本文把目前机器学习技术在社会科学研究中的应用分成三类:第一,数据生成(Data Generating Process):机器学习可以帮助学者获得以前很难或无法获得的数据;第二,预测(Prediction):机器学习可以更有效地探索变量之间的相关性,进而做出较为精准的预测;第三,因果识别(Causal Inference):社会科学、特别是经济学实证研究的核心是因果识别,而机器学习在这方面也具有一定优势。
值得注意的是,本文与Athey (forthcoming) 综述性文章并不相同, 主要体现在以下两点:第一,务实性。Athey将机器学习在社会科学中的影响分为政策评估和因果推论两部分,这对应于本文第二和第三类应用。但我们认为最普遍也是最重要的应用是数据生成。据我们统计,目前社会科学中关于机器学习技术应用超过90%都是利用该技术的海量数据处理能力生成新数据或者变量。但该应用可能被Athey认为过于基础而没有在她的文章中提及。Athey详细讨论的是机器学习在因果推论中的最新进展。通过综述,我们发现这方面的应用在当前的实证研究中极其有限。本文侧重介绍其方法论基础,特别是机器学习如何与因果识别的传统方法比如DID、RD及IV的结合。因此,本文针对机器学习应用的分类更加贴近实际;第二,公式推导及受众。在预测和因果推论部分,我们使用详细的公式推导方法比较了传统线性拟合和机器学习预测间的差异,最终将差异直观地展示出来以利于一般读者理解,Athey没有采用类似方式。我们认为本文的潜在读者群更加广泛,适用于不具备机器学习专业知识的社会科学研究者。
(一)数据生成
传统社会科学实证研究基于的数据大都来自官方、问卷调查、实地调查、田野或实验室实验。最新一些研究试图利用机器学习技术拓展数据可得性。通过机器学习获得数据的主要方式是文本挖据及图像识别。
就文本信息来说,研究者关心的是文本主题。为了在海量文本数据中提取主题,学者一般使用Latent Dirichlet Allocation(LDA)方法。[13] 例如,Hansen et al. (2018) 就利用该方法探究透明度政策如何影响政府内决策过程。 这篇论文的研究背景是美国联邦公开市场委员会(Federal Open Market Committee, FOMC)在1993年通过决议公开了内部会议的发言记录。作者将该项政策视作自然实验以观察委员会成员的发言内容在该年前后的变化。研究基于的文本信息包含5万多次发言,总计500多万个单词,人工检索几乎不可能。作者便利用上文提到的LDA模型,从这些海量文本中提取40个不同的主题(图1)。任意一个成员的每一条发言都可以对应到这些主题中的一个或几个上。每个成员发言中各个主题的占比及成员间发言的相似度等指标就可以被计算出来,作者便可以使用常规OLS检验透明度政策对这些被解释变量的影响了。[14]

图1 机器学习得到的40个主题及每个主题下最可能出现的单词
注:该图来自于Hansen et al. (2018)。 图中每一行代表LDA方法识别出的一个主题(topic0至topic39)。每一行中展示出的12个单词为该主题下最可能出现的单词,自左往右颜色变浅表示该单词出现可能性越小。
类似使用机器学习技术从文本中生成变量研究还有很多。比如Antweiler and Frank (2004) 利用朴素贝叶斯算法(Naive Bayes)将网络上超过150万股民留言分为看涨、看跌及中立三类,然后用每条留言的类别解释股票市场振幅; King et al. (2017) 和Qin et al. (2017) 分别采用自动非参数文本分析(Automated Nonparametric Content Analysis)和支持向量机(Support Vector Machine)技术来识别微博用户或账号的身份。[15]
除了文本,机器学习也可以从图像中提取变量。卫星图像就是一个被经济学家广泛研究的图像信息。[16] 例如,Engstrom et al. (2016) 的研究试图测量一个地区的综合社会福利水平。 在发达国家,研究者可以直接依赖官方数据或者调查数据。但很多落后国家由于没有足够财政维持经济普查机构的运转,其官方经济统计数据并不可得。为此,作者使用卷积神经网络(Convolutional Neural Networks, CNN)来识别卫星图片中建筑物、车辆及道路等固定资产,以此评估这些地区的福利水平。[17] 除卫星遥感照片外,谷歌街景照片(Google Street View)也经常被学者用来研究诸如城市化相关习题 (Glaeser et al., 2018)。 另外一个被广泛研究的图像信息是人像。比如,Edelman et al. (2017) 通过用机器学习技术判别Airbnb上的用户头像性别进而分析租房平台上是否存在性别歧视。 Cao and Chen (2018) 在研究恋爱配对市场中颜值和物质条件发挥作用时,使用机器学习技术对研究对象的面貌进行打分并和人工打分比较。
上述研究主要涉及变量的“绝对”值,机器学习还可以为研究者生成“相对”意义上的变量。比较不同文本相似度是该领域的典型应用。比如,Iaria et al. (2018) 试图研究一战冲击是否会影响跨国学术交流合作。 在这个研究中,解释变量是战争的爆发,被解释变量则是论文的相似程度。作者预期战争会降低论文相似程度,基于如下逻辑:如果两个国家的学者经常交流,那么大家的研究兴趣和方向就会比较相似,这会导致论文成果也具有相似性。战争的爆发使得国家之间进入敌对状态,跨国学术合作被迫中断。这将导致同盟国和协约国各自的论文标题相似度下降。该研究需要解决的关键问题是比较论文间的相似度:样本包含40000篇论文。作者采用基于机器学习的语义分析(Latent Semantic Analysis)来比较两两论文标题间的相似程度,实现了人工不大可能完成的工作(图2)。折线代表敌对阵营间论文标题的相似度。可以非常明显的看到,相似度在一战爆发后显著下降,证实了作者上述猜想。

图2 来自不同阵营的论文相似度
注: 本图来自于Iaria et al. (2018) 的论文。 图中纵轴表示两个敌对国之间的论文相似度,横轴表示论文出版年份,黑色竖线为1914年一战爆发。同上文猜想一样,敌对国之间的论文相似度在一战爆发后极速下降。图中相似度为负是因为作者选取的对照组为本国与本国内部论文的相似度,详细讨论见原文。
其他利用文本相似度进行研究的文献包括Bleakley and Ferrie (2016) 的研究以及Hoberg and Phillips (2016) 的研究等。Bleakley and Ferrie (2016) 试图研究财富增加能否增加对后代的教育投资。 由于普查数据来自多个年份,造成了部分父辈与子辈无法匹配(比如女子婚后改变姓氏)。作者使用机器学习技术并结合其他个人信息预测来自两个样本的不同个体是不是父子或父女关系以解决该问题。Hoberg and Phillips (2016) 则研究了911事件如何影响军火企业。 由于美国传统行业划分是不随时变化的,这就导致了那些由于这一事件进入或退出军火行业的企业无法被识别出来。为解决该问题,作者同样采用机器学习技术:分析公司每年的产品描述文档并根据其相似度划分行业分类。结果发现911事件后进入军火行业的企业数目显著增多。
除了对海量文本进行归类和比较外,机器学习技术还可以测量文字背后的情感。比如,Hills et al. (2016) 试图研究历史上人们的主观幸福指数。 我们可以依靠社会调查数据测量现代社会公众的幸福感。但该方法并不适用于古代。作者采用的策略是利用机器学习计算不同时期出版图书中的幸福感。研究数据来自谷歌图书(Google Books Corpora),该数据库收录了1500年以来将近1000万本书籍。作者首先利用语言学和心理学文献中已有的“幸福感词典”,定义出每一个词所代表的“幸福值”,然后用计算机计算出每一本书的幸福感指数。为了验证该方法可靠性,然后,作者比较了1970年后分别利用该方法(红线)和Eurobarometer社会调查(蓝线)所建立起来的意大利公众幸福指数(图3)。这两个指数之间类似的发展趋势说明了上述方法的可行性。

图3 作者构建的意大利主观幸福指数与Eurobarometer的意大利民调
注:本图来自于Hills et al. (2016) 的研究。 图中红色线为作者通过机器学习读取图书生成的意大利主观幸福指数,数值大小以左侧纵轴来表示;蓝色线为Eurobarometer在意大利进行的生活幸福感调查获得的幸福指数,可以看到两者吻合度很高。
另外一个被学者,特别是政治学者广泛关注的是文本中体现的政治立场。[18] 利用机器学习技术对文本进行立场分析的相关研究包括:从各个党派党章或宣言中推测党派政策立场、通过新闻报纸措辞来判断报纸党派倾向、通过国会发言来测定党派分歧等 (Laver et al., 2003; Gentzkow and Shapiro, 2010; Gentzkow et al., 2016)。[19]
(二)预测
在使用机器学习之前,社会科学研究者主要依赖最小二乘回归(OLS)进行预测。在本小节,我们首先用公式推导的方法比较该领域被广泛使用的Ridge(岭回归)技术和OLS在预测上的差异,并简单评价这两种方法的优劣;其次介绍利用机器学习进行预测的最新文献。
1. OLS与Ridge在预测上的差异
预测的目的在于找出两个变量间的相关关系。假设这两个变量间的真实关系是![]() 。此处函数关系f客观存在但不为我们所知。无论依赖于机器学习还是计量经济学,研究者的目的都是找到一个与f尽可能接近的函数g,使得该函数估计值
。此处函数关系f客观存在但不为我们所知。无论依赖于机器学习还是计量经济学,研究者的目的都是找到一个与f尽可能接近的函数g,使得该函数估计值![]() 能够非常好地吻合真实值y。评价一种预测方法好坏最常用的标准是均方误差(Mean Squared Error, MSE),也就是残差平方的期望,可表述为 (Hastieet al., 2016):
能够非常好地吻合真实值y。评价一种预测方法好坏最常用的标准是均方误差(Mean Squared Error, MSE),也就是残差平方的期望,可表述为 (Hastieet al., 2016):
 (1)
(1)
当解释变量取值为![]() 时,预测值
时,预测值![]() 与被解释变量真实值
与被解释变量真实值![]() 间的差异可被写为:
间的差异可被写为:
 (2)
(2)
通过上式,均方误差被分解为三部分:估计值与真实值间的偏差(Bias)、估计值方差(Variance)及真实值的扰动方差(Noise)。其中,扰动方差完全来自于随机扰动项ε,该部分不会消除且也不会由于预测方法的不同而存在差异。因此,不同预测方法减小均方误差的途径就是在偏差和方差间进行取舍。[20]
下面我们从偏差、方差以及最终均方误差三方面,比较OLS和Ridge在预测方面的差异。为了推导的简洁,假设Y与X的真实函数关系f(x)为线性且解释变量X为正交矩阵:[21]
 (3)
(3)
OLS的预测函数g(x)可表示为![]() ,对式中
,对式中![]() 的估计方法是最小化残差的平方和,表示为:
的估计方法是最小化残差的平方和,表示为:
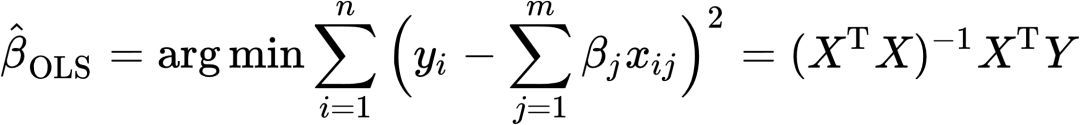 (4)
(4)
此时,![]() 的偏差是:
的偏差是: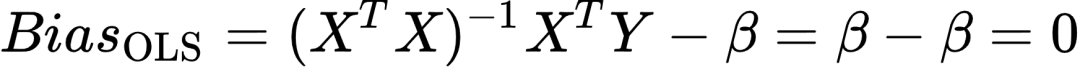 (5)
(5)
方差是:
 (6)
(6)
可知![]() 是真实值β的无偏估计量。[22]
是真实值β的无偏估计量。[22]
由以上可以看出利用OLS进行预测的优点在于估计系数偏差为0,缺点是方差可能较大。换句话说,选择若干个随机样本进行多次回归,无偏性保证所获系数的均值接近于系数的真实值。方差较大则意味着单次回归系数偏离均值较远,可能会异常大或小。当解释变量间存在多重共线性时,这一问题尤为严重。
针对此问题,Ridge在最小化目标函数中引入估计系数平方作为惩罚项,表示为:[23]
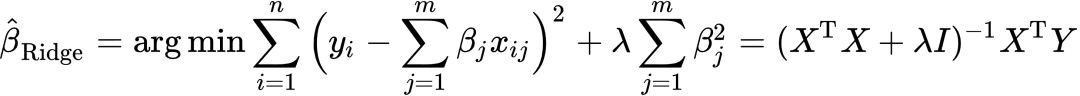 (7)
(7)
上式在直觉上非常容易理解:OLS的缺点在于方差大,也就是估计系数的上下波动很剧烈。为了防止这种情况,机器学习在最小化过程中通过加入估计系数的平方或绝对值来“抑制”系数大小。如此便可以减小估计系数的方差使得预测更加稳定。这种思路可以理解为对系数大小的一种惩罚:过大则赋予较小权重,过小则相反。LASSO和Ridge的不同就体现在惩罚系数的选取上:Ridge惩罚项为系数的平方![]() ,而LASSO则是系数的绝对值
,而LASSO则是系数的绝对值![]() 。[24] 引入惩罚项后,Ridge最小化的目标函数较之OLS更为复杂,而LASSO甚至无法导出估计系数的解析表示,只能求得数值解。操作上,最小化问题往往借助机器学习技术实现。以下将分别比较OLS和Ridge估计系数的偏差、方差和均方误差的大小。首先,根据X是正交阵假设,由式上式可得系数
。[24] 引入惩罚项后,Ridge最小化的目标函数较之OLS更为复杂,而LASSO甚至无法导出估计系数的解析表示,只能求得数值解。操作上,最小化问题往往借助机器学习技术实现。以下将分别比较OLS和Ridge估计系数的偏差、方差和均方误差的大小。首先,根据X是正交阵假设,由式上式可得系数![]() 为:
为:
 (8)
(8)
此时估计系数的偏差是:
 (9)
(9)
偏差是:
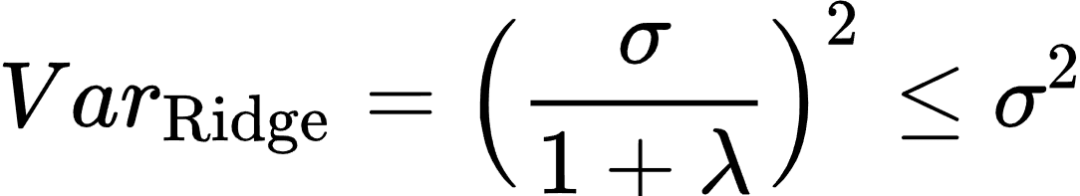 (10)
(10)
上两式表明Ridge系数估计是一个有偏估计量,但其方差比OLS要更小。换一句话说,在方差和误差的权衡中,Ridge以有偏为代价换取更小的方差。在获得了OLS和Ridge估计系数的偏差和方差后,我们就能够分别计算两者的均方误差:
![]() (11)
(11)
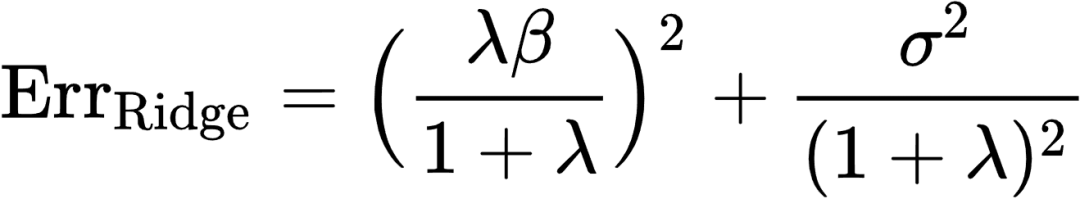 (12)
(12)
为了比较两种方法的预测能力,我们将上两式做差:
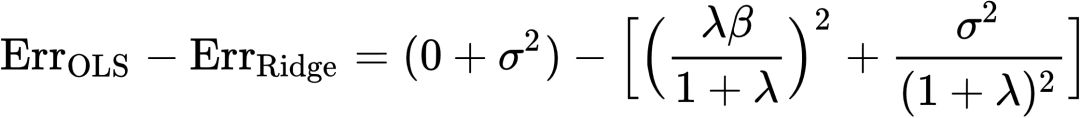 (13)
(13)
若上式取值为正,那么OLS预测误差更大,反之Ridge的误差更大。可以看到,上式实际是一个关于λ的函数,其正负性也依赖于λ的值。现在问题转变为:怎么样的λ会使得上式取正值或者负值?我们先考察该函数极值,如果该函数极大值都小于零,OLS的均方误差将恒小于Ridge;反之,如果该函数的极大值大于零,意味着我们一定能找到λ使得Ridge的均方误差更小。为找到极值,令上式的导数为零,得到一阶条件 。将该一阶条件代入,此时
。将该一阶条件代入,此时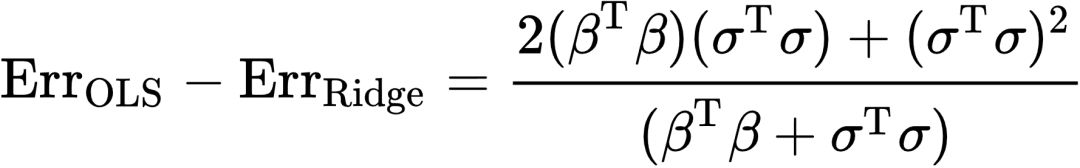 。式中分子分母都为正数,因此上式大于零,这意味着Ridge预测能力优于OLS。事实上,Theobald (1974) 证明了将该条件放宽到
。式中分子分母都为正数,因此上式大于零,这意味着Ridge预测能力优于OLS。事实上,Theobald (1974) 证明了将该条件放宽到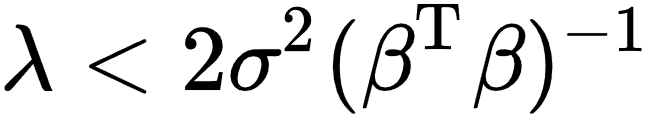 时,Ridge的均方误差都是小于或等于OLS的。
时,Ridge的均方误差都是小于或等于OLS的。
我们从“无偏性”和“可解释性”两方面评价传统计量经济学方法和机器学习方法在预测方面的优劣。正如本章开头所说,任何预测方法都是在偏差和方差间进行权衡取舍。社会科学实证研究,特别是经济学研究,特别强调因果推论。基于这种考虑,计量经济学回归模型都致力于获得一致的估计系数。这意味着在这一方差–偏差权衡中,计量经济学方法宁愿付出方差较大的代价,也不能放弃无偏这一性质 (Athey, forthcoming)。比方说上面所提到的OLS的估计系数正体现这一思路。而机器学习的目的就是进行预测——它并不在乎用以做出预测的估计系数是否具有无偏性特点。这就意味着在无偏性上,机器学习做出了“让步”:选择用偏差来换取更小的方差以提高预测性能。“可解释性”指的是从模型估计出的结果能够容易地被解释。计量经济学的目的不仅是预测,更在于解释现实中的现象以找到背后规律。从这个意义上来说,用来预测的函数形式越简单越好。因为复杂模型需要廓清模型拟合好坏的原因及解释变量与被解释变量间的互动关系等诸多问题。[25] 机器学习则恰恰相反,只要这个函数能够很好地模拟现实,哪怕函数形式再复杂也无所谓。[26] 在这一点上,机器学习不拘泥于“可解释性”,灵活地选择函数形式进行拟合数据,这使得其预测能力强过了计量经济学传统方法。[27]
参考文献:
13 LDA可以通过不同单词在一段文本中出现的位置、频率和上下文,推测出这段文本中含有几个主题。该技术的具体细节见Blei et al. (2003)
14 该文发现透明度提升后,成员更倾向于探讨经济问题并且在发言中更多地使用量化指标。造成这一变化的原因可能是官员在透明环境下更有动力探讨民众关注的经济问题并且花费更多时间去寻找量化证据来支持自己的发言。
15 此处提到的自动非参数文本分析技术是Hopkins and King (2010) 为社会科学研究中的文本分类开发的,读者可以进一步阅读原文了解其算法逻辑与实现方法。另一些研究则尝试结合人力与自然语言处理技术以进行“半自动化”的文本分析。这些研究包括Benoit et al. (2016) 以及Carlson and Montgomery (2017)。
16 这方面的工作和Henderson et al.(2012) 的研究不同,该研究是将夜间灯光的明暗转变为数据。而我们介绍的则是从高分辨率的卫星图片中识别出房屋、汽车等和地区财富相关指标。
17 类似通过卫星照片来估计地区财富水平的研究还有Jean et al. (2016)。
18 当然,文字能反映的感情显然不局限于幸福感和政治倾向,研究者可以根据研究所需生成想要的情感倾向变量。比如Wu (2017) 就利用机器学习来甄别出哪些词汇被经常用来刻画男性形象,哪些词汇更可能描述女性。
19 除了情感和政治立场分析之外,也有一些研究利用机器学习分析主流媒体的报道来预测军事冲突。Muelle and Rauh (2018) 首先利用和正文中提到的LDA方法提取《纽约时报》、《华盛顿邮报》和《经济学人》上的新闻主题并计算每年占比,然后将占比作为解释变量以预测军事冲突的可能发生地点。
20 偏差和方差的权衡取舍(Bias–Variance Tradeoff)是机器学习预测中的一个重大问题,详细讨论见Bishop (2006);Murphy (2012);Hastie et al. (2016)。
21 对于一般的非正交矩阵情况,Ridge的预测能力也是优于OLS的,严格数学证明见Theobald (1974).若读者对岭回归感兴趣,该技术的更多内容可以参考van Wieringen (2015)。
22 当X不是正交矩阵时,OLS得到的系数估计也是无偏的,这容易从式(4)中看出。
23 可以看到,λ反映了“惩罚力度”,当λ=0时意味着无惩罚,此时Ridge和OLS完全一样。
24 严格来说,LASSO和Ridge的“惩罚项”具有不同的含义:LASSO进行的是L1范数正则化,Ridge则是L2范数正则化。关于正则化详细讨论见Bishop (2006);Murphy (2012);Hastie et al. (2016)。
25 对于y=x,解释变量增加一个单位,被解释变量也增加一个单位,两者成正比。但对于y=sinx+logx^2,即便该函数对现实规律可能拟合地更好,研究者也很难对该函数进行“经济学解释”。因此在计量经济学中,学者很少使用类似复杂形式的函数模型。
26 很多机器学习技术都欠缺可解释性。比如,神经网络技术甚至能被视为黑箱:研究者无法得知解释变量通过何种机制影响被解释变量。一些致力于机器学习的学者也注意到了这个问题,正着手提高复杂模型的可解释性。相关讨论见Bau et al. (2017)。
27 用机器学习预测除Ridge之外,还可以采用非线性、半参或非参预测方法。Mullainathan and Spiess (2017) 对比了这些方法与OLS的差异,结果发现机器学习的预测能力普遍强于OLS。
![[RUST/腐蚀]Windows-开服服务端下载以及配置](https://static.hdslb.com/images/favicon.ico)









![【PWN · ret2libc】[2021 鹤城杯]babyof](https://img-blog.csdnimg.cn/6c95d5c7027a44daade842236b7345c9.png)