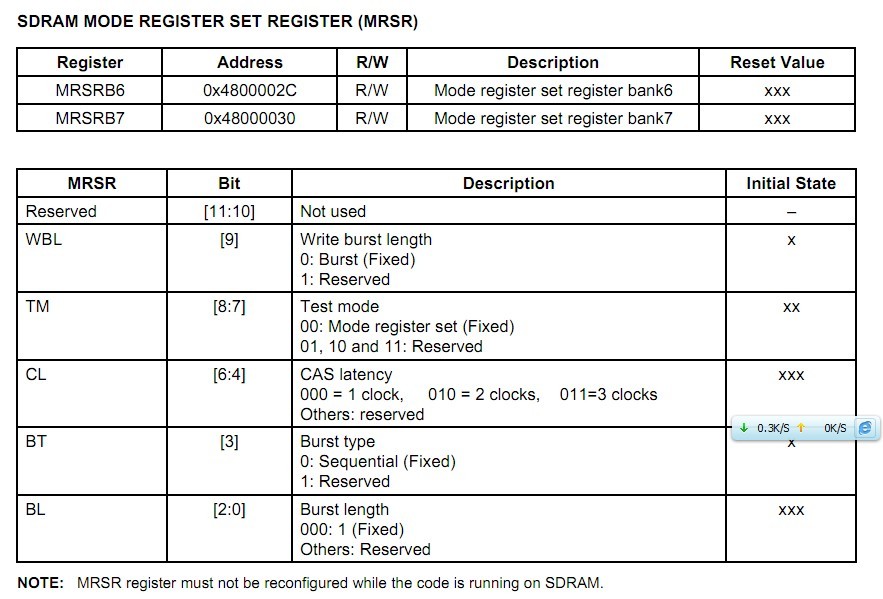
"""
Created by Young on 2019/1/16 17:00
"""from bs4 import BeautifulSoup
import requests
import json as js
import reheaders = {'user-agent':''}#之前爬取错了,这个只能爬取一页
def parsing_webpage(url):wb_data = requests.get(url,headers=headers)wb_data.encoding = "utf-8" #解决乱码soup = BeautifulSoup(wb_data.text,'lxml',from_encoding="utf8")rooms = soup.find('ul',class_='live-list clearfix')single_rooms = rooms.find_all('li',class_='game-live-item')for single_room in single_rooms:room_title = single_room.find_all('a',class_='title new-clickstat')[0].get_text()nick_title = single_room.find_all('i',class_='nick')[0].get_text()room_popularity = single_room.find_all('i',class_='js-num')[0].get_text()print({"room_title":room_title,"nick_title":nick_title,"room_popularity":room_popularity})#正则爬取
def parsing_json(true_url):wb_data = requests.get(true_url, headers=headers)wb_data.encoding = "utf-8" # 解决乱码temps = js.loads(wb_data.text)datas = str(temps)introduction = re.findall(" 'introduction': '(.*?)', 'recommendStatus': ", datas, re.S)totalCount = re.findall(" 'totalCount': '(.*?)', 'roomName': ", datas, re.S)nick = re.findall(" 'nick': '(.*?)', 'avatar180': ", datas, re.S)for introduction, totalCount, nick, in zip(introduction, totalCount, nick,):data = {'介绍': introduction,'人气': totalCount,'主播名': nick,}print(data)def main():for i in range(1,30):urls = {'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1&tagAll=0&page={}'.format(i),#lol'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=279&tagAll=0&page={}'.format(i),#绝地求生}for url in urls:parsing_json(url)if __name__ == '__main__':main()效果图:

有疑问下方评论,我看到就回回复