想要学习如何在Kubernetes上自动缩放您的Kinesis Data Streams消费者应用程序,以便节省成本并提高资源效率吗?本文提供了一个逐步指南,教您如何实现这一目标。
通过利用Kubernetes对Kinesis消费者应用程序进行自动缩放,您可以从其内置功能中受益,例如水平Pod自动缩放器(Horizontal Pod Autoscaler)。
▌什么是Amazon Kinesis和Kinesis Data Streams?
Amazon Kinesis是一个用于实时数据处理、摄取和分析的平台。Kinesis Data Streams是一个无服务器的流式数据服务(属于Kinesis流式数据平台的一部分),还包括Kinesis Data Firehose、Kinesis Video Streams和Kinesis Data Analytics。
Kinesis Data Streams可以弹性地扩展,并持续适应数据摄取速率和流消费速率的变化。它可用于构建实时数据分析应用程序、实时仪表板和实时数据管道。
让我们首先概述一些Kinesis Data Streams的关键概念。
▌Kinesis Data Streams:高级架构
-
Kinesis数据流由一组分片组成。每个分片包含一系列数据记录。
-
生产者持续将数据推送到Kinesis Data Streams,消费者实时处理数据。
-
分区键用于在流中按分片分组数据。
-
Kinesis Data Streams将属于流的数据记录分隔到多个分片中。
-
它使用与每个数据记录关联的分区键来确定给定数据记录属于哪个分片。
-
消费者从Amazon Kinesis Data Streams获取记录,对其进行处理,并将结果存储在Amazon DynamoDB、Amazon Redshift、Amazon S3等中。
-
这些消费者也被称为Amazon Kinesis Data Streams应用程序。
-
开发能够处理KDS数据流中的数据的自定义消费者应用程序的一种方法是使用Kinesis Client Library(KCL)。
Kinesis消费者应用程序是如何实现水平扩展的呢?
Kinesis Client Library确保每个分片都有一个记录处理器正在运行,并处理来自该分片的数据。KCL帮助您从Kinesis数据流中消费和处理数据,通过处理与分布式计算和可扩展性相关的许多复杂任务。它连接到数据流,枚举数据流中的分片,并使用租约来协调分片与其消费者应用程序之间的关联。
每个分片都会实例化一个记录处理器来管理。KCL从数据流中拉取数据记录,将记录推送给相应的记录处理器,并检查点处理过的记录。更重要的是,当工作实例数量发生变化或数据流重新分片(分片拆分或合并)时,它会平衡分片-工作器的关联(租约)。这意味着您可以通过添加更多实例来扩展Kinesis Data Streams应用程序,因为KCL会自动在实例之间平衡分片。
但是,当负载增加时,您仍然需要一种方法来扩展应用程序。当然,您可以手动进行操作或构建自定义解决方案来完成此操作。
这就是Kubernetes事件驱动自动缩放(KEDA)的用武之地。KEDA是基于Kubernetes的事件驱动自动缩放组件,它可以监视Kinesis等事件源,并根据需要处理的事件数量来调整底层的部署(和Pod)的规模。
为了观察自动扩展的过程,您将使用一个使用Kinesis Client Library(KCL)2.x从Kinesis数据流中消费数据的Java应用程序。它将部署到Amazon EKS上的Kubernetes集群,并将使用KEDA进行自动缩放。该应用程序包括一个ShardRecordProcessor的实现,该实现处理来自Kinesis流的数据,并将其持久化到DynamoDB表中。我们将使用AWS CLI向Kinesis流中产生数据,并观察应用程序的扩展情况。

在我们深入研究之前,这里是对KEDA的快速概述。
▌什么是KEDA?
KEDA是一个构建在原生Kubernetes原语(如Horizontal Pod Autoscaler)之上的开源CNCF项目,可以添加到任何Kubernetes集群中。以下是其关键组件的高级概述(您可以参考KEDA文档进行深入了解):
-
KEDA中的keda-operator-metrics-apiserver组件充当Kubernetes度量服务器,用于公开Horizontal Pod Autoscaler的度量指标。
-
KEDA Scaler与外部系统(如Redis)集成,以获取这些指标(例如列表长度),根据需要处理的事件数量来驱动Kubernetes中任何容器的自动扩展。
-
keda-operator组件的作用是激活和停用Deployment,即将其扩展到零或从零缩减。
您将看到Kinesis Stream KEDA Scaler的实际效果,它会根据AWS Kinesis Stream的分片数量进行自动扩展。
现在让我们继续进行本文的实际部分。
▌先决条件
除了一个AWS账户之外,您还需要安装AWS CLI、kubectl、Docker、Java 11和Maven。
设置一个EKS集群,创建一个DynamoDB表和一个Kinesis数据流
有多种方法可以创建Amazon EKS集群。我喜欢使用eksctl CLI,因为它提供了很多便利。使用eksctl创建EKS集群可以非常简单,就像这样:
eksctl create cluster --name <cluster name> --region <region e.g. us-east-1>有关详细信息,请参阅Amazon EKS - eksctl文档中的入门指南。
创建一个DynamoDB表来持久化应用程序数据。您可以使用AWS CLI使用以下命令创建表格:
aws dynamodb create-table \--table-name users \--attribute-definitions AttributeName=email,AttributeType=S \--key-schema AttributeName=email,KeyType=HASH \--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5
使用AWS CLI创建一个具有两个分片的Kinesis流,请执行以下命令:
aws kinesis create-stream --stream-name kinesis-keda-demo --shard-count 2请克隆该GitHub仓库,并切换到正确的目录:
git clone https://github.com/abhirockzz/kinesis-keda-autoscalingcd kinesis-keda-autoscaling
好的,让我们开始吧!
▌在EKS上设置和配置KEDA
在本教程中,您将使用YAML文件来部署KEDA。但是您也可以使用Helm charts。
安装KEDA:
# update version 2.8.2 if requiredkubectl apply -f https://github.com/kedacore/keda/releases/download/v2.8.2/keda-2.8.2.yaml验证安装:
# check Custom Resource Definitions
kubectl get crd# check KEDA Deployments
kubectl get deployment -n keda# check KEDA operator logs
kubectl logs -f $(kubectl get pod -l=app=keda-operator -o jsonpath='{.items[0].metadata.name}' -n keda) -n keda▌配置IAM角色
KEDA操作员和Kinesis消费应用程序需要调用AWS API。由于两者都将作为EKS中的部署运行,我们将使用服务账号的IAM角色(IRSA)来提供必要的权限。
在这种情况下:
-
KEDA操作员需要能够获取Kinesis流的分片数量:它通过使用DescribeStreamSummary API来实现。
-
应用程序(具体而言是KCL库)需要与Kinesis和DynamoDB进行交互:它需要一系列的IAM权限来实现这一点。
配置KEDA操作员的IRSA
将AWS帐户ID和OIDC身份提供者设置为环境变量:
ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output text)#update the cluster name and region as required
export EKS_CLUSTER_NAME=demo-eks-cluster
export AWS_REGION=us-east-1OIDC_PROVIDER=$(aws eks describe-cluster --name $EKS_CLUSTER_NAME --query "cluster.identity.oidc.issuer" --output text | sed -e "s/^https:\/\///")创建一个包含角色的受信任实体的JSON文件:
read -r -d '' TRUST_RELATIONSHIP <<EOF{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"Federated": "arn:aws:iam::${ACCOUNT_ID}:oidc-provider/${OIDC_PROVIDER}"},"Action": "sts:AssumeRoleWithWebIdentity","Condition": {"StringEquals": {"${OIDC_PROVIDER}:aud": "sts.amazonaws.com","${OIDC_PROVIDER}:sub": "system:serviceaccount:keda:keda-operator"}}}]}EOFecho "${TRUST_RELATIONSHIP}" > trust_keda.json
现在,创建IAM角色并附加策略(请查看policy_kinesis_keda.json文件以获取详细信息):
export ROLE_NAME=keda-operator-kinesis-roleaws iam create-role --role-name $ROLE_NAME --assume-role-policy-document file://trust_keda.json --description "IRSA for kinesis KEDA scaler on EKS"aws iam create-policy --policy-name keda-kinesis-policy --policy-document file://policy_kinesis_keda.json
aws iam attach-role-policy --role-name $ROLE_NAME --policy-arn=arn:aws:iam::${ACCOUNT_ID}:policy/keda-kinesis-policy关联IAM角色和服务账号:
kubectl annotate serviceaccount -n keda keda-operator eks.amazonaws.com/role-arn=arn:aws:iam::${ACCOUNT_ID}:role/${ROLE_NAME}# verify the annotation
kubectl describe serviceaccount/keda-operator -n keda您需要重新启动KEDA操作员部署以使其生效:
kubectl rollout restart deployment.apps/keda-operator -n keda# to verify, confirm that the KEDA operator has the right environment variables
kubectl describe pod -n keda $(kubectl get po -l=app=keda-operator -n keda --output=jsonpath={.items..metadata.name}) | grep "^\s*AWS_"# expected outputAWS_STS_REGIONAL_ENDPOINTS: regional
AWS_DEFAULT_REGION: us-east-1
AWS_REGION: us-east-1
AWS_ROLE_ARN: arn:aws:iam::<AWS_ACCOUNT_ID>:role/keda-operator-kinesis-role
AWS_WEB_IDENTITY_TOKEN_FILE: /var/run/secrets/eks.amazonaws.com/serviceaccount/token为KCL消费者应用程序配置IRSA
首先创建一个Kubernetes服务帐号:
kubectl apply -f - <<EOFapiVersion: v1kind: ServiceAccountmetadata:name: kcl-consumer-app-saEOF
创建一个包含角色的受信实体的JSON文件:
read -r -d '' TRUST_RELATIONSHIP <<EOF{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"Federated": "arn:aws:iam::${ACCOUNT_ID}:oidc-provider/${OIDC_PROVIDER}"},"Action": "sts:AssumeRoleWithWebIdentity","Condition": {"StringEquals": {"${OIDC_PROVIDER}:aud": "sts.amazonaws.com","${OIDC_PROVIDER}:sub": "system:serviceaccount:default:kcl-consumer-app-sa"}}}]}EOFecho "${TRUST_RELATIONSHIP}" > trust.json
现在,创建IAM角色并附加策略(请查看policy.json文件以获取详细信息):
export ROLE_NAME=kcl-consumer-app-roleaws iam create-role --role-name $ROLE_NAME --assume-role-policy-document file://trust.json --description "IRSA for KCL consumer app on EKS"aws iam create-policy --policy-name kcl-consumer-app-policy --policy-document file://policy.jsonaws iam attach-role-policy --role-name $ROLE_NAME --policy-arn=arn:aws:iam::${ACCOUNT_ID}:policy/kcl-consumer-app-policy关联IAM角色和服务账号:
kubectl annotate serviceaccount -n default kcl-consumer-app-sa eks.amazonaws.com/role-arn=arn:aws:iam::${ACCOUNT_ID}:role/${ROLE_NAME}# verify the annotation
kubectl describe serviceaccount/kcl-consumer-app-sa核心基础架构已准备就绪。让我们准备并部署消费者应用程序。
▌将KCL消费者应用程序部署到EKS
首先,您需要构建Docker镜像并将其推送到Amazon Elastic Container Registry(ECR)(请参阅Dockerfile获取详细信息)。
构建并推送Docker镜像到ECR
# create runnable JAR file
mvn clean compile assembly\:single# build docker image
docker build -t kcl-consumer-app .AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output text)# create a private ECR repo
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin $AWS_ACCOUNT_ID.dkr.ecr.us-east-1.amazonaws.comaws ecr create-repository --repository-name kcl-consumer-app --region us-east-1# tag and push the image
docker tag kcl-consumer-app:latest $AWS_ACCOUNT_ID.dkr.ecr.us-east-1.amazonaws.com/kcl-consumer-app:latest
docker push $AWS_ACCOUNT_ID.dkr.ecr.us-east-1.amazonaws.com/kcl-consumer-app:latest部署消费者应用程序
更新consumer.yaml文件,将刚刚推送到ECR的Docker镜像包含在内。其他部分的清单保持不变。
apiVersion: apps/v1
kind: Deployment
metadata:name: kcl-consumer
spec:replicas: 1selector:matchLabels:app: kcl-consumertemplate:metadata:labels:app: kcl-consumerspec:serviceAccountName: kcl-consumer-app-sacontainers:- name: kcl-consumerimage: AWS_ACCOUNT_ID.dkr.ecr.us-east-1.amazonaws.com/kcl-consumer-app:latestimagePullPolicy: Alwaysenv:- name: STREAM_NAMEvalue: kinesis-keda-demo- name: TABLE_NAMEvalue: users- name: APPLICATION_NAMEvalue: kinesis-keda-demo- name: AWS_REGIONvalue: us-east-1- name: INSTANCE_NAMEvalueFrom:fieldRef:fieldPath: metadata.name创建部署(Deployment):
kubectl apply -f consumer.yaml# verify Pod transition to Running state
kubectl get pods -w▌KEDA 中的 KCL 应用自动扩展
现在您已经部署了消费者应用程序,KCL 库应该开始运行了。它首先会在 DynamoDB 中创建一个“控制表”,这个表的名称应与 KCL 应用程序的名称相同(在本例中为 kinesis-keda-demo)。
初始的协调和表的创建可能需要几分钟时间。您可以查看消费者应用程序的日志来跟踪进展。
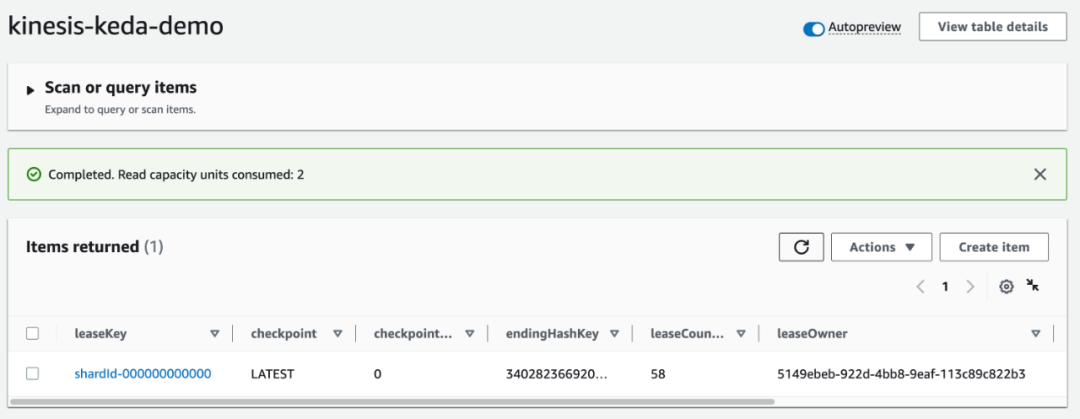
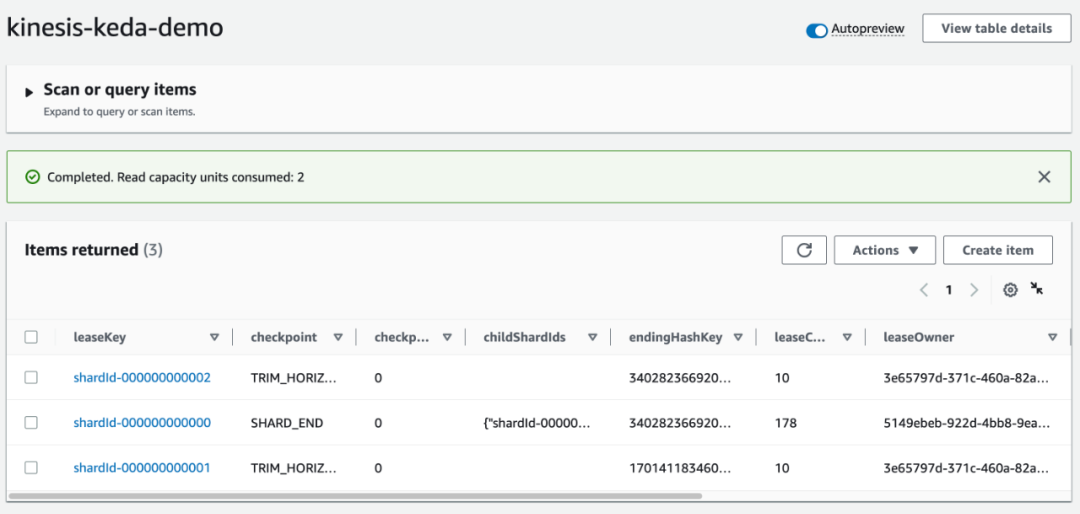
kubectl logs -f $(kubectl get po -l=app=kcl-consumer --output=jsonpath={.items..metadata.name})完成租赁分配后,请检查表并注意 leaseOwner 属性:
aws dynamodb describe-table --table-name kinesis-keda-demoaws dynamodb scan --table-name kinesis-keda-demo
现在,让我们使用 AWS CLI 向 Kinesis 流发送一些数据。
kubectl apply -f consumer.yaml# verify Pod transition to Running state
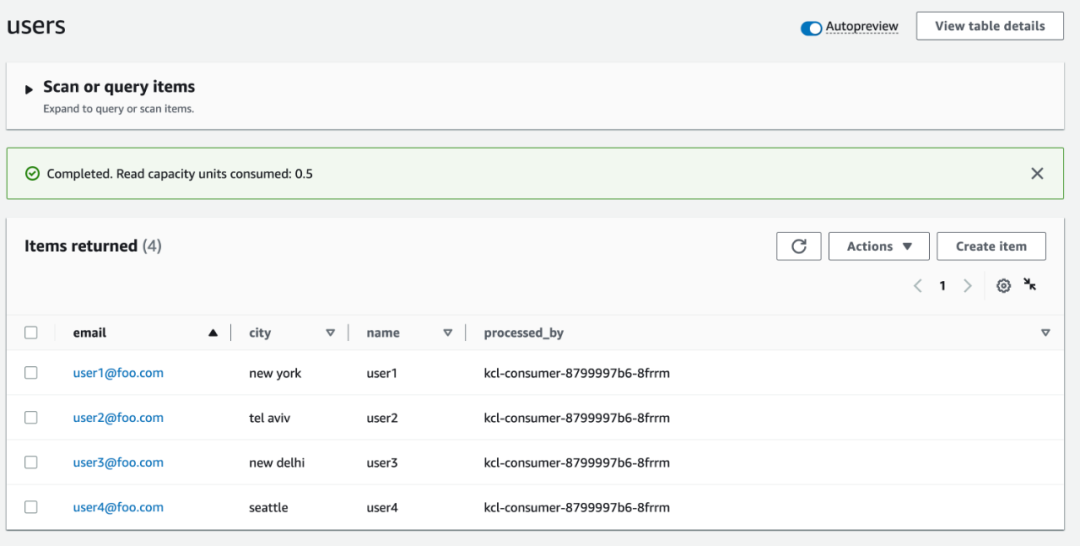
kubectl get pods -wKCL 应用程序将每条记录持久化到目标 DynamoDB 表中(在本例中为 users)。您可以检查该表以验证记录。
aws dynamodb scan --table-name users注意 processed_by 属性的值?它与 KCL 消费者 Pod 的名称相同。这将使我们更容易验证端到端的自动扩展过程。
创建 Kinesis 的 KEDA Scaler
以下是 ScaledObject 的定义。请注意,它针对的是 kcl-consumer Deployment(我们刚刚创建的那个),并且 shardCount 设置为 1:
apiVersion: keda.sh/v1alpha1kind: ScaledObjectmetadata:name: aws-kinesis-stream-scaledobjectspec:scaleTargetRef:name: kcl-consumertriggers:- type: aws-kinesis-streammetadata:# RequiredstreamName: kinesis-keda-demo# RequiredawsRegion: "us-east-1"shardCount: "1"identityOwner: "operator"
创建 KEDA Kinesis Scaler:
kubectl apply -f keda-kinesis-scaler.yaml验证 KCL 应用程序的自动伸缩
我们从一个 KCL 应用程序的 Pod 开始。但是,多亏了 KEDA,我们现在应该看到第二个 Pod 正在启动。
kubectl get pods -l=app=kcl-consumer -w# check logs of the new pod
kubectl logs -f <enter Pod name>我们的应用程序能够根据 ScaledObject 定义中的 shardCount: "1" 自动扩展到两个 Pod。这意味着 Kinesis 流中的每个 shard 都会有一个 Pod。
在 DynamoDB 中检查 kinesis-keda-demo 控制表:您应该看到 leaseOwner 的更新。
让我们向 Kinesis 流发送更多的数据。
export KINESIS_STREAM=kinesis-keda-demoaws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user5@foo.com --data $(echo -n '{"name":"user5", "city":"new york"}' | base64)
aws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user6@foo.com --data $(echo -n '{"name":"user6", "city":"tel aviv"}' | base64)
aws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user7@foo.com --data $(echo -n '{"name":"user7", "city":"new delhi"}' | base64)
aws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user8@foo.com --data $(echo -n '{"name":"user8", "city":"seattle"}' | base64)验证 "processed_by" 属性的值。由于我们已经扩展到两个 Pod,每条记录的值应该不同,因为每个 Pod 将处理 Kinesis 流的一部分记录。
增加 Kinesis 流容量
让我们将 shard 的数量从两个扩展到三个,并继续监视 KCL 应用程序的自动缩放。
aws kinesis update-shard-count --stream-name kinesis-keda-demo --target-shard-count 3 --scaling-type UNIFORM_SCALING一旦 Kinesis 重新划分完成,KEDA 扩展器将开始工作,将 KCL 应用程序扩展到三个 Pod。
kubectl get pods -l=app=kcl-consumer -w就像之前一样,确认在 DynamoDB 的 kinesis-keda-demo 控制表中,Kinesis shard 的租约已更新。检查 leaseOwner 属性。
继续向 Kinesis 流发送更多数据。正如预期的那样,Pod 将共享记录处理,并且在 users 表中的 processed_by 属性中会反映出来。
export KINESIS_STREAM=kinesis-keda-demoaws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user9@foo.com --data $(echo -n '{"name":"user9", "city":"new york"}' | base64)
aws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user10@foo.com --data $(echo -n '{"name":"user10", "city":"tel aviv"}' | base64)
aws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user11@foo.com --data $(echo -n '{"name":"user11", "city":"new delhi"}' | base64)
aws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user12@foo.com --data $(echo -n '{"name":"user12", "city":"seattle"}' | base64)
aws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user14@foo.com --data $(echo -n '{"name":"user14", "city":"tel aviv"}' | base64)
aws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user15@foo.com --data $(echo -n '{"name":"user15", "city":"new delhi"}' | base64)
aws kinesis put-record --stream-name $KINESIS_STREAM --partition-key user16@foo.com --data $(echo -n '{"name":"user16", "city":"seattle"}' | base64)缩小规模
到目前为止,我们只进行了单向的扩展。当我们减少 Kinesis 流的分片容量时会发生什么?自己尝试一下:将分片数量从三个减少到两个,观察 KCL 应用的情况。
一旦您验证了端到端的解决方案,应清理资源,以避免产生额外的费用。
▌删除资源
删除 EKS 集群、Kinesis 流和 DynamoDB 表。
eksctl delete cluster --name keda-kinesis-demoaws kinesis delete-stream --stream-name kinesis-keda-demoaws dynamodb delete-table --table-name users
▌结论
在本文中,您学习了如何使用 KEDA 自动扩展从 Kinesis 流中消费数据的 KCL 应用程序。
您可以根据应用程序的要求配置 KEDA 扩展器。例如,您可以将 shardCount 设置为 3,并为 Kinesis 流中的每三个分片设置一个 Pod。但是,如果您希望保持一对一的映射关系,可以将 shardCount 设置为 1,KCL 将负责分布式协调和租约分配,确保每个 Pod 具有一个记录处理器的实例。这是一种有效的方法,可以根据应用程序的需求扩展 Kinesis 流处理管道,以满足需求。
作者:Abhishek Gupta
更多技术干货请关注公号“云原生数据库”
squids.cn,基于公有云基础资源,提供云上 RDS,云备份,云迁移,SQL 窗口门户企业功能,
帮助企业快速构建云上数据库融合生态。