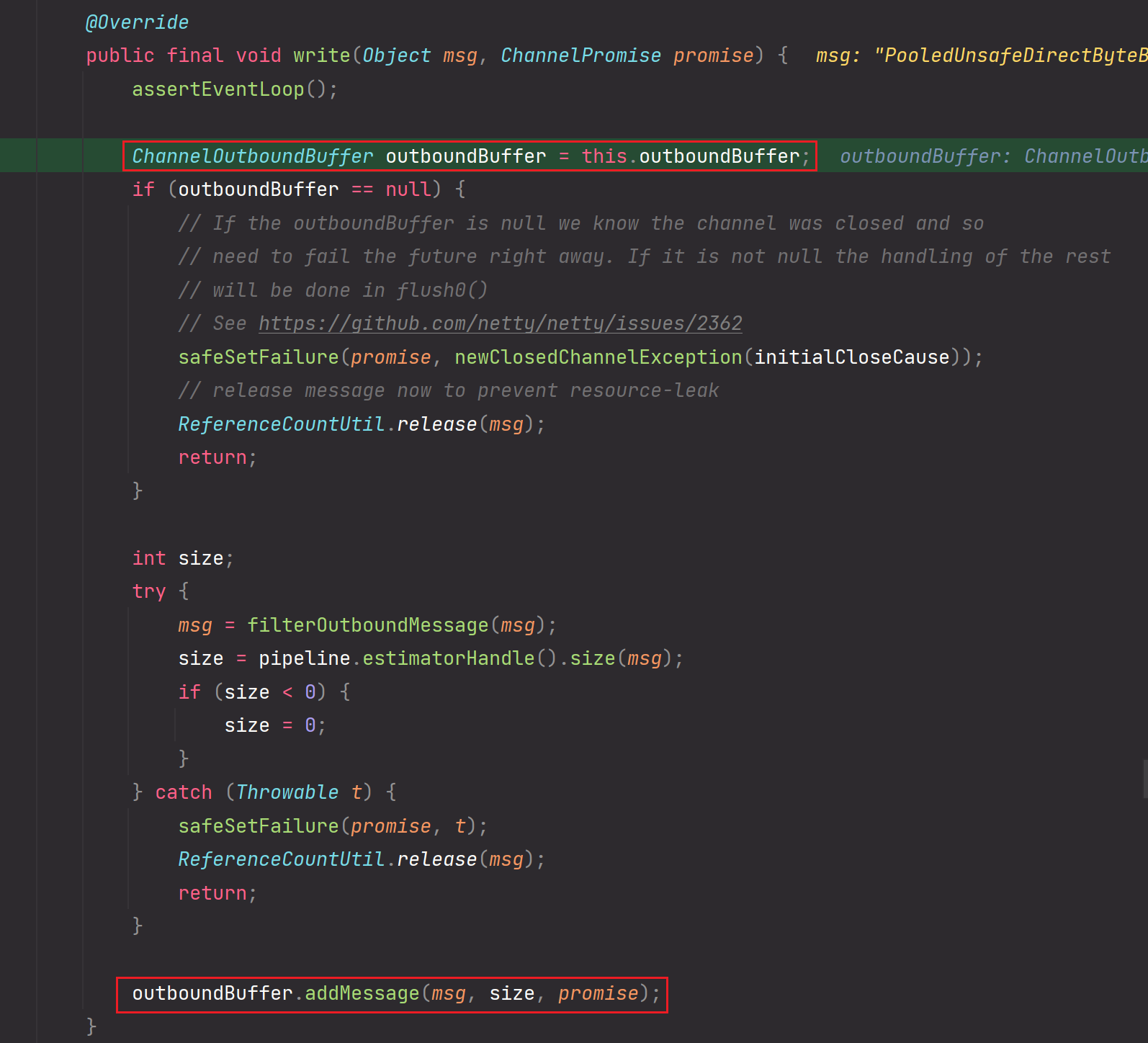
2.outboundBuffer#addMessage
把msg消息数据存储到应用层outboundBuffer缓冲区中,但是注意存储方式:是把msg消息对象转换成一个个对应的Entry对象,然后构建成一个Entry链表进行存储起来。但是也不是无限制的存储,如果在应用层缓冲区中无限制的存储msg消息数据,应用层缓冲区空间是不是就爆裂了?对吧。一旦msg消息数据堆积过多,那么内存就会被撑爆。所以高低水位线的上限就起到很大作用啦。后续会细致分析高低水位线的上限和下限
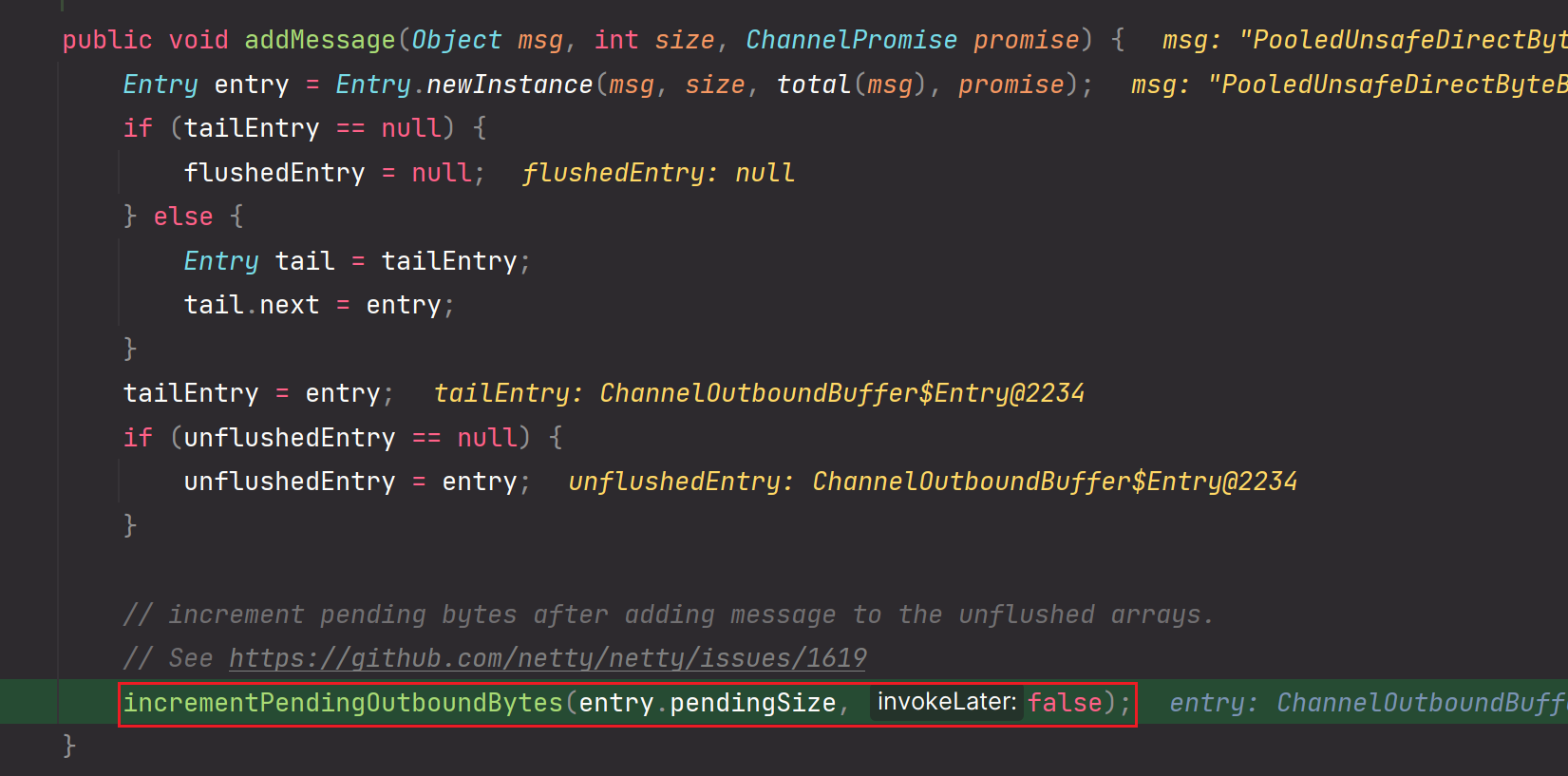
addMessage这个方法执行完,所有Entry会被链接为一个链表。
3.每一次我们想要把msg消息数据写入到outBoundBuffer缓冲区时,都会做一次累加操作,把msg消息数据长度size累加,如果当前累加长度已经大于高低水位线的上限的话,那么就可以再写入msg消息数据到应用层缓冲区啦【在代码层面的体现为:setUnwritable(invokeLater)】
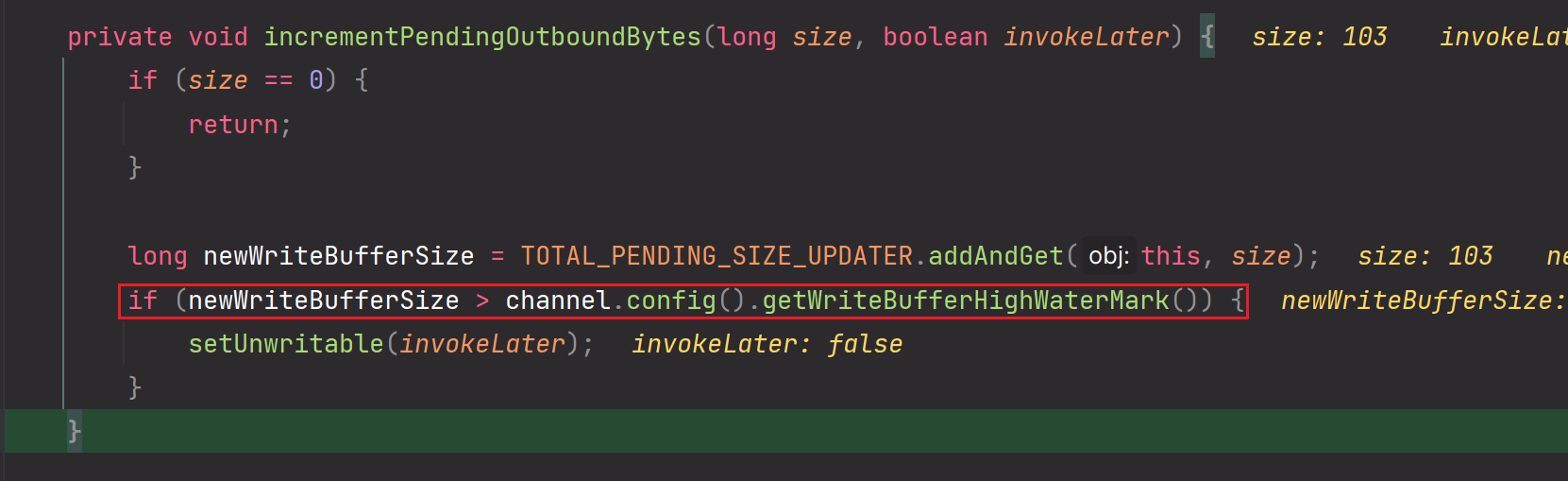
4.write流程做完,此时数据已经加载到应用层缓冲区啦。此时会执行flush操作,flush才是真正的把应用层缓冲区数据写到操作系统级别的socket内核缓冲区

5.

6.addFlush方法
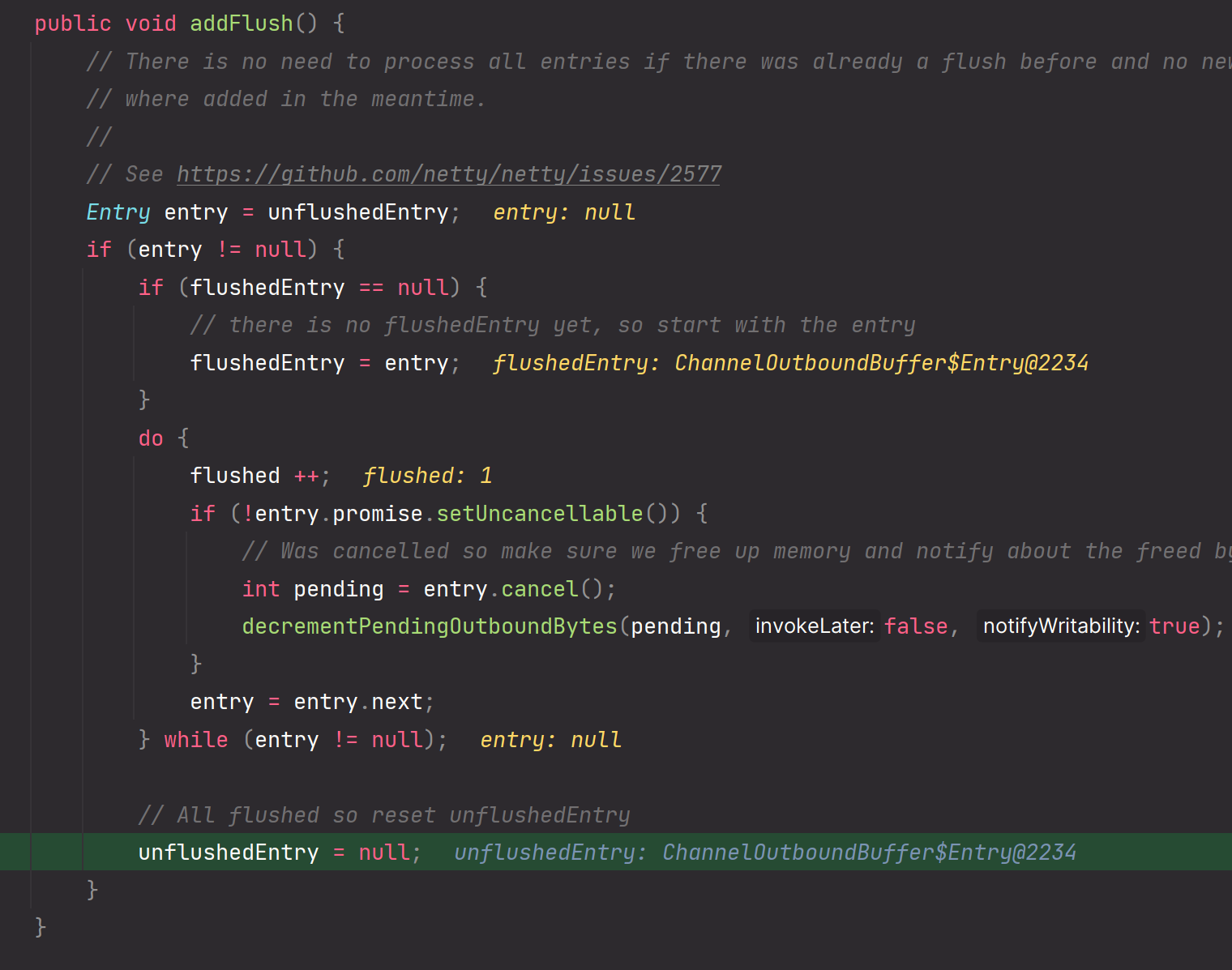
该方法是做flush标记,表示可以把应用层缓冲区的数据flush刷新到socket内核缓冲区啦
addFlush方法执行完毕后,链条如下图所示:
7.flush0方法
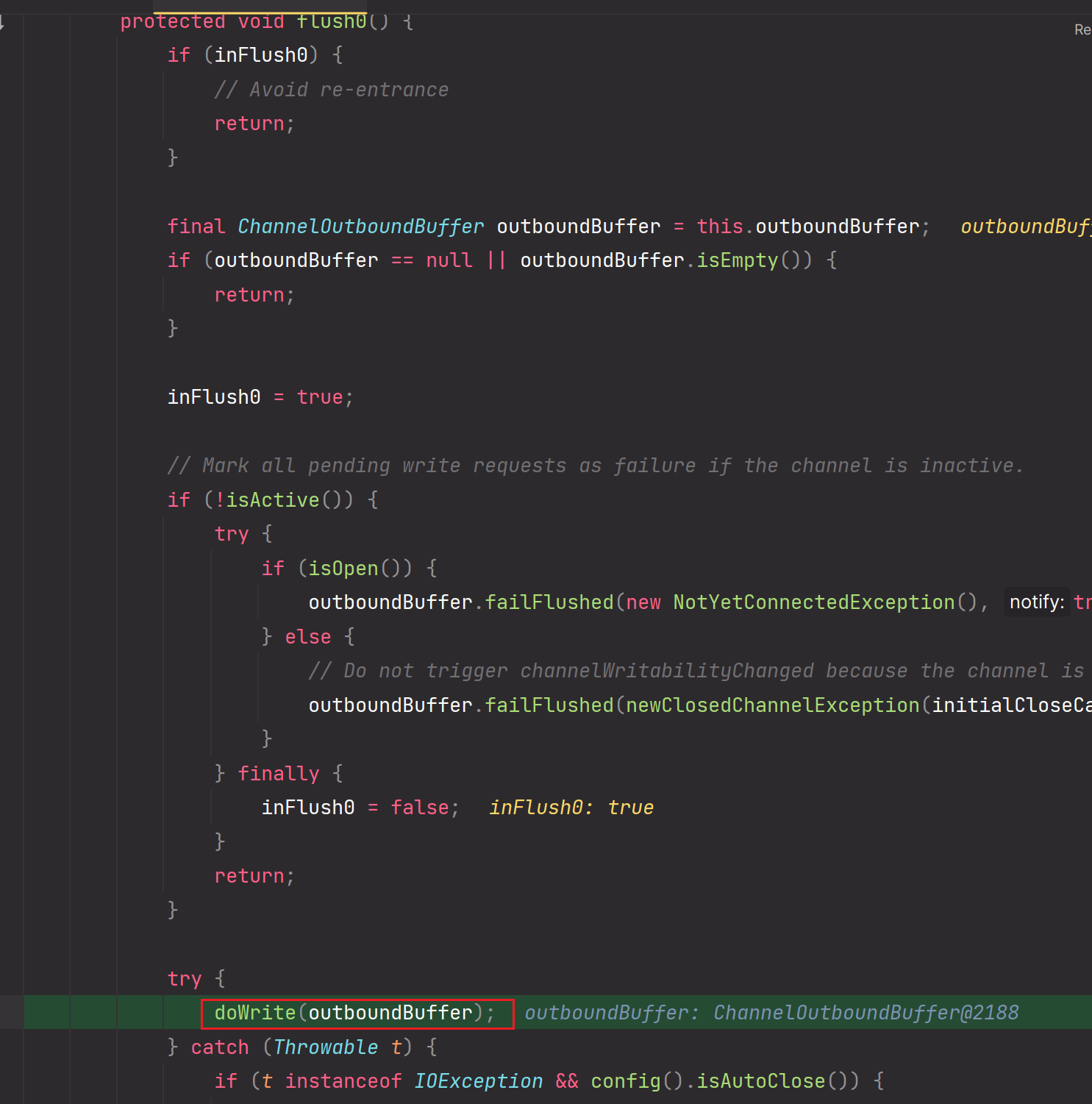
8.doWrite方法
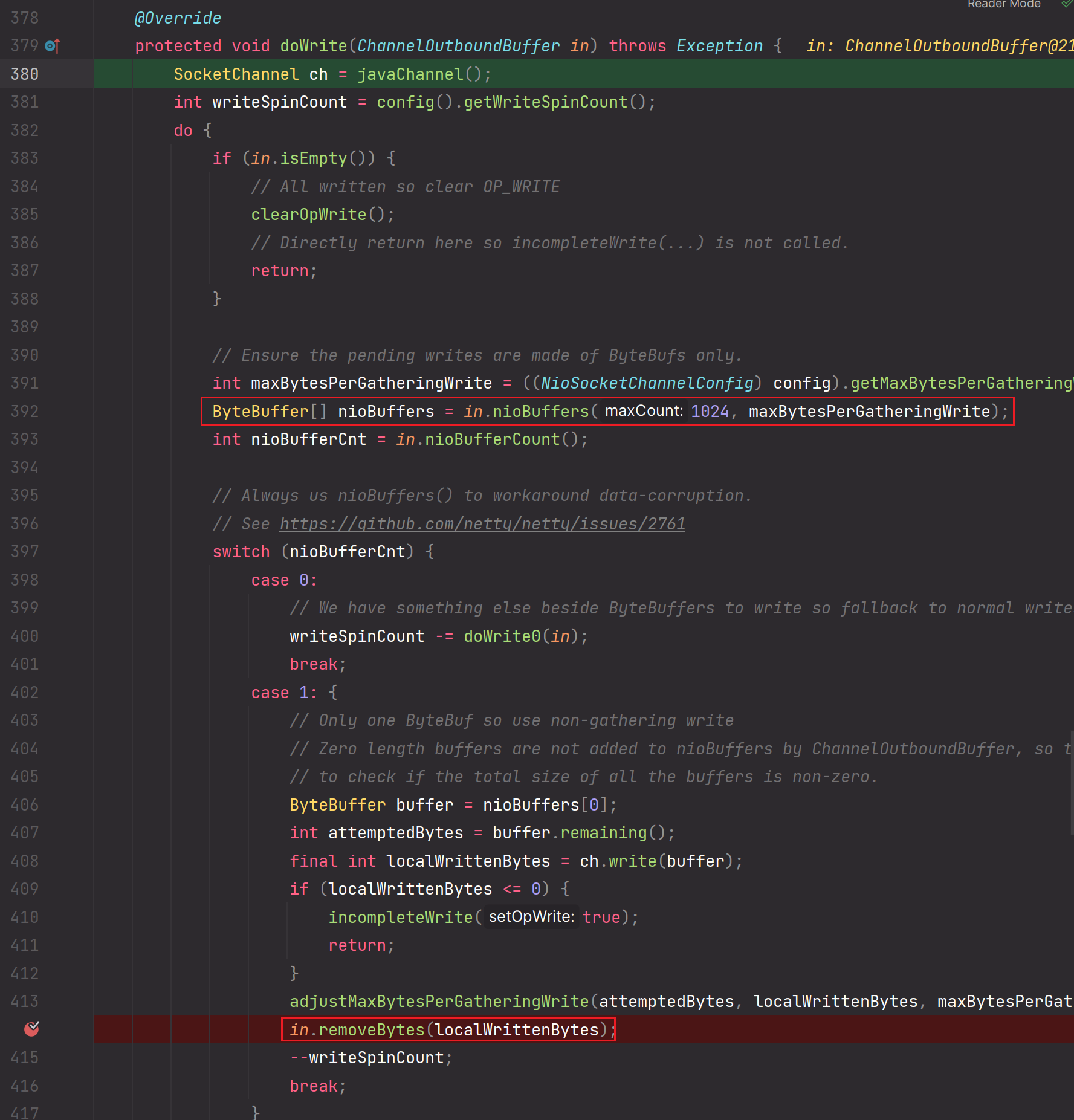
9.ByteBuffer[] nioBuffers = in.nioBuffers(1024, maxBytesPerGatheringWrite);
这个方法的作用:一句话说完,就是把Netty层面封装的一个个Entry对象进行一 一对应转换成Nio层面封装的ByteBuffer对象
如果Entry对象有多个,那么转换封装出来的ByteBuffer对象就有多个。
该方法会求出ByteBuffer的个数和所有ByteBuffer累加的size长度。
所以:nioBufferCount属性封装的就是ByteBuffer的个数。nioBufferSize封装的就是所有ByteBuffer累加的size长度。
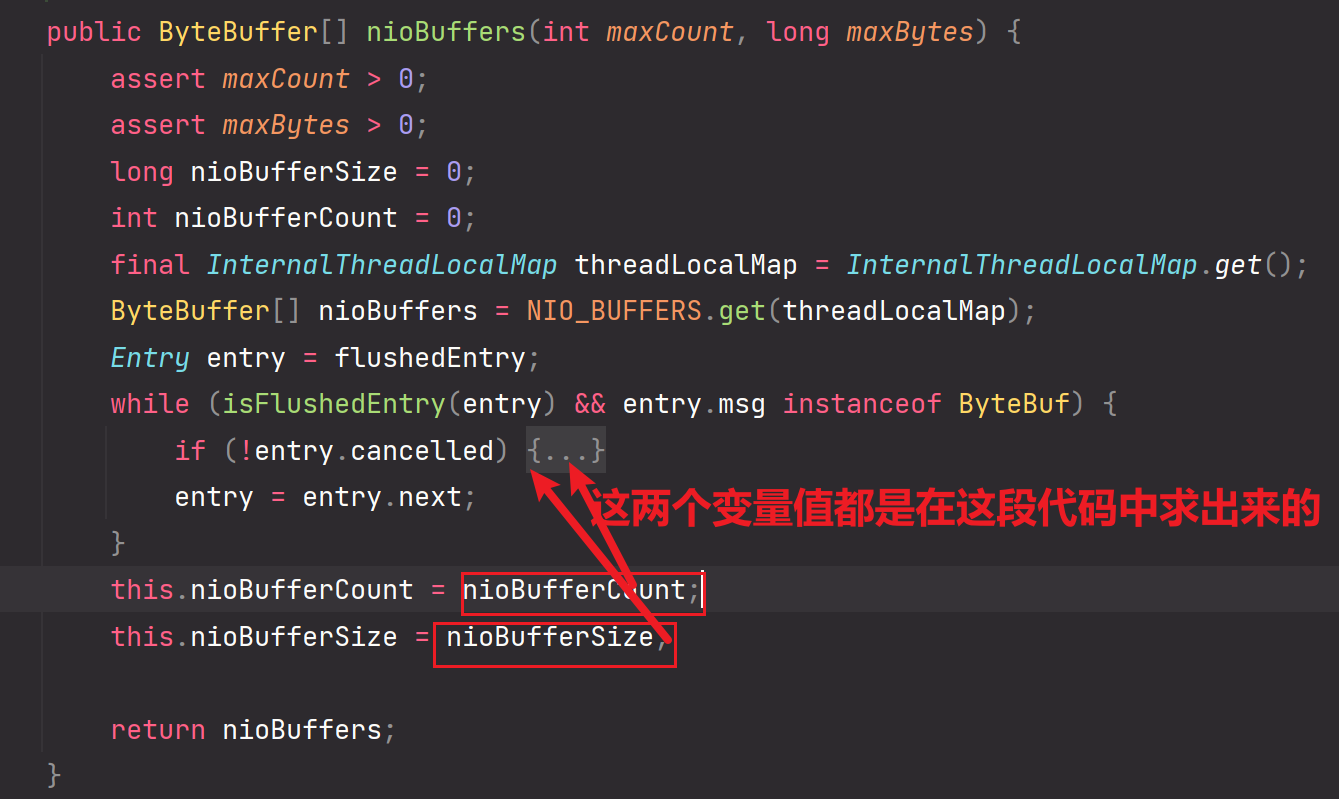
细节剖析:
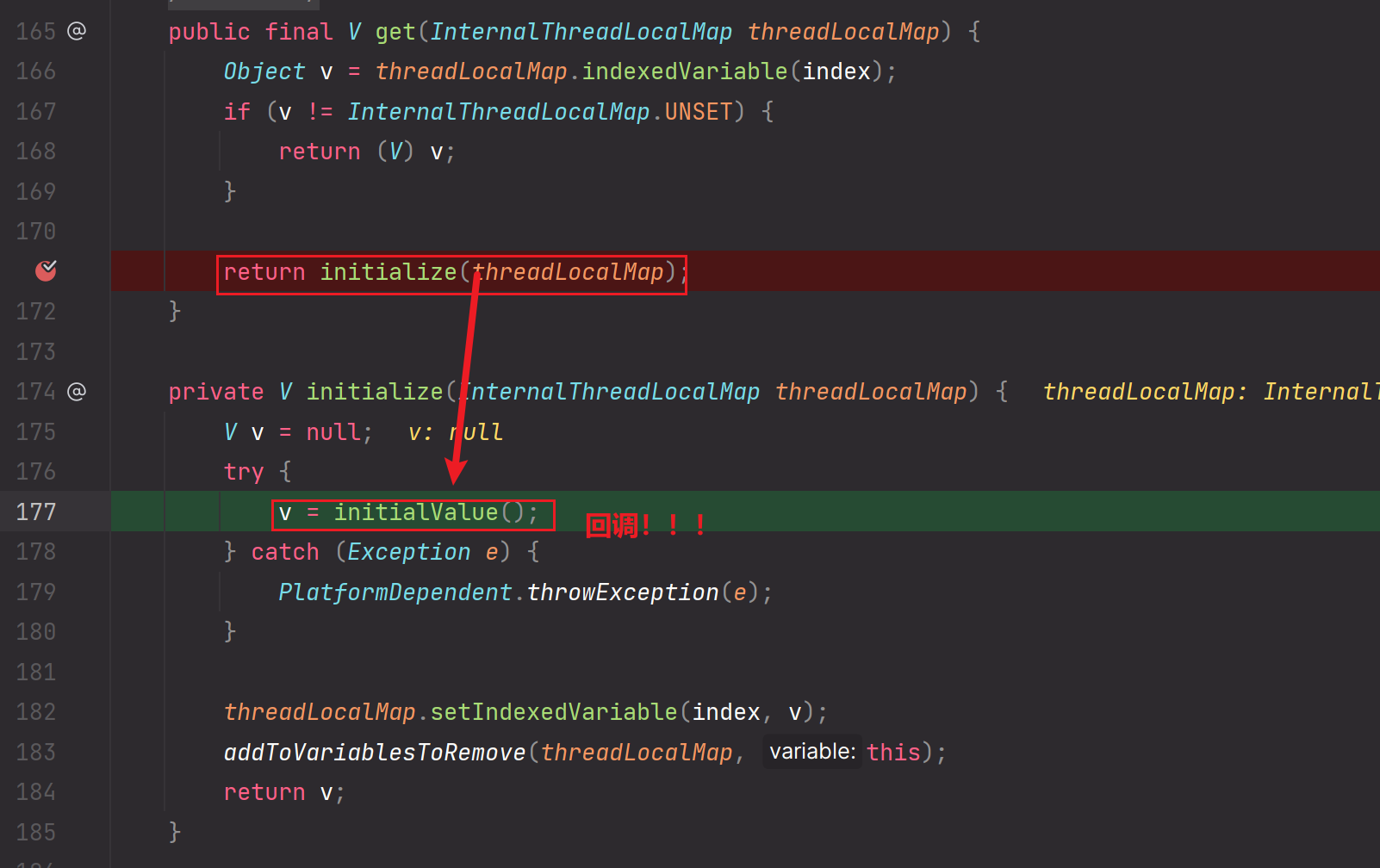
in.nioBuffers(1024, maxBytesPerGatheringWrite);这个方法会通过FastThreadLocal进行预先创建出一组长度为1024的ByteBuffer数组,但是这个ByteBuffer数组是无值的。后续我们需要通过nioBuffers这个方法的逻辑进行封装一个个的Entry对应成一个个的ByteBuffer对象,把ByteBuffer对象存储到FastThreadLocal预创建的ByteBuffer数组中。但是由于长度的限制和maxCount的限制,最多存储ByteBuffer的个数为1024。所以一次最多处理1024个Entry【1024个msg消息对象】

FastThreadLocal:之前也总结过FastThreadLocal的概述,这里不再过多阐述


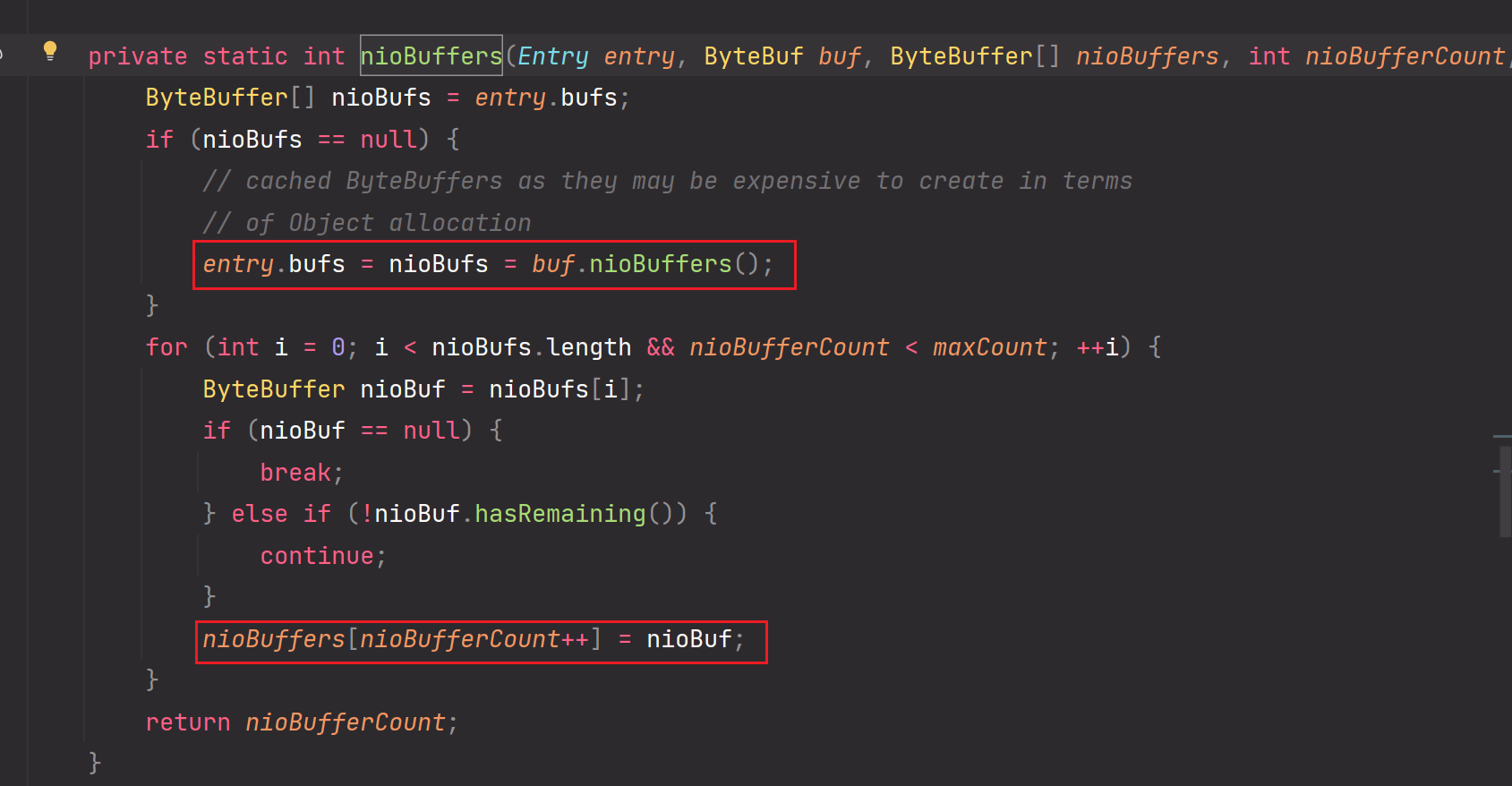
while循环处理逻辑:
完成对一个个Entry的封装,封装成对应一个个ByteBuffer对象。并且把ByteBuffer对象存储到FastThreadLocal所对应预先创建的ByteBuffer数组中。

如果有多个Entry,那么调用该重载方法进行处理,处理封装成多个ByteBuffer。
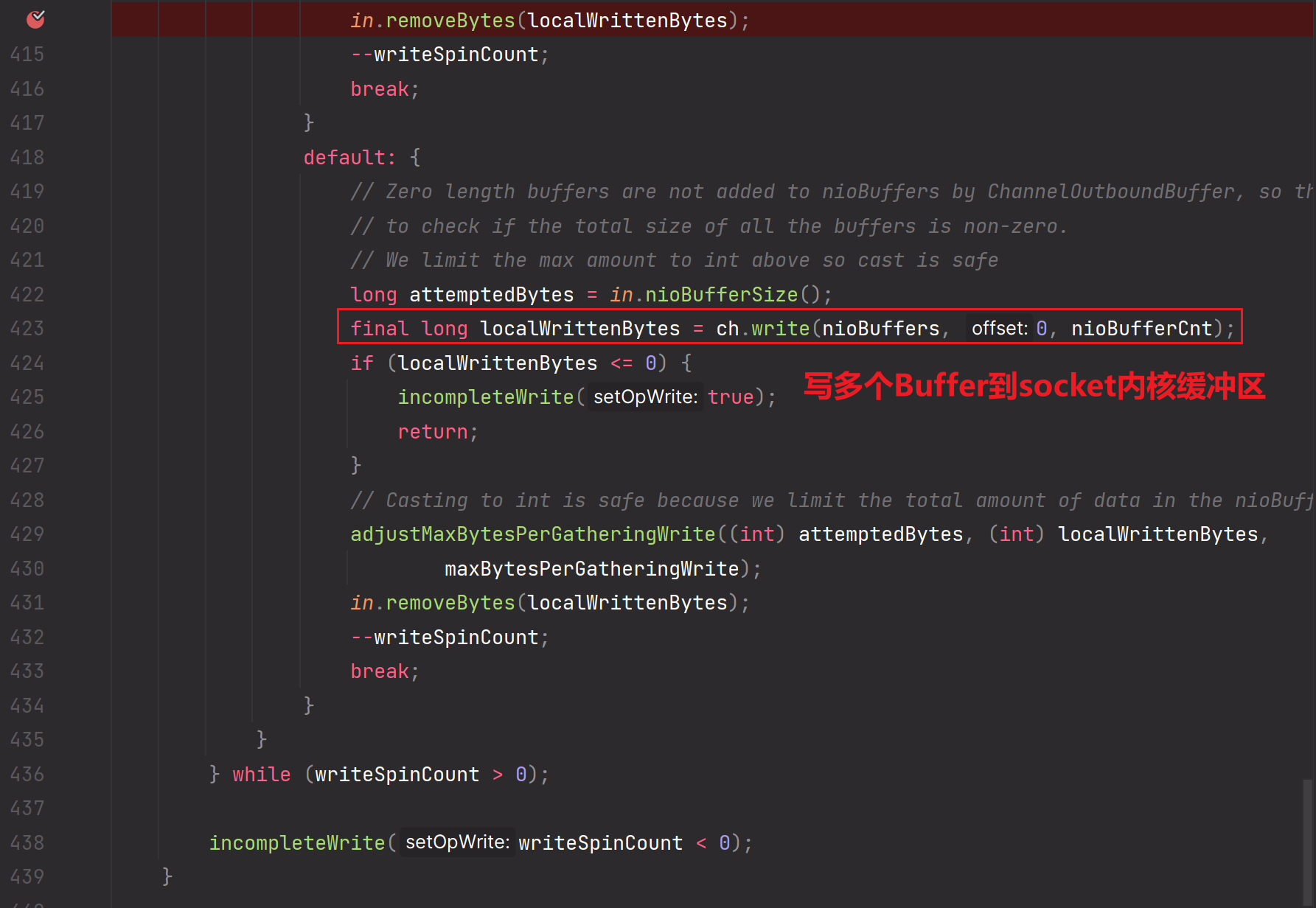
10.in.removeBytes(localWrittenBytes);
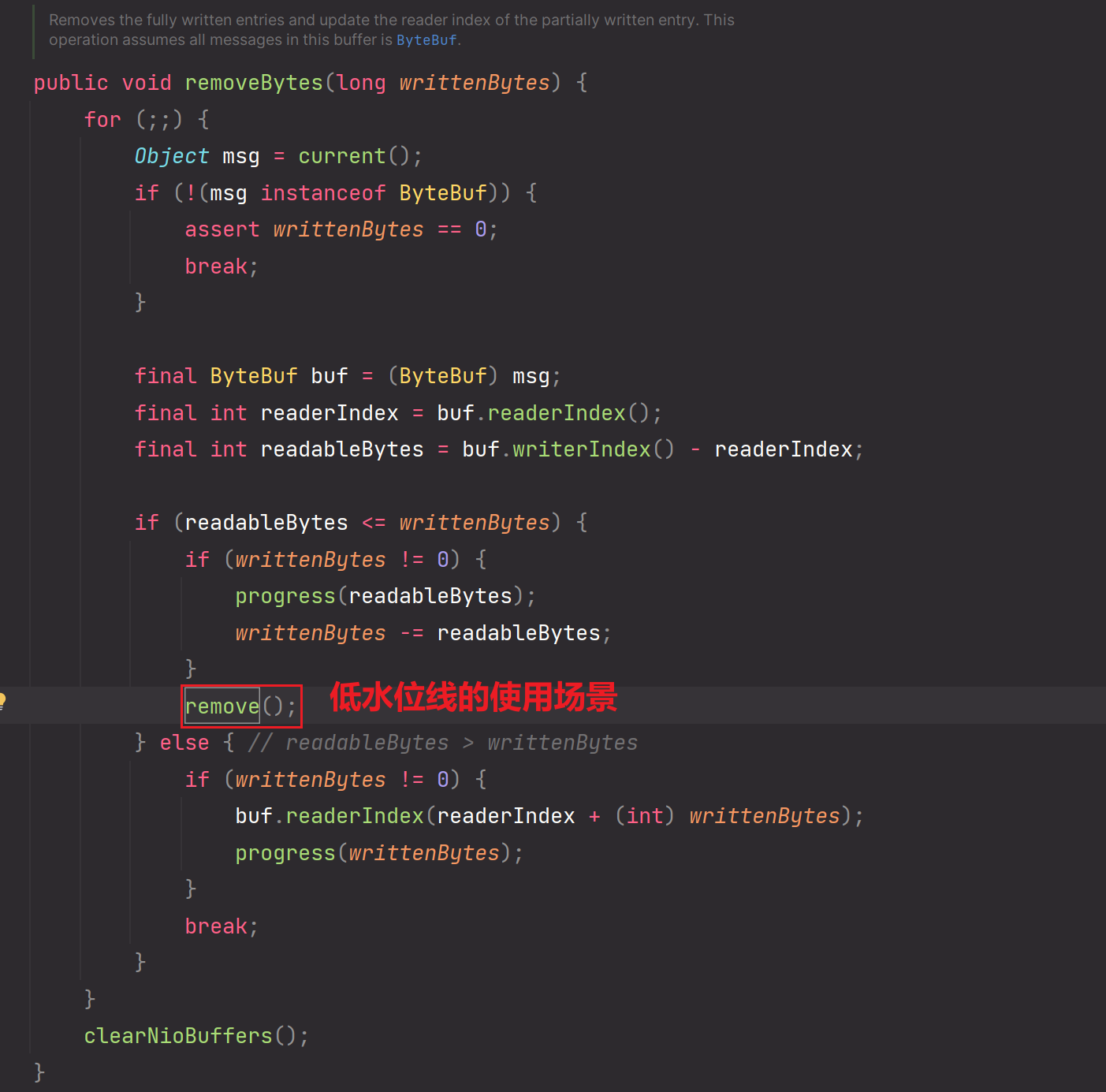
remove方法:

removeEntry(e)方法:
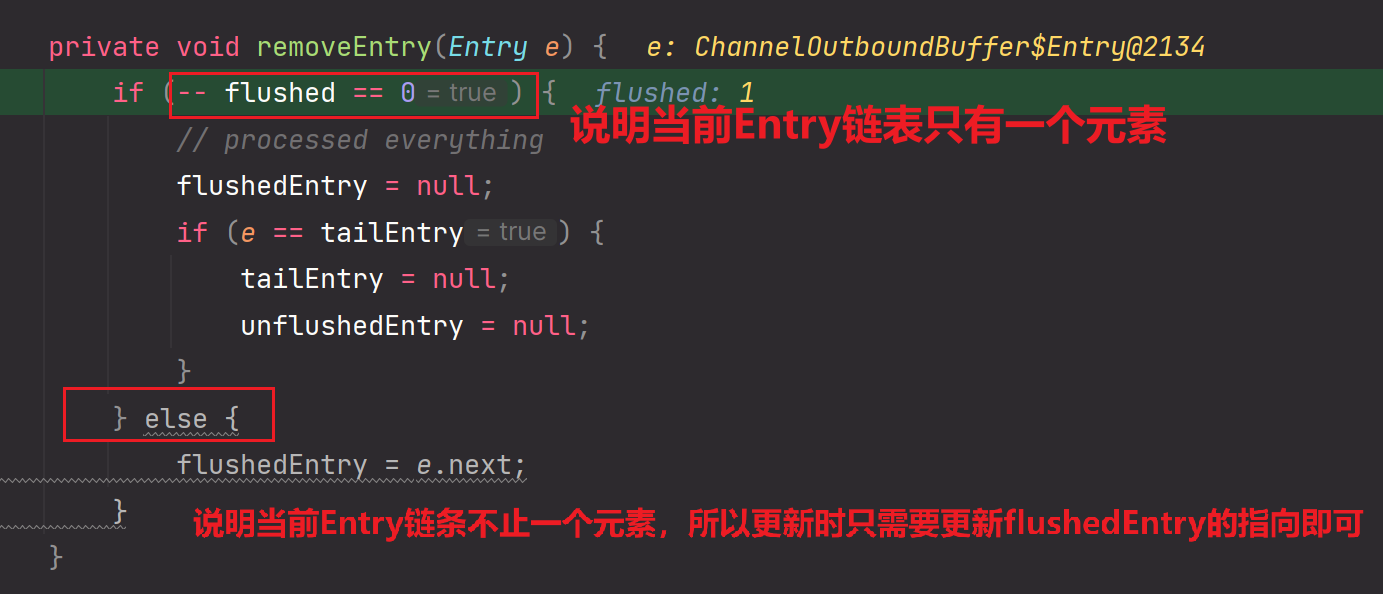
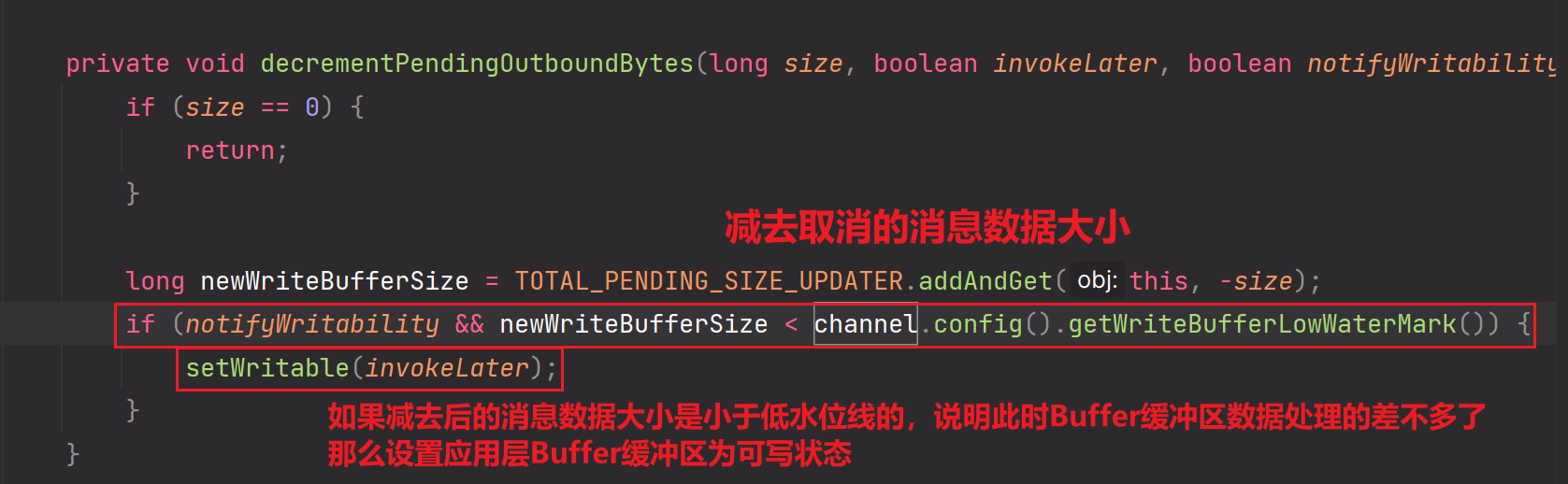
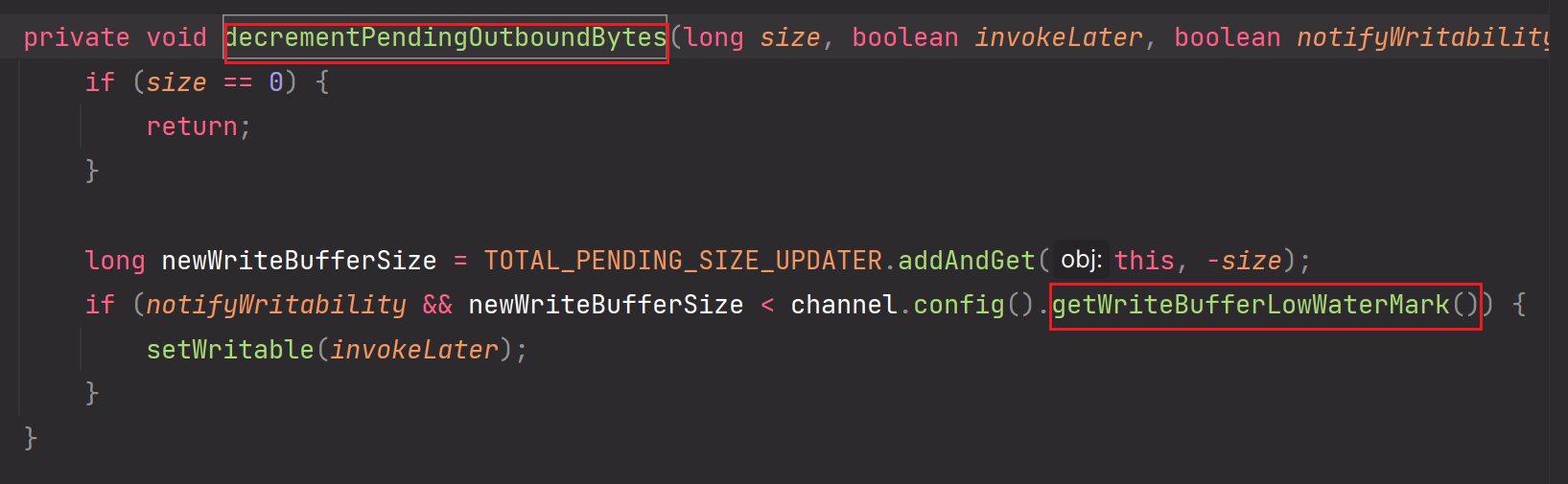
decrementPendingOutboundBytes方法:
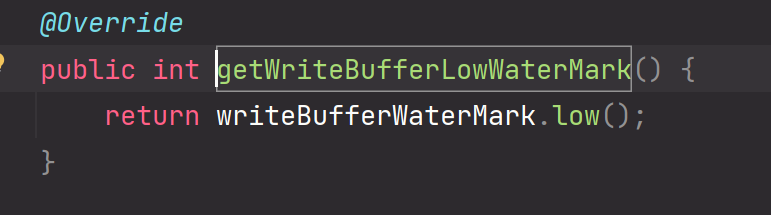
这个方法使用到了低水位线。在把应用层缓冲区的ByteBuffer数据写出到socket内核缓冲区后,这个方法会做累计减的操作,如果当前累计减之后的size大小是小于高低水位线的下限时,那么需要恢复或再一次申明为可写。这个可写是针对:应用程序可以写数据到应用层缓冲区ByteBuffer中。

高低水位线的初始化:

举个例子:



- 总结
write过程:应用程序把数据写出到应用层缓冲区
把一个个msg对象封装成一个个Entry对象,一个个的Entry对象使用链表维护起来。这其实就是存储到应用层缓冲区啦。
flush过程:把应用层缓冲区数据写出到socket内核缓冲区
1.flush方法: 把Entry状态 改成Flush
2.dowrite方法:把一个个Entry对象对应转换成一个个ByteBuffer对象。把ByteBuffer对象数据写出到socket内核缓冲区。