预计更新
一、 爬虫技术概述
1.1 什么是爬虫技术
1.2 爬虫技术的应用领域
1.3 爬虫技术的工作原理
二、 网络协议和HTTP协议
2.1 网络协议概述
2.2 HTTP协议介绍
2.3 HTTP请求和响应
三、 Python基础
3.1 Python语言概述
3.2 Python的基本数据类型
3.3 Python的流程控制语句
3.4 Python的函数和模块
3.5 Python的面向对象编程
四、 爬虫工具介绍
4.1 Requests库
4.2 BeautifulSoup库
4.3 Scrapy框架
五、 数据存储和处理
5.1 数据存储格式介绍
5.2 数据库介绍
5.3 数据处理和分析
六、 动态网页爬取
6.1 动态网页概述
6.2 Selenium工具介绍
6.3 PhantomJS工具介绍
七、 反爬虫技术
7.1 反爬虫技术概述
7.2 User-Agent伪装
7.3 IP代理池
八、 数据清洗和预处理
8.1 数据清洗和去重
8.2 数据预处理和分析
九、 分布式爬虫和高并发
9.1 分布式爬虫概述
9.2 分布式爬虫框架介绍
9.3 高并发爬虫实现
十、 爬虫实战
10.1 爬取豆瓣电影排行榜
10.2 爬取天气数据
10.3 爬取新闻网站数据
四、 爬虫工具介绍
4.1 Requests库
4.2 BeautifulSoup库
4.3 Scrapy框架
Requests库
一、前言
网络爬虫是一种自动化程序,主要用于从互联网上抓取数据。在进行网络爬虫开发时,选择一个适合的爬虫工具是非常重要的。Requests库是Python中一个非常流行的HTTP客户端库,它提供了简单易用的API,使得开发者可以方便地发送HTTP请求、处理HTTP响应和管理HTTP会话。本文将详细介绍Requests库的基本用法、高级用法和实例应用,帮助读者更好地了解和使用该库。
二、基本用法
- 安装Requests库
在使用Requests库之前,需要先安装该库。可以使用pip命令进行安装:
pip install requests
- 发送HTTP请求
使用Requests库发送HTTP请求非常简单。可以使用requests.get()函数发送一个GET请求,该函数返回一个Response对象,包含服务器返回的HTTP响应。例如,以下代码发送了一个GET请求,并输出了服务器返回的HTTP响应:
import requestsresponse = requests.get('https://www.baidu.com/')
print(response.text)
上述代码中,requests.get()函数接受一个URL作为参数,并返回一个Response对象。Response对象的text属性包含服务器返回的HTTP响应体。可以使用print()函数输出响应体。
除了GET请求,Requests库还支持发送POST、PUT、DELETE等HTTP请求。可以使用requests.post()、requests.put()、requests.delete()等函数发送对应的HTTP请求。
- HTTP请求参数
在发送HTTP请求时,可以通过URL参数或请求体参数传递参数。例如,以下代码发送了一个带有URL参数的GET请求:
import requestsparams = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://httpbin.org/get', params=params)
print(response.url)
上述代码中,params参数是一个字典,包含了需要传递的参数。requests.get()函数的params参数接受一个字典,用于设置URL参数。该代码发送了一个GET请求,URL为https://httpbin.org/get?key1=value1&key2=value2。可以使用response.url属性获取实际发送的URL。
除了URL参数,还可以使用data参数或json参数传递请求体参数。例如,以下代码发送了一个带有JSON请求体的POST请求:
import requestsurl = 'https://httpbin.org/post'
data = {'key1': 'value1', 'key2': 'value2'}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, json=data, headers=headers)
print(response.json())
上述代码中,json参数是一个字典,包含了需要传递的JSON请求体。requests.post()函数的json参数接受一个字典,用于设置JSON请求体。该代码发送了一个POST请求,请求体为{“key1”: “value1”, “key2”: “value2”},Content-Type为application/json。可以使用response.json()方法获取服务器返回的JSON响应体。
- HTTP请求头
在发送HTTP请求时,可以通过headers参数设置请求头。例如,以下代码发送了一个带有自定义请求头的GET请求:
import requestsurl = 'https://httpbin.org/get'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
print(response.json())
上述代码中,headers参数是一个字典,包含了需要设置的请求头。该代码发送了一个GET请求,使用了自定义的User-Agent请求头。可以使用response.json()方法获取服务器返回的JSON响应体。
- HTTP响应内容
在发送HTTP请求后,可以通过Response对象获取服务器返回的HTTP响应。Response对象包含了HTTP响应的状态码、响应头和响应体等信息。
例如,以下代码发送了一个GET请求,并输出了服务器返回的HTTP响应状态码和响应头:
import requestsresponse = requests.get('https://www.baidu.com/')
print(response.status_code)
print(response.headers)
上述代码中,response.status_code属性包含了服务器返回的HTTP响应状态码。可以使用print()函数输出状态码。response.headers属性是一个字典,包含了服务器返回的HTTP响应头。可以使用print(response.headers)输出响应头。
Response对象的常用属性和方法如下:
- status_code:HTTP响应状态码。
- headers:HTTP响应头,字典类型。
- text:HTTP响应体的文本内容,如果响应体是二进制数据,则需要使用response.content属性。
- json():将HTTP响应体解析为JSON格式的数据,如果响应体不是JSON格式,则会抛出异常。
- content:HTTP响应体的二进制数据。
- HTTP会话管理
在使用Requests库发送HTTP请求时,每次请求都需要重新建立TCP连接,这会导致一定的性能损失。为了提高性能,可以使用HTTP会话来管理TCP连接。
HTTP会话是一个持久化的连接,可以在多个HTTP请求之间共享。使用Requests库创建HTTP会话非常简单,只需要创建一个Session对象即可。例如,以下代码创建了一个HTTP会话,并使用该会话发送了两个GET请求:
import requestssession = requests.Session()response1 = session.get('https://www.baidu.com/')
print(response1.text)response2 = session.get('https://www.google.com/')
print(response2.text)
上述代码中,创建了一个Session对象,并使用该对象发送了两个GET请求。由于使用了HTTP会话,第二个请求可以直接复用第一个请求的TCP连接,避免了重新建立TCP连接的性能损失。
- SSL证书验证
在使用Requests库发送HTTPS请求时,可以通过verify参数设置SSL证书验证。如果verify参数为True,则会对服务器返回的SSL证书进行验证;如果为False,则不会进行验证;如果为字符串类型,则会将其作为证书文件进行验证。例如,以下代码发送了一个HTTPS请求,并关闭了SSL证书验证:
import requestsresponse = requests.get('https://www.baidu.com/', verify=False)
print(response.text)
上述代码中,verify参数为False,表示关闭了SSL证书验证。可以使用response.text属性获取服务器返回的HTTP响应体。
- 代理设置
在使用Requests库发送HTTP请求时,可以通过proxies参数设置代理。proxies参数是一个字典,包含了要使用的代理服务器的地址。例如,以下代码使用了一个HTTP代理发送了一个GET请求:
import requestsproxies = {'http': 'http://127.0.0.1:8080','https': 'http://127.0.0.1:8080',
}response = requests.get('https://www.baidu.com/', proxies=proxies)
print(response.text)
上述代码中,proxies参数指定了要使用的HTTP代理服务器的地址。可以使用response.text属性获取服务器返回的HTTP响应体。
- 总结
本文介绍了Python中使用Requests库发送HTTP请求的方法。可以使用Requests库发送GET、POST等HTTP请求,可以设置请求头、请求参数、响应状态码、HTTP会话、SSL证书验证和代理等功能。使用Requests库发送HTTP请求非常方便,可以大大提高开发效率。
BeautifulSoup库
- 简介
BeautifulSoup是Python中的一个HTML和XML解析库,可以将HTML或XML文档解析为Python对象,并提供了方便的方法来遍历和搜索文档树。
BeautifulSoup支持解析HTML和XML文档,可以自动将输入文档转换为Unicode编码,同时也支持不同的解析器,包括Python标准库中的html.parser、lxml、html5lib等。
- 安装
使用pip安装BeautifulSoup库:
pip install beautifulsoup4
如果需要使用lxml或html5lib解析器,还需要安装相应的库:
pip install lxml
pip install html5lib
- 基本用法
使用BeautifulSoup库解析HTML文档的基本步骤如下:
- 将HTML文档作为输入,创建一个BeautifulSoup对象;
- 使用BeautifulSoup对象提供的方法遍历和搜索文档树。
以下是一个简单的例子,解析一个HTML文档并输出其中所有的链接:
from bs4 import BeautifulSoup
import requests# 获取HTML文档
url = 'https://www.baidu.com'
r = requests.get(url)
html_doc = r.text# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')# 输出所有的链接
for link in soup.find_all('a'):print(link.get('href'))
上述代码中,首先使用requests库获取了百度首页的HTML文档,然后创建了一个BeautifulSoup对象,使用find_all方法搜索文档中所有的链接,并输出它们的href属性。
- 文档树的遍历
BeautifulSoup对象是HTML文档的根节点,可以通过调用BeautifulSoup对象的属性和方法来遍历文档树。以下是一些常用的属性和方法:
- tag.name:获取标签的名称;
- tag.attrs:获取标签的属性;
- tag.string:获取标签的文本内容;
- tag.contents:获取标签的直接子节点列表;
- tag.children:获取标签的直接子节点的迭代器;
- tag.descendants:获取标签的所有子孙节点的迭代器;
- tag.parent:获取标签的父节点;
- tag.previous_sibling:获取标签的前一个兄弟节点;
- tag.next_sibling:获取标签的后一个兄弟节点;
- tag.previous_element:获取文档树中的前一个节点;
- tag.next_element:获取文档树中的后一个节点。
以下是一个例子,遍历一个HTML文档的所有标签,并输出它们的名称、属性和文本内容:
from bs4 import BeautifulSoup
import requests# 获取HTML文档
url = 'https://www.baidu.com'
r = requests.get(url)
html_doc = r.text# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')# 遍历文档树
for tag in soup.descendants:if tag.name:print('Tag name:', tag.name)print('Tag attributes:', tag.attrs)print('Tag text:', tag.string)
上述代码中,遍历了文档树中的所有节点,并输出它们的名称、属性和文本内容。
- 搜索文档树
BeautifulSoup对象提供了一些方法来搜索文档树,可以根据标签名、属性、文本内容等条件来搜索节点。以下是一些常用的搜索方法:
- find_all(name, attrs, recursive, text, **kwargs):返回文档中所有满足条件的节点的列表;
- find(name, attrs, recursive, text, **kwargs):返回文档中第一个满足条件的节点;
- select(selector):使用CSS选择器语法搜索文档中的节点。
以下是一个例子,搜索一个HTML文档中的所有图片,并输出它们的src属性:
from bs4 import BeautifulSoup
import requests# 获取HTML文档
url = 'https://www.baidu.com'
r = requests.get(url)
html_doc = r.text# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')# 搜索文档树
for img in soup.find_all ('img'):print(img.get('src'))
上述代码中,使用find_all方法搜索文档树中的所有img标签,并输出它们的src属性。
除了使用标签名来搜索节点,还可以使用属性、文本内容等条件来搜索节点。例如,以下代码搜索一个HTML文档中所有class属性为"test"的标签:
from bs4 import BeautifulSoup
import requests# 获取HTML文档
url = 'https://www.baidu.com'
r = requests.get(url)
html_doc = r.text# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')# 搜索文档树
for tag in soup.find_all(class_='test'):print(tag)
上述代码中,使用class_参数指定要搜索的class属性值,使用find_all方法搜索文档树中所有满足条件的标签,并输出它们的内容。
另外,使用CSS选择器语法可以更灵活地搜索文档树中的节点。以下是一个例子,使用CSS选择器语法搜索一个HTML文档中所有a标签中包含"baidu"文本的节点:
from bs4 import BeautifulSoup
import requests# 获取HTML文档
url = 'https://www.baidu.com'
r = requests.get(url)
html_doc = r.text# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')# 使用CSS选择器搜索文档树
for a in soup.select('a:contains("baidu")'):print(a.get('href'))
上述代码中,使用select方法和CSS选择器语法搜索文档树中所有a标签中包含"baidu"文本的节点,并输出它们的href属性。
- 解析XML文档
BeautifulSoup同样支持解析XML文档,只需要指定解析器为"xml"即可。以下是一个例子,解析一个XML文档并输出其中所有的节点名:
from bs4 import BeautifulSoup# XML文档
xml_doc = '<?xml version="1.0" encoding="UTF-8"?><root><node1>text1</node1><node2>text2</node2></root>'# 创建BeautifulSoup对象
soup = BeautifulSoup(xml_doc, 'xml')# 输出所有的节点名
for tag in soup.descendants:if tag.name:print(tag.name)
上述代码中,使用"xml"解析器创建了一个BeautifulSoup对象,遍历了文档树中的所有节点,并输出它们的节点名。
- 总结
BeautifulSoup是Python中一个强大的HTML和XML解析库,可以将输入文档解析为Python对象,并提供了方便的方法来遍历和搜索文档树。使用BeautifulSoup可以更快、更简单地处理HTML和XML文档,是Python爬虫工具中不可或缺的一部分。
Scrapy框架
- 简介
Scrapy是一个用于爬取Web站点并从中提取数据的Python框架。它提供了一种高效、可扩展、可重用的方式来设计和编写爬虫程序。使用Scrapy框架,可以轻松地定义爬虫规则、处理爬取到的数据、存储数据等操作。
Scrapy框架的主要特点包括:
- 高效:Scrapy使用异步IO和Twisted网络库实现了高效的网络请求和数据处理,可以快速地爬取大量数据。
- 可扩展:Scrapy提供了各种插件和中间件,可以方便地扩展框架的功能。
- 可配置:Scrapy框架提供了丰富的配置选项,可以根据不同的需求进行配置。
- 可重用:Scrapy框架的设计模式使得代码可以被多次重用,可以节省开发时间和成本。
- 安装
使用Scrapy框架需要先安装Scrapy库。可以使用pip工具进行安装:
pip install scrapy
安装完成后,可以使用以下命令来验证是否安装成功:
scrapy version
- 架构
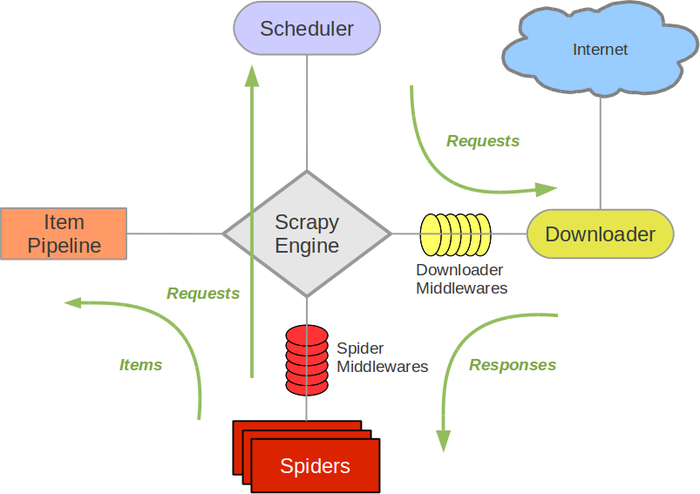
Scrapy框架的架构分为引擎、调度器、下载器、爬虫、管道等几个组件。
- 引擎:Scrapy框架的核心组件,负责协调其他组件,控制整个爬取流程的开始、中止和异常处理等。
- 调度器:负责接收引擎传递过来的请求,并根据一定的策略将请求转发给下载器。
- 下载器:根据调度器传递过来的请求,下载网页并返回给引擎。
- 爬虫:定义了如何爬取网站的规则和逻辑,包括网站的URL、如何跟进链接、如何解析页面等。
- 管道:负责处理从爬虫中提取出来的数据,包括数据的清洗、存储等操作。
Scrapy框架的整个流程大致如下:
- 爬虫实现
使用Scrapy框架编写爬虫程序,需要先定义一个爬虫类。以下是一个简单的爬取豆瓣电影Top250的爬虫示例:
import scrapyclass DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250']def parse(self, response):# 解析页面for item in response.css('.item'):yield {'title': item.css('.title::text').get(),'rating': item.css('.rating_num::text').get(),'link': item.css('a::attr(href)').get(),}# 爬取下一页next_page = response.css('.next a::attr(href)').get()if next_page:yield response.follow(next_page, self.parse)
以上代码定义了一个名为"DoubanSpider"的爬虫类,继承自Scrapy框架中的Spider类。其中,name属性定义了爬虫名称,allowed_domains属性定义了爬虫可以爬取的域名,start_urls属性定义了爬虫的起始URL。
parse方法是Scrapy框架中的一个默认方法,用于解析爬取到的网页。在该方法中,使用response.css方法选择页面中符合条件的元素,并使用yield语句返回提取到的数据。在最后,使用response.follow方法跟进下一页的链接,并再次调用parse方法解析页面。
- 中间件
Scrapy框架提供了丰富的中间件,可以方便地扩展框架的功能。中间件可以在请求、响应、爬取等过程中拦截和处理数据,并修改请求和响应的内容。以下是一些常用的中间件:
- User-Agent中间件:设置请求的User-Agent头,以避免被网站屏蔽或限制。
- Proxy中间件:设置请求的代理服务器,以实现IP切换和反反爬。
- Retry中间件:对请求失败进行重试,以增加爬取成功率。
- Downloader Middleware:自定义下载器中间件,可以修改请求和响应的内容,实现自定义的下载器逻辑。
- Spider Middleware:自定义爬虫中间件,可以拦截和处理爬虫请求和响应,实现自定义的爬虫逻辑。
以下是一个简单的User-Agent中间件的示例:
from scrapy import signalsclass RandomUserAgentMiddleware:def __init__(self, user_agents):self.user_agents = user_agents@classmethoddef from_crawler(cls, crawler):return cls(crawler.settings.getlist('USER_AGENTS'))def process_request(self, request, spider):request.headers.setdefault('User-Agent', random.choice(self.user_agents))
以上代码定义了一个名为"RandomUserAgentMiddleware"的User-Agent中间件类。在该类的构造方法中,传入了一个User-Agent列表,用于随机选择一个User-Agent头。在类方法from_crawler中,从Scrapy框架的设置中获取USER_AGENTS配置项,并传入构造方法中。在process_request方法中,修改request对象的User-Agent头,以实现随机选择User-Agent头的功能。
- 数据存储
爬虫爬取到的数据可以存储到不同的数据源中,如文件、数据库、消息队列等。Scrapy框架提供了Pipeline组件,用于将爬取到的数据保存到不同的数据源中。
在Scrapy框架中,Pipeline是一个类,可以实现以下方法:
- process_item(item, spider):处理爬虫提取出来的数据,并将其保存到数据源中。
- open_spider(spider):在爬虫启动时调用。
- close_spider(spider):在爬虫关闭时调用。
以下是一个简单的将数据保存到文件的Pipeline示例:
class FilePipeline:def __init__(self, filename):self.filename = filename@classmethoddef from_crawler(cls, crawler):return cls(crawler.settings.get('FILE_NAME'))def open_spider(self, spider):self.file = open(self.filename, 'w')def process_item(self, item, spider):line = json.dumps(dict(item), ensure_ascii=False) + '\n'self.file.write(line)return itemdef close_spider(self, spider):self.file.close()
以上代码定义了一个名为"FilePipeline"的Pipeline类。在该类的构造方法中,传入文件名,用于存储数据。在类方法from_crawler中,从Scrapy框架的设置中获取FILE_NAME配置项,并传入构造方法中。在open_spider方法中,打开文件,以便写入数据。在process_item方法中,将item对象转换为JSON格式字符串,并写入文件中。在close_spider方法中,关闭文件,以便保存数据。
- 部署
使用Scrapy框架编写完爬虫程序后,可以使用Scrapy框架自带的命令进行爬虫启动和停止。但是,如果需要在分布式环境中运行爬虫程序,需要进行部署。
Scrapy框架提供了多种部署方式,如:
- Scrapy Cloud:Scrapy官方提供的云端部署服务,支持自动化部署、监控和调度等功能。
- Scrapyd:Scrapy官方提供的分布式爬虫部署工具,支持通过API进行爬虫的部署、管理和监控。
- Docker:使用Docker容器技术,可以将爬虫程序打包成镜像,方便部署和迁移。
- 自定义部署方式:可以将爬虫程序打包成可执行文件,并通过其他工具进行部署和管理。
以下是使用Scrapyd进行爬虫部署的示例:
- 在本地创建Scrapyd项目
在命令行中执行以下命令:
scrapyd-deploy <project> -p <project_name>
其中,为Scrapy项目所在的目录路径,<project_name>为Scrapyd项目的名称。
- 在服务器上安装Scrapyd
在服务器上执行以下命令:
pip install scrapyd
- 在服务器上启动Scrapyd
在命令行中执行以下命令:
scrapyd
- 在服务器上部署爬虫
在命令行中执行以下命令:
curl http://localhost:6800/schedule.json -d project=<project_name> -d spider=<spider_name>
其中,<project_name>为Scrapyd项目的名称,<spider_name>为要部署的爬虫名称。
以上是使用Scrapyd进行爬虫部署的简单示例。部署过程可能因具体情况而异,需要根据实际情况进行调整和优化。
总结
本文介绍了Scrapy框架的基本功能和使用方法,包括创建Scrapy项目、编写爬虫、解析网页、使用中间件、数据存储、部署等方面。Scrapy框架具有高效、灵活、易用等特点,在爬取大规模、复杂的网站数据方面具有很大的优势。在实际应用中,需要根据具体情况进行调整和优化,才能发挥Scrapy框架的最大效益。