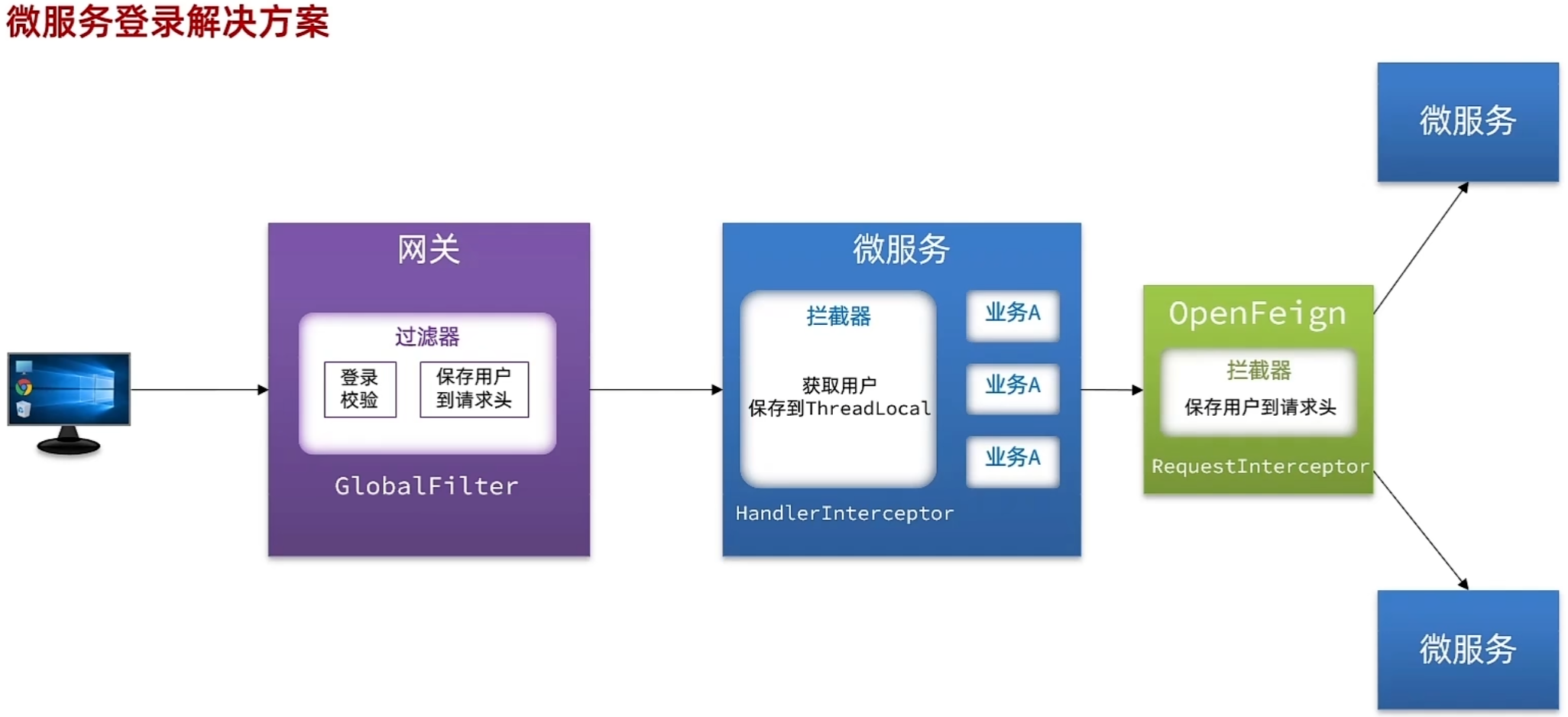
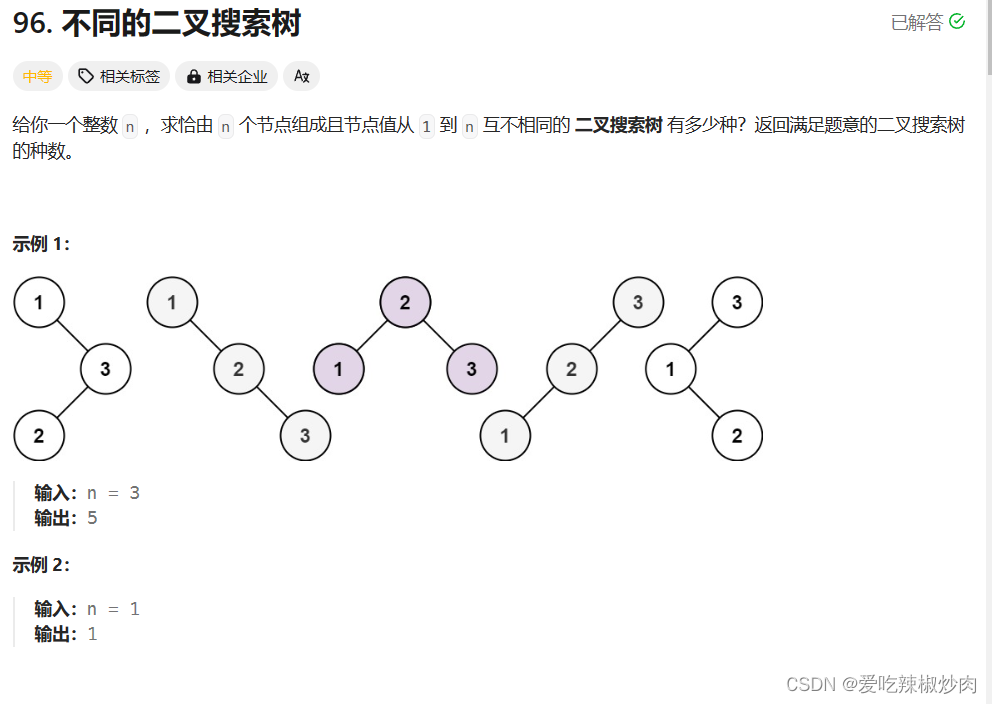
- 基于Feign的声明式远程调用(代码更优雅),用它来去代替我们之前的RestTemplate方式的远程调用
1. Nacos配置管理:Nacos Config
服务配置中心介绍
首先我们来看一下,微服务架构下关于配置文件的一些问题:
- 配置文件相对分散。在一个微服务架构下,配置文件会随着微服务的增多变的越来越多,而且分散在各个微服务中,不好统一配置和管理。
- 配置文件无法区分环境。微服务项目可能会有多个环境,例如:测试环境、预发布环境、生产环境。每一个环境所使用的配置理论上都是不同的,一旦需要修改,就需要我们去各个微服务下手动维护,这比较困难。
- 配置文件无法实时更新。我们修改了配置文件之后,必须重新启动微服务才能使配置生效,这对一个正在运行的项目来说是非常不友好的。
基于上面这些问题,我们就需要"配置中心"的加入来解决这些问题。
配置中心的思路是:
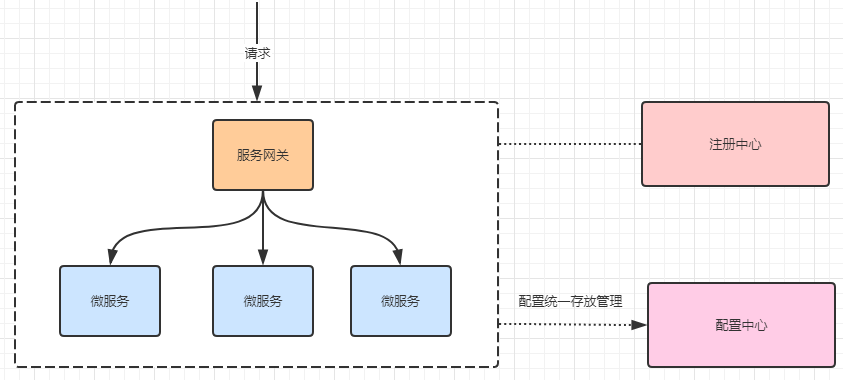
- 首先把项目中各种配置全部都放到一个集中的地方进行统一管理,并提供一套标准的接口;
- 当各个服务需要获取配置的时候,就来配置中心的接口拉取自己的配置;
- 当配置中心中的各种参数有更新的时候,也能通知到各个服务实时的过来同步最新的信息,使之动态更新。
当加入了服务配置中心之后,我们的系统架构图会变成下面这样:
常见的服务配置中心
Apollo
- Apollo是由携程开源的分布式配置中心。特点有很多,比如:配置更新之后可以实时生效,支持灰度发布功能,并且能对所有的配置进行版本管理、操作审计等功能,提供开放平台API。并且资料也写的很详细。
Disconf
- Disconf是由百度开源的分布式配置中心,它是基于Zookeeper来实现配置变更后实时通知和生效的。
Spring Cloud Config
- 这是Spring Cloud中带的配置中心组件,它和Spring是无缝集成,使用起来非常方便,并且它的配置存储支持Git,不过它没有可视化的操作界面,配置的生效也不是实时的,需要重启或去刷新。
Nacos
- 这是Sping Cloud Alibaba技术栈中的一个组件,前面我们已经使用它做过服务注册中心,其实它也集成了服务配置的功能,我们可以直接使用它作为服务配置中心。
Nacos Config 入门
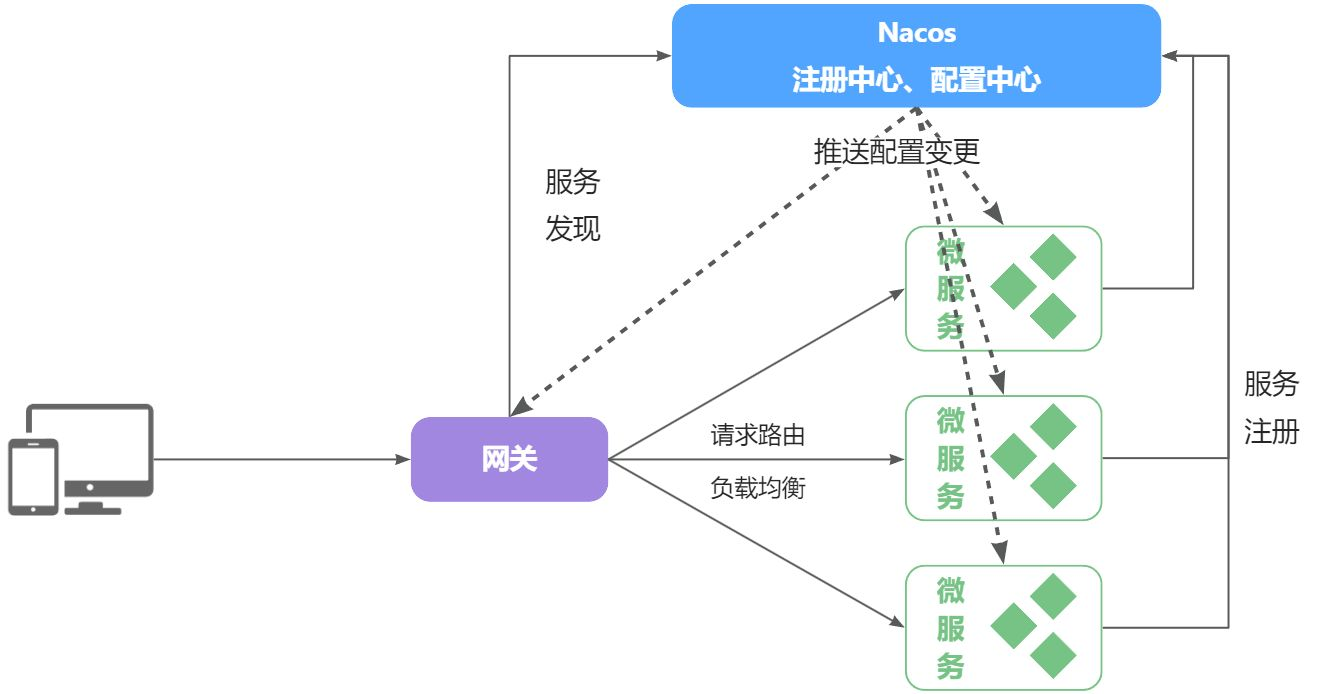
- 使用Nacos作为配置中心,其实就是将Nacos当做一个服务端,将各个微服务看成是客户端,我们将各个微服务的配置文件统一存放在Nacos上,然后各个微服务从Nacos上拉取配置即可。
- Nacos除了可以做注册中心,同样也可以做配置管理来使用。
-
Nacos可以当统一的配置管理器服务。
- 利用Nacos实现统一配置管理以及配置的热更新:解决微服务的配置文件重复和配置热更新问题
1.1 统一配置管理
- 配置的热更新:服务不用重启配置就可以生效。
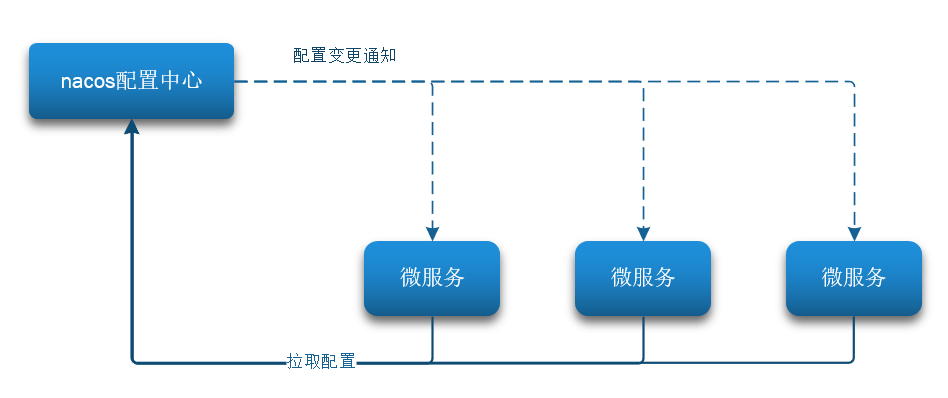
当微服务部署的实例越来越多时,逐个修改微服务配置就会效率低下,而且很容易出错,所以我们需要一种统一配置管理方案,可以集中管理所有实例的配置。
而Naocs除了可以做注册中心,同样也可以做配置管理来使用:
- Nacos一方面可以将配置集中管理,另一方面可以在配置变更时,及时通知微服务,实现配置的热更新。

在nacos中添加配置文件:把配置交给Nacos去实现配置的统一管理
如何在nacos中管理配置呢?
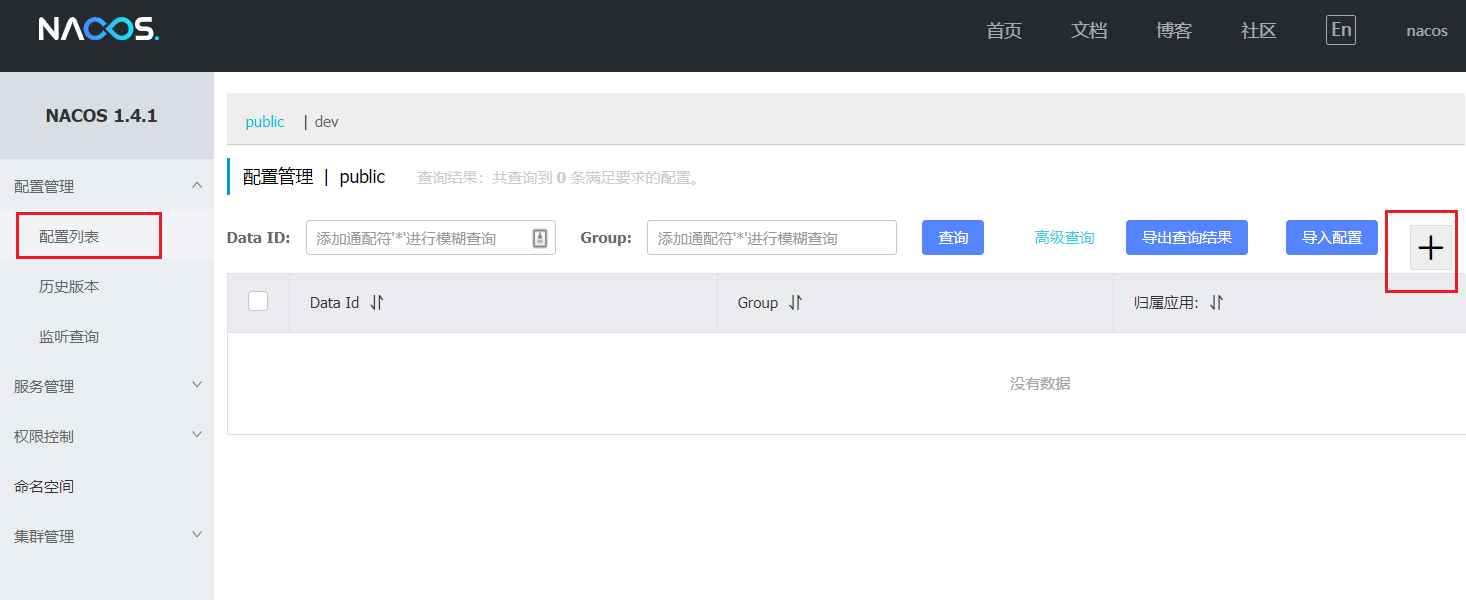 然后在弹出的表单中,填写配置信息:
然后在弹出的表单中,填写配置信息:
 注意:
注意:
- 项目的核心配置,需要热更新的配置才有放到nacos管理的必要,基本不会变更的一些配置还是保存在微服务本地比较好。
从微服务拉取共享配置
微服务要拉取nacos中管理的共享配置,并且将拉取到的共享配置与本地的application.yml配置合并,才能完成项目上下文的初始化,完成项目启动:
- 读取Nacos配置是Spring Cloud上下文(ApplicationContext)初始化时处理的,发生在项目的引导阶段,然后才会初始化SpringBoot上下文,去读取application.yaml。
- 但是Nacos地址是配置在application.yml当中,我们先读取Nacos中的配置文件之前,要先获取Nacos的地址,而在引导阶段,application.yaml文件尚未读取,那如何得知Nacos的地址呢?
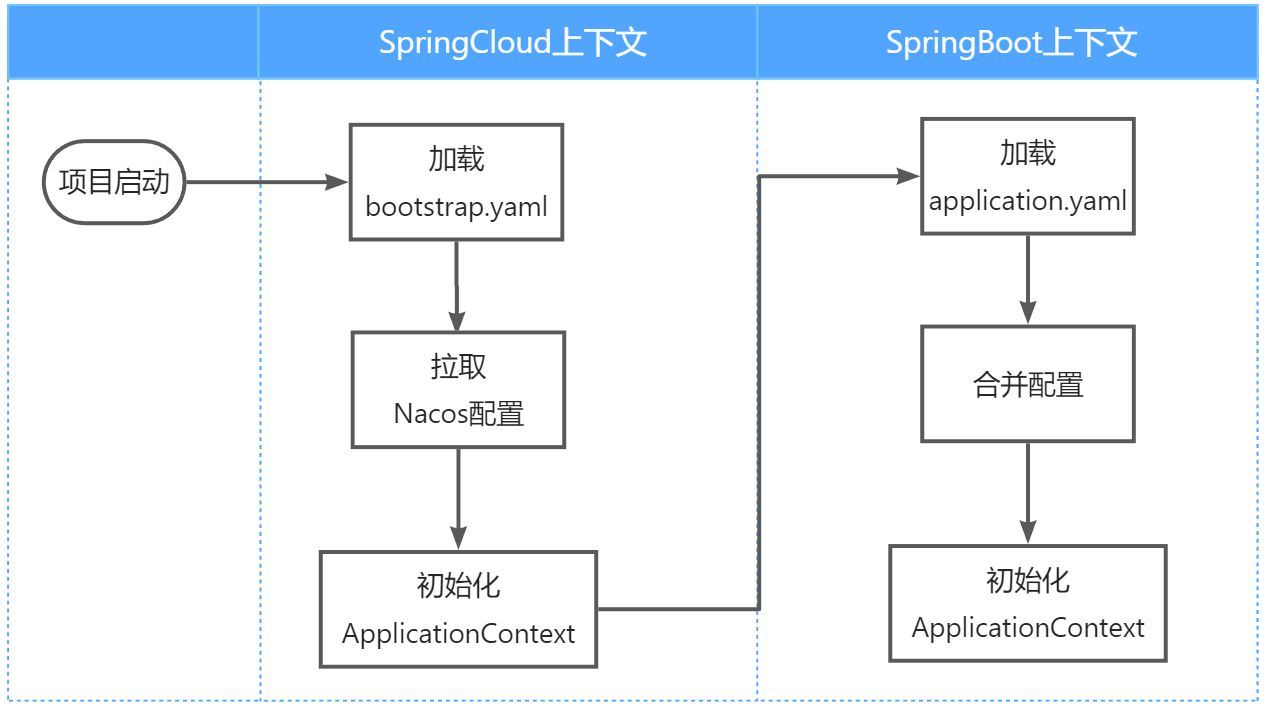
因此Spring引入了一种新的配置文件:bootstrap.yml文件(或者bootstrap.properties的文件),会在application.yml之前被读取,如果我们将Nacos地址配置到bootstrap.yaml中,那么在项目引导阶段就可以读取Nacos中的配置了,流程如下:
- bootstrap.yml的配置文件的优先级会比application.yml配置文件的优先级要高很多。
- 与Nacos地址和配置文件相关的所有信息都应该放在bootstrap.yml当中。
 1. 引入nacos-config依赖:引入Nacos的配置管理依赖
1. 引入nacos-config依赖:引入Nacos的配置管理依赖
- 在服务消费者中的pom.xml中引入依赖
<!--nacos配置管理依赖-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>2. 在resource目录中添加一个bootstrap.yml文件,这个文件是引导文件,它的优先级高于 application.yml
配的就是Data ID:
spring:application:name: userservice # 配置服务名称profiles:active: dev #开发环境,这里是dev cloud:nacos:server-addr: localhost:8848 # 配置Nacos地址config:file-extension: yaml # 文件后缀名
3. 读取nacos配置
在user-service中的UserController中添加业务逻辑,读取pattern.dateformat配置:



1.2 配置热更新 - 配置动态刷新
- 所谓的动态刷新:项目运行中,手动改了Nacos中的配置,项目在不停机的情况下也可以读到最新的数据。
- 我们最终的目的,是修改nacos中的配置后,微服务无需重启即可让配置生效,也就是配置热更新。
要实现配置热更新,可以使用两种方式:需要通过下面两种配置实现
方式一:在@Value注入的变量所在类上添加注解@RefreshScope

方式二:使用@ConfigurationProperties注解代替@Value注解
- 需要自定义配置类

1.3 多环境配置共享
当nacos、服务本地同时出现相同属性时,多种配置的优先级有高低之分:
- 本地配置的优先级是最低的,而线上配置也就是Nacos中的配置是更高一点儿的。
- 当前环境的配置肯定要比多环境共享配置的优先级更高。


1.4 搭建Nacos集群
- 注意:Nacos生产环境下一定要部署为集群状态~!
- SLB指的是负载均衡器
2. OpenFeign远程调用
- http客户端Feign
RestTemplate方式调用存在的问题:

- 代码可读性差,编程体验不统一
- 遇到参数复杂的URL难以维护
Feign的介绍
- Feign是一个伪声明式的HTTP客户端,官方地址:GitHub - OpenFeign/feign: Feign makes writing java http clients easier
其作用就是帮助我们优雅的实现HTTP请求的发送~!
OpenFeign的介绍
OpenFeign是一个声明式的HTTP客户端,是Spring Cloud在Eureka公司开源的Feign基础上改造而来,官方地址:https://github.com/OpenFeign/feign
其作用就是基于SpringMVC的常见注解,帮我们优雅的实现http请求的发送~!

OpenFeign快速入门
OpenFeign已经被Spring Cloud自动装配,实现起来非常简答:
- 引入依赖,包括OpenFeign和负载均衡组件Spring Cloud Load Balancer
<!--OpenFeign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!--负载均衡器--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency>旧版本中用的才是Ribbon,新版本中用的都是loadbalancer。
联想补充:Spring Cloud怎么实现服务的负载均衡?
- Spring Cloud 2020.0.0之前的版本使用的是spring-cloud-netflix-ribbon,一开始都是使用Ribbon作为负载均衡组件的,不过现在的Spring Cloud 2020.0.0 及后续新版本已经弃用Ribbon了,而是使用Spring Cloud Load Balancer模块作为负载均衡组件,用来替代Ribbon,不过这个也不是独立的模块,而是spring-cloud-commons中的一个子模块。
Spring Cloud LoadBalancer支持哪些负载均衡策略?
Spring Cloud LoadBalancer提供了自己负载均衡的抽象接口ReactiveLoadBalancer,并且提供了两种策略实现:
- RoundRobinLoadBalancer(轮循)
- RandomLoadBalancer(随机)
目前相比Ribbon来说负载均衡策略还是比较简单的。

2. 在启动类通过添加@EnableFeignClients注解,启用OpenFeign功能

编写OpenFeign客户端
在cart-service中,定义一个新的接口,编写Feign客户端:
其中代码如下:
package com.hmall.cart.client;import com.hmall.cart.domain.dto.ItemDTO;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;import java.util.List;@FeignClient("item-service")
public interface ItemClient {@GetMapping("/items")List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}这里只需要声明接口,无需实现方法。接口中的几个关键信息:


使用FeignClient
- feign替我们完成了服务拉取、负载均衡、发送http请求的所有工作,而且,这里我们不再需要RestTemplate了,还省去了RestTemplate的注册。

OpenFeign连接池
Feign底层发起http请求,依赖于其它的框架。其底层支持的http客户端实现包括:
-
HttpURLConnection:默认实现,不支持连接池 => 每一次都需要重新创建连接,因此效率极低
-
Apache HttpClient :支持连接池
-
OKHttp:支持连接池
因此我们通常会使用带有连接池的客户端来代替默认的HttpURLConnection。比如,我们使用OK Http:
引入依赖:
<!--OK http 的依赖 -->
<dependency><groupId>io.github.openfeign</groupId><artifactId>feign-okhttp</artifactId>
</dependency>开启连接池:
在application.yml配置文件中开启Feign的连接池功能
feign:okhttp:enabled: true # 开启OKHttp功能重启服务,连接池就生效了。
所谓最近实践,就是使用过程中总结的经验,最好的一种使用方式。
日志配置
OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
-
NONE:不记录任何日志信息,这是默认值。
-
BASIC(推荐):仅记录请求的方法,URL以及响应状态码和执行时间
-
HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
-
FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。
要自定义日志级别需要声明一个类型为Logger.Level的Bean,在其中定义日志级别:
-
也可以基于Java代码来修改日志级别,先声明一个类,然后声明一个Logger.Level的对象
public class DefaultFeignConfiguration {@Beanpublic Logger.Level feignLogLevel(){return Logger.Level.BASIC; // 日志级别为BASIC}
}如果要全局生效,将其放到启动类的@EnableFeignClients这个注解中:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class) 如果是局部生效,则把它放到对应的@FeignClient这个注解中:
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class) 3. Getway服务网关
- 统一网关Getway
由于每个微服务都有不同的地址或端口,入口不同,在与前端做联调时会发现:
- 请求不同数据时要访问不同的入口,需要维护多个入口地址,麻烦
- 前端无法调用Nacos,无法实时更新服务列表
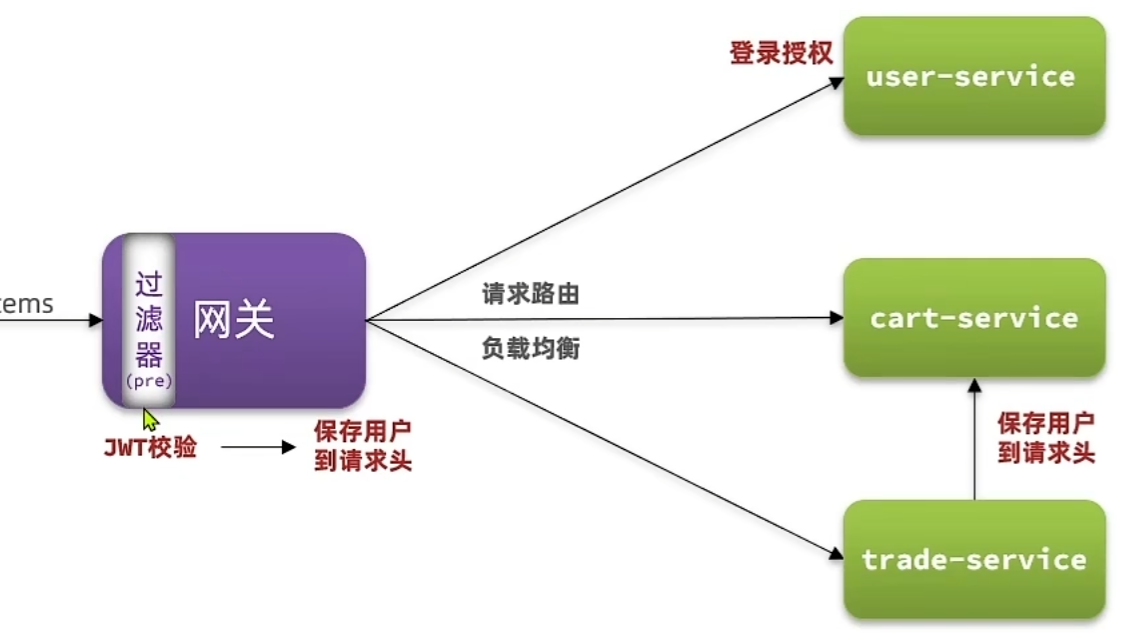
单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息,而微服务拆分后,每个微服务都独立部署,这就存在一些问题:
- 如果没有网关做校验,微服务直接摆在那里,允许任何人都可以来请求访问,这是不安全的
- 如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去调用,这样无疑增加了代码编写的复杂性
- 服务地址过多,而且将来可能变化,前端不知道该请求谁?
- 认证复杂,每个服务都需要独立认证:每个服务都可能需要登录用户信息,难道每个微服务都需要编写JWT登录校验、用户信息获取的功能吗?
- 当微服务之间调用时,该如何传递用户信息?
可以通过API网关技术来解决上述问题。
网关概述
网关的核心功能特性
网关就是网络的关口,是指系统的统一入口,它封装了应用程序的内部结构,为客户端提供统一服务,一些与业务本身功能无关的公共逻辑可以在这里实现,负责前端请求的路由 => 服务路由(告诉你在几楼几号这叫做路由)、转发(你找不着带你过去这叫做转发)以及用户登录时的身份校验(身份认证和权限校验,做过滤拦截)(检查你户口本)。
数据在网络间传输,从一个网络传输到另一网络时就需要经过网关来做数据的路由和转发以及数据安全的校验。
网关的作用:
网关是所有微服务的统一入口
- 对用户请求做身份认证、权限校验
- 将用户请求路由到微服务,并实现负载均衡
- 对用户请求做限流

- 网关路由:解决前端请求入口的问题
- 网关鉴权:解决统一登录校验和用户信息获取的问题
更通俗的来讲,网关就像是以前园区传达室的大爷。
-
外面的人要想进入园区,必须经过大爷的认可,如果你是不怀好意的人,肯定被直接拦截。
-
外面的人要传话或送信,要找大爷。大爷帮你带给目标人。
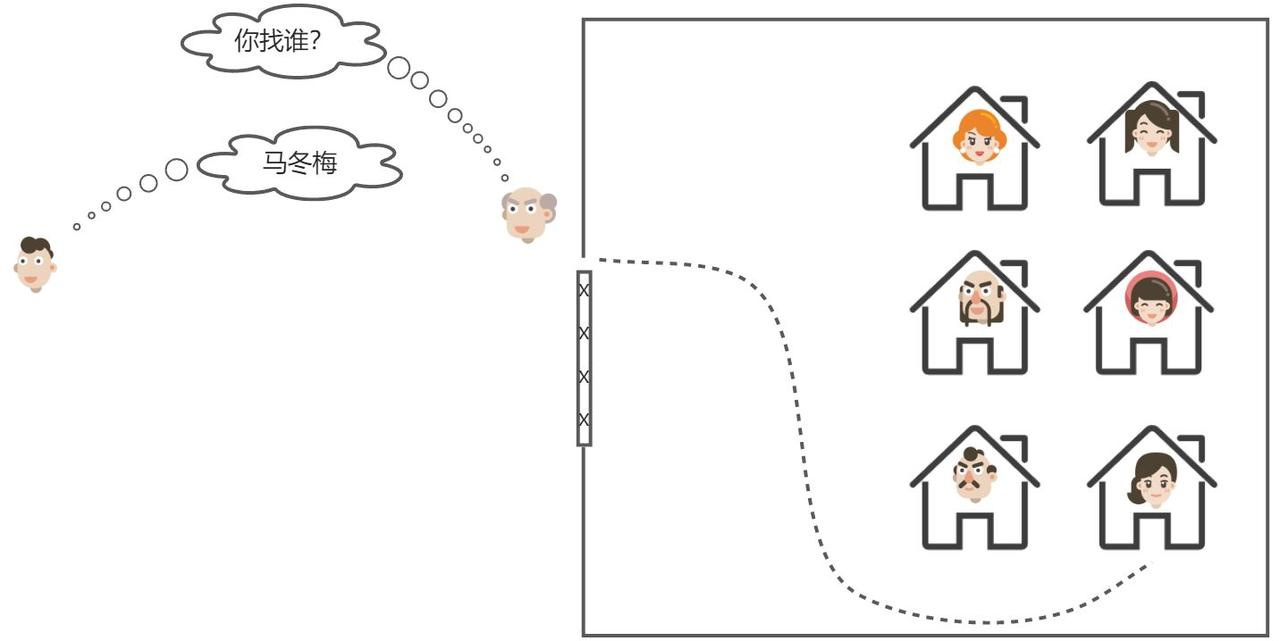
现在,服务网关就起到同样的作用,前端请求不能直接访问微服务,而是要请求网关:
- 网关可以做安全控制,也就是做登录身份校验,网关作为微服务入口,需要校验用户是否有请求资格(比如是否登录),校验通过才放行(接着解析JWT令牌),如果校验不通过则需要进行拦截
- 一切请丢都必须先经过网关,但网关不处理业务,通过网关认证后,网关再根据前端的请求判断应该访问哪个微服务,这个判断的过程就是请求路由,然后再将请求转发过去,转发到具体的微服务,当路由的目标服务有多个时,还需要做负载均衡
- 网关它也是一个微服务,网关也是需要将自己的信息注册到注册中心上,并且网关会去注册中心去拉取所有的服务地址
- 有了网关以后,我们微服务的地址再也不需要暴露给前端了,要暴露给前端的仅仅是网关地址,这对于微服务来讲也是一种保护,而且,对前端来讲,由于它只知道网关地址,因此整个微服务对它来讲是隐藏的,是一个黑盒的,也就是说在前端看来,后端跟原来的单体架构其实是没什么区别的,这样它的开发体验也是一致的
- 一切请求,一定要先到网关(前端直接请求网关),即可再到微服务~!
- 限流:当请求流量过高时,在网关中按照下游的微服务能够接受的速度来放行请求,避免服务压力过大
- 限流是保护服务器,避免因请求过多而导致服务器过载甚至宕机。
如果微服务有做集群,网关还要进行负载均衡:

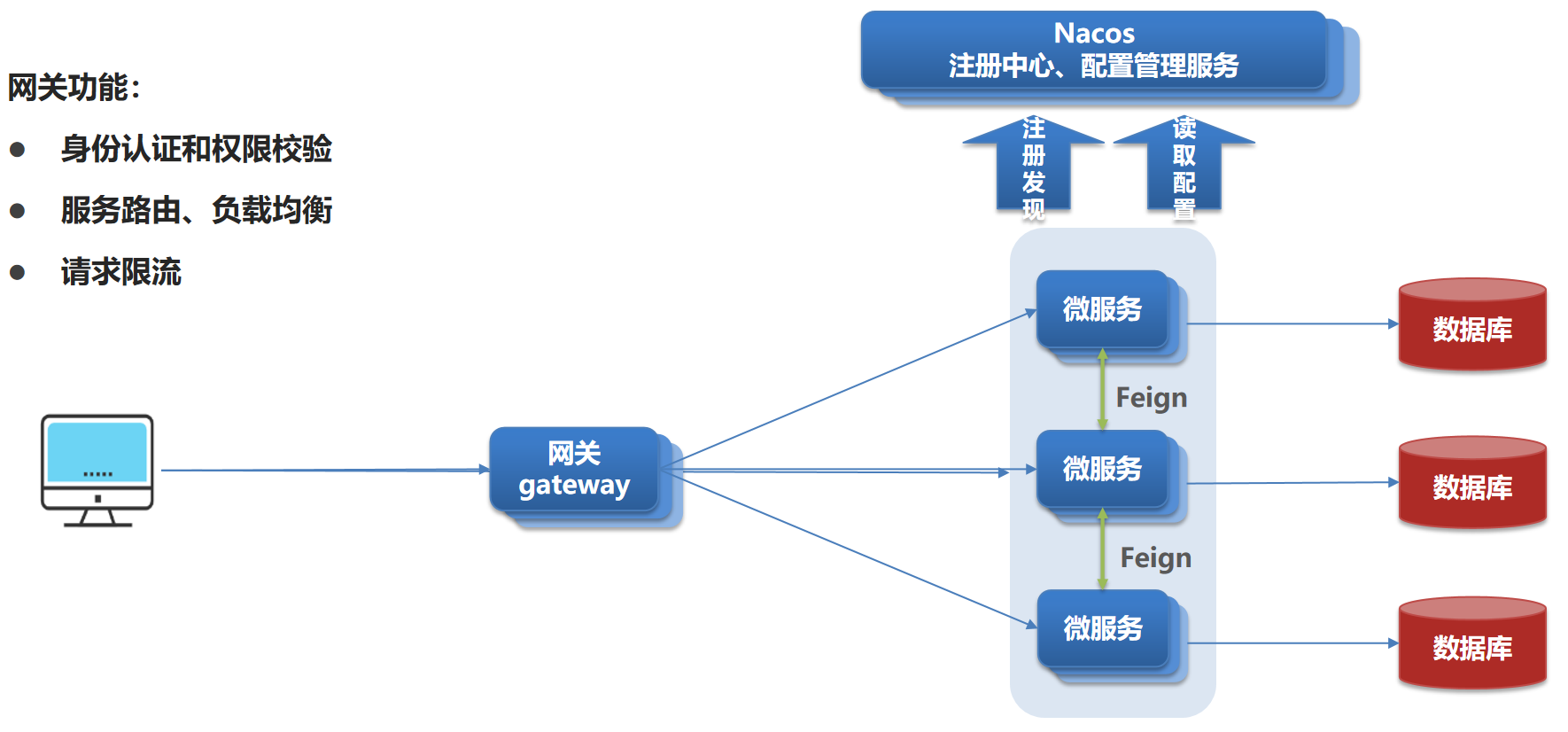
在Spring Cloud当中,提供了两种网关的实现方案:
- Netfilx Zuul:它是Netflix出品,基于Servlet的阻塞式编程,早期实现,目前已经淘汰,需要调优才能获得与Spring Cloud Getway类似的性能
- Spring Cloud Getway:Spring官方出品,基于Spring 5 中提供的的WebFlux技术,完全支持响应式编程,属于响应式编程的体现 => 基于WebFlux的响应式编程,吞吐能力更强,具备更好的性能,无需调优即可获得优异性能,它的目标是替代Netflix Zuul,它不仅提供统一的路由方式,并且基于Filter过滤器链的方式提供了网关的基本功能,比如:安全、监控和限流。
注意:
- Spring Cloud Alibaba技术栈中并没有提供自己的网关,我们可以采用Spring Cloud Getway来做网关。
Getway快速入门

利用网关实现请求路由
- 网关是一个独立服务~!
搭建网关服务
- 创建新的Module,创建Spring Boot工程Getway,引入Spring Cloud Getway的起步依赖和Nacos的服务发现依赖
<!--网关Getway依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><!--nacos的服务发现依赖--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--负载均衡--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency><!-- Spring Boot的编译打包插件--><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>2. 编写启动类SpringBootApplication

3. 编写基础配置和路由规则(配置路由规则:spring cloud getway routes)
- id是路由的唯一标识,每一个路由规则都应该有自己的ID,确保它唯一不重复。
server:port: 10010 # 网关端口
spring:application:name: gateway # 服务名称cloud:nacos:server-addr: localhost:8848 # nacos地址gateway:routes: # 网关路由配置- id: user-service # 路由规则id,自定义(一般情况下与微服务名称保持一致),只要唯一即可# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址(不推荐)uri: lb://userservice # 路由的目标地址(路由目标微服务) lb就是负载均衡,后面跟服务名称predicates: # 路由断言,判断请求是否符合规则,符合规则才路由到目标也就是判断请求是否符合路由规则的条件- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
4. 启动网关服务进行测试
路由属性总结
网关路由对应的Java类是RouteDefinition,其中常见的属性,即可以配置的内容包括:
- 路由id:路由的唯一标识
- 路由目标(uri):路由的目标地址(路由目的地),支持lb和http两种:http代表固定地址,lb代表根据服务名负载均衡
- 路由断言(predicates):判断请求是否符合路由的规则,判断请求是否符合要求,符合则转发到路由目的地
- 路由过滤器(filters):对请求或响应做特殊处理
路由断言工厂 - Route Predicate Factory
读取并解析用户配置定义的断言规则
- 我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件

例如Path=/user/**是按照路径匹配,这个规则是由
"org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory"类来处理的
Spring提供了12种基本的RoutePredicateFactory实现:
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围(对IP地址做限制) | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 |
我们只需要掌握Path这种路由工程就可以了。
网关实现用户的登录校验
- 单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息,而微服务拆分后,每个微服务都独立部署,不再共享数据,总不能每个微服务都需要做登录校验,这显然不可取。
鉴权思路分析
- 我们的登录是基于JWT来实现的,校验JWT的算法复杂,而且需要用到密钥,如果每个微服务都去做登录校验,这就会存在两大问题:
- 每个微服务都需要知道JWT的密钥,不安全
- 每个微服务重复编写登录校验代码、权限校验代码,麻烦
既然网关是所有微服务的入口,一切请求都需要先经过网关,我们完全可以把登录校验的工作放到网关去做,这样之前说的问题就都解决了:
- 只需要在网关和用户服务保存密钥
- 只需要在网关开发登录校验的功能
此时,登录校验的流程图:(将用户信息向后传递)


不过,这里存在几个问题:
- JWT校验它一定要在网关将请求转发到微服务之前去做,但是请求转发是Getway网关内部代码来做,那我们如何在网关转发之前去做登录校验?
- 网关校验JWT之后,如何将用户信息传递给下游的微服务?
- 微服务之间也会相互调用,这种调用不经过网关,又该如何传递用户信息?
网关过滤器
- 过滤器就是在请求的传递过程中,对请求和响应做一些手脚。
Filter的生命周期一般只有两个:Pre和Post:
- Pre:在请求被路由之前调用,我们可以利用它实现身份验证、在集群中选择请求的微服务等;
- Post:在路由到微服务响应返回后执行,可以利用它将响应从微服务发送给客户端等。
Getway网关内部源码分析 - 网关请求处理流程
- 登录校验必须在网关请求转达到微服务之前去做,否则就失去了意义,而网关的请求转发是Gateway内部代码实现的,要想在请求转发之前做登录校验,就必须了解Gateway内部工作的基本原理。
- 我们知道,网关的底层是没有业务逻辑的,它要做的事情就是基于我们配置的路由规则来去判断前端请求到底应该由哪个微服务来进行处理,然后将请求转发到对应的微服务,而这里对路由规则的判断就是由HandlerMapping的接口来进行处理的,HandlerMapping的默认实现是RoutePredicateHandlerMapping(基于路由断言去做路由规则的匹配)。
- HandlerMapping就是来做路由匹配的,匹配完了以后就交给下一个接口去处理了,这就是责任链模式。
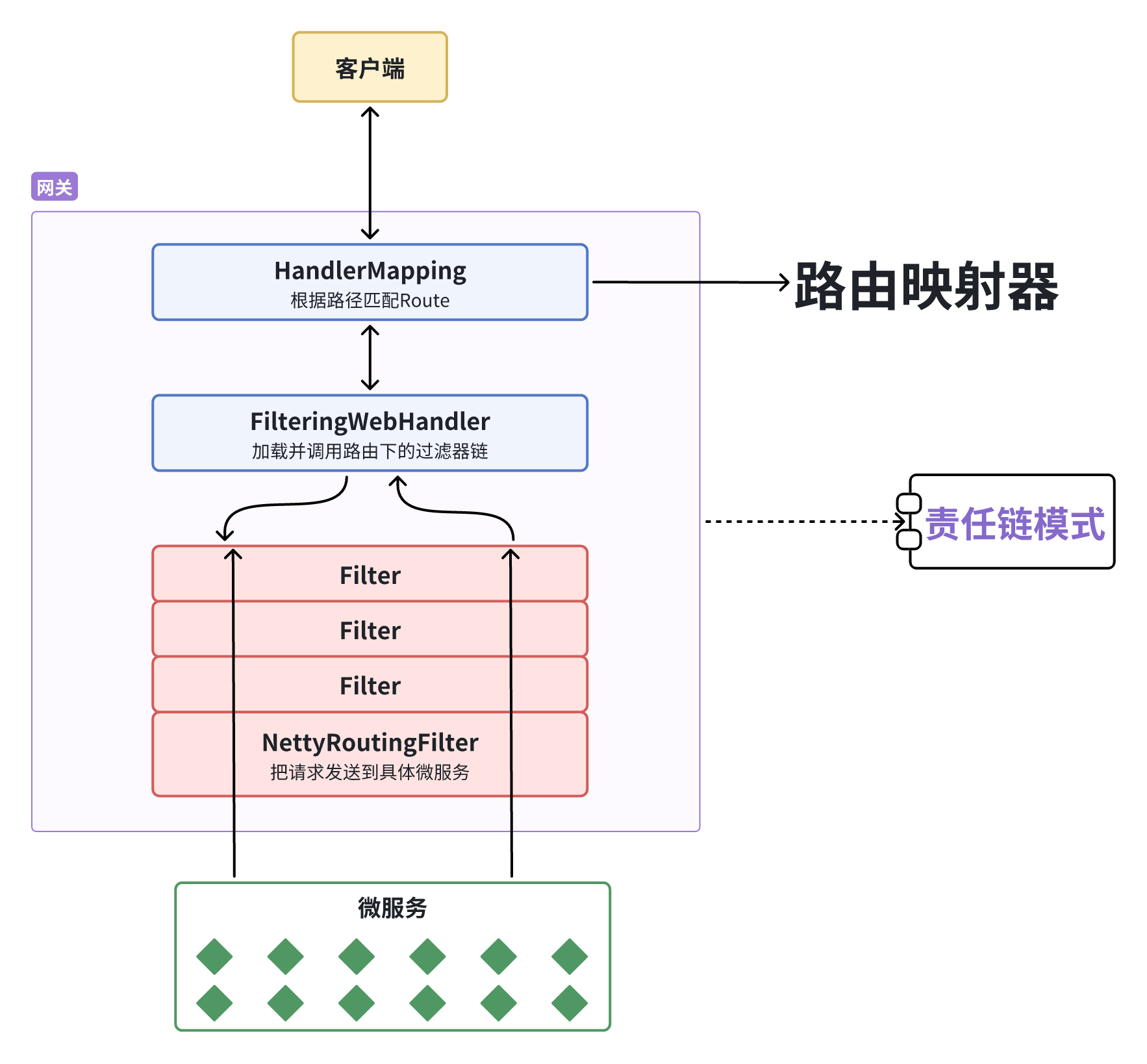
如图所示:
-
客户端请求进入网关后由HandlerMapping对请求做判断,HandlerMapping找到与当前请求匹配的路由规则(
Route)并存入上下文,然后将请求交给请求处理器WebHandler去处理。 -
WebHandler则会加载网关中配置生效的多个过滤器,加载当前路由下需要执行的过滤器链(Filter Chain),放入到集合并排序,形成过滤器链,然后按照顺序逐一执行这些过滤器(后面称为Filter)。
-
图中Filter被虚线分为左右两部分,是因为Filter内部的逻辑分为pre和post两部分,分别会在请求路由到微服务之前和之后被执行 => pre顺序执行,post倒序执行。
-
只有在所有Filter的pre逻辑都依次顺序执行通过后,请求才会被路由到微服务(如果过滤器的pre逻辑执行失败,则会直接结束,不会再往下去执行了)。
-
微服务返回结果后,再倒序执行Filter的post逻辑。
-
最终把响应结果返回。
过滤器链当中的一个特殊过滤器:
- NettyRoutingFilter:该过滤器不用做配置,默认对所有路由都生效的过滤器,而且该过滤器的执行顺序恰好就是在整个过滤器链的最后,而它的作用就是将请求转发到微服务,当微服务返回结果后去做封装,然后保存上下文接着又依次返回给其它过滤器,最终返回给用户。

上图我们得知:最终请求转发是由一个名为NettyRoutingFilter的过滤器来执行的,而且这个过滤器是整个过滤器链中顺序最靠后的一个,而我们需要在请求转发之前去做用户的身份校验,如果能够定义一个过滤器,在其中实现登录校验逻辑,并且将过滤器的执行顺序定义到NettyRoutingFilter之前,这就符合我们的需求了!
这个登录校验的逻辑是应该放在pre阶段还是post阶段呢?
- 显然应该放在pre阶段,如果放在post阶段,那么请求都已经转发到微服务并且都已经执行完了,这个时候你再去校验,还有什么意义呢?
- 而如果我放在pre阶段,请求来了以后,先执行我的登录校验,如果不通过,则直接抛个异常结束即可,这样就不会向下执行,自然也就不会去转发了,所以,肯定放在pre阶段。
不过此时还有第二个问题,就是网关内部是不处理业务逻辑的,网关校验JWT完成以后,得到了用户信息,但是最终我们的微服务才是处理业务的,因此网关需要把用户信息传递给下游的微服务,网关该如何将用户信息传递给下游的微服务呢?
- 这简单,我们以前传递用户信息都用ThreadLocal。。。。注意:这不可行!网关也是一个独立的微服务,它们都部署在不同的Tomcat上,而ThreadLocal它是在Tomcat内部,在线程之间去做共享,而现在都是不同的Tomcat了,肯定不能用ThreadLocal去实现共享了,这种方案显然不行。
- 网关到微服务,其实是一次新的HTTP请求,要通过HTTP请求去传递信息,最佳的传递方案肯定是通过请求头来传递,因为放在请求头里面是不会对业务产生影响的,把用户信息保存到请求头,网关在发请求到微服务,微服务再从请求头当中取出用户信息。
微服务之间也会相互调用,这种调用不经过网关,又该如何传递用户信息?
- 都是HTTP请求,那我此时是不是也可以把用户信息保存到请求头呢?
- 但是,微服务之间的HTTP请求它是基于OpenFeign去发起的,而网关则是它内置的一种HTTP的请求方式去发起的,所以虽然都是通过请求头去传递,但是它们在实现方式上还是有差别的。
如何自定义网关过滤器?
该如何实现一个网关过滤器呢?
网关过滤器链中的过滤器有两种,分别是:
- GetwayFilter:路由过滤器(局部路由过滤器 & 全局路由过滤器),作用范围比较灵活,可以作用于任意指定的路由Route;默认不生效,要配置到路由后生效。
- GlobalFilter:全局过滤器,作用范围是所有路由,声明后自动生效,不可配置。
注意:
- 过滤器链之外还有一种过滤器,HttpHeadersFilter,用来处理传递到下游微服务的请求头。例如org.springframework.cloud.gateway.filter.headers.XForwardedHeadersFilter可以传递代理请求原本的host头到下游微服务。
这两种过滤器的方法签名完全一致:
- filter()方法就是编写过滤逻辑的核心方法了。
- 如果自定义GatewayFilter是比较麻烦的,在日常开发过程中,我们大多数时候都会选择自定义GlobalFilter~!
- 自定义GatewayFilter不是直接实现GatewayFilter,而是实现AbstractGatewayFilterFactory,并且自定义该类的名称还一定要以GatewayFilterFactory为后缀。。。。。(太麻烦了,暂时先不去学习)
/*** 处理请求并将其传递给下一个过滤器* @param exchange 当前请求的上下文,其中包含request、response等各种数据* @param chain 过滤器链,基于它向下传递请求* @return 根据返回值标记当前请求是否被完成或拦截,chain.filter(exchange)就放行了。*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);Mono是一个回调函数,回调函数里面的逻辑就是post里面的逻辑了,在实际开发中基本上不会写post。
看看NettyRountingFilter的源码的优先级:
- Ordered接口的作用就是来做排序的,它是springframework.core核心包下:

- getOrder()方法的返回值越小,代表优先级就越高 => 源码当中的优先级代表最低优先级。


需求:在网关中基于过滤器实现登录校验功能
JWT工具
- 登录校验需要用到JWT,而且JWT的加密需要密钥和加密工具。

- request.getHeaders().get():请求头是允许一个头对应多个值的,所以返回值类型是一个List。

网关校验JWT之后,如何将用户信息传递给下游的微服务?
网关完成JWT登录校验后获取到登录用户的身份信息之后,网关还需要将请求转发到下游的微服务,微服务又该如何获取用户身份呢?
实现登录用户信息的传递思路:
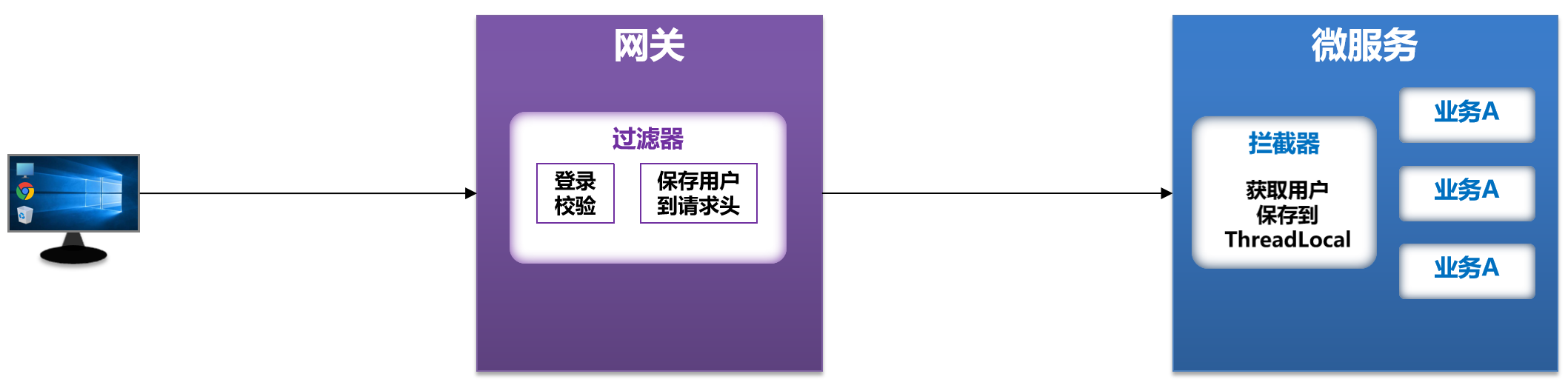
- 因为最终处理业务的是微服务,而不是网关。
- 网关发送请求到微服务依然采用的HTTP请求,并且网关到微服务是一次新的HTTP请求,因此我们可以将用户信息以请求头的方式传递到下游微服务,然后微服务可以从请求头中获取登录用户的信息然后来实现自己的业务逻辑了,但是微服务内部可能很多地方都需要用到登录用户的信息,我们总不可能把获取请求头中的用户信息的逻辑在每个业务当中都写一遍,这显然不合适,我们知道微服务的业务接口都是基于Spring MVC去实现的,那现在我们不想在每一个业务接口里都去获取登录用户,而想直接用,我们应该在所有业务接口执行之前去做获取用户信息这件事,而Spring MVC当中的拦截器可以在所有的Controller接口执行之前去执行,因此我们可以利用Spring MVC的拦截器去获取请求头中的用户信息来实现登录用户信息获取,并将其保存到或存入ThreadLocal当中,这样在后续的业务执行过程中可以随时去从ThreadLocal里取出用户的登录信息,就不用在每个业务里都去写了。

因此,接下来我们要做两件事情:
- 改造网关过滤器,在获取用户信息后保存到请求头,转发到下游微服务
- 自定义微服务拦截器,拦截请求获取用户信息,保存到ThreadLcoal后放行
步骤一:在网关的登录校验过滤器中,把获取到的用户信息保存写入到下游请求的请求头中。
需要用到ServerWebExchange类提供的API,示例如下:
exchange.mutate() // mutate就是对下游请求做更改 添加请求头的名字和请求头的值 .request(builder -> builder.header("user-info", userInfo)).build(); // 返回新的exchange
第二步:定义一个common模块编写Spring MVC拦截器,获取登录用户信息
需求:
- 由于每个微服务都可能有获取登录用户信息的需求,因此我们直接在common模块定义拦截器,这样微服务只需要引入依赖即可生效,无需重复编写。
提示:获取到用户信息后需要保存到ThreadLocal,对应的工具类在common中已经定义好了:
package com.hmall.common.interceptor;import cn.hutool.core.util.StrUtil;
import com.hmall.common.utils.UserContext;
import org.springframework.web.servlet.HandlerInterceptor;import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;/*** 自定义Spring MVC拦截器*/
public class UserInfoInterceptor implements HandlerInterceptor {/*** 该方法是在Controller之前执行*/@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {// 1.获取请求头中的用户信息(请求头里只能存字符串,所以返回值类型为String)String userInfo = request.getHeader("user-info");// 2.判断是否为空if (StrUtil.isNotBlank(userInfo)) {// 不为空,保存到ThreadLocalUserContext.setUser(Long.valueOf(userInfo));}// 3.放行return true;}@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {// 业务执行完成后完成用户的清理:移除用户UserContext.removeUser();}
}Spring MVC的拦截器要想生效,还需要编写Spring MVC的配置类:
package com.hmall.common.config;import com.hmall.common.interceptor.UserInfoInterceptor;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;@ConditionalOnClass(DispatcherServlet.class) // 仅对Spring MVC生效
@Configuration
public class MvcConfig implements WebMvcConfigurer {@Overridepublic void addInterceptors(InterceptorRegistry registry) {// 拦截器注册器registry.addInterceptor(new UserInfoInterceptor());}
}不过,需要注意的是,这个配置类默认是不会生效的,因为它所在的包是com.hmall.common.config,与其它微服务的扫描包不一致,无法被扫描到,因此无法生效。
基于SpringBoot的自动装配原理,我们要将其添加到resources目录下的META-INF/spring.factories文件中:
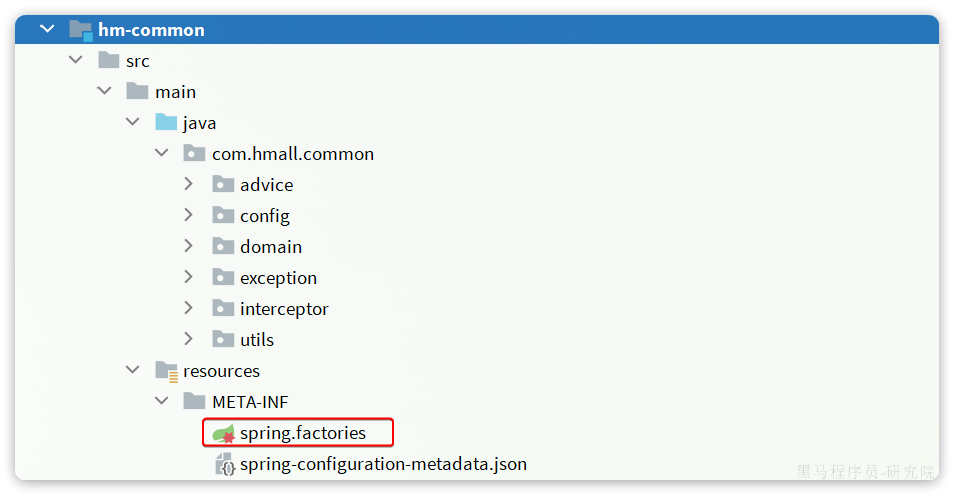
将配置类的全类名添加到该文件即可。
微服务之间也会相互调用,这种调用不经过网关,又该如何传递用户信息?
使用OpenFeign在服务之间传递用户信息
前端发起的请求都会经过网关再到微服务,由于我们之前编写的过滤器和拦截器功能,微服务可以轻松获取登录用户的信息。
但是有些业务是比较复杂的,请求到达微服务后还需要调用其它多个微服务(业务链比较长),而这个过程中也需要传递登录用户的信息,比如下单业务,流程如下:

下单的过程中,需要调用商品服务扣减库存,调用购物车服务清理用户购物车。而清理购物车时必须知道当前登录的用户身份。但是,订单服务调用购物车时并没有传递用户信息,购物车服务无法知道当前用户是谁!
由于微服务获取用户信息是通过拦截器在请求头中读取,因此要想实现微服务之间的用户信息传递,就必须在微服务发起调用时把用户信息存入请求头。
微服务之前调用是基于OpenFeign来实现的,并不是我们自己发送的请求,我们如何才能让每一个由OpenFeign发起的请求自动携带登录用户信息呢?
- 这里就需要借助OpenFeign中提供的一个拦截器接口:feign.RequestInterceptor,所有由OpenFeign发起的请求都会先调用拦截器处理请求!
public interface RequestInterceptor {/*** Called for every request. * Add data using methods on the supplied {@link RequestTemplate}.*/void apply(RequestTemplate template);
}
我们只需要实现这个接口,然后调用apply()方法,利用RequestTemplate类来添加请求头,将用户信息保存到请求头中,这样一来,每次OpenFeign发起请求的时候都会调用该方法,传递用户信息。
其中的RequestTemplate类中提供了一些方法可以让我们修改请求头:
@Bean
public RequestInterceptor userInfoRequestInterceptor(){return new RequestInterceptor() {@Overridepublic void apply(RequestTemplate template) {// 获取登录用户Long userId = UserContext.getUser();if(userId == null) { // 防止NPE// 如果为空则直接跳过return;}// 如果不为空则放入请求头中,传递给下游微服务template.header("user-info", userId.toString());}};
}好了,现在微服务之间通过OpenFeign调用时也会传递登录用户信息了。
总结
-
微服务远程调用
-
微服务注册、发现
-
微服务请求路由、负载均衡
-
微服务登录用户信息传递
路由过滤器或网关过滤器 - GaetwayFilter
GaetwayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:
 路由过滤器工厂 - GetwayFilterFactory
路由过滤器工厂 - GetwayFilterFactory
Spring提供了33种不同的路由过滤器(工厂),每种路由过滤器都有独特的作用,例如:
| 名称 | 说明 |
|---|---|
| AddRequestHeaderGatewayFilterFactory | 添加请求头的过滤器,给当前请求添加一个请求头(key-value形式)并传递到下游微服务 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
......
Gateway内置的GatewayFilter过滤器使用起来非常简单,只需在服务的application.yml文件当中来简单配置即可,并且其作用范围也很灵活,配置在哪个Route下,就作用于哪个Route。
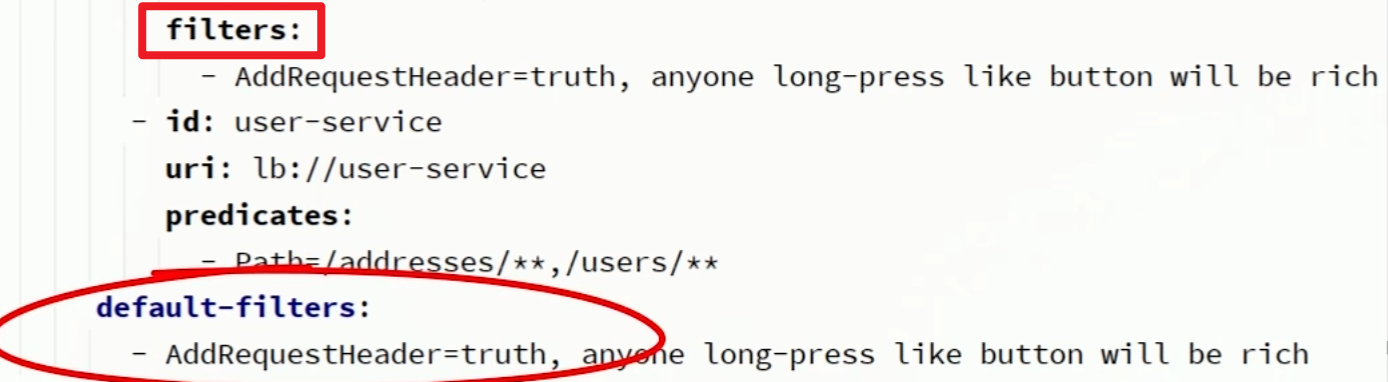
全局路由过滤器:默认过滤器 - defaultFilters - 让过滤器作用于所有的路由
- 如果要对所有的路由都生效,则可以将过滤器工厂写到defalut下。
spring:cloud:gateway:routes:- id: user-service uri: lb://userservice predicates: - Path=/user/**default-filters: # 默认过滤项,default-filters下的过滤器可以作用于所有路由- AddRequestHeader=Truth, Itcast is freaking awesome! 总结
过滤器的作用是什么?
- 对路由的请求或响应做加工处理,比如添加请求头
- 配置在路由下的过滤器只对当前路由的请求生效
defaultFilters的作用是什么?
- 对所有路由都生效的过滤器
全局过滤器 - GlobalFilter
- 全局过滤器的作用是拦截处理一切进入网关的请求和微服务响应,与GetwayFilter的作用一样。
- 区别于路由过滤器或网关过滤器GetwayFilter通过配置来定义,并且每一种路由过滤器的处理逻辑是固定的,如果我们希望拦截请求,做自己的业务逻辑则没办法实现,而GlobalFilter的逻辑需要自己写代码实现。
定义方式是实现GlobalFilter接口:
public interface GlobalFilter {/*** 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理** @param exchange 当前请求的上下文,里面可以获取Request、Response等信息* @param chain 过滤器链,基于它向下传递请求,用来把请求委托给下一个过滤器 * @return {@code Mono<Void>} 根据返回值标记当前请求是否被完成或拦截,标记过滤器业务结束 chain.filter(exchange)放行*/Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}在filter中编写自定义逻辑,可以实现下列功能:
- 登录状态判断
- 权限校验
- 请求限流等

拦截器是在Servlet之后Controller之前,而过滤器是在Servlet之前。
package cn.itcast.filter;import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.core.annotation.Order;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.stereotype.Component;
import org.springframework.util.MultiValueMap;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;/*** 自定义全局过滤器* 过滤器的顺序除了可以通过注解来指定,还可以通过Ordered接口来指定 => 责任链模式*/
@Order(-1) // 该注解是一个顺序注解,设置过滤器先后顺序的,这个值越小,优先级越高
@Component
public class AuthorizationFilter implements GlobalFilter, Ordered {/*** 自定义全局过滤器,拦截请求并判断用户身份(登录认证过滤器)** @param exchange 请求上下文,里面可以获取Request,Response等信息* @param chain 用来把请求委托给下一个过滤器* @return 返回标识当前过滤器业务结束*/@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// TODO 模拟登录校验逻辑// 1.获取request请求参数 .var自动补全左边
// MultiValueMap<String, String> queryParams = exchange.getRequest().getQueryParams();ServerHttpRequest request = exchange.getRequest();MultiValueMap<String, String> queryParams = request.getQueryParams();// 2.获取参数中的authorization参数String authorization = queryParams.getFirst("authorization");// 3.判断参数值是否等于adminif ("admin".equals(authorization)) {// 4.是,放行 只有这一个APIreturn chain.filter(exchange);} else {// 5.否,拦截// 5.1 禁止访问,设置响应状态码:HttpStatus是一个枚举类 403:服务端拒绝访问exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);// 5.2 结束处理return exchange.getResponse().setComplete();}}/*** 设置过滤器的优先级或执行顺序** @return 该方法的返回值越小, 优先级越高*/@Overridepublic int getOrder() {return -1;}
}
设置响应状态码:一种是直接写int值,一种是枚举!

总结 - 实现全局过滤器的步骤:
-
实现GlobalFilter接口
-
添加注解@Order注解或者实现Ordered接口
-
编写处理逻辑
过滤器一定要有顺序~!
过滤器链的执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器(局部路由过滤器)、DefaultFilter(全局路由过滤器)、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
- 局部路由过滤器和全局路由过滤器它两的本质一样,是同一类,都是路由过滤器GaetwayFilter类,只不过作用范围不同而已~!
GetwayFilterAdapter:过滤器适配器 => 适配器模式
 在网关当中,所有的GlobalFilter都可以被适配成GetwayFilter,从这个角度来讲,我们可以认为网关中的所有过滤器最终都是GetwayFilter类型,既然是同一种类型,那我们当然可以扔到同一种集合中去做排序,放到同一个过滤器链中,排序以后依次执行。
在网关当中,所有的GlobalFilter都可以被适配成GetwayFilter,从这个角度来讲,我们可以认为网关中的所有过滤器最终都是GetwayFilter类型,既然是同一种类型,那我们当然可以扔到同一种集合中去做排序,放到同一个过滤器链中,排序以后依次执行。
 过滤器的排序规则是什么呢?网关中过滤器的执行顺序?
过滤器的排序规则是什么呢?网关中过滤器的执行顺序?
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序就越靠前
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,值由我们自己指定
- 路由过滤器和defaultFilter的order值由Spring指定,默认是按照声明顺序(就是在application.yml文件中的声明顺序)从1递增。
- 当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行(看了Spring的Getway源码才知道)。
getFilter()方法是加载路由过滤器和defaultFilter,handle()方法就是去加载GlobalFilter并且对GlobalFilter去做装饰,把它变成GetwayFilter,最后把所有过滤器合并做排序的:
 总结:
总结:
- 排序,先看order值,值越小,优先级越高,值一样时,defaultFilter最先,然后是局部的路由过滤器,最后是全局过滤器。
网关的跨域问题处理
- 在微服务当中,所有请求都要先经过网关,再到微服务,也就是说,跨域请求不需要在每个微服务里都去处理,仅仅在网关处理就可以了。
- 但是网关又跟以前的不一样,网关是基于WebFlux实现的,没有Servlet相关的API,因此,我们之前所学的解决方案不一定能够适用。
跨域问题回顾:
- 域名不一致就是跨域,比如域名不同、域名相同但端口不同
跨域问题:浏览器禁止请求的发起者与微服务发生跨域Ajax请求,请求被浏览器拦截的问题。
解决方案:CORS
网关处理跨域问题采用的同样是CORS方案(CORS是浏览器去询问服务器你让不让跨域,它有一次询问,这个询问的请求方式是options,默认情况下这种请求方式是会被网关拦截的,所以要改为true,就是让网关不拦截options类型的请求,这样CORS的询问请求就会被正常发出了),只需要在网关Getway服务的application.yml文件当中简单配置即可实现:
spring:cloud:gateway:# 。。。globalcors: # 全局的跨域处理add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题corsConfigurations:'[/**]': #直接拦截哪些请求allowedOrigins: # 允许哪些网站的跨域请求 - "http://localhost:8090"allowedMethods: # 允许的跨域ajax的请求方式- "GET"- "POST"- "DELETE"- "PUT"- "OPTIONS"allowedHeaders: "*" # 允许在请求中携带的头信息allowCredentials: true # 是否允许携带cookiemaxAge: 360000 # 这次跨域检测的有效期,减少每一次对服务器的Ajax请求而造成的访问压力跨域的CORS方案对性能会有一定的损耗,为了减少损耗,我们可以给跨域请求设置有效期,有效期范围内,浏览器将不再发起询问,而是直接放行,从而提高性能。