目录
题目来源
题目描述
示例
提示
题目解析
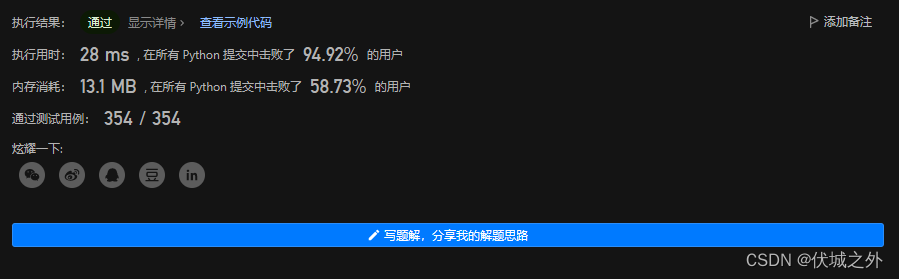
算法源码
题目来源
10. 正则表达式匹配 - 力扣(LeetCode)
题目描述
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.' 匹配任意单个字符
'*' 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
示例
示例 1
- 输入:s = "aa", p = "a"
- 输出:false
- 解释:"a" 无法匹配 "aa" 整个字符串。
示例 2
- 输入:s = "aa", p = "a*"
- 输出:true
- 解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3
- 输入:s = "ab", p = ".*"
- 输出:true
- 解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
提示
- 1 <= s.length <= 20
- 1 <= p.length <= 20
- s 只包含从 a-z 的小写字母。
- p 只包含从 a-z 的小写字母,以及字符 . 和 *。
- 保证每次出现字符 * 时,前面都匹配到有效的字符
题目解析
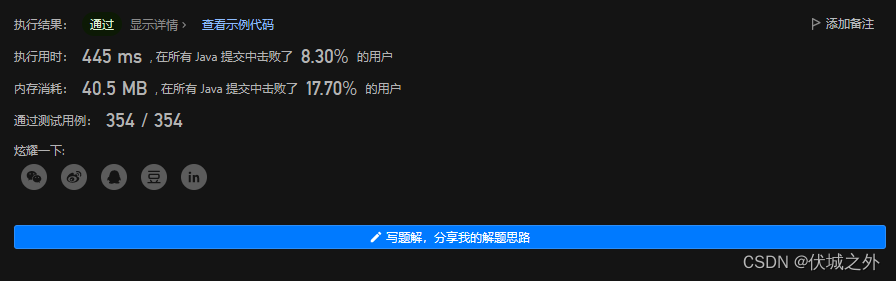
本题如果用正则表达式实现的话,逻辑非常简单,代码实现也非常简单,如下代码所示:
Java正则解法
import java.util.regex.Pattern;class Solution {public boolean isMatch(String s, String reg) {return Pattern.compile("^" + reg + "$").matcher(s).find();}
}
JS正则解法
/*** @param {string} s* @param {string} p* @return {boolean}*/
var isMatch = function(s, p) {return new RegExp(`^${p}$`).test(s);
};
Python正则解法
import re
class Solution(object):def isMatch(self, s, p):return re.compile("^"+ p +"$").match(s) is not None
但是,我们可以发现正则匹配的性能是非常差的,并且这题的目的是想让我们实现类似于正则匹配的功能,而不是让我们去套皮。
本题的最优解法是动态规划。
字符串s,正则p,现在想要确定正则p是否可以匹配字符串s。
我们假设 dp[ i ][ j ] 表示字符串s的0 ~ i部分,和正则p的0 ~ j 部分的匹配结果:
- 要么是true,即匹配
- 要么是false,即不匹配
那么此时,dp[ i ][ j ] 其实可以分情况讨论:
如果 p[ j ] == '*' 的话,
我们需要注意的是 '*' 在正则是一个量词符,用于表示它前面一个字符可能出现0次或多次。
比如p = "abc*",表示 '*' 前面的字符c可能出现0次或多次,即 p 可以匹配:
- "ab":c出现0次
- "abc":出现1次
- "abcccccc":c出现多次
那么我们不仅需要关注p[ j ],还需要关注 p [ j - 1 ],因为p[ j ]是量词符,而p[ j - 1 ]才是实际要匹配的内容字符。
比如上面例子p = "abc*"中,p[ j - 1 ] = 'c',p[ j ] = '*',而p[ j - 1 ] + p[ j ] 可以匹配字符串s最后部分的0个'c',或者1个‘c’,或者多个'c'。
如果 p[ j - 1 ] != s[ i ] 的话,
那么p[ j - 1 ] + p[ j ] 就只能匹配 s 最后的0个字符,比如例子:p = "abc*",s="ab"
如果 p[ j - 1 ] == s[ i ] 但是 p[ j - 1 ] != s[ i - 1 ],
那么p[ j - 1 ] + p[ j ]就只能匹配 s 最后的1个字符,比如例子:p = "abc*",s="abc"
如果 p[ j - 1 ] == s[ i ] 且 p[ j - 1 ] == s[ i - 1 ] 但是 p[ j - 1 ] != s[ i - 2 ],
那么p[ j - 1 ] + p[ j ]就只能匹配 s 最后的2个字符,比如例子:p = "abc*",s="abcc"
.............
如果 p[ j - 1 ] == s[ i ] 且 .... 且 p[ j - 1 ] == s[ i - k ] 但是 p [ j - 1 ] != s[ i - k - 1 ]
那么p[ j - 1 ] + p[ j ]就只能匹配 s 最后的k个字符
因此,基于上面逻辑写状态转义方程的话,有
if p[ j ] == '*':
dp[ i ][ j ] =
( not_eq(p[ j - 1 ], s[ i ]) and dp[ i ][ j - 2 ] )
or
( eq(p[ j - 1 ], s[ i ]) and not_eq(p[ j - 1 ], s[ i - 1 ]) and dp[ i - 1 ][ j - 2 ] )
or
( eq(p[ j - 1 ], s[ i ]) and eq(p[ j - 1 ], s[ i - 1 ]) and not_eq(p[ j - 1 ], s[ i - 2 ]) and dp[ i - 2 ][ j - 2 ] )
or
........
可以发现,这个状态转义方程是写不完的。因此需要简化,而dp[i][j]的简化,依赖于dp[i-1][j],下面是dp[i-1][j]的状态转义方程
if p[ j ] == '*':
dp[ i - 1 ][ j ] =
( not_eq(p[ j - 1 ], s[ i - 1 ]) and dp[ i - 1 ][ j - 2 ] )
or
( eq(p[ j - 1 ], s[ i -1 ]) and not_eq(p[ j - 1 ], s[ i - 2 ]) and dp[ i - 2 ][ j - 2 ] )
or
( eq(p[ j - 1 ], s[ i - 1 ]) and eq(p[ j - 1 ], s[ i - 2 ]) and not_eq(p[ j - 1 ], s[ i - 3 ]) and dp[ i - 3 ][ j - 2 ] )
or
........
对比,dp[i][j] 和 dp[i-1][j],可以发现,dp[i][j]的部分内容可以转化为dp[i-1][j]
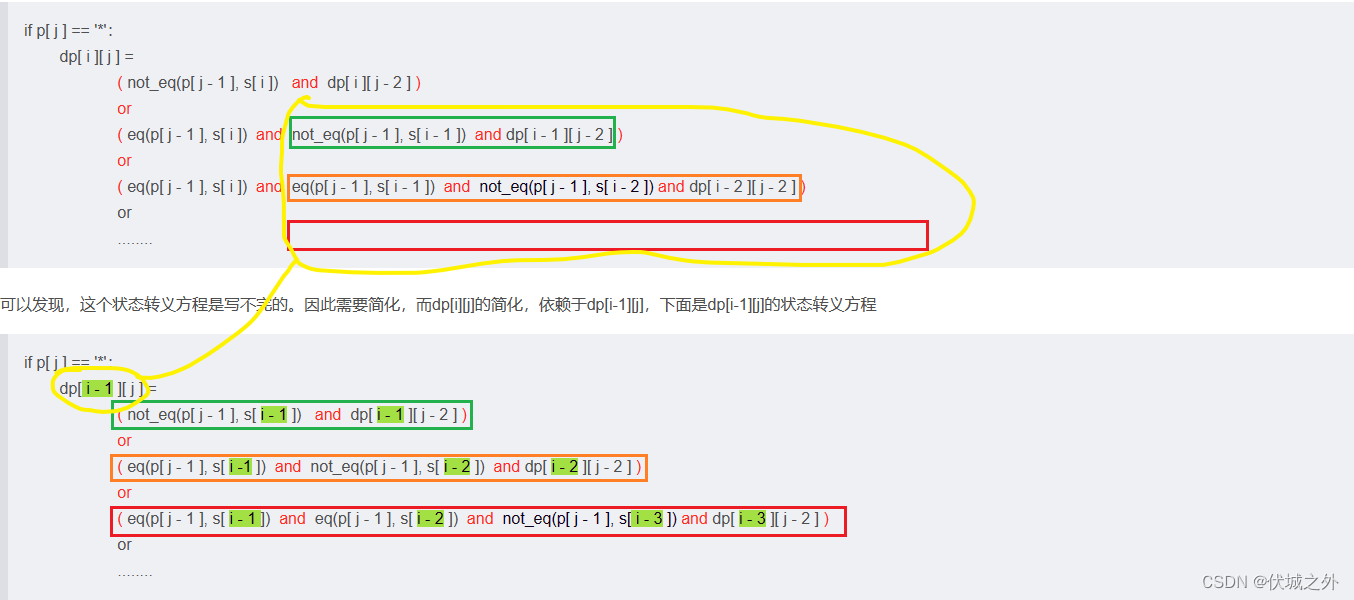
即可得状态转义方程:
if p[ j ] == '*':
dp[ i ][ j ] = ( not_eq(p[ j - 1 ], s[ i ]) and dp[ i ][ j - 2 ] ) or ( eq(p[ j - 1 ], s[ i ]) and dp[ i - 1 ][ j ] )
但是上面状态转义方程是存在问题的!!!!!
如果p[j] == '*':
- 如果 p[j-1] != s[i],那么 dp[i][j] 就可以分解为 dp[i][j-2]子问题,即正则p的j-1~j部分不匹配字符串s的任何内容,接下来只需要关心字符串s的0~i部分是否可以被正则p的0~j-2部分匹配。
- 如果 p[j-1] == s[i],那么dp[i][j] 就可以分解为 dp[i-1][j] 子问题,因为 p[j-1] == s[i],所以我们只需要关心字符串s的0~i-1部分是否可以被正则p的0~j匹配即可。
但是,实际上关于1,即使p[j-1] == s[i]的情况下,dp[i][j]也可以分解为dp[i][j-2]子问题,什么意思呢?
- 如果 p[j-1] == s[i],那么正则p的j-1~j部分依旧可以选择不匹配字符串s的任何内容,接下来如果字符串s的0~i部分是否可以被正则p的0~j-2部分匹配,那么依然可以说明s可以被p匹配。
因此,最正确的状态转义方程是:
if p[ j ] == '*':
dp[ i ][ j ] = ( dp[ i ][ j - 2 ] ) or ( eq(p[ j - 1 ], s[ i ]) and dp[ i - 1 ][ j ] )
另外关于,上面eq和not_eq该如何实现呢?
首先,如果 p[ j - 1 ] == s[ i ]的话,那么肯定是相同的,eq(p[ j - 1 ], s[ i ]) == true
其次,在正则表达式中,有一个通配符‘.’,它可以匹配任意一个实际字符,因此如果 p[ j - 1 ] == '.' 的话,则也可以认为 p[ j - 1 ] == s[ i ],即eq(p[ j - 1 ], s[ i ]) == true
如果 p[ j ] ! = '*' 的话,
那么此时的判断就非常简单了,因为p[ j ]确定不是量词符了,因此p[ j ]就只能匹配一个字符s[ i ]
如果 eq(p[ j ], s[ i ]),那么 dp[i][j] = dp[i-1][j-1],否则直接dp[i][j] = false
因此综合来看,dp[i][j]的状态转义方程如下:
if p[ j ] == '*':
dp[ i ][ j ] = ( not_eq(p[ j - 1 ], s[ i ]) and dp[ i ][ j - 2 ] ) or ( eq(p[ j - 1 ], s[ i ]) and dp[ i - 1 ][ j ] )
else:
dp[ i ][ j ] = eq(p[ j ], s[ i ]) ? dp[i - 1][j - 1] : false
当然,上面状态转义方程需要注意索引越界处理,必须要保证索引不越界。
关于,dp[i][j] 的初始化问题,比如dp[0][0]应该初始化为多少?
dp[0][0]的含义是 字符串s的0~0部分,是否可以被正则p的0~0部分匹配?
似乎说匹配也可以,不匹配也可以,因为正则为空。
因此,为了初始化容易理解,我们应该为s,p开头都加一个" ",即
s = " " + s
p = " " + p
那么其实原来dp[0][0]的问题,就变为dp[1][1]的问题,即字符串s的0~1部分,是否可以被正则p的0~1部分匹配,即" "是否可以被" "匹配,那么这里是肯定确定可以匹配的。
但是我们不能初始化dp[1][1] = true,而是需要初始化dp[0][0] = true。具体原因,大家可以基于上面状态转义方程,结合几个例子验证一下。
Java算法源码
class Solution {public boolean isMatch(String s, String p) {s = " " + s;p = " " + p;int n = s.length();int m = p.length();boolean[][] dp = new boolean[n][m];dp[0][0] = true;for (int i = 0; i < n; i++) {// 内层循环遍历的是正则p的范围,如果j=0.那么代表正则为空,此时匹配结果必然为false,而dp数组初始化时所有元素都初始化为了false,因此这里j可以从1开始for (int j = 1; j < m; j++) {if (p.charAt(j) == '*') {// 注意下面case1和case2仅为了方便理解,所以分开写了,实际时可以代入到case1 || case2中boolean case1 = j >= 2 && dp[i][j - 2];boolean case2 = eq(p.charAt(j - 1), s.charAt(i)) && i >= 1 && dp[i - 1][j];dp[i][j] = case1 || case2;} else {dp[i][j] = eq(p.charAt(j), s.charAt(i)) && i >= 1 && dp[i - 1][j - 1];}}}return dp[n - 1][m - 1];}public static boolean eq(char p, char s) {return p == s || p == '.';}
}
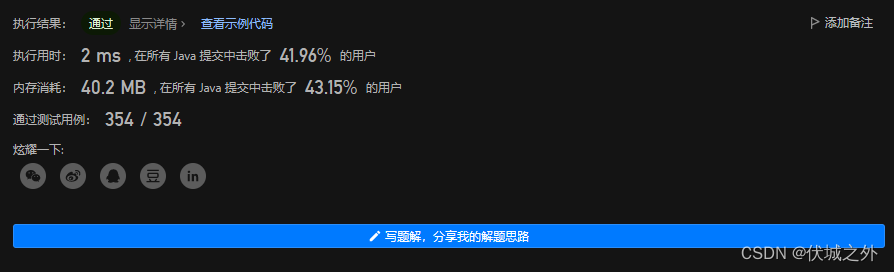
JS算法源码
/*** @param {string} s* @param {string} p* @return {boolean}*/
var isMatch = function (s, p) {s = " " + s;p = " " + p;const n = s.length;const m = p.length;const dp = new Array(n).fill(0).map(() => new Array(m).fill(false));dp[0][0] = true;for (let i = 0; i < n; i++) {// 内层循环遍历的是正则p的范围,如果j=0.那么代表正则为空,此时匹配结果必然为false,而dp数组初始化时所有元素都初始化为了false,因此这里j可以从1开始for (let j = 1; j < m; j++) {if (p[j] == "*") {// 注意下面case1和case2仅为了方便理解,所以分开写了,实际时可以代入到case1 || case2中const case1 = j >= 2 && dp[i][j - 2];const case2 = eq(p[j - 1], s[i]) && i >= 1 && dp[i - 1][j];dp[i][j] = case1 || case2;} else {dp[i][j] = eq(p[j], s[i]) && i >= 1 && dp[i - 1][j - 1];}}}return dp[n - 1][m - 1];
};function eq(p, s) {return p == s || p == ".";
}
Python算法源码
class Solution(object):def isMatch(self, s, p):s = " " + sp = " " + pn = len(s)m = len(p)dp = [[False] * m for _ in range(n)]dp[0][0] = Truefor i in range(n):# 内层循环遍历的是正则p的范围,如果j=0.那么代表正则为空,此时匹配结果必然为false,而dp数组初始化时所有元素都初始化为了false,因此这里j可以从1开始for j in range(1, m):if p[j] == '*':# 注意下面case1和case2仅为了方便理解,所以分开写了,实际时可以代入到case1 || case2中case1 = j >= 2 and dp[i][j - 2]case2 = self.eq(p[j - 1], s[i]) and i >= 1 and dp[i - 1][j]dp[i][j] = case1 or case2else:dp[i][j] = self.eq(p[j], s[i]) and i >= 1 and dp[i - 1][j - 1]return dp[n - 1][m - 1]def eq(self, p, s):return p == s or p == '.'