http://erlang.org/doc/design_principles/des_princ.html
图和代码皆源自以上链接中Erlang官方文档,翻译时的版本为20.1。
这个设计原则,其实是说用户在设计系统的时候应遵循的标准和规范。阅读前我一直以为写的是作者在设计 Erlang/OTP 框架时的一些原则。
闲话少叙。Let's go!
1.概述
OTP设计原则规定了如何使用进程、模块和目录来组织 Erlang 代码。
1.1 监控树
Erlang/OTP的一个基本概念就是监控树。它是基于 workers(工人)和 supervisors(监工、监程)的进程组织模型。
- Workers 是实际执行运算的进程。
- Supervisors 是负责监控 workers 的进程。如果 worker 发生异常,supervisor 可以重启这个 worker。
- 监控树就是由 supervisors 和 workers 组成的层次结构,让我们可以设计和编写容错的软件。
下图中方块表示 supervisor,圆圈表示 worker(图源Erlang官方文档):

图1.1: 监控树
1.2 Behaviours(行为模式)
在监控树中,很多进程拥有一样的结构,遵循一样的行为模式。例如,supervisors 结构上都是一样的,唯一的不同就是他们监控的子进程不同。而很多 wokers 都是以 server/client、finite-state machines(有限状态自动机)或是 error logger(错误记录器)之类的事件处理器的行为模式运行。
Behaviour就是把这些通用行为模式形式化。也就是说,把进程的代码分成通用的部分(behaviour 模块)和专有的部分(callback module 回调模块).
Behaviour 是 Erlang/OTP 框架中的一部分。用户如果要实现一个进程(例如一个 supervisor),只需要实现回调模块,然后导出预先定义的函数集(回调函数)就行了。
下面的例子表明了怎么把代码分成通用部分和专有部分。我们把下面的代码当作是一个简单的服务器(用普通Erlang编写),用来记录 channel 集合。其他进程可以各自通过调用函数 alloc/0 和 fee/1 来分配和释放 channel。
-module(ch1). -export([start/0]). -export([alloc/0, free/1]). -export([init/0]).start() ->spawn(ch1, init, []).alloc() ->ch1 ! {self(), alloc},receive{ch1, Res} ->Resend.free(Ch) ->ch1 ! {free, Ch},ok.init() ->register(ch1, self()),Chs = channels(),loop(Chs).loop(Chs) ->receive{From, alloc} ->{Ch, Chs2} = alloc(Chs),From ! {ch1, Ch},loop(Chs2);{free, Ch} ->Chs2 = free(Ch, Chs),loop(Chs2)end.
这个服务器可以重写成一个通用部分 server.erl :
-module(server). -export([start/1]). -export([call/2, cast/2]). -export([init/1]).start(Mod) ->spawn(server, init, [Mod]).call(Name, Req) ->Name ! {call, self(), Req},receive{Name, Res} ->Resend.cast(Name, Req) ->Name ! {cast, Req},ok.init(Mod) ->register(Mod, self()),State = Mod:init(),loop(Mod, State).loop(Mod, State) ->receive{call, From, Req} ->{Res, State2} = Mod:handle_call(Req, State),From ! {Mod, Res},loop(Mod, State2);{cast, Req} ->State2 = Mod:handle_cast(Req, State),loop(Mod, State2)end.
和一个回调模块 ch2.erl :
-module(ch2). -export([start/0]). -export([alloc/0, free/1]). -export([init/0, handle_call/2, handle_cast/2]).start() ->server:start(ch2).alloc() ->server:call(ch2, alloc).free(Ch) ->server:cast(ch2, {free, Ch}).init() ->channels().handle_call(alloc, Chs) ->alloc(Chs). % => {Ch,Chs2}handle_cast({free, Ch}, Chs) ->free(Ch, Chs). % => Chs2
注意以下几点:
- server 的代码可以重用来构建不同的服务器。
- server 名字(在这个例子中是 ch2)对用户函数来说是透明的。即,修改名字不会影响函数调用。
- 协议(server 发送和接受到的消息)也是透明的。这是一个好的编码惯例,修改协议不会影响到调用接口函数的代码。
- 扩展 server 的功能不需要改变 ch2 或其他回调模块。
上面的 ch1.erl 和 ch2.erl 中,channels/0, alloc/1 和 free/2 的实现被刻意遗漏,因为与本例无关。完整性起见,下面给出这些函数的一种实现方式。这只是个示例,现实中还必须能够处理诸如 channel 用完无法分配等情况。
channels() ->{_Allocated = [], _Free = lists:seq(1,100)}.alloc({Allocated, [H|T] = _Free}) ->{H, {[H|Allocated], T}}.free(Ch, {Alloc, Free} = Channels) ->case lists:member(Ch, Alloc) oftrue ->{lists:delete(Ch, Alloc), [Ch|Free]};false ->Channelsend.
没有使用 behaviour 的代码可能效率更高,但是通用性差。将系统中的所有 applications 组织成一致的行为模式很重要。
而且使用 behaviour 能让代码易读易懂。简易的程序结构可能会更有效率,但是比较难理解。
上面的 server 模块其实就是一个简化的 Erlang/OTP behaviour - gen_server。
Erlang/OTP的标配 behaviour 有:
- gen_server 实现 client/server 模式的服务器
- gen_statem 实现状态机(译者补充:旧版本中为 gen_fsm)
- gen_event 实现事件处理器
- supervisor 实现监控树中的监控者
编译器能识别模块属性 -behaviour(Behaviour) ,会对未实现的回调函数发出编译警告,例如:
-module(chs3). -behaviour(gen_server). ...3> c(chs3). ./chs3.erl:10: Warning: undefined call-back function handle_call/3 {ok,chs3}
1.3 Applications
Erlang/OTP 自带一些组件,每个组件实现了特定的功能。这些组件用 Erlang/OTP 术语叫做 application(应用)。例如 Mnesia 就是一个Erlang/OTP 应用,它包含了所有数据库服务所需的功能,还有 Debugger,用来 debug Erlang 代码。基于 Erlang/OTP 的系统,至少必须包含下面两个 application:
- Kernel - 运行 Erlang 时必须的功能
- STDLIB - Erlang 标准库
应用的概念适用于程序结构(进程)和目录结构(模块)。
最简单的应用由一组功能模块组成,不包含任何进程,这种叫 library application(库应用)。STDLIB 就属于这类。
有进程的应用可以使用标准 behaviour 很容易地实现一个监控树。
如何编写应用详见后文 Applications。
1.4 Releases(发布版本)
一个 release 是一个完整的系统,包含 Erlang/OTP 应用的子集和一系列用户定义的 application。
详见后文 Releases。
怎么在目标环境中部署 release 在系统原则的文档中有讲到。
1.5 Release Handling(管理发布)
管理 release 即在一个 release 的不同版本之间升级或降级,怎么在一个运行中的系统操作这些,详见后文 Release Handling。
2 gen_server Behaviour
这部分可与 stdblib 中的 gen_server(3) 教程(包含了 gen_server 所有接口函数和回调函数)一起阅读。
2.1 Client-Server 原则
C/S模型就是一个服务器对应任意多个客户端。C/S模型是用来进行资源管理,多个客户端想分享一个公共资源。而服务器则用来管理这个资源。
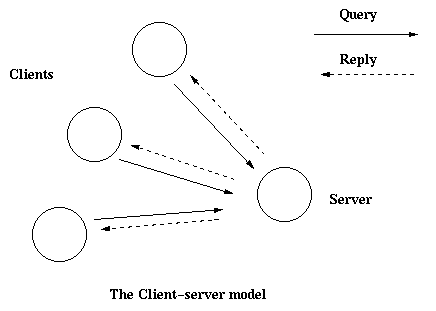
图 2.1: Client-Server Model
2.2 例子
前文有用普通 erlang 写的简单的服务器的例子。使用 gen_server 重写,结果如下:
-module(ch3). -behaviour(gen_server).-export([start_link/0]). -export([alloc/0, free/1]). -export([init/1, handle_call/3, handle_cast/2]).start_link() ->gen_server:start_link({local, ch3}, ch3, [], []).alloc() ->gen_server:call(ch3, alloc).free(Ch) ->gen_server:cast(ch3, {free, Ch}).init(_Args) ->{ok, channels()}.handle_call(alloc, _From, Chs) ->{Ch, Chs2} = alloc(Chs),{reply, Ch, Chs2}.handle_cast({free, Ch}, Chs) ->Chs2 = free(Ch, Chs),{noreply, Chs2}.
下一小节将解释这段代码。
2.3 启动一个 gen_server
在上一小节的示例中,gen_server 通过调用 ch3:start_link() 启动:
start_link() ->gen_server:start_link({local, ch3}, ch3, [], []) => {ok, Pid} start_link 调用了函数 gen_server:start_link/4 ,这个函数产生并连接了一个新进程(一个 gen_server)。
- 第一个参数,{local, ch3},指定了进程名,gen_server 会在本地注册为 ch3。
如果名字被省略,gen_server 不会被注册,此时一定要用它的 pid。名字还可以用 {global, Name},这样的话 gen_server 会调用 global:register_name/2 来注册。
- 第二个参数,ch3,是回调模块的名字,即回调函数所在的模块名。
接口函数 (start_link, alloc 和 free) 和回调函数 (init, handle_call 和 handle_cast) 放在同一个模块中。这是一个好的编程惯例,把与一个进程相关的代码放在同一个模块中。
- 第三个参数,[],是用来传递给回调函数 init 的参数。此例中 init 不需要输入,所以忽视了这个参数。
- 第四个参数,[],是一个选项list。查看 gen_server(3) 可获悉可用选项。
如果名字注册成功,这个新的 gen_server 进程会调用回调函数 ch3:init([]) 。init 函数应该返回 {ok, State},其中 State 是 gen_server 的内部状态,在此例中,内部状态指的是 channel 集合。
init(_Args) ->{ok, channels()}. gen_server:start_link 是同步调用,在 gen_server 初始化成功可接收请求之前它不会返回。
如果 gen_server 是一个监控树的一部分,supervisor 启动 gen_server 时一定要使用 gen_server:start_link。还有一个函数是 gen_server:start ,这个函数会启动一个独立的 gen_server,也就是说它不会成为监控树的一部分。
2.4 同步消息请求 - Call
同步的请求 alloc() 是用 gen_server:call/2 来实现的:
alloc() ->gen_server:call(ch3, alloc). ch3 是 gen_server 的名字,要与进程名字相符合才能使用。alloc 是实际的请求。
这个请求会被转化成一个消息,发送给 gen_server。收到消息后,gen_server 调用 handle_call(Request, From, State) 来处理消息,正常会返回 {reply, Reply, State1}。Reply 是会发回给客户端的回复内容,State1 是 gen_server 新的内部状态。
handle_call(alloc, _From, Chs) ->{Ch, Chs2} = alloc(Chs),{reply, Ch, Chs2}.
此例中,回复内容就是分配给它的 channel Ch,而新的内部状态是剩余的 channel 集合 Chs2。
就这样,ch3:alloc() 返回了分配给它的 channel Ch,gen_server 则保存剩余的 channel 集合,继续等待新的请求。
2.5 异步消息请求 - Cast
异步的请求 free(Ch) 是用 gen_server:cast/2 来实现的:
free(Ch) ->gen_server:cast(ch3, {free, Ch}). ch3 是 gen_server 的名字,{free, Ch} 是实际的请求。
这个请求会被转化成一个消息,发送给 gen_server。发送后直接返回 ok。
收到消息后,gen_server 调用 handle_cast(Request, State) 来处理消息,正常会返回 {noreply,State1}。State1 是 gen_server 新的内部状态。
handle_cast({free, Ch}, Chs) ->Chs2 = free(Ch, Chs),{noreply, Chs2}. 此例中,新的内部状态是新的剩余的 channel集合 Chs2。然后 gen_server 继续等待新的请求。
2.6 终止
在监控树中
如果 gen_server 是监控树的一部分,则不需要终止函数。gen_server 会自动被它的监控者终止,具体怎么终止通过 终止策略 来决定。
如果要在终止前进行一些操作,终止策略必须有一个 time-out 值,且 gen_server 必须在 init 函数中被设置为捕捉 exit 信号。当被要求终止时,gen_server 会调用回调函数 terminate(shutdown, State):
init(Args) ->...,process_flag(trap_exit, true),...,{ok, State}....terminate(shutdown, State) ->..code for cleaning up here..ok.
独立的 gen_server
如果 gen_server 不是监控树的一部分,可以写一个 stop 函数,例如:
... export([stop/0]). ...stop() ->gen_server:cast(ch3, stop). ...handle_cast(stop, State) ->{stop, normal, State}; handle_cast({free, Ch}, State) ->.......terminate(normal, State) ->ok.
处理 stop 消息的回调函数返回 {stop, normal, State1},normal 意味着这是一次自然死亡,而 State1 是一个新的 gen_server 内部状态。这会导致 gen_server 调用 terminate(normal, State1) 然后优雅地……挂掉。
2.7 处理其他消息
如果 gen_server 会在除了请求之外接收其他消息,需要实现回调函数 handle_info(Info, State) 来进行处理。其他消息可能是 exit 消息,如果 gen_server 与其他进程连接起来(不是 supervisor),并且被设置为捕捉 exit 信号。
handle_info({'EXIT', Pid, Reason}, State) ->..code to handle exits here..{noreply, State1}. 一定要实现 code_change 函数。(译者补充:在代码热更新时会用到)
code_change(OldVsn, State, Extra) ->..code to convert state (and more) during code change{ok, NewState}.
3 gen_statem Behavior
此章可结合 gen_statem(3) (包含全部接口函数和回调函数的详述)教程一起看。
注意:这是 Erlang/OTP 19.0 引入的新 behavior。它已经经过了完整的 review,稳定使用在至少两个大型 OTP 应用中并被保留下来。基于用户反馈,我们觉得有必要在 Erlang/OTP 20.0 对它进行小调整(不向后兼容)。
3.1 事件驱动的状态机
现在的自动机理论没有具体描述状态变迁是如何触发的,而是假定输出是一个以输入和当前状态为参数的函数,它们是某种类型的值。
对一个事件驱动的状态机来说,输入就是一个触发状态变迁的事件,输出是状态迁移过程中执行的动作。用类似有限状态自动机的数学模型来描述,它是一系列如下形式的关系:
State(S) x Event(E) -> Actions(A), State(S')
这些关系可以这么理解:如果我们现在处于 S 状态,事件 E 发生了,我们就要执行动作 A 并且转移状态为 S' 。注意: S’ 可能与 S 相同。
由于 A 和 S' 只取决于 S 和 E,这种状态机被称为 Mealy 机(可参见维基百科的描述)。
跟大多数 gen_ 开头的 behavior 一样, gen_statem 保存了 server 的数据和状态。而且状态数是没有限制的(假设虚拟机内存足够),输入事件类型数也是没有限制的,因此用这个 behavior 实现的状态机实际上是图灵完备的。不过感觉上它更像一个事件驱动的 Mealy 机。
3.2 回调模式
gen_statem 支持两种回调模式:
- state_functions 方式,状态迁移规则以 erlang 函数的形式编写,写法如下:
StateName(EventType, EventContent, Data) ->... code for actions here ...{next_state, NewStateName, NewData}. 在示例部分用的最多的就是这种格式。
- handle_event_function 方式,只用一个 erlang 函数来装载所有的状态迁移规则:
handle_event(EventType, EventContent, State, Data) ->... code for actions here ...{next_state, NewState, NewData} 示例可见单个事件处理器这一小节。
这两种函数都支持其他的返回值,具体可见 gen_statem 的教程页面的 Module:StateName/3。其他的返回元组可以停止状态机、在状态机引擎中执行转移动作、发送回复等等。
选择何种回调方式
这两种回调方式有不同的功能和限制,但是目标都一样:要处理所有可能的事件和状态的组合。
你可以同时只关心一种状态,确保每个状态都处理了所有事件。或者只关心一个事件,确保它在所有状态下都被处理。你也可以结合两种策略。
state_functions 方式中,状态只能用 atom 表示,gen_statem 引擎通过状态名来分发处理。它提倡回调模块把一个状态下的所有事件和动作放在代码的同一个地方,以此同时只关注一个状态。
当你的状态图确定时,这种模式非常好。就像本小节举的例子,状态对应的事件和动作都放在一起,每个状态有自己独一无二的名字。
而通过 handle_event_function 方式,可以结合两种策略,因为所有的事件和状态都在同一个回调函数中。
无论是想以状态还是事件为中心,这种方式都能满足。不过没有分发到辅助函数的话,Module:handle_event/4 会迅速增长到无法管理。
3.3 状态enter回调
不论回调模式是哪种,gen_statem 都会在状态改变的时候(译者补充:进入状态的时候调用)自动调用回调函数(call the state callback),所以你可以在状态的转移规则附近写状态入口回调。通常长这样:
StateName(enter, _OldState, Data) ->... code for state entry actions here ...{keep_state, NewData}; StateName(EventType, EventContent, Data) ->... code for actions here ...{next_state, NewStateName, NewData}.
这可能会在特定情况下很有帮助,不过它要求你在所有状态中都处理入口回调。详见 State Entry Actions。
3.4 动作(Actions)
在第一小节事件驱动的状态机中,动作(action)作为通用状态机模型的一部分被提及。一般的动作会在 gen_statem 处理事件的回调中执行(返回到 gen_statem 引擎之前)。
还有一些特殊的状态迁移动作,在回调函数返回后指定 gen_statem 引擎去执行。回调函数可以在返回的元组中指定一个动作列表。这些动作影响 gen_statem 引擎本身,可以做下列事情:
- 延缓(postpone)当前事件, 详见延缓事件
- 挂起(hibernate)状态机,详见挂起
- 状态超时(state time-out),详见状态超时
- 一般超时(generic time-out),详见一般超时
- 事件超时(event time-out),详见事件超时
- 回复调用者,详见全状态事件
- 生成下一个要处理的事件,详见自生成事件
详见 gen_statem(3) 。你可以回复很多调用者、生成多个后续事件、设置相对时间或绝对时间的超时等等。
3.5 事件类型
事件分成不同的类型(event types)。同状态下的不同类型的事件都在同一个回调函数中处理,回调函数以 EventType 和 EventContent 作为参数。
下面列出事件类型和来源的完整列表:
cast
由 gen_statem:cast 生成。
{call, From}
由 gen_statem:call 生成,状态迁移动作返回 {reply, From, Msg} 或调用 gen_statem:reply 时,会用到 From 作为回复地址。
info
发送给 gen_statem 进程的常规进程消息。
state_timeout
状态迁移动作 {state_timeout,Time,EventContent} 生成。
- {timeout,Name}
状态迁移动作 {{timeout,Name},Time,EventContent} 生成。
timeout
状态迁移动作 {timeout,Time,EventContent}(或简写为 Time)生成。
internal
状态迁移动作 {next_event,internal,EventContent} 生成。
上述所有事件类型都可以用 {next_event,EventType,EventContent} 来生成。
3.6 示例
密码锁的门可以用一个自动机来表述。初始状态,门是锁住的。当有人按一个按钮,即触发一个事件。结合此前按下的按钮,结果可能是正确、不完整或者错误。如果正确,门锁会开启10秒钟(10,000毫秒)。如果不完整,则等待下一个按钮被按下。如果错了,一切从头再来,等待新一轮按钮。

图3.1: 密码锁状态图
密码锁状态机用 gen_statem 实现,回调模块如下:
-module(code_lock). -behaviour(gen_statem). -define(NAME, code_lock).-export([start_link/1]). -export([button/1]). -export([init/1,callback_mode/0,terminate/3,code_change/4]). -export([locked/3,open/3]).start_link(Code) ->gen_statem:start_link({local,?NAME}, ?MODULE, Code, []).button(Digit) ->gen_statem:cast(?NAME, {button,Digit}).init(Code) ->do_lock(),Data = #{code => Code, remaining => Code},{ok, locked, Data}.callback_mode() ->state_functions.locked(cast, {button,Digit},#{code := Code, remaining := Remaining} = Data) ->case Remaining of[Digit] ->do_unlock(),{next_state, open, Data#{remaining := Code},[{state_timeout,10000,lock}]};[Digit|Rest] -> % Incomplete{next_state, locked, Data#{remaining := Rest}};_Wrong ->{next_state, locked, Data#{remaining := Code}}end.open(state_timeout, lock, Data) ->do_lock(),{next_state, locked, Data}; open(cast, {button,_}, Data) ->{next_state, open, Data}.do_lock() ->io:format("Lock~n", []). do_unlock() ->io:format("Unlock~n", []).terminate(_Reason, State, _Data) ->State =/= locked andalso do_lock(),ok. code_change(_Vsn, State, Data, _Extra) ->{ok, State, Data}.
下一小节解释代码。
3.7 启动状态机
前例中,可调用 code_lock:start_link(Code) 来启动 gen_statem:
start_link(Code) ->gen_statem:start_link({local,?NAME}, ?MODULE, Code, []). start_link 函数调用 gen_statem:start_link/4,生成并连接了一个新进程(gen_statem)。
- 第一个参数,{local, ?NAME} 指定了名字。在此例中 gen_statem 在本地注册为 code_lock(?NAME)。如果名字被省略,gen_statem 不会被注册,此时必须用它的 pid。名字还可以用{global, Name},这样的话 gen_server 会调用 global:register_name/2 来注册。
- 第二个参数,?MODULE,这个参数就是回调模块的名字,此例的回调模块就是当前模块。接口函数(start_link/1 和 button/1)与回调函数(init/1, locked/3, 和 open/3)放在同一个模块中。这是一个好的编程惯例,把 client 和 server 的代码放在同一个模块中。
- 第三个参数,Code,是一串数字,存储了正确的门锁密码,将被传递给 init/1 函数。
- 第四个参数,[],是一个选项list。查看 gen_statem:start_link/3 可获悉可用选项。
如果名字注册成功,这个新的 gen_statem 进程会调用 init 回调 code_lock:init(Code)。init 函数应该返回 {ok, State, Data},其中 State 是初始状态(此例中是锁住状态,假设门一开始是锁住的)。Data 是 gen_statem 的内部数据。此例中 Data 是一个map,其中 code 对应的是正确的密码,remaining 对应的是按钮按对后剩余的密码(初始与 code 一致)。
init(Code) ->do_lock(),Data = #{code => Code, remaining => Code},{ok,locked,Data}.
gen_statem:start_link 是同步调用,在 gen_statem 初始化成功可接收请求之前它不会返回。
如果 gen_statem 是一个监控树的一部分,supervisor 启动 gen_statem 时一定要使用 gen_statem:start_link。还有一个函数是 gen_statem:start ,这个函数会启动一个独立的 gen_statem,也就是说它不会成为监控树的一部分。
callback_mode() ->state_functions. 函数 Module:callback_mode/0 规定了回调模块的回调模式,此例中是 state_functions 模式,每个状态有自己的处理函数。
3.8 事件处理
通知 code_lock 按钮事件的函数是用 gen_statem:cast/2 实现的:
button(Digit) ->gen_statem:cast(?NAME, {button,Digit}). 第一个参数是 gen_statem 的名字,要与进程名字相同,所以我们用了同样的宏 ?NAME。{button, Digit} 是事件的内容。
这个事件会被转化成一个消息,发送给 gen_statem。当收到事件时, gen_statem 调用 StateName(cast, Event, Data),一般会返回一个元组 {next_state, NewStateName, NewData}。StateName 是当前状态名,NewStateName是下一个状态。NewData 是 gen_statem 的新的内部数据,Actions 是 gen_statem 引擎要执行的动作列表。
locked(cast, {button,Digit},#{code := Code, remaining := Remaining} = Data) ->case Remaining of[Digit] -> % Completedo_unlock(),{next_state, open, Data#{remaining := Code},[{state_timeout,10000,lock}]};[Digit|Rest] -> % Incomplete{next_state, locked, Data#{remaining := Rest}};[_|_] -> % Wrong{next_state, locked, Data#{remaining := Code}}end.open(state_timeout, lock, Data) ->do_lock(),{next_state, locked, Data}; open(cast, {button,_}, Data) ->{next_state, open, Data}.
如果门是锁着的,按钮被按下,比较输入按钮和正确的按钮。根据比较的结果,如果锁开了,gen_statem 变为 open 状态,否则继续保持 locked 状态。
如果按钮是错的,数据又变为初始的密码列表。
状态为 open 时,按钮事件会被忽略,状态维持不变。还可以返回 {keep_state, Data} 表示状态不变或者返回 keep_state_and_data 表示状态和数据都不变。
3.9 状态超时
当给出正确的密码,门锁开启,locked/2 返回如下元组:
{next_state, open, Data#{remaining := Code},[{state_timeout,10000,lock}]}; 10,000 是以毫秒为单位的超时时长。10秒后,会触发一个超时,然后 StateName(state_timeout, lock, Data) 被调用,此后门重新锁住:
open(state_timeout, lock, Data) ->do_lock(),{next_state, locked, Data}; 状态超时会在状态改变的时候自动取消。重新设置一个状态超时相当于重启,旧的定时器被取消,新的定时器被启动。也就是说可以通过重启一个时间为 infinite 的超时来取消状态超时。
3.10 全状态事件
有些事件可能在任何状态下到达 gen_statem。可以在一个公共的函数处理这些事件,所有的状态函数都调用它来处理通用的事件。
假定一个 code_length/0 函数返回正确密码的长度(不敏感的信息)。我们把所有与状态无关的事件分发到公共函数 handle_event/3:
... -export([button/1,code_length/0]). ...code_length() ->gen_statem:call(?NAME, code_length).... locked(...) -> ... ; locked(EventType, EventContent, Data) ->handle_event(EventType, EventContent, Data).... open(...) -> ... ; open(EventType, EventContent, Data) ->handle_event(EventType, EventContent, Data).handle_event({call,From}, code_length, #{code := Code} = Data) ->{keep_state, Data, [{reply,From,length(Code)}]}.
此例使用 gen_statem:call/2,调用者会等待 server 的回复。{reply,From,Reply} 元组表示回复,{keep_state, ...} 用来保持状态不变。这个返回格式在你想保持状态不变(不管状态是什么)的时候非常方便。
3.11 单个事件处理器
如果使用 handle_event_function 模式,所有的事件都会在 Module:handle_event/4 被处理,我们可以(也可以不)在第一层以事件为中心进行分组,然后再判断状态:
... -export([handle_event/4]).... callback_mode() ->handle_event_function.handle_event(cast, {button,Digit}, State, #{code := Code} = Data) ->case State oflocked ->case maps:get(remaining, Data) of[Digit] -> % Completedo_unlock(),{next_state, open, Data#{remaining := Code},[{state_timeout,10000,lock}]};[Digit|Rest] -> % Incomplete{keep_state, Data#{remaining := Rest}};[_|_] -> % Wrong{keep_state, Data#{remaining := Code}}end;open ->keep_state_and_dataend; handle_event(state_timeout, lock, open, Data) ->do_lock(),{next_state, locked, Data}....
3.12 终止
在监控树中
如果 gen_statem 是监控树的一部分,则不需要终止函数。gen_statem 自动的被它的监控者终止,具体怎么终止通过 终止策略 来决定。
如果需要在终止前进行一些操作,那么终止策略必须有一个 time-out 值,且 gen_statem 必须在 init 函数中被设置为捕捉 exit 信号,调用 process_flag(trap_exit, true):
init(Args) ->process_flag(trap_exit, true),do_lock(),... 当被要求终止时,gen_statem 会调用回调函数 terminate(shutdown, State, Data):
terminate(_Reason, State, _Data) ->State =/= locked andalso do_lock(),ok.
独立的 gen_statem
如果 gen_statem 不是监控树的一部分,可以写一个 stop 函数(使用 gen_statem:stop)。建议增加一个 API :
...
-export([start_link/1,stop/0])....
stop() -> gen_statem:stop(?NAME). 这会导致 gen_statem 调用 terminate/3(像监控树中的服务器被终止一样),等待进程终止。
3.13 事件超时
事件超时功能继承自 gen_statem 的前辈 gen_fsm ,事件超时的定时器在有事件达到的时候就会被取消。你可以接收到一个事件或者一个超时,但不会两个都收到。
事件超时由状态迁移动作 {timeout,Time,EventContent} 指定,或者仅仅是 Time, 或者仅仅一个 Timer 而不是动作列表(继承自 gen_fsm)。
不活跃情况下想做点什么时,可以用此类超时。如果30秒内没人按钮,重置密码列表:
...locked(timeout, _, #{code := Code, remaining := Remaining} = Data) ->{next_state, locked, Data#{remaining := Code}}; locked(cast, {button,Digit},#{code := Code, remaining := Remaining} = Data) -> ...[Digit|Rest] -> % Incomplete{next_state, locked, Data#{remaining := Rest}, 30000}; ...
接收到任意按钮事件时,启动一个30秒超时,如果接收到超时事件就重置密码列表。
接收到其他事件时,事件超时会被取消,所以要么接收到其他事件要么接受到超时事件。所以不能也不必要重启一个事件超时。因为你处理的任何事件都会取消事件超时。
3.14 一般超时
前面说的状态超时只在状态不改变时有效。而事件超时只在不被其他事件打断的时候生效。
你可能想要在某个状态下开启一个定时器,而在另一个状态下做处理,想要不改变状态就取消一个定时器,或者希望同时存在多个定时器。这些都可以用过 generic time-outs 一般超时来实现。它们看起来有点像事件超时,但是它们有名字,不同名字的可以同时存在多个,并且不会被自动取消。
下面是用一般超时实现来替代状态超时的例子,定时器名字是 open_tm :
... locked(cast, {button,Digit},#{code := Code, remaining := Remaining} = Data) ->case Remaining of[Digit] ->do_unlock(),{next_state, open, Data#{remaining := Code},[{{timeout,open_tm},10000,lock}]}; ...open({timeout,open_tm}, lock, Data) ->do_lock(),{next_state,locked,Data}; open(cast, {button,_}, Data) ->{keep_state,Data}; ...
和状态超时一样,可以通过给特定的名字设置新的定时器或设置为infinite来取消定时器。
也可以不取消失效的定时器,而是在它到来的时候忽略它(确定已无用时)。
3.15 Erlang 定时器
最全面的处理超时的方式就是使用 erlang 的定时器,详见 erlang:start_timer3,4。大部分的超时任务可以通过 gen_statem 的超时功能来完成,但有时候你可能想获取 erlang:cancel_timer(Tref) 的返回值(剩余时间)。
下面是用 erlang 定时器替代前文状态超时的实现:
... locked(cast, {button,Digit},#{code := Code, remaining := Remaining} = Data) ->case Remaining of[Digit] ->do_unlock(),Tref = erlang:start_timer(10000, self(), lock),{next_state, open, Data#{remaining := Code, timer => Tref}}; ...open(info, {timeout,Tref,lock}, #{timer := Tref} = Data) ->do_lock(),{next_state,locked,maps:remove(timer, Data)}; open(cast, {button,_}, Data) ->{keep_state,Data}; ...
当状态迁移到 locked 时,我们可以不从 Data 中清除 timer 的值,因为每次进入 open 状态都是一个新的 timer 值。不过最好不要在 Data 中保留过期的值。
当其他事件触发,你想清除一个 timer 时,可以使用 erlang:cancel_timer(Tref) 。如果没有延缓(下一小节会讲到),超时消息被 cancel 后就不会再被收到,所以要确认是否一不小心延缓了这类消息。要注意的是,超时消息可能在你 cancel 它之前就到达,所以要根据 erlang:cancel_timer(Tref) 的返回值,把这消息从进程邮箱里读出来。
另一种处理方式是,不要 cancel 掉一个 timer,而是在它到达之后忽略它。
3.16 延缓事件
如果你想在当前状态忽略某个事件,在后续的某个状态中再处理,你可以延缓这个事件。延缓的事件会在状态变化后重新触发,即:OldState =/= NewState 。
延缓是通过状态迁移动作 postpone 来指定的。
此例中,我们可以延缓在 open 状态下的按钮事件(而不是忽略它),这些事件会进入等待队列,等到 locked 状态时再处理:
... open(cast, {button,_}, Data) ->{keep_state,Data,[postpone]}; ...
延缓的事件只会在状态改变时重新触发,因此要考虑怎么保存内部数据。内部数据可以在数据 Data 或者状态 State 中保存,比如用两个几乎一样的状态来表示布尔值,或者使用一个复合状态(回调模块的 handle_event_function)。如果某个值的变化会改变事件处理,那需要把这个值保存在状态 State 里。因为 Data 的变化不会触发延缓的事件。
如果你没有用延缓的话,这个不重要。但是如果你决定使用延缓功能,没有用不同的状态做区分,可能会产生很难发现的 bug。
模糊的状态图
状态图很可能没有给特定的状态指定事件处理方式。可能在相关的上下文中有提及。
可能模糊的动作(译者补充:在状态图中没有给出处理方式,可能对应的动作):忽略(丢弃或者仅仅 log)事件、延缓事件至其他状态处理。
选择性 receive
Erlang 的选择性 receive 语句经常被用来写简单的状态机(不用 gen_statem 的普通 erlang 代码)。下面是可能的实现方式之一:
-module(code_lock). -define(NAME, code_lock_1). -export([start_link/1,button/1]).start_link(Code) ->spawn(fun () ->true = register(?NAME, self()),do_lock(),locked(Code, Code)end).button(Digit) ->?NAME ! {button,Digit}.locked(Code, [Digit|Remaining]) ->receive{button,Digit} when Remaining =:= [] ->do_unlock(),open(Code);{button,Digit} ->locked(Code, Remaining);{button,_} ->locked(Code, Code)end.open(Code) ->receiveafter 10000 ->do_lock(),locked(Code, Code)end.do_lock() ->io:format("Locked~n", []). do_unlock() ->io:format("Open~n", []).
此例中选择性 receive 隐含了把 open 状态接收到的所有事件延缓到 locked 状态的逻辑。
选择性 receive 语句不能用在 gen_statem 或者任何 gen_* 中,因为 receive 语句已经在 gen_* 引擎中包含了。为了兼容 sys ,behavior 进程必须对系统消息作出反应,并把非系统的消息传递给回调模块,因此把 receive 集成在引擎层的 loop 里。
动作 postpone(延缓)是被设计来模拟选择性 receive 的。选择性 receive 隐式地延缓所有不被接受的事件,而 postpone 动作则是显示地延缓一个收到的事件。
两种机制逻辑复杂度和时间复杂度是一样的,而选择性 receive 语法的常因子更少。
3.17 entry动作
假设你有一张状态图,图中使用了状态 entry 动作。只有一两个状态有 entry 动作时你可以用自生成事件(详见下一部分),但是使用内置的状态enter回调是更好的选择。
在 callback_mode/0 函数的返回列表中加入 state_enter,会在每次状态改变的时候传入参数 (enter, OldState, ...) 调用一次回调函数。你只需像事件一样处理这些请求即可:
... init(Code) ->process_flag(trap_exit, true),Data = #{code => Code},{ok, locked, Data}.callback_mode() ->[state_functions,state_enter].locked(enter, _OldState, Data) ->do_lock(),{keep_state,Data#{remaining => Code}}; locked(cast, {button,Digit},#{code := Code, remaining := Remaining} = Data) ->case Remaining of[Digit] ->{next_state, open, Data}; ...open(enter, _OldState, _Data) ->do_unlock(),{keep_state_and_data, [{state_timeout,10000,lock}]}; open(state_timeout, lock, Data) ->{next_state, locked, Data}; ...
你可以返回 {repeat_state, ...} 、{repeat_state_and_data,_} 或 repeat_state_and_data 来重复执行 entry 代码,这些词其他含义跟 keep_state 家族一样(保持状态、数据不变等等)。详见 state_callback_result() 。
3.18 自生成事件
有时候可能需要在状态机中生成事件,可以用状态迁移动作 {next_event,EventType,EventContent} 来实现。
你可以生成所有类型(type)的事件。其中 internal 类型只能通过 next_event 来生成,不会由外部产生,你可以确定一个 internal 事件是来自状态机自身。
你可以用自生成事件来预处理输入数据,例如解码、用换行分隔数据。有强迫症的人可能会说,应该分出另一个状态机来发送预处理好的数据给主状态机。为了降低消耗,这个预处理状态机可以通过一般的状态事件处理来实现。
下面的例子为一个输入模型,通过 put_chars(Chars) 输入,enter() 来结束输入:
... -export(put_chars/1, enter/0). ... put_chars(Chars) when is_binary(Chars) ->gen_statem:call(?NAME, {chars,Chars}).enter() ->gen_statem:call(?NAME, enter)....locked(enter, _OldState, Data) ->do_lock(),{keep_state,Data#{remaining => Code, buf => []}}; ...handle_event({call,From}, {chars,Chars}, #{buf := Buf} = Data) ->{keep_state, Data#{buf := [Chars|Buf],[{reply,From,ok}]}; handle_event({call,From}, enter, #{buf := Buf} = Data) ->Chars = unicode:characters_to_binary(lists:reverse(Buf)),try binary_to_integer(Chars) ofDigit ->{keep_state, Data#{buf := []},[{reply,From,ok},{next_event,internal,{button,Chars}}]}catcherror:badarg ->{keep_state, Data#{buf := []},[{reply,From,{error,not_an_integer}}]}end; ...
用 code_lock:start([17]) 启动程序,然后就能通过 code_lock:put_chars(<<"001">>), code_lock:put_chars(<<"7">>), code_lock:enter() 这一系列动作开锁了。
3.19 重写例子
这一小节包含了之前提到的大部分修改,用到了状态 enter 回调,用一个新的状态图来表述:
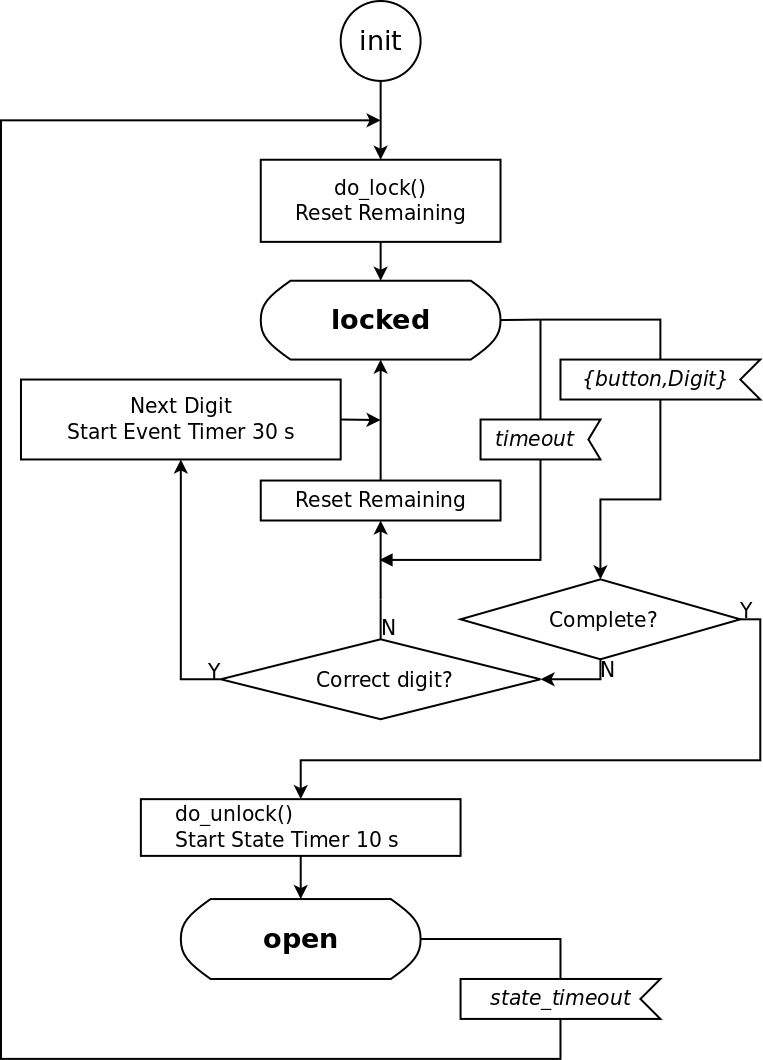
图 3.2:重写密码锁状态图
注意,图中没有说明 open 状态如何处理按钮事件。需要从其他地方找,因为没标明的事件不是被去掉了,而是在其他状态中进行处理了。图中也没有说明 code_length/0 需要在所有状态中处理。
回调模式:state_functions
使用 state functions:
-module(code_lock). -behaviour(gen_statem). -define(NAME, code_lock_2).-export([start_link/1,stop/0]). -export([button/1,code_length/0]). -export([init/1,callback_mode/0,terminate/3,code_change/4]). -export([locked/3,open/3]).start_link(Code) ->gen_statem:start_link({local,?NAME}, ?MODULE, Code, []). stop() ->gen_statem:stop(?NAME).button(Digit) ->gen_statem:cast(?NAME, {button,Digit}). code_length() ->gen_statem:call(?NAME, code_length).init(Code) ->process_flag(trap_exit, true),Data = #{code => Code},{ok, locked, Data}.callback_mode() ->[state_functions,state_enter].locked(enter, _OldState, #{code := Code} = Data) ->do_lock(),{keep_state, Data#{remaining => Code}}; locked(timeout, _, #{code := Code, remaining := Remaining} = Data) ->{keep_state, Data#{remaining := Code}}; locked(cast, {button,Digit},#{code := Code, remaining := Remaining} = Data) ->case Remaining of[Digit] -> % Complete{next_state, open, Data};[Digit|Rest] -> % Incomplete{keep_state, Data#{remaining := Rest}, 30000};[_|_] -> % Wrong{keep_state, Data#{remaining := Code}}end; locked(EventType, EventContent, Data) ->handle_event(EventType, EventContent, Data).open(enter, _OldState, _Data) ->do_unlock(),{keep_state_and_data, [{state_timeout,10000,lock}]}; open(state_timeout, lock, Data) ->{next_state, locked, Data}; open(cast, {button,_}, _) ->{keep_state_and_data, [postpone]}; open(EventType, EventContent, Data) ->handle_event(EventType, EventContent, Data).handle_event({call,From}, code_length, #{code := Code}) ->{keep_state_and_data, [{reply,From,length(Code)}]}.do_lock() ->io:format("Locked~n", []). do_unlock() ->io:format("Open~n", []).terminate(_Reason, State, _Data) ->State =/= locked andalso do_lock(),ok. code_change(_Vsn, State, Data, _Extra) ->{ok,State,Data}.
回调模式:handle_event_function
这部分描述了如何使用一个 handle_event/4 函数来替换上面的例子。前文提到的在第一层以事件作区分的方式在此例中不太合适,因为有状态 enter 调用,所以用第一层以状态作区分的方式:
... -export([handle_event/4]).... callback_mode() ->[handle_event_function,state_enter].%% State: locked handle_event(enter, _OldState, locked,#{code := Code} = Data) ->do_lock(),{keep_state, Data#{remaining => Code}}; handle_event(timeout, _, locked,#{code := Code, remaining := Remaining} = Data) ->{keep_state, Data#{remaining := Code}}; handle_event(cast, {button,Digit}, locked,#{code := Code, remaining := Remaining} = Data) ->case Remaining of[Digit] -> % Complete{next_state, open, Data};[Digit|Rest] -> % Incomplete{keep_state, Data#{remaining := Rest}, 30000};[_|_] -> % Wrong{keep_state, Data#{remaining := Code}}end; %% %% State: open handle_event(enter, _OldState, open, _Data) ->do_unlock(),{keep_state_and_data, [{state_timeout,10000,lock}]}; handle_event(state_timeout, lock, open, Data) ->{next_state, locked, Data}; handle_event(cast, {button,_}, open, _) ->{keep_state_and_data,[postpone]}; %% %% Any state handle_event({call,From}, code_length, _State, #{code := Code}) ->{keep_state_and_data, [{reply,From,length(Code)}]}....
真正的密码锁中把按钮事件从 locked 状态延迟到 open 状态感觉会很奇怪,它只是用来举例说明事件延缓。
3.20 过滤状态
目前实现的服务器,会在终止时的错误日志中输出所有的内部状态。包含了门锁密码和剩下需要按的按钮。
这个信息属于敏感信息,你可能不想因为一些不可预料的事情在错误日志中输出这些。
还有可能内部状态数据太多,在错误日志中包含了太多没用的数据,所以需要进行筛选。
你可以通过实现函数 Module:format_status/2 来格式化错误日志中通过 sys:get_status/1,2 获得的内部状态,例如:
... -export([init/1,terminate/3,code_change/4,format_status/2]). ...format_status(Opt, [_PDict,State,Data]) ->StateData ={State,maps:filter(fun (code, _) -> false;(remaining, _) -> false;(_, _) -> trueend,Data)},case Opt ofterminate ->StateData;normal ->[{data,[{"State",StateData}]}]end.
实现 Module:format_status/2 并不是强制的。如果不实现,默认的实现方式就类似上面这个例子,除了默认不会筛选 Data(即 StateData = {State,Data}),例子中因为有敏感信息必须进行筛选。
3.21 复合状态
回调模式 handle_event_function 支持使用非 atom 的状态(详见回调模式),比如一个复合状态可能是一个 tuple。
你可能想在状态变化的时候取消状态超时,或者和延缓事件配合使用控制事件处理,这时候就要用到复合状态。我们引入可配置的锁门按钮来完善前面的例子(这就是此问题中的状态),这个按钮可以在 open 状态立马锁门,且可以通过 set_lock_button/1 这个接口来设置锁门按钮。
假设我们在开门的状态调用 set_lock_button,并且此前已经延缓了一个按钮事件(不是旧的锁门按钮,译者补充:是新的锁门按钮)。说这个按钮按得太早不算是锁门按钮,合理。然而门锁状态变为 locked 时,你就会惊奇地发现一个锁门按钮事件触发了。
我们用 gen_statem:call 来实现 button/1 函数,仍在 open 状态延缓它所有的按钮事件。在 open 状态调用 button/1,状态变为 locked 之前它不会返回,因为 locked 状态时事件才会被处理并且回复。
如果另一个进程在 button/1 挂起,有人调用 set_lock_button/1 来改变锁门按钮,被挂起的 button 调用会立刻生效,门被锁住。因此,我们把当前的门锁按钮作为状态的一部分,这样当我们改变门锁按钮时,状态会改变,所有的延缓事件会重新触发。
我们定义状态为 {StateName,LockButton},其中 StateName 和之前一样,而 LockButton 则表示当前的锁门按钮:
-module(code_lock). -behaviour(gen_statem). -define(NAME, code_lock_3).-export([start_link/2,stop/0]). -export([button/1,code_length/0,set_lock_button/1]). -export([init/1,callback_mode/0,terminate/3,code_change/4,format_status/2]). -export([handle_event/4]).start_link(Code, LockButton) ->gen_statem:start_link({local,?NAME}, ?MODULE, {Code,LockButton}, []). stop() ->gen_statem:stop(?NAME).button(Digit) ->gen_statem:call(?NAME, {button,Digit}). code_length() ->gen_statem:call(?NAME, code_length). set_lock_button(LockButton) ->gen_statem:call(?NAME, {set_lock_button,LockButton}).init({Code,LockButton}) ->process_flag(trap_exit, true),Data = #{code => Code, remaining => undefined},{ok, {locked,LockButton}, Data}.callback_mode() ->[handle_event_function,state_enter].handle_event({call,From}, {set_lock_button,NewLockButton},{StateName,OldLockButton}, Data) ->{next_state, {StateName,NewLockButton}, Data,[{reply,From,OldLockButton}]}; handle_event({call,From}, code_length,{_StateName,_LockButton}, #{code := Code}) ->{keep_state_and_data,[{reply,From,length(Code)}]}; %% %% State: locked handle_event(EventType, EventContent,{locked,LockButton}, #{code := Code, remaining := Remaining} = Data) ->case {EventType, EventContent} of{enter, _OldState} ->do_lock(),{keep_state, Data#{remaining := Code}};{timeout, _} ->{keep_state, Data#{remaining := Code}};{{call,From}, {button,Digit}} ->case Remaining of[Digit] -> % Complete{next_state, {open,LockButton}, Data,[{reply,From,ok}]};[Digit|Rest] -> % Incomplete{keep_state, Data#{remaining := Rest, 30000},[{reply,From,ok}]};[_|_] -> % Wrong{keep_state, Data#{remaining := Code},[{reply,From,ok}]}endend; %% %% State: open handle_event(EventType, EventContent,{open,LockButton}, Data) ->case {EventType, EventContent} of{enter, _OldState} ->do_unlock(),{keep_state_and_data, [{state_timeout,10000,lock}]};{state_timeout, lock} ->{next_state, {locked,LockButton}, Data};{{call,From}, {button,Digit}} ->ifDigit =:= LockButton ->{next_state, {locked,LockButton}, Data,[{reply,From,locked}]};true ->{keep_state_and_data,[postpone]}endend.do_lock() ->io:format("Locked~n", []). do_unlock() ->io:format("Open~n", []).terminate(_Reason, State, _Data) ->State =/= locked andalso do_lock(),ok. code_change(_Vsn, State, Data, _Extra) ->{ok,State,Data}. format_status(Opt, [_PDict,State,Data]) ->StateData ={State,maps:filter(fun (code, _) -> false;(remaining, _) -> false;(_, _) -> trueend,Data)},case Opt ofterminate ->StateData;normal ->[{data,[{"State",StateData}]}]end.
对现实中的锁来说,button/1 在状态变为 locked 前被挂起不合理。但是作为一个 API,还好。
3.22 挂起
(译者补充:此挂起跟前文的挂起不同,前文的挂起仅意味着 receive 阻塞。)
如果一个节点中有很多个 server,并且他们在生命周期中某些时候会空闲,那么这些 server 的堆内存会造成浪费,通过 proc_lib:hibernate/3 来挂起 server 会把它的内存占用降到最低。
注意:挂起一个进程代价很高,详见 erlang:hibernate/3 。不要在每个事件之后都挂起它。 此例中我们可以在 {open,_} 状态挂起,因为正常来说只有在一段时间后它才会收到状态超时,迁移至 locked 状态:
...
%% State: open
handle_event(EventType, EventContent,{open,LockButton}, Data) ->case {EventType, EventContent} of{enter, _OldState} ->do_unlock(),{keep_state_and_data,[{state_timeout,10000,lock},hibernate]};
... 最后一行的动作列表中 hibernate 是唯一的修改。如果任何事件在 {open,_} 状态到达,我们不用再重新挂起,接收事件后 server 会一直处于活跃状态。
如果要重新挂起,我们需要在更多的地方插入 hibernate 来改变。例如,跟状态无关的 set_lock_button 和 code_length 操作,在 {open,_} 状态可以让他 hibernate,但是这样会让代码很乱。
另一个不常用的方法是使用事件超时,在一段时间的不活跃后触发挂起。
本例可能不值得使用挂起来降低堆内存。只有在运行中产生了垃圾的 server 才会从挂起中受益,从这个层面说,上面的是个不好的例子。
4 gen_event Behaviour
此章可结合 gen_event(3)(包含全部接口函数和回调函数的详述)教程一起看。
4.1 事件处理原则
在 OTP 中,一个事件管理器(event manager)是一个可以接收事件的指定的对象。事件(event)可能是要记录日志的错误、警告、信息等等。
事件管理器中可以安装(install)0个、1个或更多的事件处理器(event handler)。当事件管理器收到一个事件通知,这个事件被所有安装好的事件处理器处理。例如,一个处理错误的事件管理器可能内置一个默认的处理器,把错误写到终端。如果某段时间需要把错误信息写到文件,用户可以添加另一个处理器来处理。不需要再写入文件时,则可以删除这个处理器。
事件管理器是一个进程,而事件处理器则是一个回调模块。
事件管理器本质上就是维护一个 {Module, State} 列表,其中 Module 是一个事件处理器,State 则是处理器的内部状态。
4.2 例子
将错误信息写到终端的事件处理器的回调模块可能长这样:
-module(terminal_logger). -behaviour(gen_event).-export([init/1, handle_event/2, terminate/2]).init(_Args) ->{ok, []}.handle_event(ErrorMsg, State) ->io:format("***Error*** ~p~n", [ErrorMsg]),{ok, State}.terminate(_Args, _State) ->ok.
将错误信息写到文件的事件处理器的回调模块可能长这样:
-module(file_logger). -behaviour(gen_event).-export([init/1, handle_event/2, terminate/2]).init(File) ->{ok, Fd} = file:open(File, read),{ok, Fd}.handle_event(ErrorMsg, Fd) ->io:format(Fd, "***Error*** ~p~n", [ErrorMsg]),{ok, Fd}.terminate(_Args, Fd) ->file:close(Fd).
下一小节分析这些代码。
4.3 开启一个事件管理器
调用下面的函数来开启一个前例中说的处理错误的事件管理器:
gen_event:start_link({local, error_man}) 这个函数创建并连接一个新进程(事件管理器 event manager)。
参数 {local, error_man} 指定了事件管理器的名字,事件管理器在本地注册为 error_man。
如果名字参数被忽略,事件管理器不会被注册,则必须用到它的进程 pid。名字还可以用{global, Name},这样的话会调用 global:register_name/2 来注册事件管理器。
如果 gen_event 是一个监控树的一部分,supervisor 启动 gen_event 时一定要使用 gen_event:start_link。还有一个函数是 gen_event:start ,这个函数会启动一个独立的 gen_event,也就是说它不会成为监控树的一部分。
4.4 添加一个事件处理器
下例表明了在 shell 中,如何开启一个事件管理器,并为它添加一个事件处理器:
1> gen_event:start({local, error_man}). {ok,<0.31.0>} 2> gen_event:add_handler(error_man, terminal_logger, []). ok
这个函数会发送一个消息给事件处理器 error_man,告诉它需要添加一个事件处理器 terminal_logger。事件管理器会调用函数 terminal_logger:init([]) (init 的参数 [] 是 add_handler 的第三个参数)。正常的话 init 会返回 {ok, State},State就是事件处理器的内部状态。
init(_Args) ->{ok, []}. 此例中 init 不需要任何输入,因此忽略了它的参数。terminal_logger 中不需要用到内部状态,file_logger 可以用内部状态来保存文件描述符。
init(File) ->{ok, Fd} = file:open(File, read),{ok, Fd}.
4.5 事件通知
3> gen_event:notify(error_man, no_reply). ***Error*** no_reply ok
其中 error_man 是事件处理器的注册名,no_reply 是事件。
这个事件会以消息的形式发送给事件处理器。接收事件时,事件管理器会按照安装的顺序,依次调用每个事件处理器的 handle_event(Event, State)。handle_event 正常会返回元组 {ok,State1},其中 State1 是事件处理器的新的内部状态。
terminal_logger 中:
handle_event(ErrorMsg, State) ->io:format("***Error*** ~p~n", [ErrorMsg]),{ok, State}.
file_logger 中:
handle_event(ErrorMsg, Fd) ->io:format(Fd, "***Error*** ~p~n", [ErrorMsg]),{ok, Fd}.
4.6 删除事件处理器
4> gen_event:delete_handler(error_man, terminal_logger, []).
ok 这个函数会发送一条消息给注册名为 error_man 的事件管理器,告诉它要删除处理器 terminal_logger。此时管理器会调用 terminal_logger:terminate([], State),其中 [] 是 delete_handler 的第三个参数。terminate 中应该做与 init 相反的事情,做一些清理工作。它的返回值会被忽略。
terminal_logger 不需要做清理:
terminate(_Args, _State) ->ok. file_logger 需要关闭 init 中开启的文件描述符:
terminate(_Args, Fd) ->file:close(Fd).
4.7 终止
当事件管理器被终止,它会调用每个处理器的 terminate/2,和删除处理器时一样。
在监控树中
如果管理器是监控树的一部分,则不需要终止函数。管理器自动的被它的监控者终止,具体怎么终止通过 终止策略 来决定。
独立的事件管理器
事件管理器可以通过调用以下函数终止:
> gen_event:stop(error_man).
ok
4.8 处理其他消息
如果想要处理事件之外的其他消息,需要实现回调函数 handle_info(Info, StateName, StateData)。比如说 exit 消息,当 gen_event 与其他进程(非它的监控者)连接,并且被设置为捕捉 exit 信号。
handle_info({'EXIT', Pid, Reason}, State) ->..code to handle exits here..{ok, NewState}. code_change 函数也需要实现。
code_change(OldVsn, State, Extra) ->..code to convert state (and more) during code change{ok, NewState}
5 Supervisor Behaviour
这部分可与 stdblib 中的 supervisor(3) 教程(包含了所有细节)一起阅读。
5.1 监控原则
监控者(supervisor)要负责开启、终止和监控它的子进程。监控者的基本理念就是通过必要时的重启,来保证子进程一直活着。
子进程规格说明指定了要启动和监控的子进程。子进程根据规格列表依次启动,终止顺序和启动顺序相反。
5.2 例子
下面的例子是启动 gen_server 子进程的监控树:
-module(ch_sup). -behaviour(supervisor).-export([start_link/0]). -export([init/1]).start_link() ->supervisor:start_link(ch_sup, []).init(_Args) ->SupFlags = #{strategy => one_for_one, intensity => 1, period => 5},ChildSpecs = [#{id => ch3,start => {ch3, start_link, []},restart => permanent,shutdown => brutal_kill,type => worker,modules => [cg3]}],{ok, {SupFlags, ChildSpecs}}.
返回值中的 SupFlags 即 supervisor flag,详见下一小节。
ChildSpecs 是子进程规格列表。
5.3 supervisor flag
下面是 supervisor flag 的类型定义:
sup_flags() = #{strategy => strategy(), % optionalintensity => non_neg_integer(), % optionalperiod => pos_integer()} % optionalstrategy() = one_for_all| one_for_one| rest_for_one| simple_one_for_one - strategy 指定了重启策略。
- intensity 和 period 指定了最大重启频率。
5.4 重启策略
重启策略是由 init 返回的 map 中的 strategy 来指定的:
SupFlags = #{strategy => Strategy, ...} strategy 是可选参数,如果没有指定,默认为 one_for_one。
one_for_one
如果子进程终止,只有终止的子进程会被重启。
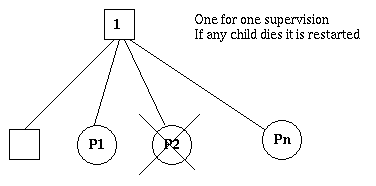
图5.1 one_for_one 监控树
one_for_all
如果一个子进程终止,其他子进程都会被终止,然后所有子进程被重启。
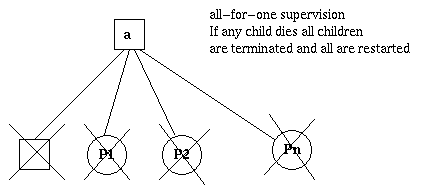
图5.2 one_for_all 监控树
rest_for_one
如果一个子进程终止,启动顺序在此子进程之后的子进程们都会被终止。然后这些终止的进程(包括自己终止的那位)被重启。
simple_one_for_one
详见 simple-one-for-one supervisors(译者补充:本原则中也有提及simple_one_for_one)
5.5 最大重启频率
supervisor 内置了一个机制来限制给定时间间隔内的重启次数。由 init 函数返回的 supervisor flag 中的 intensity 和 period 字段来指定:
SupFlags = #{intensity => MaxR, period => MaxT, ...} 如果 MaxT 秒内重启了 MaxR 次,监控者会终止所有的子进程,然后退出。此时 supervisor 退出的理由是 shutdown。
当 supervisor 终止时,它的上一级 supervisor 会作出一些处理,重启它,或者跟着退出。
这个重启机制的目的是防止进程反复因为同一原因终止和重启。
intensity 和 period 都是可选参数,如果没有指定,它们缺省值分别为1和5。
调整 intensity 和 period
缺省值为5秒重启1次。这个配置对大部分系统(即便是很深的监控树)来说都是保险的,但你可能想为某些特殊的应用场景做出调整。
首先,intensity 决定了你能忍受多少次突发重启。例如,你只能接受5~10次的重启尝试(尽管下一秒它可能会重启成功)。
其次,如果崩溃持续发生,但是没有频繁到让 supervisor 放弃,你需要考虑持续的失败率。比如说你把 intensity 设置为10,而 period 为1,supervisor 会允许子进程在1秒内重启10次,在人工干预前它会持续往日志中写入 crash 报告。
此时你需要把 period 设置得足够大,让 supervisor 在你能接受的比值下运行。例如,你将 intensity 设置为5,period 为30s,会让它在一段时间内允许平均6s的重启间隔,这样你的日志就不会太快被填满,你可以观察错误,然后作出修复。
这些选择取决于你的问题作用域。如果你不会实时监测或者不能快速解决问题(例如在嵌入式系统中),你可能想1分钟最多重启一次,把问题交给更高层去自动清理错误。或者有时候,可能高失败率时仍然尝试重启是更好的选择,你可以设置成一秒1-2次重启。
避免一些常见的错误:
- 不要忘记考虑爆发率。如果你把 intensity 设置为1,period 为6,它的长期错误率与5/30和10/60差不多,但是它不允许连续两次重启。这可能不是你想要的。
- 如果想容忍爆发,不要把 period 设置得很大。如果你把 intensity 设置为5,period 为3600(1小时),supervisor 允许短时间内重启5次,然而接近(但不到)一个小时的一次崩溃会导致它放弃。而这两拨崩溃可能是不同原因导致的,所以设置为5到10分钟会更合理。
- 如果你的应用包含多级监控,不要简单地把所有层的重启频率设置成相同的值。在顶层 supervisor 放弃重启并终止应用之前,重启的总次数是崩溃的子进程上层的所有 supervisor 的密度的乘积。
例如,如果最上层允许10次重启,第二层也允许10次,下层崩溃的子进程会被重启100次,这太多了。最上层允许3次重启可能更好。
5.6 子进程规格说明
下面是子进程规格(child specification)的类型定义:
child_spec() = #{id => child_id(), % mandatorystart => mfargs(), % mandatoryrestart => restart(), % optionalshutdown => shutdown(), % optionaltype => worker(), % optionalmodules => modules()} % optionalchild_id() = term()mfargs() = {M :: module(), F :: atom(), A :: [term()]}modules() = [module()] | dynamicrestart() = permanent | transient | temporaryshutdown() = brutal_kill | timeout()worker() = worker | supervisor - id 在 supervisor 内部被用来识别不同的 child specificaton。
id 是必填项
有时 id 会被称为 name,现在一般都用 identifier 或者 id,但为了向后兼容,有时也能看到 name,例如在错误信息中。
- start 规定了启动子进程的函数。它是一个 模块-函数-参数 元组,用来传递给 apply(M, F, A) 。
它应该(或者最终应该)调用下面这些函数:
-
- supervisor:start_link
- gen_server:start_link
- gen_statem:start_link
- gen_event:start_link
- 跟这些函数类似的函数。详见 supervisor(3) 的 start 参数。(译者补充:函数应满足条件:创建并且连接到子进程,且必须返回 {ok,Child} 或 {ok,Child,Info},其中 Child 是子进程 pid,Info 会被 supervisor 忽略)
start 是必填项。
- restart 规定了什么时候一个终止的进程会触发重启
- permanent 表示进程总是触发重启
- temporary 表示进程不会被重启(即便重启策略是 rest_for_one 或 one_for_all,前置进程导致 temporary 进程终止)
- transient 仅在进程异常退出时重启,即:终止理由不是 normal、shutdown 或 {shutdown,Term} 。
restart 是可选项,缺省值为 permanent。
- shutdown 规定了进程被终止的方式
- brutal_kill 表示会使用 exit(Child, kill) 无条件终止子进程。
- 一个整数超时值,意味着 supervisor 会调用 exit(Child, shutdown) 通知子进程退出,然后等待退出信号返回。如果指定时间内没有收到退出信号,子进程会被 exit(Child, kill) 无条件终止。
- 如果子进程是一个 supervisor,可以设置为 infinity 来让子监控树有足够的时间退出。如果子进程是 worker 也可以设置为 infinity。警告:
警告:当子进程是 worker 时慎用 infinity。因为这种情况下,监控树的退出取决于子进程的退出,必须要安全地实现子进程,确保它的清理过程必定会返回。
shutdown 是可选项,如果子进程是 worker,默认为 5000;如果子进程是监控树,默认为 infinity。
- type 标明子进程是 worker 还是 supervisor
type 是可选项,缺省值为 worker。
- modules 当 Module 是回调模块名,modules 是单元素的列表 [Module](子进程为 supervisor, gen_server, gen_statem);如果子进程是 gen_event,值应该为 dynamic。
这个字段在发布管理的升级和降级中会用到,详见 Release Handling。
modules 是可选项,缺省值为 [M],其中 M 来自子进程的启动参数 {M,F,A} 。
例:前例中 ch3 的子进程规格如下:
#{id => ch3,start => {ch3, start_link, []},restart => permanent,shutdown => brutal_kill,type => worker,modules => [ch3]} 或者简化一下,取默认值:
#{id => ch3,start => {ch3, start_link, []}shutdown => brutal_kill} 例:上文的 gen_event 子进程规格如下:
#{id => error_man,start => {gen_event, start_link, [{local, error_man}]},modules => dynamic} 这两个都是注册进程,都被期望一直能访问到。所以他们被指定为 permanent 。
ch3 在终止前不需要做任何清理工作,所以不需要指定终止时间,shudown 值设置为 brutal_kill 就行了。而 error_man 需要时间去清理,所以设置为5000毫秒(默认值)。
例:启动另一个 supervisor 的子进程规格:
#{id => sup,start => {sup, start_link, []},restart => transient,type => supervisor} % will cause default shutdown=>infinity (type为supervisor会导致shutdown的默认值为infinity)
5.7 启动supervisor
前例中,supervisor 通过调用 ch_sup:start_link() 来启动:
start_link() ->supervisor:start_link(ch_sup, []). ch_sup:start_link 函数调用 supervisor:start_link/2,生成并连接了一个新进程(supervisor)。
- 第一个参数,ch_sup 是回调模块的名字,也就是 init 函数所在的模块。
- 第二个参数,[],是传递给 init 函数的参数,此例中 init 不需要任何输入,忽略了此参数。
此例中 supervisor 没有被注册,因此必须用到它的 pid。可以通过调用 supervisor:start_link({local, Name}, Module, Args) 或 supervisor:start_link({global, Name}, Module, Args) 来指定它的名字。
这个新的 supervisor 进程会调用 init 回调 ch_sup:init([])。init 函数应该返回 {ok, {SupFlags, ChildSpecs}}。
init(_Args) ->SupFlags = #{},ChildSpecs = [#{id => ch3,start => {ch3, start_link, []},shutdown => brutal_kill}],{ok, {SupFlags, ChildSpecs}}. 然后 supervisor 会根据子进程规格列表,启动所有的子进程。此例中只有一个子进程,ch3 。
supervisor:start_link 是同步调用,在所有子进程启动之前它不会返回。
5.8 增加子进程
除了静态的监控树外,还可以动态地添加子进程到监控树中:
supervisor:start_child(Sup, ChildSpec)
Sup 是 supervisor 的 pid 或注册名。ChildSpec 是子进程规格。
使用 start_child/2 添加的子进程跟其他子进程行为一样,除了一点:如果 supervisor 终止并被重启,所有动态添加的进程都会丢失。
5.9 终止子进程
调用下面的函数,静态或动态的子进程,都会根据规格终止:
supervisor:terminate_child(Sup, Id)
一个终止的子进程的规格可通过下面的函数删除:
supervisor:delete_child(Sup, Id)
Sup 是 supervisor 的 pid 或注册名。Id 是子进程规格中的 id 项。
删除静态的子进程规格会导致它跟动态子进程一样,在 supervisor 重启时丢失。
5.10 简化的 one_for_one(simple_one_for_one)
重启策略 simple_one_for_one 是简化的 one_for_one,所有的子进程是相同过程的实例,被动态地添加到监控树中。
下面是一个 simple_one_for_one 的 supervisor 回调模块:
-module(simple_sup). -behaviour(supervisor).-export([start_link/0]). -export([init/1]).start_link() ->supervisor:start_link(simple_sup, []).init(_Args) ->SupFlags = #{strategy => simple_one_for_one,intensity => 0,period => 1},ChildSpecs = [#{id => call,start => {call, start_link, []},shutdown => brutal_kill}],{ok, {SupFlags, ChildSpecs}}.
启动时,supervisor 没有启动任何子进程。所有的子进程是通过调用如下函数动态添加的:
supervisor:start_child(Pid, [id1])
子进程会通过调用 apply(call, start_link, []++[id1]) 来启动,即:
call:start_link(id1)
simple_one_for_one 监程的子进程通过下面的方式来终止:
supervisor:terminate_child(Sup, Pid)
Sup 是 supervisor 的 pid 或注册名。Pid 是子进程的 pid。
由于 simple_one_for_one 的监程可能有大量的子进程,所以它是异步终止它们的。就是说子进程平行地做清理工作,终止顺序不可预测。
5.11 终止
由于 supervisor 是监控树的一部分,它会自动地被它的 supervisor 终止。当被要求终止时,它会根据 shutdown 配置按照与启动相反的顺序(译者补充:除了 simple_one_for_one 模式)终止所有的子进程,然后退出。
6 sys and proc_lib
sys 模块包含一些函数,可以简单地 debug 用 behaviour 实现的进程。还有一些函数可以和 proc_lib 模块的函数一起,用来实现特殊的进程,这些特殊的进程不采用标准的 behaviour,但是满足 OTP 设计原则。这些函数还可以用来实现用户自定义(非标准)的 behaviour。
sys 和 proc_lib 模块都属于 STDLIB 应用。
6.1 简易debug
sys 模块包含一些函数,可以简单地 debug 用 behaviour 实现的进程。用 gen_statem Behaviour 中的例子 code_lock 举例:
Erlang/OTP 20 [DEVELOPMENT] [erts-9.0] [source-5ace45e] [64-bit] [smp:8:8] [ds:8:8:10] [async-threads:10] [hipe] [kernel-poll:false]Eshell V9.0 (abort with ^G) 1> code_lock:start_link([1,2,3,4]). Lock {ok,<0.63.0>} 2> sys:statistics(code_lock, true). ok 3> sys:trace(code_lock, true). ok 4> code_lock:button(1). *DBG* code_lock receive cast {button,1} in state locked ok *DBG* code_lock consume cast {button,1} in state locked 5> code_lock:button(2). *DBG* code_lock receive cast {button,2} in state locked ok *DBG* code_lock consume cast {button,2} in state locked 6> code_lock:button(3). *DBG* code_lock receive cast {button,3} in state locked ok *DBG* code_lock consume cast {button,3} in state locked 7> code_lock:button(4). *DBG* code_lock receive cast {button,4} in state locked ok Unlock *DBG* code_lock consume cast {button,4} in state locked *DBG* code_lock receive state_timeout lock in state open Lock *DBG* code_lock consume state_timeout lock in state open 8> sys:statistics(code_lock, get). {ok,[{start_time,{{2017,4,21},{16,8,7}}},{current_time,{{2017,4,21},{16,9,42}}},{reductions,2973},{messages_in,5},{messages_out,0}]} 9> sys:statistics(code_lock, false). ok 10> sys:trace(code_lock, false). ok 11> sys:get_status(code_lock). {status,<0.63.0>,{module,gen_statem},[[{'$initial_call',{code_lock,init,1}},{'$ancestors',[<0.61.0>]}],running,<0.61.0>,[],[{header,"Status for state machine code_lock"},{data,[{"Status",running},{"Parent",<0.61.0>},{"Logged Events",[]},{"Postponed",[]}]},{data,[{"State",{locked,#{code => [1,2,3,4],remaining => [1,2,3,4]}}}]}]]}
6.2 特殊的进程
此小节讲述怎么不使用标准 behaviour 来写一个程序,使它满足 OTP 设计原则。这样一个进程需要满足:
- 提供启动方式使它可以纳入监控树中
- 支持 sys 的debug工具
- 关心系统消息
系统消息是在监控树中用到的、有特殊意义的消息。典型的系统消息有追踪输出的请求、挂起或恢复进程的请求(release handling 发布管理中用到)。使用标准 behaviour 实现的进程能自动处理这些消息。
例子
概述里面的简单服务器,使用 sys 和 proc_lib 来实现以使其可纳入监控树中:
-module(ch4). -export([start_link/0]). -export([alloc/0, free/1]). -export([init/1]). -export([system_continue/3, system_terminate/4,write_debug/3,system_get_state/1, system_replace_state/2]).start_link() ->proc_lib:start_link(ch4, init, [self()]).alloc() ->ch4 ! {self(), alloc},receive{ch4, Res} ->Resend.free(Ch) ->ch4 ! {free, Ch},ok.init(Parent) ->register(ch4, self()),Chs = channels(),Deb = sys:debug_options([]),proc_lib:init_ack(Parent, {ok, self()}),loop(Chs, Parent, Deb).loop(Chs, Parent, Deb) ->receive{From, alloc} ->Deb2 = sys:handle_debug(Deb, fun ch4:write_debug/3,ch4, {in, alloc, From}),{Ch, Chs2} = alloc(Chs),From ! {ch4, Ch},Deb3 = sys:handle_debug(Deb2, fun ch4:write_debug/3,ch4, {out, {ch4, Ch}, From}),loop(Chs2, Parent, Deb3);{free, Ch} ->Deb2 = sys:handle_debug(Deb, fun ch4:write_debug/3,ch4, {in, {free, Ch}}),Chs2 = free(Ch, Chs),loop(Chs2, Parent, Deb2);{system, From, Request} ->sys:handle_system_msg(Request, From, Parent,ch4, Deb, Chs)end.system_continue(Parent, Deb, Chs) ->loop(Chs, Parent, Deb).system_terminate(Reason, _Parent, _Deb, _Chs) ->exit(Reason).system_get_state(Chs) ->{ok, Chs}.system_replace_state(StateFun, Chs) ->NChs = StateFun(Chs),{ok, NChs, NChs}.write_debug(Dev, Event, Name) ->io:format(Dev, "~p event = ~p~n", [Name, Event]).
sys 模块中的简易 debug 也可用于 ch4:
% erl Erlang (BEAM) emulator version 5.2.3.6 [hipe] [threads:0]Eshell V5.2.3.6 (abort with ^G) 1> ch4:start_link(). {ok,<0.30.0>} 2> sys:statistics(ch4, true). ok 3> sys:trace(ch4, true). ok 4> ch4:alloc(). ch4 event = {in,alloc,<0.25.0>} ch4 event = {out,{ch4,ch1},<0.25.0>} ch1 5> ch4:free(ch1). ch4 event = {in,{free,ch1}} ok 6> sys:statistics(ch4, get). {ok,[{start_time,{{2003,6,13},{9,47,5}}},{current_time,{{2003,6,13},{9,47,56}}},{reductions,109},{messages_in,2},{messages_out,1}]} 7> sys:statistics(ch4, false). ok 8> sys:trace(ch4, false). ok 9> sys:get_status(ch4). {status,<0.30.0>,{module,ch4},[[{'$ancestors',[<0.25.0>]},{'$initial_call',{ch4,init,[<0.25.0>]}}],running,<0.25.0>,[],[ch1,ch2,ch3]]}
启动进程
proc_lib 中的一些函数可用来启动进程。有几个函数可选,如:异步启动 spawn_link/3,4 和同步启动 start_link/3,4,5 。
使用这些函数启动的进程会存储一些信息(比如高层级进程 ancestor 和初始化回调 initial call),这些信息在监控树中会被用到。
如果进程以除 normal 或 shutdown 之外的理由终止,会生成一个 crash 报告。可以在 SASL 的用户手册中了解更多 crash 报告的内容。
此例中,使用了同步启动。进程通过 ch4:start_link() 来启动:
start_link() ->proc_lib:start_link(ch4, init, [self()]). ch4:start_link 调用了函数 proc_lib:start_link 。这个函数的参数为模块名、函数名和参数列表,它创建并连接到一个新进程。新进程执行给定的函数来启动,ch4:init(Pid),其中 Pid 是第一个进程的 pid,即父进程。
所有的初始化(包括名字注册)都在 init 中完成。新进程需要通知父进程它的启动:
init(Parent) ->...proc_lib:init_ack(Parent, {ok, self()}),loop(...). proc_lib:start_link 是同步函数,在 proc_lib:init_ack 被调用前不会返回。
Debugging
要支持 sys 的 debug 工具,需要 debug 结构。Deb 通过 sys:debug_options/1 来初始生成:
init(Parent) ->...Deb = sys:debug_options([]),...loop(Chs, Parent, Deb).
sys:debug_options/1 的参数为一个选项列表。此例中列表为空,即初始时没有 debug 被启用。可用选项详见 sys 模块的用户手册。
然后,对于每个要记录或追踪的系统事件,下面的函数会被调用:
sys:handle_debug(Deb, Func, Info, Event) => Deb1
其中:
- Deb 是 debug 结构
- Func 指定了一个用户自定义的函数,用来格式化追踪输出。对于每个系统事件,格式化函数会被调用 Func(Dev, Event, Info),其中:
- Dev 是要输出到的 I/0 设备,详见 io 模块的手册。
- Event 和 Info 是从 handle_debug 传入的。
- Info 用来传递更多信息给 Func,可以是任何类型,会原样传给 Func。
- Event 是系统事件。用户可以决定系统事件的定义和表现形式。一般至少输入和输出消息会被认为是系统事件,分别用 {in,Msg[,From]} 和 {out,Msg,To} 表示。
handle_debug 返回一个更新的 debug 结构 Deb1。
此例中,handle_debug 会在每次输入和输出信息时被调用。格式化函数 Func 即 ch4:write_debug/3,它调用 io:format/3 打印消息:
loop(Chs, Parent, Deb) ->receive{From, alloc} ->Deb2 = sys:handle_debug(Deb, fun ch4:write_debug/3,ch4, {in, alloc, From}),{Ch, Chs2} = alloc(Chs),From ! {ch4, Ch},Deb3 = sys:handle_debug(Deb2, fun ch4:write_debug/3,ch4, {out, {ch4, Ch}, From}),loop(Chs2, Parent, Deb3);{free, Ch} ->Deb2 = sys:handle_debug(Deb, fun ch4:write_debug/3,ch4, {in, {free, Ch}}),Chs2 = free(Ch, Chs),loop(Chs2, Parent, Deb2);...end.write_debug(Dev, Event, Name) ->io:format(Dev, "~p event = ~p~n", [Name, Event]).
处理系统消息
收到的系统消息形如:
{system, From, Request} 这些消息的内容和意义,进程不需要理解,而是直接调用下面的函数:
sys:handle_system_msg(Request, From, Parent, Module, Deb, State)
这个函数不会返回。它处理了系统消息之后,如果要继续执行,会调用:
Module:system_continue(Parent, Deb, State)
如果进程终止,调用:
Module:system_terminate(Reason, Parent, Deb, State)
监控树中的进程应以父进程相同的理由退出。
- Request 和 From 是从系统消息中原样传递的。
- Parent 是父进程的 pid。
- Module 是模块名。
- Deb 是 debug 结构。
- State 是描述内部状态的项,会被传递给 system_continue/system_terminate/ system_get_state/system_replace_state。
如果进程要返回它的状态,handle_system_msg 会调用:
Module:system_get_state(State)
如果进程要调用函数 StateFun 替换它的状态,handle_system_msg 会调用:
Module:system_replace_state(StateFun, State)
此例中对应代码:
loop(Chs, Parent, Deb) ->receive...{system, From, Request} ->sys:handle_system_msg(Request, From, Parent,ch4, Deb, Chs)end.system_continue(Parent, Deb, Chs) ->loop(Chs, Parent, Deb).system_terminate(Reason, Parent, Deb, Chs) ->exit(Reason).system_get_state(Chs) ->{ok, Chs, Chs}.system_replace_state(StateFun, Chs) ->NChs = StateFun(Chs),{ok, NChs, NChs}.
如果这个特殊的进程设置为捕捉 exit 信号,并且父进程终止,它的预期行为是以同样的理由终止:
init(...) ->...,process_flag(trap_exit, true),...,loop(...).loop(...) ->receive...{'EXIT', Parent, Reason} ->..maybe some cleaning up here..exit(Reason);...end.
6.3 自定义behaviour
要实现自定义 behaviour,代码跟特殊进程差不多,除了要调用回调模块里的函数来处理特殊的任务。
如果想要编译器像对 OTP 的 behaviour 一样,给缺少的回调函数报警告,需要在 behaviour 模块增加 -callback 属性来描述预期的回调:
-callback Name1(Arg1_1, Arg1_2, ..., Arg1_N1) -> Res1. -callback Name2(Arg2_1, Arg2_2, ..., Arg2_N2) -> Res2. ... -callback NameM(ArgM_1, ArgM_2, ..., ArgM_NM) -> ResM.
NameX 是预期的回调名。ArgX_Y 和 ResX 是 Types and Function Specifications 中所描述的类型。-callback 属性支持 -spec 的所有语法。
-optional_callbacks 属性可以用来指定可选的回调:
-optional_callbacks([OptName1/OptArity1, ..., OptNameK/OptArityK]).
其中每个 OptName/OptArity 指定了一个回调函数的名字和参数个数。-optional_callbacks 应与 -callback 一起使用,它不能与下文的 behaviour_info() 结合使用。
注意:我们推荐使用 -callback 而不是 behaviour_info() 函数。因为工具可以用额外的类型信息来生成文档和找出矛盾。
你也可以实现并导出 behaviour_info() 来替代 -callback 和 -optional_callbacks 属性:
behaviour_info(callbacks) ->[{Name1, Arity1},...,{NameN, ArityN}]. 其中每个 {Name, Arity} 指定了回调函数的名字和参数个数。使用 -callback 属性会自动生成这个函数。
当编译器在模块 Mod 中遇到属性 -behaviour(Behaviour),它会调用 Behaviour:behaviour_info(callbacks),并且与 Mod 实际导出的函数集相比较,在缺少回调函数的时候发布一个警告。
例:
%% User-defined behaviour module -module(simple_server). -export([start_link/2, init/3, ...]).-callback init(State :: term()) -> 'ok'. -callback handle_req(Req :: term(), State :: term()) -> {'ok', Reply :: term()}. -callback terminate() -> 'ok'. -callback format_state(State :: term()) -> term().-optional_callbacks([format_state/1]).%% Alternatively you may define: %% %% -export([behaviour_info/1]). %% behaviour_info(callbacks) -> %% [{init,1}, %% {handle_req,2}, %% {terminate,0}]. start_link(Name, Module) ->proc_lib:start_link(?MODULE, init, [self(), Name, Module]).init(Parent, Name, Module) ->register(Name, self()),...,Dbg = sys:debug_options([]),proc_lib:init_ack(Parent, {ok, self()}),loop(Parent, Module, Deb, ...)....
在回调模块中:
-module(db). -behaviour(simple_server).-export([init/1, handle_req/2, terminate/0])....
behaviour 模块中 -callback 属性指定的协议,在回调模块中可以添加 -spec 属性来优化。-callback 指定的协议一般都比较宽泛,所以 -spec 会非常有用。有协议的回调模块:
-module(db). -behaviour(simple_server).-export([init/1, handle_req/2, terminate/0]).-record(state, {field1 :: [atom()], field2 :: integer()}).-type state() :: #state{}. -type request() :: {'store', term(), term()};{'lookup', term()}....-spec handle_req(request(), state()) -> {'ok', term()}....
每个 -spec 协议都是对应的 -callback 协议的子类型。
7 Applications
此部分可与 Kernel 手册中的 app 和 application 部分一起阅读。
7.1 应用概念
如果你编码实现了一些特定的功能,你可能想把它封装成一个应用,可以作为一个整体启动和终止,在其他系统中可以重用等。
要做到这一点,需要创建一个应用回调模块,描述怎么启动和终止这个应用。
然后还需要一个应用规格说明(application specification),把它放在应用资源文件中。这个文件指定了组成应用的模块列表以及回调模块名。
如果你使用 Erlang/OTP 的代码打包工具 systools(详见 Releases),每个应用的代码都放在不同的目录下,并遵循预定义的目录结构 。
7.2 应用回调模块
在下面两个回调函数中,指定了怎么启动和终止应用(即监控树):
start(StartType, StartArgs) -> {ok, Pid} | {ok, Pid, State}
stop(State) - start 函数在启动应用的时候被调用,它通过启动顶层的 supervisor 来创建监控树。正常它会返回顶层 supervisor 的pid,和一个可选字段 State(默认为 [] )。State 会传递给 stop 函数。
- StartType 通常是 normal 。只有在接管或故障切换(译者补充:分布式应用提供的功能)时它会有其他值,详见 Distributed Applications 。
- StartArgs 在应用资源文件中由 mod 指定。
- stop/1 在应用停止之后调用,用来做清理工作。实际的应用终止(即监控树的终止)是自动处理的,详见启动和终止应用。
打包前文 Supervisor Behaviour 的监控树为一个应用,应用回调模块如下:
-module(ch_app). -behaviour(application).-export([start/2, stop/1]).start(_Type, _Args) ->ch_sup:start_link().stop(_State) ->ok.
库应用不需要启动和终止,所以不需要应用回调模块。
7.3 应用资源文件
应用的规格说明用来配置一个应用,它放在应用资源文件中,简称 .app 文件:
{application, Application, [Opt1,...,OptN]}. - Application,atom 类型,应用的名字。资源文件名必须为 Application.app 。
- 每个 Opt 都是 {Key,Value} 元组,指定了应用的一个特定属性。所有的 key 都是可选项,每个 key 都有缺省值。
库应用的最简短的 .app 文件长这样(libapp 应用):
{application, libapp, []}. 有监控树的应用最简短的 .app 文件长这样(ch_app 应用):
{application, ch_app,[{mod, {ch_app,[]}}]}. mod 定义了应用的回调模块(ch_app)和启动参数([]),应用启动时会调用:
ch_app:start(normal, [])
应用终止后会调用:
ch_app:stop([])
当使用 Erlang/OTP 的代码打包工具 systools(详见 Releases),还要指定 description、vsn、modules、registered 和 applications:
{application, ch_app,[{description, "Channel allocator"},{vsn, "1"},{modules, [ch_app, ch_sup, ch3]},{registered, [ch3]},{applications, [kernel, stdlib, sasl]},{mod, {ch_app,[]}}]}.
-
description - 简短的描述,字符串,默认为 ""。
-
vsn - 版本号,字符串,默认为 ""。
-
modules - 应用引入的所有模块,在生成启动脚本和 tar 文件的时候 systools 会用到此列表。默认为 [] 。
-
registered - 应用中所有注册的进程名。systools 会用它来检测应用间的名字冲突。默认为 [] 。
- applications - 所有必须在此应用启动前启动的应用。systools 会用这个列表来生成正确的启动脚本。默认为 [] 。注意,所有的应用都至少依赖于 Kernel 和 STDLIB 应用。
注意:应用资源文件的语法和内容,详见Kernel中的app手册
7.4 目录结构
使用 systools 来打包代码,每个应用的代码会放在单独的目录下:lib/Application-Vsn,其中 Vsn 是版本号。
即便不用 systools 打包,由于 Erlang 是根据 OTP 原则打包,它会有一个特定的目录结构。如果应用存在多个版本,code server(详见 code(3) )会自动使用版本号最高的目录的代码。
开发环境的目录结构准则
只要发布环境的目录结构遵循规定,开发目录结构怎么样都行,但还是建议在开发环境中使用相同的目录结构。目录名中的版本号要略掉,因为版本是发布步骤的一部分。
有些子目录是必须的。有些子目录是可选的,应用需要才有。还有些子目录是推荐有的,也就是说建议您按下面说的使用它。例如,文档 doc 和测试 test 目录是建议在应用中包含的,以成为一个合格的 OTP 应用。
─ ${application}├── doc│ ├── internal│ ├── examples│ └── src├── include├── priv├── src│ └── ${application}.app.src└── test - src - 必须。容纳 Erlang 源码、.app 文件和应用内部使用的 include 文件。src 中可以创建子目录用以组织源文件。子目录不能超过一层。
- priv - 可选。存放应用相关的文件。
- include - 可选。存放能被其他应用访问到的 include 文件。
- doc - 推荐。所有的源文档应放在此目录的子目录下。
- doc/internal - 推荐。应用的实现细节(不对外)相关文档放在此处。
- doc/examples - 推荐。存放示例源码。建议大家把对外文档的示例放在此处。
- doc/src - 推荐。存放所有的文档源文件(包括Markdown、AsciiDoc 和 XML 文件)。
- test - 推荐。存放测试相关的所有文件,包括测试规范和测试集等。
开发环境可能还需要其他文件夹。例如,如果有其他语言的源码,比如说 C 语言写的 NIF,应该把它们放在其他目录。按照惯例,应该以语言名为前缀命名目录,比如说 C 语言用 c_src,Java 用 java_src,Go 用 go_src 。后缀 _src 意味着这个文件夹里的文件是编译和应用步骤中的一部分。最终构建好的文件应放在 priv/lib 或 priv/bin 目录下。
priv 目录存放应用运行时需要的资源。可执行文件应放在 priv/bin 目录,动态链接应放在 priv/bin 目录。其他资源可以随意放在 priv 目录下,不过最好用结构化的方式组织。
生成 erlang 代码的其他语言代码,比如 ASN.1 和 Mibs,应该放在顶层目录或 src 目录的子目录中,子目录以语言名命名(如 asn1 和 mibs)。构建文件应放在相应的语言目录下,比如 erlang 对应 src 目录,java 对应 java_src 目录。
开发环境的 .app 文件可能放在 ebin 目录下,不过建议在构建时再把它放过去。惯常做法是使用 .app.src 文件,存放在 src 目录。.app.src 文件和 .app 文件基本上是一样的,只是某些字段会在构建阶段被替换,比如应用版本号。
目录名不应该用大写字母。
建议删掉空目录。
发布环境的目录结构
应用的发布版必须遵循特定的目录结构。
─ ${application}-${version}├── bin├── doc│ ├── html│ ├── man[1-9]│ ├── pdf│ ├── internal│ └── examples├── ebin│ └── ${application}.app├── include├── priv│ ├── lib│ └── bin└── src - src - 可选。容纳 Erlang 源码、.app 文件和应用内部使用的 include 文件。发布版本中不必要用到。
- ebin - 必须。包含 Erlang 目标代码 beam 文件,.app 文件也必须要放在这里。
- priv - 可选。存放应用相关的文件,可用 code:priv_dir/1 函数访问此目录。
- priv/lib - 推荐。存放应用需要用到的共享对象( shared-object )文件,比如 NIF 或 linked-in-driver 。
- priv/bin - 推荐。存放应用需要用到的可执行文件,例如 port-program 。
- include - 可选。存放能被其他应用访问到的 include 文件。
- bin - 可选。存放应用生成的可执行文件,比如 escript 或 shell-script。
- doc - 可选。存放发布文档。
- doc/man1 - 推荐。存放应用可执行文件的帮助文档。
- doc/man3 - 推荐。存放模块 API 的帮助文档。
- doc/man6 - 推荐。存放应用概述帮助文档。
- doc/html - 可选。存放应用的 html 文档。
- doc/pdf - 可选。存放应用的 pdf 文档。
src 目录可用于 debug,但不是必须有的。include 目录只有在应用有公开的 include 文件时会用到。
推荐大家以上面的方式发布帮助文档(doc/man...),一般 HTML 和 PDF 会以其他方式发布。
建议删掉空目录。
7.5 应用控制器(application controller)
当 erlang 运行时系统启动,Kernel 应用会启动很多进程,其中一个进程是应用控制器(application controller)进程,注册名为 application_controller 。
应用的所有操作都是通过控制器来协调的。它使用了 application 模块的一些函数,详见 application 模块的文档。它控制应用的加载、卸载、启动和终止。
7.6 加载和卸载应用
应用启动前,一定要先加载它。控制器会读取并存储 .app 文件中的信息:
1> application:load(ch_app).
ok
2> application:loaded_applications().
[{kernel,"ERTS CXC 138 10","2.8.1.3"},{stdlib,"ERTS CXC 138 10","1.11.4.3"},{ch_app,"Channel allocator","1"}] 终止或者未启动的应用可以被卸载。卸载时,应用的信息会从控制器的内部数据库中清除:
3> application:unload(ch_app).
ok
4> application:loaded_applications().
[{kernel,"ERTS CXC 138 10","2.8.1.3"},{stdlib,"ERTS CXC 138 10","1.11.4.3"}] 注意:加载或卸载应用不会加载或卸载应用的代码。代码加载是以平时的方式处理的。
7.7 启动和终止应用
启动应用:
5> application:start(ch_app).
ok
6> application:which_applications().
[{kernel,"ERTS CXC 138 10","2.8.1.3"},{stdlib,"ERTS CXC 138 10","1.11.4.3"},{ch_app,"Channel allocator","1"}] 如果应用没被加载,控制器会先调用 application:load/1 来加载它。它校验 applications 的值,确保这个配置中的所有应用在此应用运行前都已经启动了。
然后控制器为应用创建一个 application master 。这个 master 是应用中所有进程的组长。master 通过调用应用回调函数 start/2 来启动应用,应用回调由 mod 配置指定。
调用下面的函数,应用会被终止,但不会被卸载:
7> application:stop(ch_app). ok
master 通过 shutdown 顶层 supervisor 来终止应用。顶层 supervisor 通知它所有的子进程终止,层层下推,整个监控树会以与启动相反的顺序终止。然后 master 会调用回调函数 stop/1(mod 配置指定的应用回调模块)。
7.8 配置应用
可以通过配置参数来配置应用。配置参数就是 .app 文件中的 env 字段对应的一个 {Par,Val} 列表:
{application, ch_app,[{description, "Channel allocator"},{vsn, "1"},{modules, [ch_app, ch_sup, ch3]},{registered, [ch3]},{applications, [kernel, stdlib, sasl]},{mod, {ch_app,[]}},{env, [{file, "/usr/local/log"}]}]}. 其中 Par 必须是一个 atom,Val 可以是任意类型。可以调用 application:get_env(App, Par) 来获取配置参数,还有一组类似函数,详见 Kernel 模块的 application 手册。
例:
% erl
Erlang (BEAM) emulator version 5.2.3.6 [hipe] [threads:0]Eshell V5.2.3.6 (abort with ^G)
1> application:start(ch_app).
ok
2> application:get_env(ch_app, file).
{ok,"/usr/local/log"} .app 文件中的配置值会被系统配置文件中的配置覆盖。配置文件包含了相关应用的配置参数:
[{Application1, [{Par11,Val11},...]},...,{ApplicationN, [{ParN1,ValN1},...]}]. 系统配置文件名为 Name.config,erlang 启动时可通过命令行参数 -config Name 来指定配置文件。详见 Kernel 模块的 config 文档。
例:
文件 test.config 内容如下:
[{ch_app, [{file, "testlog"}]}]. file 的值会覆盖 .app 文件中 file 对应的值:
% erl -config test
Erlang (BEAM) emulator version 5.2.3.6 [hipe] [threads:0]Eshell V5.2.3.6 (abort with ^G)
1> application:start(ch_app).
ok
2> application:get_env(ch_app, file).
{ok,"testlog"} 如果使用 release handling ,只能使用一个系统配置文件:sys.config 。
.app 文件和系统配置文件中的值都会被命令行中指定的值覆盖:
% erl -ApplName Par1 Val1 ... ParN ValN
例:
% erl -ch_app file '"testlog"'
Erlang (BEAM) emulator version 5.2.3.6 [hipe] [threads:0]Eshell V5.2.3.6 (abort with ^G)
1> application:start(ch_app).
ok
2> application:get_env(ch_app, file).
{ok,"testlog"}
7.9 应用启动类型
启动类型在应用启动时指定:
application:start(Application, Type)
application:start(Application) 相当于 application:start(Application, temporary) 。Type 还可以是 permanent 和 transient:
- permanent 意味着应用终止的时候,其他所有应用以及运行时系统都会终止。
- transient 应用如果终止理由是 normal,会有终止报告,但不会终止其他应用。如果 transient 应用异常终止(理由不是 normal),那么其他所有应用以及运行时系统都会终止。
- temporary 应用终止,只会有终止报告,其他应用不会终止。
通过调用 application:stop/1 可以显式地终止一个应用,不管启动类型是什么,其他应用都不会被影响。
transient 模式基本没什么用,因为当监控树退出,终止理由会是 shutdown 而不是 normal 。
8 Included Applications
8.1 引言
应用可以 include(译作包含) 其他应用。被包含的应用(included application)有自己的应用目录和 .app 文件,不过它是另一个应用的监控树的一部分。
应用不能被多个应用包含。
被包含的应用可以包含其他应用。
没有被任何应用包含的应用被称为原初应用(primary application)。
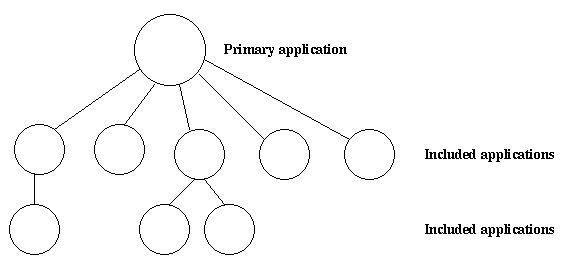
图8.1 原初应用和被包含的应用
应用控制器会在加载原初应用时,自动加载被包含的应用,但是不会启动它们。被包含的应用顶层 supervisor 必须由包含它的应用的 supervisor 启动。
也就是说运行时,被包含的应用实际上是原初应用的一部分,被包含应用中的进程会认为自己归属于原初应用。
8.2 指定被包含的应用
要包含哪些应用,是在 .app 文件的 included_applications 中指定的:
{application, prim_app,[{description, "Tree application"},{vsn, "1"},{modules, [prim_app_cb, prim_app_sup, prim_app_server]},{registered, [prim_app_server]},{included_applications, [incl_app]},{applications, [kernel, stdlib, sasl]},{mod, {prim_app_cb,[]}},{env, [{file, "/usr/local/log"}]}]}.
8.3 启动时同步
被包含应用的监控树,是包含它的应用的监控树的一部分。如果需要在两个应用间做同步,可以通过 start phase 来实现。
Start phase 是由 .app 文件中的 start_phases 字段指定的,它是一个 {Phase,PhaseArgs} 列表,其中 Phase 是一个 atom,PhaseArgs 可以是任何类型。
包含其他应用时,mod 字段必须为 {application_starter,[Module,StartArgs]}。其中 Module 是应用回调模块,StartArgs 是传递给 Module:start/2 的参数:
{application, prim_app,[{description, "Tree application"},{vsn, "1"},{modules, [prim_app_cb, prim_app_sup, prim_app_server]},{registered, [prim_app_server]},{included_applications, [incl_app]},{start_phases, [{init,[]}, {go,[]}]},{applications, [kernel, stdlib, sasl]},{mod, {application_starter,[prim_app_cb,[]]}},{env, [{file, "/usr/local/log"}]}]}.{application, incl_app,[{description, "Included application"},{vsn, "1"},{modules, [incl_app_cb, incl_app_sup, incl_app_server]},{registered, []},{start_phases, [{go,[]}]},{applications, [kernel, stdlib, sasl]},{mod, {incl_app_cb,[]}}]}.
启动包含了其他应用的原初应用,跟正常启动应用是一样的,也就是说:
- 应用控制器为应用创建 application master 。
- master 调用 Module:start(normal, StartArgs) 启动顶层 supervisor 。
然后,原初应用和被包含应用按照从上到下从左到右的顺序,master 依次为它们 start phase 。对每个应用,master 按照原初应用中指定的 phase 顺序依次调用 Module:start_phase(Phase, Type, PhaseArgs) ,其中当前应用的 start_phases 中未指定的 phase 会被忽略。
被包含应用的 .app 文件需要如下内容:
- {mod, {Module,StartArgs}} 项必须有。这个选项指定了应用的回调模块。StartArgs 会被忽略,因为只有原初应用会调用 Module:start/2 。
- 如果被包含的应用本身包含了其他应用,则需要使用 {mod, {application_starter, [Module,StartArgs]}} 。
- {start_phases, [{Phase,PhaseArgs}]} 字段必须要有,并且这个列表必须是原初应用指定的 Phase 的子集。
启动上文定义的 prim_app 时,在 application:start(prim_app) 返回之前,应用控制器会调用下面的回调:
application:start(prim_app)=> prim_app_cb:start(normal, [])=> prim_app_cb:start_phase(init, normal, [])=> prim_app_cb:start_phase(go, normal, [])=> incl_app_cb:start_phase(go, normal, []) ok
9 Distributed Applications
9.1 引言
在拥有多个节点的分布式系统中,有必要以分布式的方式来管理应用。如果某应用所在的节点崩溃,则在另一个节点重启这个应用。
这样的应用被称为分布式应用。注意,分布式指的是应用的“管理”。如果从跨节点使用服务的角度来说,所有的应用都能分布式。
分布式的应用可以在节点间迁移,所以需要寻址机制来确保不管它在哪个节点都能被其他应用访问到。这个问题不在此讨论,可通过 Kernel 应用的 global 和 pg2 模块的某些功能来实现。
9.2 配置分布式应用
分布式的应用受两个东西控制,应用控制器(application_controller)和分布式应用控制进程(dist_ac)。这两个都是 Kernel 应用的一部分。所以分布式应用是通过配置 Kernel 应用来指定的,可以使用下面的配置参数(详见 kernel 文档):
distributed = [{Application, [Timeout,] NodeDesc}]
- 指定了应用 Application = atom() 能在哪里运行。
- NodeDesc = [Node | {Node,...,Node}] 是一个节点名列表,按优先级排列。元组 {} 中的节点没有先后顺序。
- Timeout = integer() 指定了等待多少毫秒后在其他节点上重启应用。默认为0。
为了正确地管理分布式应用,可运行应用的节点必须互相连接,协商应用在哪里启动。可在 Kernel 中使用下面的配置参数:
- sync_nodes_mandatory = [Node] - 指定了必须启动的其他节点(在 sync_nodes_timeout 指定的时间内)。
- sync_nodes_optional = [Node] - 指定了可以启动的其他节点(在 sync_nodes_timeout 指定的时间内)。
- sync_nodes_timeout = integer() | infinity- 指定了等待其他节点启动的超时时长,单位毫秒。
节点启动时会等待所有 sync_nodes_mandatory 和 sync_nodes_optional 中的节点启动。如果所有节点都启动了,或必须启动的节点启动了,sync_nodes_timeout 时长后所有的应用会被启动。如果有必须的节点没启动,当前节点会终止。
例:
应用 myapp 在 cp1@cave 中运行。如果此节点终止,myapp 将在 cp2@cave 或 cp3@cave 节点上重启。cp1@cave 的系统配置 cp1.config 如下:
[{kernel,[{distributed, [{myapp, 5000, [cp1@cave, {cp2@cave, cp3@cave}]}]},{sync_nodes_mandatory, [cp2@cave, cp3@cave]},{sync_nodes_timeout, 5000}]} ].
cp2@cave 和 cp3@cave 的系统配置也是一样的,除了必须启动的节点分别是 [cp1@cave, cp3@cave] 和 [cp1@cave, cp2@cave] 。
注意:所有节点的 distributed 和 sync_nodes_timeout 值必须一致,否则该系统行为不会被定义。
9.3 启动和终止分布式应用
当所有涉及(必须启动)的节点被启动,在所有这些节点中调用 application:start(Application) 就能启动这个分布式应用。
可以用引导脚本(Releases)来自动启动应用。
应用将在参数 distributed 配置的节点列表中的第一个可用节点启动。和平常启动应用一样,创建了一个 application master,调用回调:
Module:start(normal, StartArgs)
例:
继续上一小节的例子,启动了三个节点,指定系统配置文件:
> erl -sname cp1 -config cp1 > erl -sname cp2 -config cp2 > erl -sname cp3 -config cp3
所有节点可用时,myapp 会被启动。所有节点中调用 application:start(myapp) 即可。此时它会在 cp1 中启动,如下图所示:
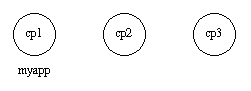
图9.1:应用 myapp - 情况 1
同样地,在所有的节点中调用 application:stop(Application) 将终止应用。
9.4 故障切换
如果应用所在的节点终止,指定的超时时长后,应用将在 distributed 配置中指定的第一个可用节点中重启。这就是故障切换。
应用在新节点中和平常一样启动,application master 调用:
Module:start(normal, StartArgs)
有一个例外,如果应用指定了 start_phases(详见Included Applications),应用将这样重启:
Module:start({failover, Node}, StartArgs) 其中 Node 为终止的节点。
例:
如果 cp1 终止,系统会等待 cp1 重启5秒,超时后在 cp2 和 cp3 中选择一个运行的应用最少的。如果 cp1 没有重启,且 cp2 运行的应用比 cp3 少,myapp 将会 cp2 节点重启。
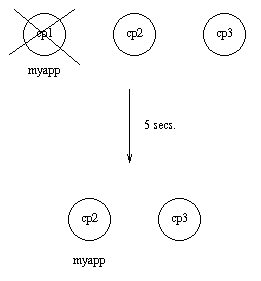
图9.2:应用 myapp - 情况 2
假设 cp2 也崩溃了,并且5秒内没有重启。myapp 将在 cp3 重启。
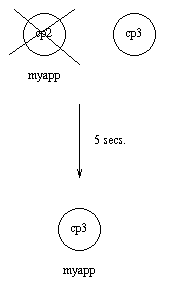
图9.3:应用 myapp - 情况 3
9.5 接管
如果一个在 distributed 配置中优先级较高的节点启动,应用会在新节点重启,在旧节点结束。这就是接管。
应用会通过如下方式启动:
Module:start({takeover, Node}, StartArgs) 其中 Node 表示旧节点。
例:
如果 myapp 在 cp3 节点运行,此时 cp2 启动,应用不会被重启,因为 cp2 和 cp3 是没有先后顺序的。
图9.4:应用 myapp - 情况 4
但如果 cp1 也重启了,函数 application:takeover/2 会将 myapp 移动到 cp1,因为对 myapp 来说 cp1 比 cp3 优先级高。此时节点 cp1 会调用 Module:start({takeover, cp3@cave}, StartArgs) 来启动应用。
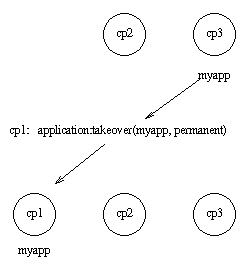
图9.5:应用 myapp - 情况 5
10 Releases
此章应与 SASL 部分的 rel、systemtools、script 教程一起阅读。
10.1 概念
当你写了一个或多个应用,你可能想用这些应用加 Erlang/OTP 应用的子集创建一个完整的系统。这就是 release 。
首先要创建一个 release 源文件,文件中指定了 release 所包含的应用。
此文件用于生成启动脚本和 release 包。可移动和安装到另一个地址的系统被称为目标系统。系统原则(System Principles)中讲了如何用 release 包创建目标系统。
10.2 Release 源文件
创建 release 源文件来描述一个 release,简称 .rel 文件。文件中指定了 release 的名字和版本号,它基于哪个版本的 ERTS,以及它由哪些应用组成:
{release, {Name,Vsn}, {erts, EVsn},[{Application1, AppVsn1},...{ApplicationN, AppVsnN}]}. Name、Vsn、EVsn 和 AppVsn 都是字符串(string)。
文件名必须为 Rel.rel ,其中 Rel 是唯一的名字。
Application (atom) 和 AppVsn 是 release 中各应用的名字和版本号。基于 Erlang/OTP 的最小的 release 由 Kernel 和 STDLIB 应用组成,这两个应用一定要在应用列表中。
要升级 release 的话,还必须包含 SASL 应用。
例:Applications 章中的 ch_app 的 release 中有下面的 .app 文件:
{application, ch_app,[{description, "Channel allocator"},{vsn, "1"},{modules, [ch_app, ch_sup, ch3]},{registered, [ch3]},{applications, [kernel, stdlib, sasl]},{mod, {ch_app,[]}}]}.
.rel 文件必须包含 kernel、stdlib 和 sasl,因为 ch_app 要用到这些应用。文件名 ch_rel-1.rel :
{release,{"ch_rel", "A"},{erts, "5.3"},[{kernel, "2.9"},{stdlib, "1.12"},{sasl, "1.10"},{ch_app, "1"}] }.
10.3 生成启动脚本
SASL 应用的 systools 模块包含了构建和检查 release 的工具。这些函数读取 .rel 和 .app 文件,执行语法和依赖检测。用 systools:make_script/1,2 来生成启动脚本(详见 System Principles):
1> systools:make_script("ch_rel-1", [local]).
ok 这个会创建启动脚本,可读版本 ch_rel-1.script 和运行时系统用到的二进制版本 ch_rel-1.boot。
- ch_rel-1 是 .rel 文件的名字去掉扩展名。
- local 是个附加选项,意思是在启动脚本中使用应用所在的目录,而不是 $ROOT/lib($ROOT 是安装后的 release 的根目录)。
这在本地测试生成启动脚本时有用处。
使用启动脚本来启动 Erlang/OTP 时,会自动加载和启动 .rel 文件中所有的应用:
% erl -boot ch_rel-1 Erlang (BEAM) emulator version 5.3Eshell V5.3 (abort with ^G) 1> =PROGRESS REPORT==== 13-Jun-2003::12:01:15 ===supervisor: {local,sasl_safe_sup}started: [{pid,<0.33.0>},{name,alarm_handler},{mfa,{alarm_handler,start_link,[]}},{restart_type,permanent},{shutdown,2000},{child_type,worker}]...=PROGRESS REPORT==== 13-Jun-2003::12:01:15 ===application: saslstarted_at: nonode@nohost... =PROGRESS REPORT==== 13-Jun-2003::12:01:15 ===application: ch_appstarted_at: nonode@nohost
10.4 创建 release 包
systools:make_tar/1,2 函数以 .rel 文件作为输入,输出一个 zip 压缩的 tar 文件,文件中包含指定应用的代码,即 release 包:
1> systools:make_script("ch_rel-1").
ok
2> systools:make_tar("ch_rel-1").
ok 一个 release 包默认包含:
- .app 文件
- .rel 文件
- 所有应用的目标代码,代码根据应用目录结构组织
- 二进制启动脚本,重命名为 start.boot
% tar tf ch_rel-1.tar lib/kernel-2.9/ebin/kernel.app lib/kernel-2.9/ebin/application.beam ... lib/stdlib-1.12/ebin/stdlib.app lib/stdlib-1.12/ebin/beam_lib.beam ... lib/sasl-1.10/ebin/sasl.app lib/sasl-1.10/ebin/sasl.beam ... lib/ch_app-1/ebin/ch_app.app lib/ch_app-1/ebin/ch_app.beam lib/ch_app-1/ebin/ch_sup.beam lib/ch_app-1/ebin/ch3.beam releases/A/start.boot releases/A/ch_rel-1.rel releases/ch_rel-1.rel
Release 包生成前,生成了一个新的启动脚本(不使用 local 选项)。在 release 包中,所有的应用目录都放在 lib 目录下。由于不知道 release 包会发布到哪里,所以不能写死绝对路径。
在 tar 文件中有两个一样的 rel 文件。最初这个文件只放在 releases 目录下,这样 release_handler 就能单独提取这个文件。解压 tar 文件后,release_handler 会自动把它拷贝到 releases/FIRST 目录。但是有时 tar 文件解包时没有 release_handler 参与(比如解压第一个目标系统),所以改为在 tar 文件中有两份,不需要再手动拷贝。
包里面还可能有 relup 文件和系统配置文件 sys.config,这些文件也会在 release 包中包含。详见 Release Handling 。
10.5 目录结构
release_handler 从 release 包安装的代码目录结构如下:
$ROOT/lib/App1-AVsn1/ebin/priv/App2-AVsn2/ebin/priv.../AppN-AVsnN/ebin/priv/erts-EVsn/bin/releases/Vsn/bin
- lib - 应用目录
- erts-EVsn/bin - Erlang 运行时系统可执行文件
- releases/Vsn - .rel 文件和启动文件 start.boot。relup 和 sys.config 也在此目录下
- bin - 最上层的 Erlang 运行时系统可执行文件
应用不一定要放在 $ROOT/lib 目录。因此可以有多个安装目录,包含系统的不同部分。例如,上面的例子可以拓展成:
$SECOND_ROOT/.../SApp1-SAVsn1/ebin/priv/SApp2-SAVsn2/ebin/priv.../SAppN-SAVsnN/ebin/priv$THIRD_ROOT/TApp1-TAVsn1/ebin/priv/TApp2-TAVsn2/ebin/priv.../TAppN-TAVsnN/ebin/priv
$SECOND_ROOT 和 $THIRD_ROOT 在调用 systools:make_script/2 函数时作为参数传入。
无磁盘或只读客户端
如果系统由无磁盘的或只读的客户端节点组成,$ROOT 目录中还会有一个 clients 目录。只读的节点就是节点在一个只读文件系统中。
每个客户端节点在 clients 中有一个子目录。每个子目录的名字是对应的节点名。一个客户端目录至少包含 bin 和 releases 两个子目录。这些目录用来存放 release 的信息,以及把当前 release 指派给客户端。$ROOT 目录如下所示:
$ROOT/.../clients/ClientName1/bin/releases/Vsn/ClientName2/bin/releases/Vsn.../ClientNameN/bin/releases/Vsn
这个结构用于所有客户端都运行在同类型的 Erlang 虚拟机上。如果有不同类型的 Erlang 虚拟机,或者在不同的操作系统中,可以把 clients 分成每个类型一个子目录。或者每个类型设置一个 $ROOT。此时 $ROOT 目录相关的一些子目录都需要包含进来:
$ROOT/.../clients/Type1/lib/erts-EVsn/bin/ClientName1/bin/releases/Vsn/ClientName2/bin/releases/Vsn.../ClientNameN/bin/releases/Vsn.../TypeN/lib/erts-EVsn/bin...
这个结构中,Type1 的客户端的根目录为 $ROOT/clients/Type1 。
11 Release Handling
11.1 Relase 管理原则
Erlang 的一个重要特点就是可以在运行时改变模块代码,即 Erlang Reference Manual(参考手册)中说的代码替换。
基于这个特点,OTP 应用 SASL 提供在运行时升级和降级整个 release 的框架。这就是 release 管理。
这个框架包含:
- 线下支持 - 用 systools 模块生成脚本和创建 release 包
- 线上支持 - 用 release_handler 打包和安装 release 包
包含 release 管理的基于 Erlang/OTP 的最小的系统,由 Kernel、STDLIB 和 SASL 应用组成。
Release 管理工作流
步骤 1:按 Releases 章所述创建一个 release。
步骤 2:在目标环境中安装 release 。如何安装第一个目标系统,详见 System Principles 文档。
步骤 3:在开发环境中修改代码(比如错误修复)。
步骤 4:某个时间点,需要创建新版本 release 。更新相关的 .app 文件,创建 .rel 文件。
步骤 5:为每个修改的应用,创建 .appup 文件(应用升级文件)。该文件描述了怎么在应用的新旧版本间升降级。
步骤 6:基于 .appup 文件,创建 relup 文件 (release 升级文件)。该文件描述了怎么在整个 release 的新旧版本间升降级。
步骤 7:创建一个新的 release 包,放到目标系统上。
步骤 8:使用 release handler 解包。
步骤 9:使用 release handler 安装新版 release 包。执行 relup 文件中的指令:添加、删除或重新加载模块,启动、终止或重启应用,等等。有时需要重启整个模拟器。
- 如果安装失败,系统会被重启。默认使用旧版本 release 。
- 如果安装成功,新版本会变为默认版本,系统重启时会使用新版本。
Release 管理特性
Appup Cookbook 章中有 .appup 文件的示例,包含了典型的运行时系统可以轻松处理的案例。然而有些情况下 release 管理会很复杂,例如:
- 复杂或者环形的依赖关系会让事情变得很复杂,很难决定以什么顺序执行才能不引起系统错误。依赖可能存在于:
- 节点之间
- 进程之间
- 模块之间
- 在 release 管理过程中,不受影响的进程会继续正常执行。这可能导致超时或其他问题。例如,挂起使用某模块的进程,到加载该模块新版本的过程中,创建的新进程可能执行旧代码。
所以建议代码做尽可能小的改动,永远保持向后兼容。
11.2 必要条件
为了正确地执行 release 管理,运行时系统必须知道当前运行哪个 release 。必须能在运行时,改变重启时要用哪个启动脚本和系统配置文件,使其崩溃时还能生效。所以,Erlang 必须以嵌入式系统方式启动,详见 Embedded System 文档。
为了系统重启顺利,系统启动时必须启动心跳监测,详见 ERTS 部分的 erl 手册和 Kernel 部分的 heart(3) 手册。
其他必要条件:
- Release 包中的启动脚本必须和 release 包从同一个 .rel 文件中生成。升降级时,应用信息从该脚本中获取。
- 系统只能有一个系统配置文件 sys.config 。如果文件存在,创建 release 包时会自动包含进来。
- 所有版本的 release(除了第一个),必须包含 relup 文件。如果文件存在,创建 release 包时会自动包含进来。
11.3 分布式系统
如果系统由多个节点组成,每个节点可以拥有自己的 release 。release_handler 是一个本地注册的进程,升降级时只能在节点中调用。Release 管理指令 sync_nodes 可以用来同步多个节点的 release 管理进程,详见 SASL 的 appup(4) 手册。
11.4 Release 管理指令
OTP 支持一系列 Release 管理指令,在创建 appup 文件时会用到。release_handler 能理解其中一部分,低级指令。还有一些高级指令,是为了用户方便而设计的,调用 systools:make_relup 时会被转化成低级指令。
此节描述了最常用的指令。完整的指令列表可见 SASL 的 appup(4) 手册。
首先,给出一些定义:
- Residence module(驻地模块) - 模块中有进程的尾递归循环函数(进程 loop 所在)。如果多个模块有这些函数,所有这些模块都是这个进程的 residence 模块。
- Functional module(功能模块) - 不是任何进程的 residence 模块的模块。
对一个 OTP behaviour 实现的进程来说,behaviour 模块就是它的驻地模块,回调模块就是功能模块。
load_module
如果模块做了简单的扩展,加载模块的新版本并移除旧版本就行了。这就是简单的代码替换,使用如下指令即可:
{load_module, Module} update
如果有复杂的修改,比如改了 gen_server 的内部状态格式,简单的代码替换就不够了。必须做到:
- 挂起使用该模块的进程(避免它们在代码替换完成前处理请求)。
- 要求进程修改内部状态格式,并切换到新版本代码。
- 移除旧代码。
- 恢复进程。
这个就是同步代码替换,使用如下指令:
{update, Module, {advanced, Extra}}
{update, Module, supervisor} 当要改变上述 behaviour 的内部状态时,使用 {advanced,Extra} 。它会导致进程调用回调函数 code_change,传递 Extra 和一些其他信息作为参数。详见对应 behaviour 和 Appup Cookbook 。
改变监程的启动规格时使用 supervisor 参数。详见 Appup Cookbook 。
当模块更新时,release_handler 会遍历各应用的监控树,检查所有的子进程规格,找到用到该模块的进程:
{Id, StartFunc, Restart, Shutdown, Type, Modules} 进程用到了某模块,意思就是该模块在子进程规格的 Modules 列表中。
如果 Modules=dynamic,如事件管理器,则事件管理器会通知 release_handler 当前安装的事件处理器列表(gen_event),它会检测这个列表的模块名。
release_handler 通过 sys:suspend/1,2 、sys:change_code/4,5 和 sys:resume/1,2 来挂起、要求切换代码以及恢复进程。
add_module 和 delete_module
使用下列指令引入新模块:
{add_module, Module} 这条指令加载了新模块,在嵌入模式运行 Erlang 时必须使用它。交互模式下可以不使用这条指令,因为代码服务器会自动搜寻和加载未加载的模块。
delete_module 与 add_module 相反,它能卸载模块:
{delete_module, Module} 当这条指令执行时,以 Module 为驻地模块的所有进程都会被杀死。用户必须保证在卸载模块前,所有涉及进程都终止,以避免无谓的 supervisor 重启。
应用指令
添加应用:
{add_application, Application} 添加一个应用,会先用 add_module 指令加载所有 .app 文件中 modules 字段所列模块,然后启动应用。
移除应用:
{remove_application, Application} 移除应用会终止应用,并且使用 delete_module 指令卸载模块,最后会从应用控制器卸载应用的规格信息。
重启应用:
{restart_application, Application} 重启应用会先终止应用再启动应用,相当于连续使用 remove_application 和 add_application 。
apply (低级指令)
让 release_handler 调用任意函数:
{apply, {M, F, A}} release_handler 会执行 apply(M, F, A) 。
restart_new_emulator (低级指令)
这条指令用于改变模拟器版本,或者升级核心应用 Kernel、STDLIB 或 SASL 。如果因为某种原因需要系统重启,则应该使用 restart_emulator 指令。
这条指令要求系统启动时必须启动心跳监测,详见 ERTS 部分的 erl 手册和 Kernel 部分的 heart(3) 手册。
restart_new_emulator 必须是 relup 文件的第一条指令,如果使用 systools:make_relup/3,4 生成 relup 文件,会默认放在最前面。
当 release_handler 执行这条命令,它会先生成一个临时的启动文件,文件指定新版本的模拟器和核心应用以及旧版本的其他应用。然后它调用 init:reboot()(详见 Kernel 的 init(3) 手册)关闭当前模拟器。所有进程优雅地终止,然后 heart 程序使用临时启动文件重启系统。重启后,会执行其他的 relup 指令,这个过程定义在临时启动文件中。
警告:这个机制会在启动时使用新版本的模拟器和核心应用,但是其他应用仍是旧版本。所以要额外注意兼容问题。有时核心应用中会做不兼容的修改。如果可能,新旧代码先共存于一个 release,线上更新完成后再在此后的新 release 弃用旧代码。为了保证应用不会因为不兼容的修改而崩溃,应尽可能早地停止调用弃用函数。
升级完成会写一条 info 报告。可以通过调用 release_handler:which_releases(current) ,检查它是否返回预期的新的 release 。
当新模拟器可操作时,必须持久化新的 release 版本。否则系统重启时仍会使用旧版。
在 UNIX 系统中,release_handler 会告诉 heart 程序使用哪条命令来重启系统。此时 heart 程序使用的环境变量 HEART_COMMAND 会被忽略,默认命令为 $ROOT/bin/start 。也可以通过使用 SASL 的配置参数 start_prg 来指定其他命令,详见 sasl(6) 手册。
restart_emulator (低级命令)
这条命令不用于 ERTS 或核心应用的升级。在所有升级指令执行完后,可以用它来强制重启模拟器。
relup 文件只能有一个 restart_emulator 指令,且必须放在最后。如果使用 systools:make_relup/3,4 生成 relup 文件,会默认放在最后。
当 release_handler 执行这条命令,它会调用 init:reboot()(详见 Kernel 的 init(3) 手册)关闭当前模拟器。所有进程优雅地终止,然后 heart 程序使用新版 release 来重启系统。重启后不会执行其他升级指令。
11.5 应用升级文件
创建应用升级文件来指定如何在当前版本和旧版本应用之间升降级,简称 .appup 文件。文件名为 Application.appup ,其中 Application 是应用名:
{Vsn,[{UpFromVsn1, InstructionsU1},...,{UpFromVsnK, InstructionsUK}],[{DownToVsn1, InstructionsD1},...,{DownToVsnK, InstructionsDK}]}. - Vsn - 字符串,当前应用版本号( .app 文件中的版本号)。
- UpFromVsn - 升级前的版本号。
- DownToVsn - 要降级至的版本号。
- Instructions - release 管理指令列表。
.appup 文件的语法和内容,详见 SASL 的 appup(4) 手册。
Appup Cookbook 中有典型案例的 .appup 文件示例。
例:Releases 章中的例子。如果想在 ch3 中添加函数 available/0 ,返回可用 channel 的数量(修改的时候,在原目录的副本里改,这样第一版仍然可用):
-module(ch3). -behaviour(gen_server).-export([start_link/0]). -export([alloc/0, free/1]). -export([available/0]). -export([init/1, handle_call/3, handle_cast/2]).start_link() ->gen_server:start_link({local, ch3}, ch3, [], []).alloc() ->gen_server:call(ch3, alloc).free(Ch) ->gen_server:cast(ch3, {free, Ch}).available() ->gen_server:call(ch3, available).init(_Args) ->{ok, channels()}.handle_call(alloc, _From, Chs) ->{Ch, Chs2} = alloc(Chs),{reply, Ch, Chs2}; handle_call(available, _From, Chs) ->N = available(Chs),{reply, N, Chs}.handle_cast({free, Ch}, Chs) ->Chs2 = free(Ch, Chs),{noreply, Chs2}.
创建新版 ch_app.app 文件,修改版本号:
{application, ch_app,[{description, "Channel allocator"},{vsn, "2"},{modules, [ch_app, ch_sup, ch3]},{registered, [ch3]},{applications, [kernel, stdlib, sasl]},{mod, {ch_app,[]}}]}.
要让 ch_app 从版本 "1" 升到 "2" 或从 "2" 降到 "1",只需要加载对应版本的 ch3 回调即可。在 ebin 目录创建 ch_app.appup 应用升级文件:
{"2",[{"1", [{load_module, ch3}]}],[{"1", [{load_module, ch3}]}]
}.
11.6 Release 升级文件
要指定如何在 release 的版本间切换,要创建一个 release 升级文件,简称 relup 文件。
可以使用 systools:make_relup/3,4 自动生成此文件,将相关版本的 .rel 文件、.app 文件和 .appup 文件作为输入。它不包含要增删哪些应用,哪些应用要升降级。这些指令会从 .appup 文件中获取,按正确的顺序转化成低级指令列表。
如果 relup 文件很简单,可以手动创建它。它只包含低级指令。
relup 文件的语法和内容详见 SASL 的 relup(4) 手册。
继续前小节的例子:已经有新版 "2" 的 ch_app 应用以及 .appup 文件。还需新版的 .rel 文件。文件名 ch_rel-2.rel ,release 版本从 "A" 变为 "B":
{release,{"ch_rel", "B"},{erts, "5.3"},[{kernel, "2.9"},{stdlib, "1.12"},{sasl, "1.10"},{ch_app, "2"}] }.
生成 relup 文件:
1> systools:make_relup("ch_rel-2", ["ch_rel-1"], ["ch_rel-1"]).
ok 生成了一个 relup 文件,文件中有从版本 "A" ("ch_rel-1") 升级到版本 "B" ("ch_rel-2") 和从 "B" 降到 "A" 的指令。
新版和旧版的 .app 和 .rel 文件、.appup 文件和新的 .beam 文件都必须在代码路径中。代码路径可以使用选项 path 来扩展:
1> systools:make_relup("ch_rel-2", ["ch_rel-1"], ["ch_rel-1"],
[{path,["../ch_rel-1",
"../ch_rel-1/lib/ch_app-1/ebin"]}]).
ok
11.7 安装 release
有了一个新版的 release,就可以创建 release 包并放到目标环境中去。
在运行时系统中安装新版 release 会用到 release handler 。它是 SASL 应用的一个进程,用于处理 release 包的解包、安装和移除。它通过 release_handler 模块通讯。详见 SASL 的 release_handler(3) 手册。
假设有一个可操作的目标系统,安装根目录为 $ROOT,新版 release 包应拷贝到 $ROOT/releases 目录下。首先,解包。从包中提取文件:
release_handler:unpack_release(ReleaseName) => {ok, Vsn}
- ReleaseName - release 包的名字,不包含 .tar.gz 后缀。
- Vsn - release 的版本号,包的 .rel 文件中定义的。
release_handler:install_release(Vsn) => {ok, FromVsn, []} 如果安装过程中有错误发生,系统会使用旧版 release 重启。如果安装成功,后续系统会用新版本,不过如果系统中途有重启的话,还是会使用旧版本。
必须把新安装的 release 持久化才能让它成为默认版本,让之前的版本变成旧版本:
release_handler:make_permanent(Vsn) => ok
系统在 $ROOT/releases/RELEASES 和 $ROOT/releases/start_erl.data 中保存版本信息。
从 Vsn 降级到 FromVsn 时,须再次调用 install_release:
release_handler:install_release(FromVsn) => {ok, Vsn, []} 安装了的但是还没持久化的 release 可以被移除。移除意味着 release 的信息会被从 $ROOT/releases/RELEASES 中移除。代码也会被移除,也就是说,新的应用目录和 $ROOT/releases/Vsn 目录都会被删掉。
release_handler:remove_release(Vsn) => ok
继续前小节的例子
步骤 1)创建 Releases 中的版本 "A" 的目标系统。这回 sys.config 必须包含在 release 包中。如果不需要任何配置,这个文件中为一个空列表:
[].
步骤 2)启动系统。现实中会以嵌入式系统启动。不过,使用 erl 和正确的启动脚本和配置就足以用来举例说明:
% cd $ROOT % bin/erl -boot $ROOT/releases/A/start -config $ROOT/releases/A/sys ...
步骤 3)在另一个 Erlang shell,生成启动脚本,并创建版本 "B" 的 release 包。记得包含 sys.config(可能有变化)和 relup 文件,详见 Release 升级文件。
1> systools:make_script("ch_rel-2").
ok
2> systools:make_tar("ch_rel-2").
ok 新的 release 包现在包含版本 "2" 的 ch_app 和 relup 文件:
% tar tf ch_rel-2.tar lib/kernel-2.9/ebin/kernel.app lib/kernel-2.9/ebin/application.beam ... lib/stdlib-1.12/ebin/stdlib.app lib/stdlib-1.12/ebin/beam_lib.beam ... lib/sasl-1.10/ebin/sasl.app lib/sasl-1.10/ebin/sasl.beam ... lib/ch_app-2/ebin/ch_app.app lib/ch_app-2/ebin/ch_app.beam lib/ch_app-2/ebin/ch_sup.beam lib/ch_app-2/ebin/ch3.beam releases/B/start.boot releases/B/relup releases/B/sys.config releases/B/ch_rel-2.rel releases/ch_rel-2.rel
步骤 4)拷贝 release 包 ch_rel-2.tar.gz 到 $ROOT/releases 目录。
步骤 5)在运行的目标系统中,解包:
1> release_handler:unpack_release("ch_rel-2").
{ok,"B"} 新版本应用 ch_app-2 被安装在 $ROOT/lib 目录,在 ch_app-1 附近。kernel、stdlib 和 sasl 目录不受影响,因为它们没有改变。
$ROOT/releases 下创建了一个新目录 B,其中包含了 ch_rel-2.rel、start.boot、sys.config 和 relup 。
步骤 6)检查 ch3:available/0 是否可用:
2> ch3:available().
** exception error: undefined function ch3:available/0 步骤 7)安装新 release 。$ROOT/releases/B/relup 中的指令会一一被执行,新版 ch3 被加载进来。函数 ch3:available/0 现在可用了:
3> release_handler:install_release("B").
{ok,"A",[]}
4> ch3:available().
3
5> code:which(ch3).
".../lib/ch_app-2/ebin/ch3.beam"
6> code:which(ch_sup).
".../lib/ch_app-1/ebin/ch_sup.beam" ch_app 中的进程代码不变,例如,supervisor 还在执行 ch_app-1 的代码。
步骤 8)如果目标系统现在重启,它会重新使用 "A" 版本。要在重启时使用 "B" 版本,必须持久化:
7> release_handler:make_permanent("B").
ok
11.8 更新应用规格
当新版 release 安装,所有加载的应用规格会自动更新。
注意:新的应用规格从 release 包中的启动脚本中获取。所以启动脚本必须和 release 包从同一个 .rel 文件中生成。
确切地说,应用配置参数会根据下面的内容自动更新(优先级递增):
- 启动脚本从新的应用资源文件 App.app 中获取到的信息。
- 新的 sys.config
- 命令行参数 -App Par Val
也就是说被其他系统配置文件设置的值,以及使用 application:set_env/3 设置的值都会被无视。
当安装好的 release 被设置为永久时,系统进程 init 会指向新的 sys.config 文件。
安装后,应用控制器会比较所有运行中的应用的新旧配置参数,并调用回调:
Module:config_change(Changed, New, Removed)
- Module - .app 文件中定义的 mod 字段,应用回调模块。
- Changed 和 New 是一个 {Par,Val} 列表,包含了所有改变和增加的配置参数。
- Removed 是被删除的所有配置参数 Par 的列表。
这个函数是可选的,在实现应用回调模块时可以省略。
12 Appup Cookbook
此章包含典型案例的升降级 .appup 文件的例子。
12.1 修改功能模块
如果功能模块被修改,例如新加了一个函数或修复了一个 bug,简单的代码替换就够了:
{"2",[{"1", [{load_module, m}]}],[{"1", [{load_module, m}]}]
}.
12.2 修改驻地模块
如果系统完全根据 OTP 设计原则来实现,除系统进程和特殊进程外的所有进程,都会驻扎在某个 behavior 中,supervisor、gen_server、gen_fsm、gen_statem 或 gen_event 。这些都属于 STDLIB 应用,升降级一般来说需要模拟器重启。
因此 OTP 没有支持修改驻地模块,除了一些特殊进程。
12.3 修改回调模块
回调模块属于功能模块,代码扩展只需要简单的代码替换就行。
例:前文 Relase Handling 中的例子,在 ch3 中添加一个函数,ch_app.appup 内容如下:
{"2",[{"1", [{load_module, ch3}]}],[{"1", [{load_module, ch3}]}]
}. OPT 还支持修改 behaviour 进程的内部状态,详见下一小节。
12.4 修改内部状态
这种情况下,简单的代码替换不能解决问题。在切换到新版回调模块前,进程必须使用 code_change 回调显示地修改它的状态。此时要用到同步代码替换(译者补充:同步即需要等待进程作出一些反应)。
例:前文 gen_server Behaviour 中的 gen_server ch3,内部状态为 Chs,表示可用的 channel 。假设你想增加一个计数器 N,记录 alloc 请求次数。状态的格式必须变为 {Chs,N} 。
.appup 文件内容如下:
{"2",[{"1", [{update, ch3, {advanced, []}}]}],[{"1", [{update, ch3, {advanced, []}}]}]
}. update 指令的第三个参数是一个元组 {advanced,Extra} ,意思是在加载新版模块之前,受影响的进程要先修改状态。修改状态是通过让进程调用 code_change 回调来完成的(详见 STDLIB 的 gen_server(3) 手册)。Extra(此例中是 [])会被传递到 code_change 函数:
-module(ch3). ... -export([code_change/3]). ... code_change({down, _Vsn}, {Chs, N}, _Extra) ->{ok, Chs}; code_change(_Vsn, Chs, _Extra) ->{ok, {Chs, 0}}.
code_change 第一个参数,如果降级则为 {down,Vsn},升级则为 Vsn 。Vsn 是模块的“原”版,即升级前的版本。
如果模块有 vsn 属性的话,版本即该属性的值。ch3 没有这个属性,所以此时版本号为 beam 文件的校验和(大整数),此处它不重要被忽略。
ch3 的其他回调也要修改,还要加其他接口函数,不过此处不赘述。
12.5 模块依赖
在模块中增加了一个接口函数,比如前文 Release Handling 中的,在 ch3 中增加 available/0 。
假设在另一个模块 m1 会调用此函数。在 release 升级过程中,如果先加载新版 m1,在 ch3 加载前 m1 调用 ch3:available/0 会引发一个 runtime error 。
所以升级时 ch3 必须在 m1 之前加载,降级时则相反。即 m1 依赖于 ch3 。在 release 处理指令中,用 DepMods 元素来表示:
{load_module, Module, DepMods}
{update, Module, {advanced, Extra}, DepMods} DepMods 是模块列表,表示 Module 所依赖的模块。
例:myapp 应用的模块 m1 依赖于 ch_app 应用的模块 ch3,从 "1" 升级到 "2",或从 "2" 降级到 "1" 时:
myapp.appup:{"2",[{"1", [{load_module, m1, [ch3]}]}],[{"1", [{load_module, m1, [ch3]}]}] }.ch_app.appup:{"2",[{"1", [{load_module, ch3}]}],[{"1", [{load_module, ch3}]}] }.
如果 m1 和 ch_app 属于同一个应用,.appup 文件如下:
{"2",[{"1",[{load_module, ch3},{load_module, m1, [ch3]}]}],[{"1",[{load_module, ch3},{load_module, m1, [ch3]}]}]
}. 降级时也是 m1 依赖于 ch3 。systools 能区分升降级,生成正确的 relup 文件,升级时先加载 ch3 再 m1,降级时先加载 m1 再 ch3 。
12.6 修改特殊进程的代码
这种情况下,简单的代码替换不能解决问题。加载特殊进程的新版驻地模块时,进程必须调用它的 loop 函数的全名,来切换至新代码。此时,必须用同步代码替换。
注意:用户自定义的驻地模块,必须在特殊进程的子进程规格的 Modules 列表中。否则 release_handler 会找不到该进程。
例:前文 sys and proc_lib 中的例子。通过 supervisor 启动时,子进程规格如下:
{ch4, {ch4, start_link, []},permanent, brutal_kill, worker, [ch4]} 如果 ch4 是应用 sp_app 的一部分,从版本 "1" 升级到版本 "2" 时,要加载该模块的新版本,sp_app.appup 内容如下:
{"2",[{"1", [{update, ch4, {advanced, []}}]}],[{"1", [{update, ch4, {advanced, []}}]}]
}. update 指令必须包含元组 {advanced,Extra} 。这条指令让特殊进程调用回调 system_code_change/4,这个回调必须要实现。Extra(此例中为 [] ),会被传递给 system_code_change/4 :
-module(ch4). ... -export([system_code_change/4]). ...system_code_change(Chs, _Module, _OldVsn, _Extra) ->{ok, Chs}.
- 第一个参数是内部状态 State,从函数 sys:handle_system_msg(Request, From, Parent, Module, Deb, State) 中传入,sys:handle_system_msg 是特殊进程在收到系统消息时调用的。ch4 的内容状态是可用的 Chs 集。
- 第二个参数是模块名( ch4 )。
- 第三个参数是 Vsn 或 {down,Vsn},跟 12.4 小节中 gen_server:code_change/3 的参数一样。
此例中,只用到了第一个参数,函数仅返回内部状态。如果代码只是被扩展,这样就 ok 了。如果内部状态改变(类似 12.4 小节),要在这个函数中进行改变,并返回 {ok,Chs2} 。
12.7 修改 supervisor
supervisor behaviour 支持修改内部状态,也就是修改重启策略、最大重启频率以及子进程规格。
可以添加或删除子进程,不过不是自动处理的。必须在 .appup 中指定。
修改属性
由于 supervisor 内部状态有改动,必须使用同步代码替换。需要一个特殊的 update 指令。
首先,加载新版回调模块(升或降)。然后检测 init/1 的新的返回值,并据此修改内部状态。
supervisor 的升级指令如下:
{update, Module, supervisor} 例:把 ch_sup 的重启策略,从 one_for_one 变为 one_for_all,要改 ch_sup.erl 中的回调函数 init/1 :
-module(ch_sup). ...init(_Args) ->{ok, {#{strategy => one_for_all, ...}, ...}}.
文件 ch_app.appup :
{"2",[{"1", [{update, ch_sup, supervisor}]}],[{"1", [{update, ch_sup, supervisor}]}]
}. 修改子进程规格
修改已存在的子进程规格,指令和 .appup 文件与前面的修改属性一样:
{"2",[{"1", [{update, ch_sup, supervisor}]}],[{"1", [{update, ch_sup, supervisor}]}]
}. 这些修改不会影响已存在的子进程。例如,修改启动函数,只会影响子进程重启。
子进程规格的 id 不能修改。
修改子进程规格的 Modules 字段,会影响 release_handler 进程自身,因为这个字段用于在同步代码替换中,确认哪些进程收到影响。
增加和删除子进程
如前文所说,修改子进程规格,不影响现有子进程。新的规格会自动添加,但是不会删除废弃规格。子进程不会自动重启或终止,必须使用 apply 指令来操作。
例:假设从 "1" 升到 "2" 时, ch_sup 增加了一个子进程 m1。降级时 m1 会被删除:
{"2",[{"1",[{update, ch_sup, supervisor},{apply, {supervisor, restart_child, [ch_sup, m1]}}]}],[{"1",[{apply, {supervisor, terminate_child, [ch_sup, m1]}},{apply, {supervisor, delete_child, [ch_sup, m1]}},{update, ch_sup, supervisor}]}]
}. 指令的顺序很重要。
supervisor 必须被注册为 ch_sup 才能让脚本生效。如果没有注册,不能从脚本中直接访问它。此时必须写一个帮助函数来寻找 supervisor 的 pid,并调用 supervisor:restart_child 。然后在脚本中使用 apply 指令调用该帮助函数。
如果模块 m1 在应用 ch_app 的版本 "2" 引入,它必须在升级时加载、降级时删除:
{"2",[{"1",[{add_module, m1},{update, ch_sup, supervisor},{apply, {supervisor, restart_child, [ch_sup, m1]}}]}],[{"1",[{apply, {supervisor, terminate_child, [ch_sup, m1]}},{apply, {supervisor, delete_child, [ch_sup, m1]}},{update, ch_sup, supervisor},{delete_module, m1}]}]
}. 如前文所述,指令的顺序很重要。升级时,必须在启动新进程之前,加载 m1、改变 supervisor 的子进程规格。降级时,子进程必须在规格改变和模块被删除前终止。
12.8 增加或删除模块
例:应用 ch_app 增加了一个新的功能模块:
{"2",[{"1", [{add_module, m}]}],[{"1", [{delete_module, m}]}]
12.9 启动或终止进程
一个根据 OTP 设计原则组织的系统中,所有的进程都是某 supervisor 的子进程,详见增加和删除子进程。
12.10 增加或移除应用
增加或移除应用时,不需要 .appup 文件。生成 relup 文件时,会比较 .rel 文件,并自动添加 add_application 和 remove_application 指令。
12.11 重启应用
当修改太复杂时(如监控树层级重构),可以重启应用。
例:增加和删除子进程中的例子,ch_sup 增加了一个子进程 m1,还可以通过重启整个应用来更新 supervisor :
{"2",[{"1", [{restart_application, ch_app}]}],[{"1", [{restart_application, ch_app}]}]
}.
12.12 修改应用规格
在执行 relup 脚本前,在安装 release 时,应用规格就自动更新了。因此,不需要在 .appup 中增加指令:
{"2",[{"1", []}],[{"1", []}]
}.
12.13 修改应用配置
可以通过修改 .app 文件中的 env 字段,来修改应用配置。
另外,还可以修改 sys.config 文件来修改应用配置参数。
12.14 修改被包含的应用
增加、移除、重启应用的 release 处理指令,只适用于原初应用。被包含应用没有相应的指令。但是因为实际上,被包含应用的最上层 supervisor 是包含它的应用的 supervisor 的子进程,我们可以手动创建 relup 文件。
例:假设一个 release 包含了应用 prim_app,它的监控树中有一个监程 prim_sup 。
在新版本 release 中,应用 ch_app 被包含进了 prim_app ,也就是说它的最上层监程 ch_sup 是 prim_sup 的子进程。
工作流如下:
步骤 1)修改 prim_sup 的代码:
init(...) ->{ok, {...supervisor flags...,[...,{ch_sup, {ch_sup,start_link,[]},permanent,infinity,supervisor,[ch_sup]},...]}}. 步骤 2)修改 prim_app 的 .app 文件:
{application, prim_app,[...,{vsn, "2"},...,{included_applications, [ch_app]},...]}.
步骤 3)创建新的 .rel 文件,包含 ch_app:
{release,...,[...,{prim_app, "2"},{ch_app, "1"}]}.
被包含的应用可以通过两种方式重启。下面会说。
应用重启
步骤 4a)一种方式,是重启整个 prim_app 应用。在 prim_app 的 .appup 文件中使用 restart_application 指令。
然而,如果这样做,relup 文件不止包含了重启(移除和添加)prim_app 的指令,它还会有启动(以及降级时移除)ch_app 的指令。因为新的 .rel 文件中有 ch_app,而旧的 .rel 文件没有。
所以,应该手动创建正确的 relup 文件,重写或在自动生成的基础上写都行。用加载/卸载 ch_app 的指令,替换启动/停止的指令:
{"B",[{"A",[],[{load_object_code,{ch_app,"1",[ch_sup,ch3]}},{load_object_code,{prim_app,"2",[prim_app,prim_sup]}},point_of_no_return,{apply,{application,stop,[prim_app]}},{remove,{prim_app,brutal_purge,brutal_purge}},{remove,{prim_sup,brutal_purge,brutal_purge}},{purge,[prim_app,prim_sup]},{load,{prim_app,brutal_purge,brutal_purge}},{load,{prim_sup,brutal_purge,brutal_purge}},{load,{ch_sup,brutal_purge,brutal_purge}},{load,{ch3,brutal_purge,brutal_purge}},{apply,{application,load,[ch_app]}},{apply,{application,start,[prim_app,permanent]}}]}],[{"A",[],[{load_object_code,{prim_app,"1",[prim_app,prim_sup]}},point_of_no_return,{apply,{application,stop,[prim_app]}},{apply,{application,unload,[ch_app]}},{remove,{ch_sup,brutal_purge,brutal_purge}},{remove,{ch3,brutal_purge,brutal_purge}},{purge,[ch_sup,ch3]},{remove,{prim_app,brutal_purge,brutal_purge}},{remove,{prim_sup,brutal_purge,brutal_purge}},{purge,[prim_app,prim_sup]},{load,{prim_app,brutal_purge,brutal_purge}},{load,{prim_sup,brutal_purge,brutal_purge}},{apply,{application,start,[prim_app,permanent]}}]}]
}. 修改监程
步骤 4b)另一种方式,是结合为 prim_sup 添加或删除子进程的指令,以及加载和卸载 ch_app 代码和应用规格的指令。
这种方式也需要手动创建 relup 文件。重写或在自动生成的基础上写都行。先加载 ch_app 的代码和应用规格,然后再更新 prim_sup 。降级时先更新 prim_sup 再卸载 ch_app 的代码和应用规格。
{"B",[{"A",[],[{load_object_code,{ch_app,"1",[ch_sup,ch3]}},{load_object_code,{prim_app,"2",[prim_sup]}},point_of_no_return,{load,{ch_sup,brutal_purge,brutal_purge}},{load,{ch3,brutal_purge,brutal_purge}},{apply,{application,load,[ch_app]}},{suspend,[prim_sup]},{load,{prim_sup,brutal_purge,brutal_purge}},{code_change,up,[{prim_sup,[]}]},{resume,[prim_sup]},{apply,{supervisor,restart_child,[prim_sup,ch_sup]}}]}],[{"A",[],[{load_object_code,{prim_app,"1",[prim_sup]}},point_of_no_return,{apply,{supervisor,terminate_child,[prim_sup,ch_sup]}},{apply,{supervisor,delete_child,[prim_sup,ch_sup]}},{suspend,[prim_sup]},{load,{prim_sup,brutal_purge,brutal_purge}},{code_change,down,[{prim_sup,[]}]},{resume,[prim_sup]},{remove,{ch_sup,brutal_purge,brutal_purge}},{remove,{ch3,brutal_purge,brutal_purge}},{purge,[ch_sup,ch3]},{apply,{application,unload,[ch_app]}}]}]
}.
12.15 修改非 Erlang 代码
修改其他语言写的代码,比如接口程序,是依赖于应用的,OTP 没有提供特别的支持。
例:修改 port 程序,假设控制这个接口的 Erlang 进程是注册为 portc 的 gen_server,通过回调 init/1 来开启接口:
init(...) ->...,PortPrg = filename:join(code:priv_dir(App), "portc"),Port = open_port({spawn,PortPrg}, [...]),...,{ok, #state{port=Port, ...}}.
要更新接口程序,gen_server 的代码必须有 code_change 回调,用来关闭接口和开启新接口(如果有需要,还可以让 gen_server 先从旧接口请求必要的数据,然后传递给新接口):
code_change(_OldVsn, State, port) ->State#state.port ! close,receive{Port,close} ->trueend,PortPrg = filename:join(code:priv_dir(App), "portc"),Port = open_port({spawn,PortPrg}, [...]),{ok, #state{port=Port, ...}}.
更新 .app 文件的版本号,并创建 .appup 文件:
["2",[{"1", [{update, portc, {advanced,port}}]}],[{"1", [{update, portc, {advanced,port}}]}] ].
确保 C 程序所在的 priv 目录被包含在新的 release 包中:
1> systools:make_tar("my_release", [{dirs,[priv]}]).
...
12.16 模拟器重启和升级
两条重启模拟器的升级指令:
- restart_new_emulator
当 ERTS、Kernel、STDLIB 或 SASL 要升级时会用到。用 systools:make_relup/3,4 生成 relup 文件会自动添加这条指令。它会在所有其他指令之前执行。详见前文的 restart_new_emulator(低级指令)。
- restart_emulator
在所有其他指令执行完后需要重启模拟器时会用到。详见前文的 restart_emulator 。
如果只需要重启模拟器,不需要其他升级指令,可以手动创建一个 relup 文件:
{"B",[{"A",[],[restart_emulator]}],[{"A",[],[restart_emulator]}]
}. 此时,release 管理框架会自动打包、解包、更新路径等,且不需要指定 .appup 文件。
12.17 OTP R15 之前的模拟器升级
从 OTP R15 开始,模拟器升级会在加载代码和运行其他应用升级指令前,使用新版的核心应用(Kernel、STDLIB 和 SASL)重启模拟器来完成模拟器升级。这要求要升级的 release 必须是 OTP R15 或更晚版本。
如果 release 是早期版本,systools:make_relup 会生成一个向后兼容的 relup 文件。所有升级指令在模拟器重启前执行,新的应用代码会被加载到旧模拟器中。如果新代码是用新模拟器编译的,而新模拟器下的 beam 文件的格式有变化,可能导致加载 beam 文件失败。用旧模拟器编译新代码,可以解决这个问题。