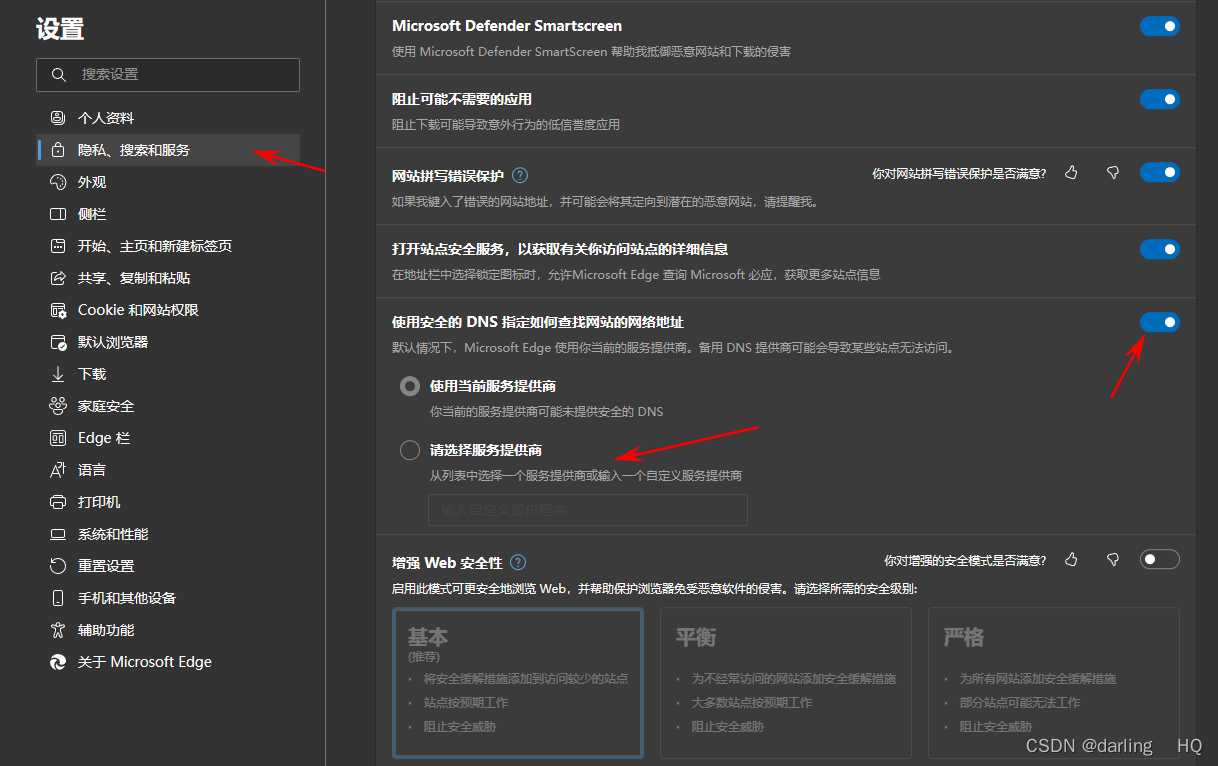
淘宝店铺搜索界面
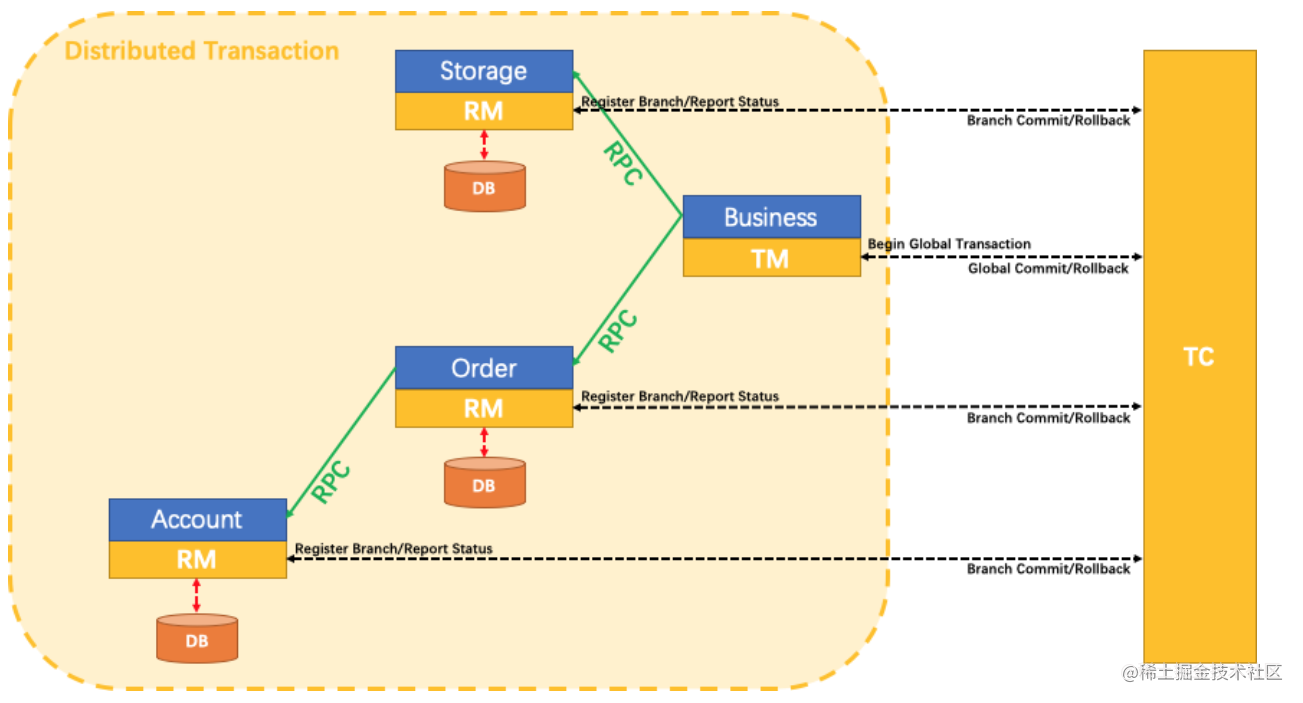
- 1.元素
- 2.过程
- 2.1 搜索界面的网页源码
- 2.2 通过Chrome控制台获取sellerid
- 2.3 搜索链接
- 2.4 控制台
- 3.总结
1.元素
- 获取店铺搜索界面每个店铺的’sellerid’
备注:通过sellerid可以在下面链接中获取买家秀的图片,也可以使用相关软件进行下载。[将最后的xxx替换为sellerid即可]
Link:https://h5.m.taobao.com/ocean/privatenode/shop.html?&sellerId=xxx
2.过程
2.1 搜索界面的网页源码
店铺搜索界面如下:
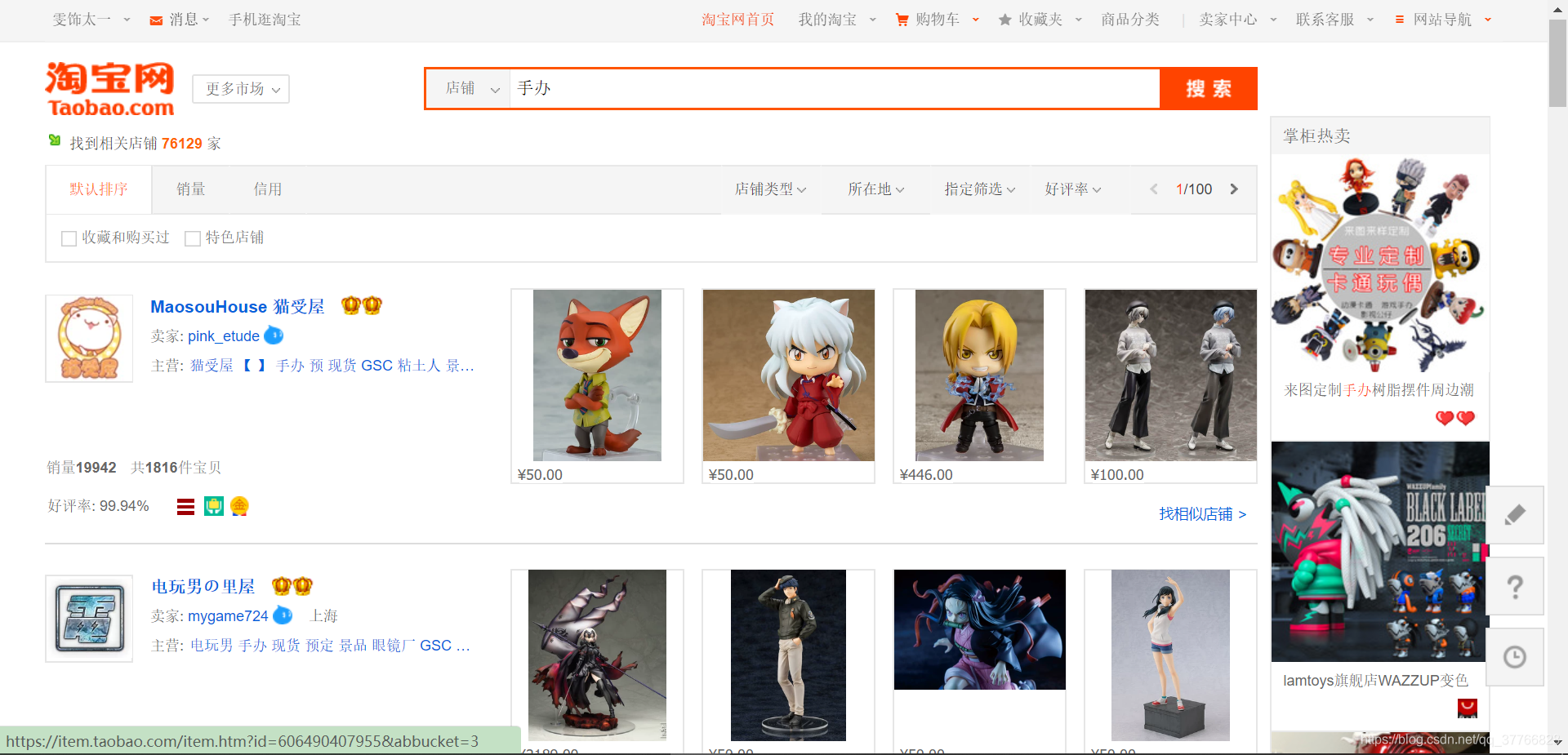
备注:每一个界面会有20个结果,结果是根据热度排序的
源码如下:

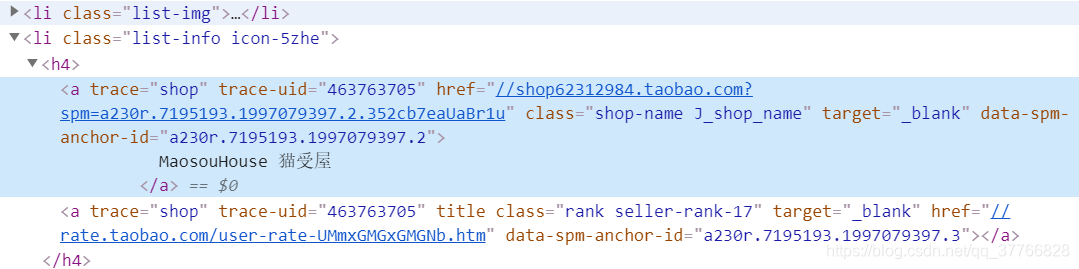
trace-uid:与sellerid是一致的
猫受屋:店铺的名字
备注:每一页对应可以搜索得到20个类似的id。
2.2 通过Chrome控制台获取sellerid
//备注:需要保证20个店铺都加载过,否则获取的不完整
tag_list=document.getElementsByClassName("list-img");
str_pr="";
for (var i =0; i < tag_list.length; i++) {a_list=tag_list[i].getElementsByTagName("a");trace_uid=a_list[0].getAttribute("trace-uid");trace_title=a_list[0].title;str_temp=trace_uid+':'+trace_title;str_pr=str_pr+str_temp+'\n';
}
console.log(str_pr);
对应的一段源码如下:
2.3 搜索链接
如下链接:不能得到任何与第几页相关的内容
url='https://shopsearch.taobao.com/search?q=%E6%89%8B%E5%8A%9E&js=1&initiative_id=staobaoz_20200511&ie=utf8';
'q=%E6%89%8B%E5%8A%9E':搜索的内容,url二次编码
'ie=utf8':编码格式
下翻一页与上一页对比:
url1='https://shopsearch.taobao.com/search?q=%E6%89%8B%E5%8A%9E&js=1&initiative_id=staobaoz_20200511&ie=utf8';
url2='https://shopsearch.taobao.com/search?q=%E6%89%8B%E5%8A%9E&js=1&initiative_id=staobaoz_20200511&ie=utf8&s=20';
可以看到末尾的多了 ‘s=20’ ,可以通过这个链接,每次获取网页源码,从中进行提取。
备注:
上面的方法不可行,因为需要进行登录,哈哈~
因此,需要在控制台输入JS代码,将每次的结果进行复制
2.4 控制台
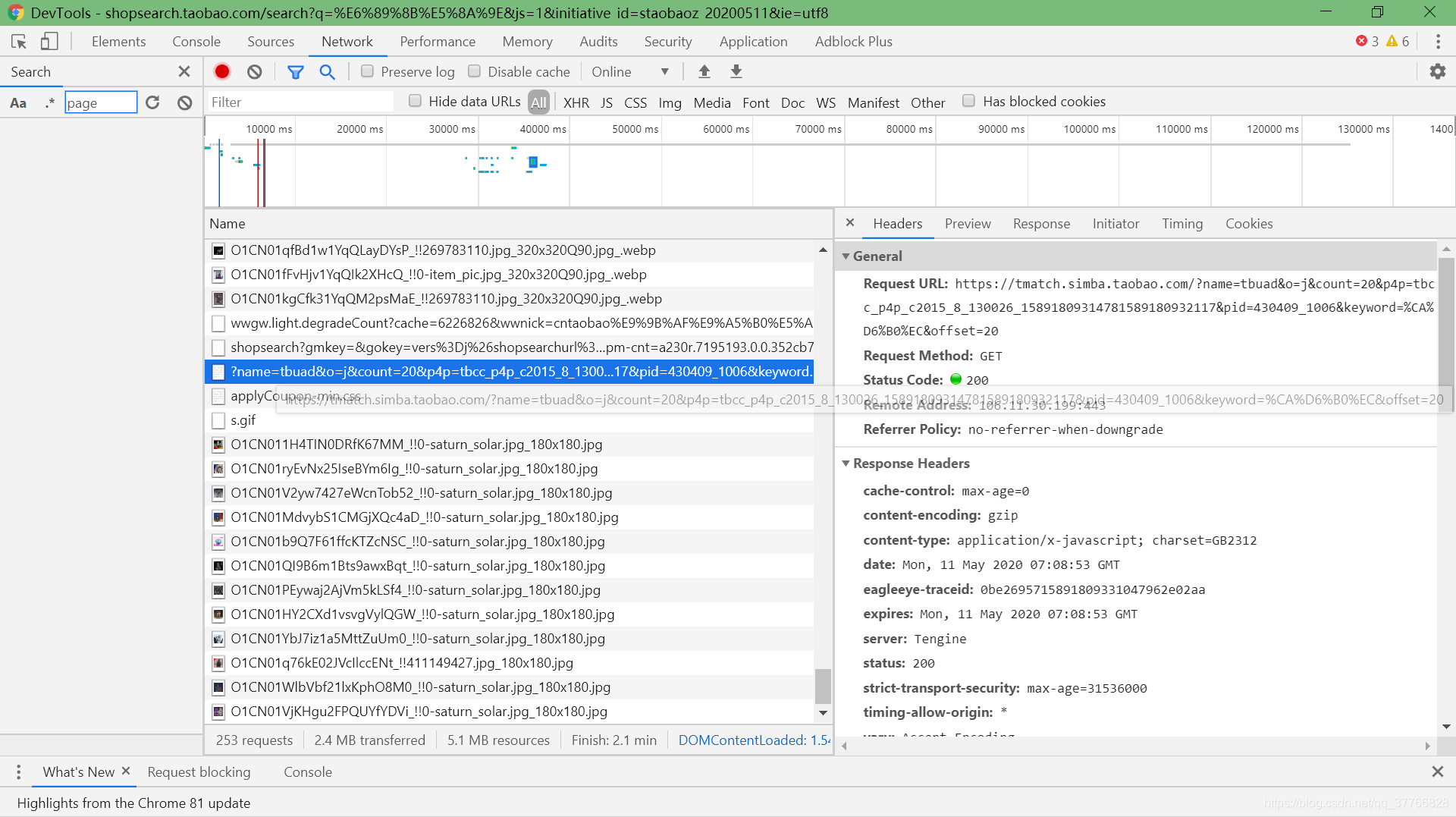
有这么一项:
url='https://tmatch.simba.taobao.com/?name=tbuad&o=j&count=20&p4p=tbcc_p4p_c2015_8_130026_15891809314781589180932117&pid=430409_1006&keyword=%CA%D6%B0%EC&offset=20';
name='tbuad';
count=20;
p4p='tbcc_p4p_c2015_8_130026_15891809314781589180932117';
pid='430409_1006';
keyword='%CA%D6%B0%EC';
offset=20;
经过了一番测试,得到如下结果:
- count:返回搜索结果的数目,最大200
- offset:偏移,从将offset后count个店铺信息返回
- keyword:类似于url二次编码,但似乎还进行了其他处理,不能直接解码
- p4p可以去掉
- pid可以任意修改,但一定要有
类似于一个接口
其中的内容如下:
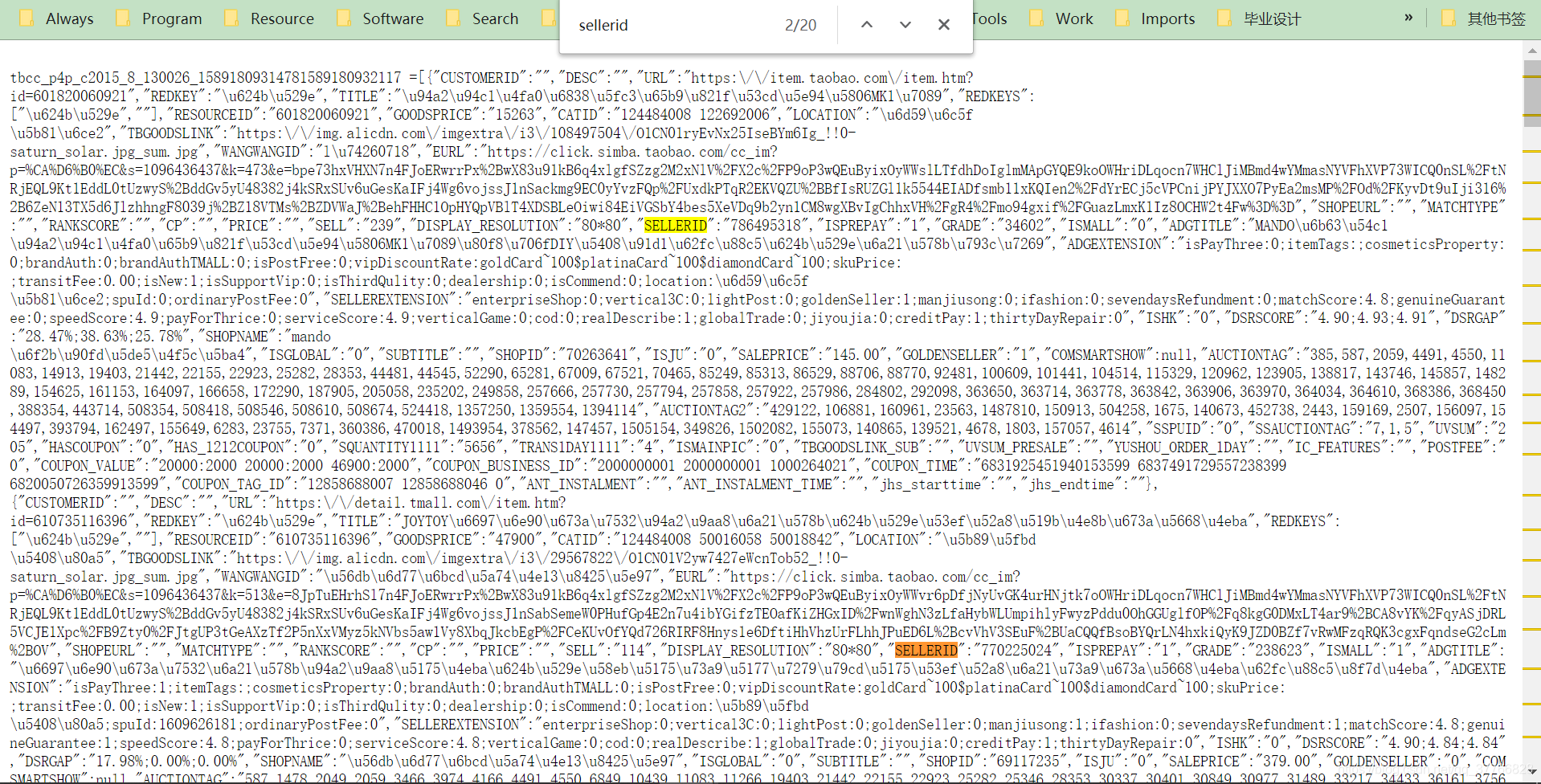
备注:果不其然,只有20条数据。
单拎出来一条:
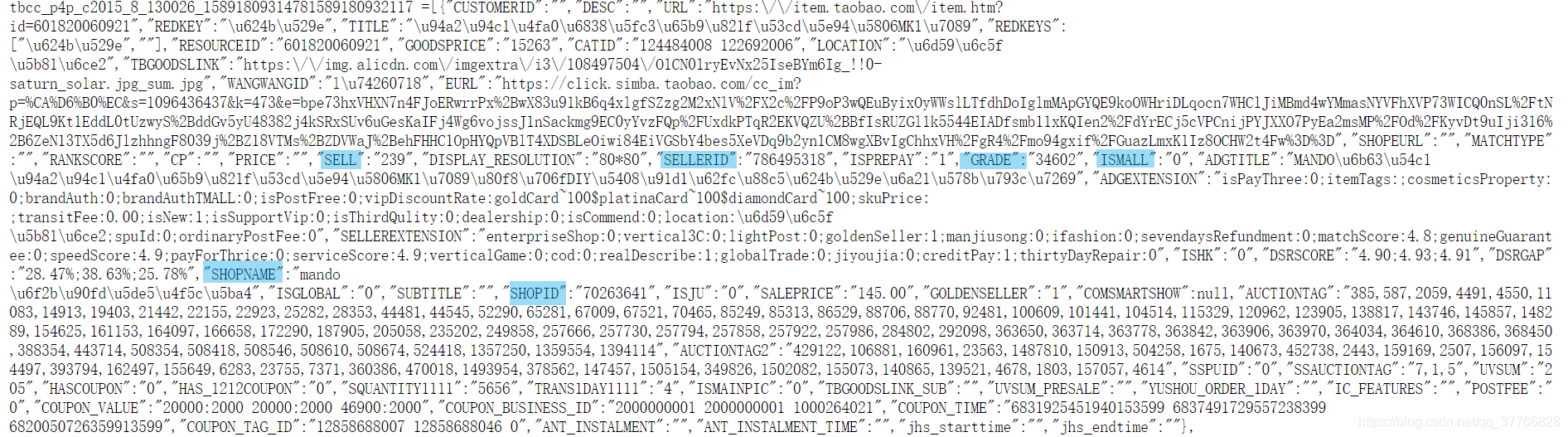
SELL:卖出的数目
SELLERID:店铺的sellerid
GRADE:类似于热度,数字越大、热度越高
ISMALL:不知道
SHOPNAME:店铺的名字
SHOPID:店铺的id
备注:可以使用python批量获取N条数据,将其排列得到热度较高的店铺。python代码就不贴出来了 。
3.总结
这才不过是第一篇,以后指定会遇到各种奇奇怪怪的网站~
其中类似于url二次编码的问题,是值得思考与探讨的~
//这两个是如何表示同一种内容的?
//使用Javascript encodeURI() 函数,用于完整的URL编码。',
str1='%E6%89%8B%E5%8A%9E';//encodeURI
//使用Javascript encodeURIComponent() 函数,用于拼接URL的参数。
str2='%CA%D6%B0%EC';//encodeURIComponent
关于图片下载的部分内容:
链接:https://wenshitaiyi.lanzous.com/ichlukf
密码:8pzd
备注:生成的文件夹与该.exe文件在同一个路径下!🤔