Scrapy框架爬虫——以京东众筹为例
- 第一步, 打开命令提示符,创建一个Scrapy框架;
- 第二步,定位到创建的文件夹;
- 第三步,在spider文件夹中创建一个.py文件(注:不要关闭命令提示符);
- 第四步,打开items.py这个文件,将提取信息的名称、属性写入其中;
- 第五步,打开第三步创建的.py文件;
- 第六步,根据网页源代码查找提取信息,编写代码(这里需要修改start_urls为访问网页的网址。删除allowed_domains,导入items.py中的Jd1Item类);
- 第七步,打开pipelines.py,将所提取的内容写入json文件;
- 第八步, 打开settings.py,修改访问的USER_AGENT,注释掉ROBOTSTXT_OBEY,解除ITEM_PIPELINES注释;
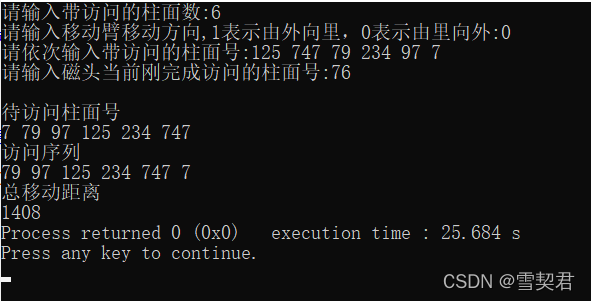
- 最后,打开命令提示符,运行创建的.py文件(这里是jdzch1.py);
第一步, 打开命令提示符,创建一个Scrapy框架;

第二步,定位到创建的文件夹;

第三步,在spider文件夹中创建一个.py文件(注:不要关闭命令提示符);

第四步,打开items.py这个文件,将提取信息的名称、属性写入其中;
import scrapyclass Jd1Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 定义所找的变量的名字、属性title = scrapy.Field()perc = scrapy.Field()outc1 = scrapy.Field()money = scrapy.Field()outc2 = scrapy.Field()time = scrapy.Field()outc3 = scrapy.Field()
第五步,打开第三步创建的.py文件;

第六步,根据网页源代码查找提取信息,编写代码(这里需要修改start_urls为访问网页的网址。删除allowed_domains,导入items.py中的Jd1Item类);
提取信息的其他方式见(https://blog.csdn.net/weixin_43196531/article/details/85159471)
import scrapy
# 导入items类, 使items类生效
from jd1.items import Jd1Itemclass Jdzch1Spider(scrapy.Spider):name = 'jdzch1'start_urls = ['http://z.jd.com/bigger/search.html']def parse(self, response):result = response.xpath('//li[@class="info type_now"]')# 循环每个商品,提取所需信息for i in result:# 定义 item 字典item = Jd1Item()# 筛选信息item['title'] = i.xpath('.//h4[@class="link-tit"]/text()').extract_first()item['perc'] = i.xpath('.//li[@class="fore1"]/p[@class="p-percent"]/text()').extract_first()item['outc1'] = i.xpath('.//li[@class="fore1"]/p[@class="p-extra"]/text()').extract_first()item['money'] = i.xpath('.//li[@class="fore2"]/p[@class="p-percent"]/text()').extract_first()item['outc2'] = i.xpath('.//li[@class="fore2"]/p[@class="p-extra"]/text()').extract_first()item['time'] = i.xpath('.//li[@class="fore3"]/p[@class="p-percent"]/text()').extract_first()item['outc3'] = i.xpath('.//li[@class="fore3"]/p[@class="p-extra"]/text()').extract_first()yield item
第七步,打开pipelines.py,将所提取的内容写入json文件;
import jsonclass Jd1Pipeline(object):# 定义初始化函数def __init__(self):# 定义函数名self.filename = open('jdzch.json', 'w',encoding = 'utf-8')# 处理函数def process_item(self, item, spider):# 将json数据转化为字符串text = json.dumps(dict(item), ensure_ascii = False) + '\n'# 对文件进行写入self.filename.write(text)# 定义文件关闭函数def close_spider(self,spider):self.filename.close()
第八步, 打开settings.py,修改访问的USER_AGENT,注释掉ROBOTSTXT_OBEY,解除ITEM_PIPELINES注释;
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2714.400'

最后,打开命令提示符,运行创建的.py文件(这里是jdzch1.py);
 文件内容如下:
文件内容如下: