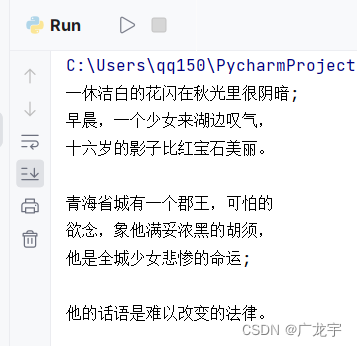
Python提取图片中的文字信息
使用的Python库
Python tesseract是Python的一个光学字符识别(OCR)工具。也就是说,它将识别并“读取”嵌入图像中的文本。
Python tesseract是Google tesseract OCR引擎的包装器。它还可用作tesseract的独立调用脚本,因为它可以读取Pillow和Leptonica图像库支持的所有图像类型,包括jpeg、png、gif、bmp、tiff等。此外,如果用作脚本,Python tesseract将打印识别的文本,而不是将其写入文件。
程序如下
import pytesseract
from PIL import Imageprint(pytesseract.image_to_string(Image.open('./1A2737EC36534A6636E062FF17838D99.jpg'), lang='chi_sim'))
安装识别引擎tesseract-ocr
如果有以下报错:
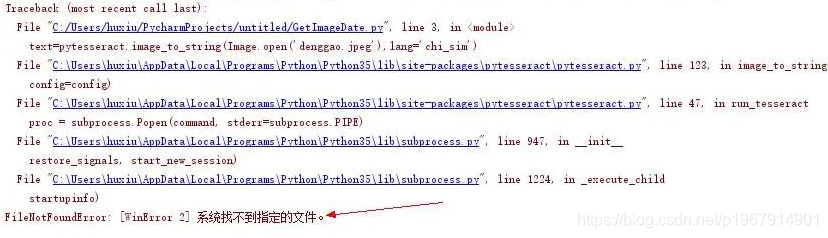
则还需要安装识别引擎tesseract-ocr
网上下载安装包,然后直接点击安装即可
因为tesseract-ocr默认不支持中文识别,所以解压安装tesseract-ocr后还需下载对应的语言包
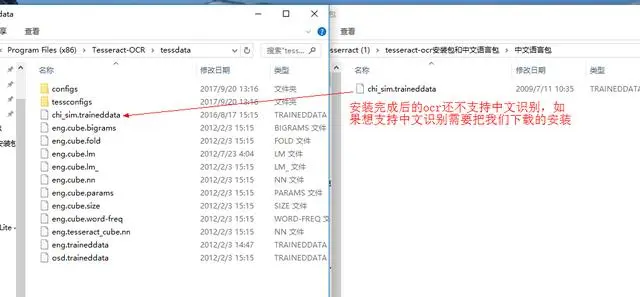
安装完成tesseract-ocr后,我们还需配置一下
在C:\Users\ASUS\AppData\Local\Programs\Python\Python38\Lib\site-packages\pytesseract中找到pytesseract.py
打开后做如下操作:
# tesseract_cmd = 'tesseract'
tesseract_cmd = 'D:/Tesseract-OCR/tesseract.exe'
环境变量设置
根据这个教程设置环境变量
接下来便可以使用程序来进行文字识别提取