文章目录
- GAN(生成对抗网络)
- 1. 生成对抗网络简述
- 2.具体内容
- 2.1 网络如何训练
- 2.2 网络训练时会遇到的问题
- 3.GAN的发展
- 4.GAN的代码实践
- 4.1 基于GAN的mnist数据生成
- 4.2 放大招—生成美女图片
- 4.2.1 爬取美女图片
- 4.2.2 提取人脸
- 4.2.3 开始训练
GAN(生成对抗网络)
没有女朋友也没关系,现在我们就试试自己GAN出一个。
1. 生成对抗网络简述
首先要提的肯定是2014年Ian J. Goodfellow大佬的关于GAN的论文,应该也算是GAN的开山之作。Generative Adversarial Network 论文链接
生成对抗网络顾名思义包含了生成和对抗的思想,按照原始的GAN网络结构中主要包含了两部分,分别是生成模型 G和判别模型 D,通常这两部分都是神经网络,其中G负责通过我们输入的数据生成一些新的数据(生成的数据要尽可能接近我们的数据集中的数据);而D则负责作判别,判断输入的数据是来自真实数据集的 “真数据” 还是由G生成的 ”假数据“ ,所以D是一个用来分辨真伪的二分类模型,网络最后一层往往也使用sigmoid激活函数。
举个简单的例子:
G就像现实中制作假币的机器,而D就是验钞机。一开始G和D的技术都不太好,往往G产生的假币假到人肉眼就看出来是假的,而D判断的技术也很差,往往人肉眼都觉得的是假币而它判断确实真币;经过一段时间的改进优化,D可以比人眼更好的分辨真假币,而G制作出来的假币也能骗过人的眼睛;到了最后,G生成的假币已经可以完美的媲美真币,而D这个时候已经无法区分到底是真币还是G生成的假币(准确率50%),这个时候就是最完美的时候,我们的目的也就达到了。
GAN整体示意图如下:
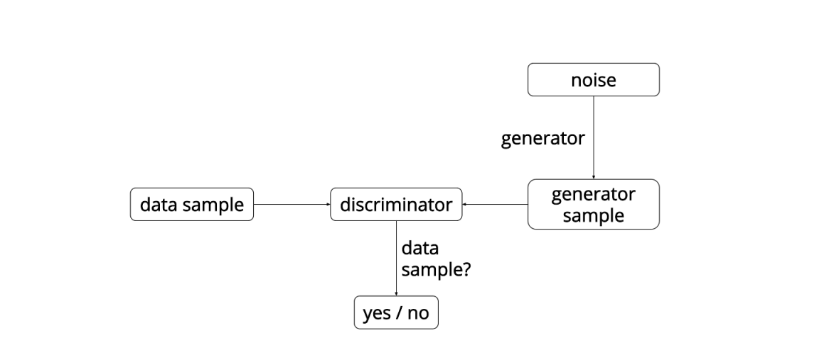
从图来看,G网络所需要的输入只有一个随机噪音,通过随机噪音来生成数据,而D网络的输入就是我们真实的样本数据以及G所生成的数据,并对它们作真假判断。
结合上面的简述,我们可以体会到生成以及对抗的含义,这个想法非常好两者在对抗竞争中互相提高,但是实际上往往会出现一些意外情况,导致模型无法达到预期效果。
-
当我们的验钞机非常厉害,而假币制造技术还很差的时候。不管怎么努力做出的假币还是会被分辨出来,这个时候就没有人会去想着制造假币(无利可图),还不如老老实实工作。
-
当验钞机判别能力相当弱的时候,不管假币制造的多么假,它还是会觉得是真币,尽管这个时候人眼就能看出这是假币;那这个时候假币制造机已经觉得满足了,也不会去进一步增强自己的造假能力。现实中的情况往往是只会生成假的1元,而5元、10元、20元等都不会生成。
上面两种情况其实就是我们训练GAN时通常会遇到的两种情况,都会导致我们的生成器无法达到我们预期想要的结果。此外,对于这样的一种网络概念,怎么对它进行优化训练也是我们需要考虑的,这些就留到下面继续说。
2.具体内容
由上面的简述,我们有了一种新的网络设计思想,通过两种网络的竞争从而得到性能优异的生成模型,并且同时我们还得到了一个能力不错的判定模型。但是当我们把想法实践的时候也遇到了不少问题,上面的D性能太好和太坏都会导致G的训练失败,而且如何训练这两个模型也是我们需要思考的问题,在这里我就展开详细的说说。
2.1 网络如何训练
有了上面零和博弈的思想,我们就会开始设计网络,通常我们的生成器和判定器都是深层神经网络,简单的全连接到复杂点的卷积……;设计好网络后,我们就需要对网络进行训练,也就是更新网络参数,这个时候就需要设置网络的目标函数。

从论文上看,所给出的目标函数
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min\limits_{G}\max\limits_{D}V(D,G)=E_{x \sim p_{data}(x)}[\log{D(x)}]+E_{z \sim p_{z}(z)}[\log{(1-D(G(z)))}] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
实际训练过程中,我们的损失函数分别为:
-
对于G
最小化 log ( 1 − D ( G ( z ) ) ) \log{(1-D(G(z)))} log(1−D(G(z)))但是在早期可能无法提供足够的梯度来训练G,所以有了替代为最大化 log D ( G ( z ) ) \log{D(G(z))} logD(G(z))。
-
对于D
− ( log D ( x ) + log ( 1 − D ( G ( x ) ) ) ) -(\log{D(x)}+\log{(1-D(G(x)))}) −(logD(x)+log(1−D(G(x))))
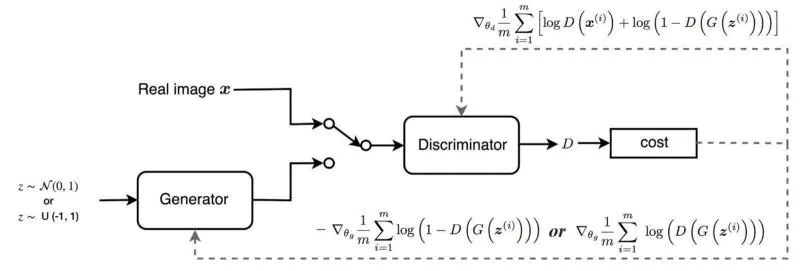
有了上面的损失函数,我们就可以对网络权重进行更新,从而训练网络。不过GAN训练起来可并不容易,往往理想很丰满,现实很骨感。
2.2 网络训练时会遇到的问题
再解释我上面提到的两种情况
-
Vanishing Gradient 梯度消失
梯度消失是指D判别器训练的判别效果远比G的生成效果好,导致无论G生成什么数据,它都觉得与真实数据分布不一致,这个时候就会导致G的训练一直停滞。

从论文上看,我们最终可以得到一个最优解 D ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) D^*(x)=\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)} D∗(x)=pdata(x)+pg(x)pdata(x),带入目标函数,得到简化后的函数 min G ( 2 ∗ J S ( P d a t a ∣ ∣ P G ) − l o g 4 ) \min\limits_{G}(2*JS(P_{data}||P_G)-log4) Gmin(2∗JS(Pdata∣∣PG)−log4)
当我们生成的数据与实际数据集数据分布相差过大,几乎没有重叠部分的时候,散度就成了一个常数,这个时候函数的梯度就是0,也就出现了梯度消失的现象。
-
Mode Collapse 模式坍塌
模式坍塌则是我们GAN训练过程中会出现的另一种问题,当D的判别性能跟不上G的生成效果时,G生成的图片都会被判定为真实的,这个时候 D ( G ( x ) ) = 1 D(G(x))=1 D(G(x))=1,G也就失去了训练的方向。往往这种情况下就会导致只能很好的生成某一类数据,或者生成的数据重复率过高。具体如下图

生成的图像中出现了多个相似图片,失去了生成模型的多样性。
3.GAN的发展
基于零和博弈策略的GAN作为生成模型,相比之前的生成模型不再需要知道数据的分布,而是先生成数据然后往我们所给出的数据分布上去靠拢。GAN往往用于图像、视频的生成,也有用于文字的生成。从它的原理我们可以看出,它对于不同的输入noise,就会生成不同的数据;另外,它生成的数据往往是整体的,而不能依赖于某一个数据去控制另一个数据。
对于图像的生成,将全连接神经网络改为了卷积神经网络,并且优化激活函数等,比如DCGAN;对于风格迁移的CycleGAN;为了使GAN训练更稳定提出的WGAN和WGAN-GP以及Conditional GAN;最后是复杂的StyleGAN,也是我目前需要研究学习的,下一篇应该就是关于StyleGAN和StyleGAN2的博客
4.GAN的代码实践
4.1 基于GAN的mnist数据生成
来源:pytorch-exercise/pt01_generative_adversarial_network.py at main · Baileyswu/pytorch-exercise
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.utils.data import DataLoaderfrom bokeh.io import show, output_notebook
from bokeh.plotting import figure, gridplot
from bokeh.models import LinearAxis, Range1d
output_notebook()train_dataset = dsets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = dsets.MNIST(root='./data', train=False, transform=transforms.ToTensor())batch_size = 50
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=1, shuffle=True)# 定义模型
class GAN(nn.Module):def __init__(self):super().__init__()# 生成器self.G = nn.Sequential(nn.Linear(64, 256),nn.LeakyReLU(0.2),nn.Linear(256, 256),nn.LeakyReLU(0.2),nn.Linear(256, 784),nn.Tanh())# 判定器self.D = nn.Sequential(nn.Linear(784, 256),nn.LeakyReLU(0.2),nn.Linear(256, 256),nn.LeakyReLU(0.2),nn.Linear(256, 1),nn.Sigmoid())def forward(self, z):return self.G(z)# 将输入噪音z传入G,然后G生成的数据给D进行判断def score(self, z):fake_imgs = self.G(z)fake_score = self.D(fake_imgs)return fake_scorelrate = 0.0001
epochs = 300# 模型实例化
model = GAN().cuda()
# 损失函数
criterion = nn.BCELoss()
# 优化器
optim_G = torch.optim.Adam(model.G.parameters(), lr = lrate)
optim_D = torch.optim.Adam(model.D.parameters(), lr = lrate)# 模型可视化
model# 绘制图片
def list_img(i, img, title):img = img.reshape(28, 28)plt.subplot(2, 5, i+1)plt.imshow(img)plt.title('%s' % (title))# 可视化生成的数据
def generate_test(inputs, title=''):plt.figure(figsize=(15, 6))imgs = model(inputs)imgs = (imgs + 1) / 2imgs.clamp(0, 1)for i in range(len(inputs)):list_img(i, imgs[i].cpu().detach().numpy(), title)plt.show()result_d = []
result_g = []
test_inputs = torch.randn(5, 64).cuda()# 开始训练
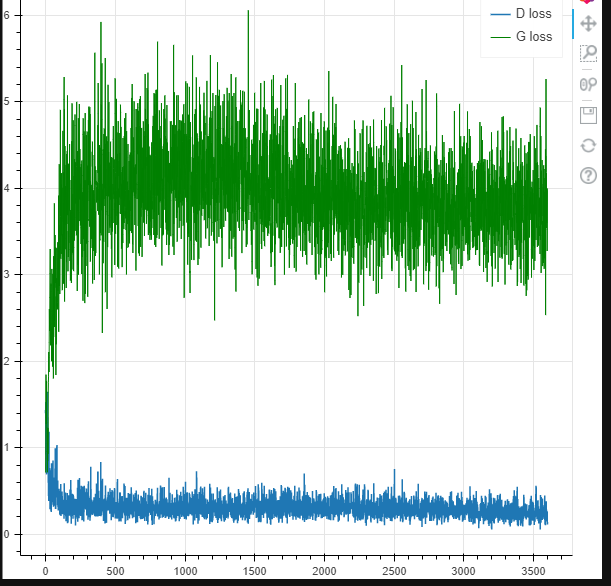
for e in range(epochs):for i, (inputs, _) in enumerate(train_loader):inputs = inputs.view(-1, 28*28).cuda()real_labels = torch.ones(batch_size, 1).cuda()fake_labels = torch.zeros(batch_size, 1).cuda()# 对D进行训练real_score = model.D(inputs)loss_d_real = criterion(real_score, real_labels)fake_score = model.score(torch.randn(batch_size, 64).cuda())loss_d_fake = criterion(fake_score, fake_labels)optim_D.zero_grad() loss_d = loss_d_real + loss_d_fakeloss_d.backward()optim_D.step()fake_score = model.score(torch.randn(batch_size, 64).cuda())loss_g = criterion(fake_score, real_labels)optim_G.zero_grad()loss_g.backward()optim_G.step()if i % 100 == 0:result_d.append(float(loss_d))result_g.append(float(loss_g))if e % 30 == 0:generate_test(test_inputs, str(e))
fig = figure()
fig.line(range(len(result_d)), result_d, legend_label='D loss', line_width=1.5)
fig.line(range(len(result_g)), result_g, legend_label='G loss', line_color="green")
show(fig)# 测试生成器效果
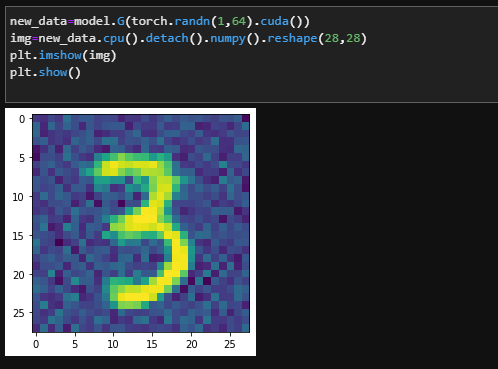
new_data=model.G(torch.randn(1,64).cuda())
img=new_data.cpu().detach().numpy().reshape(28,28)
plt.imshow(img)
plt.show()
训练图片过程
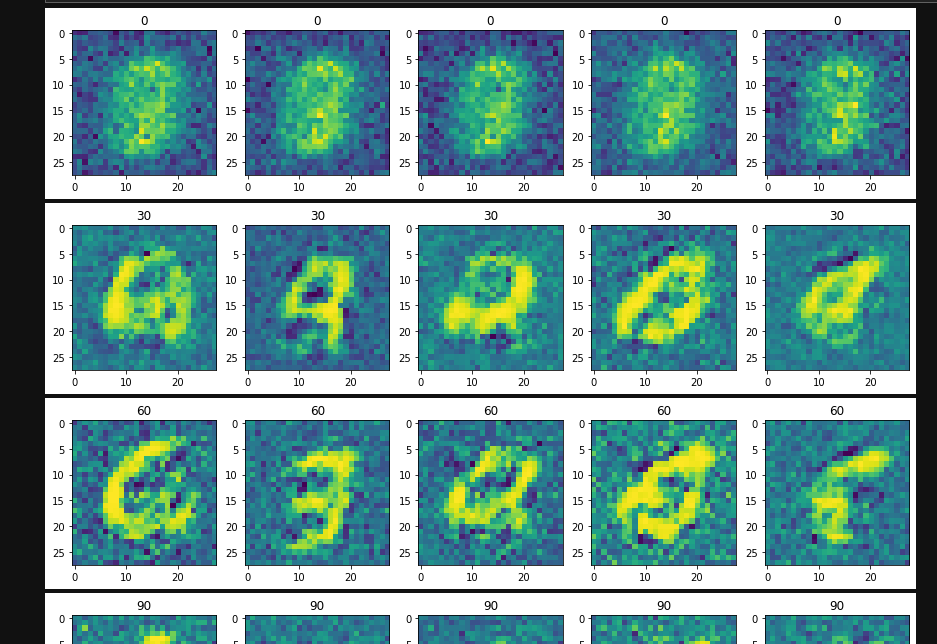
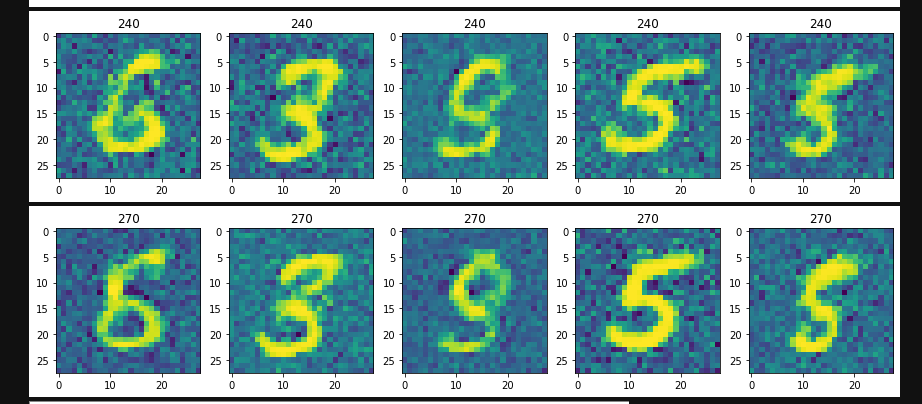
损失曲线
测试生成图片
4.2 放大招—生成美女图片
4.2.1 爬取美女图片
这里我爬取的是百度图片,爬虫代码链接爬取百度图片——详细思路_小白一直白-CSDN博客_爬取百度图片
# 爬取数据
import requests
import os
import urllibclass Spider_baidu_image():def __init__(self):self.url = 'http://image.baidu.com/search/acjson?'self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.\3497.81 Safari/537.36'}self.headers_image = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.\3497.81 Safari/537.36','Referer':'http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1557124645631_R&pv=&ic=&nc=1&z=&hd=1&latest=0©right=0&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E8%83%A1%E6%AD%8C'}# self.keyword = '刘亦菲壁纸'self.keyword = input("请输入搜索图片关键字:")self.paginator = int(input("请输入搜索页数,每页30张图片:"))# self.paginator = 50# print(type(self.keyword),self.paginator)# exit()def get_param(self):"""获取url请求的参数,存入列表并返回:return: """keyword = urllib.parse.quote(self.keyword)params = []for i in range(1,self.paginator+1):params.append('tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=1&latest=0©right=0&word={}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=star&pn={}&rn=30&gsm=78&1557125391211='.format(keyword,keyword,30*i))return paramsdef get_urls(self,params):"""由url参数返回各个url拼接后的响应,存入列表并返回:return:"""urls = []for i in params:urls.append(self.url+i)return urlsdef get_image_url(self,urls):image_url = []for url in urls:json_data = requests.get(url,headers = self.headers).json()json_data = json_data.get('data')for i in json_data:if i:image_url.append(i.get('thumbURL'))return image_urldef get_image(self,image_url):"""根据图片url,在本地目录下新建一个以搜索关键字命名的文件夹,然后将每一个图片存入。:param image_url: :return: """cwd = os.getcwd()file_name = os.path.join(cwd,self.keyword)if not os.path.exists(self.keyword):os.mkdir(file_name)for index,url in enumerate(image_url,start=1):with open(file_name+'\\{}.jpg'.format(index),'wb') as f:f.write(requests.get(url,headers = self.headers_image).content)if index != 0 and index % 30 == 0:print('{}第{}页下载完成'.format(self.keyword,index/30))def __call__(self, *args, **kwargs):params = self.get_param()urls = self.get_urls(params)image_url = self.get_image_url(urls)self.get_image(image_url)if __name__ == '__main__':spider = Spider_baidu_image()spider()
4.2.2 提取人脸
-
首先去https://github.com/nagadomi/lbpcascade_animeface 下载xml文件
-
将文件夹重命名英文(我这里改为girls),为了解决opencv读取图片不能有中文的问题
最后将文件夹中的图片全部变为128*128
# 提取美女的面部图片import cv2import sysimport numpy as npimport os.pathfrom glob import globdef detect(filename, cascade_file="lbpcascade_animeface.xml"):if not os.path.isfile(cascade_file):raise RuntimeError("%s: not found" % cascade_file)cascade = cv2.CascadeClassifier(cascade_file)image = cv2.imread(filename)#image = cv2.imdecode(np.fromfile(filename, dtype=np.uint8),0)gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)gray = cv2.equalizeHist(gray)faces = cascade.detectMultiScale(gray,# detector optionsscaleFactor=1.1,minNeighbors=5,minSize=(48, 48))for i, (x, y, w, h) in enumerate(faces):face = image[y: y + h, x:x + w, :]face = cv2.resize(face, (128,128))save_filename = '%s-%d.jpg' % (os.path.basename(filename).split('.')[0], i)cv2.imwrite("faces/" + save_filename, face)if __name__ == '__main__':if os.path.exists('faces') is False:os.makedirs('faces')file_list = glob('girls/*.jpg')for filename in file_list:detect(filename)4.2.3 开始训练
这里是基于tensorflow 1.X写的DCGAN,当然如果你现在环境是2.X也无所谓,使用
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
屏蔽掉2.X的代码部分就好
# 开始训练生成美女图片
import os
import time
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()import numpy as np
from glob import glob
import datetime
import random
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline# 生成器
def generator(z, output_channel_dim, training):with tf.variable_scope("generator", reuse= not training):# 8x8x1024fully_connected = tf.layers.dense(z, 8*8*1024)fully_connected = tf.reshape(fully_connected, (-1, 8, 8, 1024))fully_connected = tf.nn.leaky_relu(fully_connected)# 8x8x1024 -> 16x16x512trans_conv1 = tf.layers.conv2d_transpose(inputs=fully_connected,filters=512,kernel_size=[5,5],strides=[2,2],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name="trans_conv1")batch_trans_conv1 = tf.layers.batch_normalization(inputs = trans_conv1,training=training,epsilon=EPSILON,name="batch_trans_conv1")trans_conv1_out = tf.nn.leaky_relu(batch_trans_conv1,name="trans_conv1_out")# 16x16x512 -> 32x32x256trans_conv2 = tf.layers.conv2d_transpose(inputs=trans_conv1_out,filters=256,kernel_size=[5,5],strides=[2,2],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name="trans_conv2")batch_trans_conv2 = tf.layers.batch_normalization(inputs = trans_conv2,training=training,epsilon=EPSILON,name="batch_trans_conv2")trans_conv2_out = tf.nn.leaky_relu(batch_trans_conv2,name="trans_conv2_out")# 32x32x256 -> 64x64x128trans_conv3 = tf.layers.conv2d_transpose(inputs=trans_conv2_out,filters=128,kernel_size=[5,5],strides=[2,2],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name="trans_conv3")batch_trans_conv3 = tf.layers.batch_normalization(inputs = trans_conv3,training=training,epsilon=EPSILON,name="batch_trans_conv3")trans_conv3_out = tf.nn.leaky_relu(batch_trans_conv3,name="trans_conv3_out")# 64x64x128 -> 128x128x64trans_conv4 = tf.layers.conv2d_transpose(inputs=trans_conv3_out,filters=64,kernel_size=[5,5],strides=[2,2],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name="trans_conv4")batch_trans_conv4 = tf.layers.batch_normalization(inputs = trans_conv4,training=training,epsilon=EPSILON,name="batch_trans_conv4")trans_conv4_out = tf.nn.leaky_relu(batch_trans_conv4,name="trans_conv4_out")# 128x128x64 -> 128x128x3logits = tf.layers.conv2d_transpose(inputs=trans_conv4_out,filters=3,kernel_size=[5,5],strides=[1,1],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name="logits")out = tf.tanh(logits, name="out")return out# 判定器
def discriminator(x, reuse):with tf.variable_scope("discriminator", reuse=reuse): # 128*128*3 -> 64x64x64 conv1 = tf.layers.conv2d(inputs=x,filters=64,kernel_size=[5,5],strides=[2,2],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name='conv1')batch_norm1 = tf.layers.batch_normalization(conv1,training=True,epsilon=EPSILON,name='batch_norm1')conv1_out = tf.nn.leaky_relu(batch_norm1,name="conv1_out")# 64x64x64-> 32x32x128 conv2 = tf.layers.conv2d(inputs=conv1_out,filters=128,kernel_size=[5, 5],strides=[2, 2],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name='conv2')batch_norm2 = tf.layers.batch_normalization(conv2,training=True,epsilon=EPSILON,name='batch_norm2')conv2_out = tf.nn.leaky_relu(batch_norm2,name="conv2_out")# 32x32x128 -> 16x16x256 conv3 = tf.layers.conv2d(inputs=conv2_out,filters=256,kernel_size=[5, 5],strides=[2, 2],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name='conv3')batch_norm3 = tf.layers.batch_normalization(conv3,training=True,epsilon=EPSILON,name='batch_norm3')conv3_out = tf.nn.leaky_relu(batch_norm3,name="conv3_out")# 16x16x256 -> 16x16x512conv4 = tf.layers.conv2d(inputs=conv3_out,filters=512,kernel_size=[5, 5],strides=[1, 1],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name='conv4')batch_norm4 = tf.layers.batch_normalization(conv4,training=True,epsilon=EPSILON,name='batch_norm4')conv4_out = tf.nn.leaky_relu(batch_norm4,name="conv4_out")# 16x16x512 -> 8x8x1024conv5 = tf.layers.conv2d(inputs=conv4_out,filters=1024,kernel_size=[5, 5],strides=[2, 2],padding="SAME",kernel_initializer=tf.truncated_normal_initializer(stddev=WEIGHT_INIT_STDDEV),name='conv5')batch_norm5 = tf.layers.batch_normalization(conv5,training=True,epsilon=EPSILON,name='batch_norm5')conv5_out = tf.nn.leaky_relu(batch_norm5,name="conv5_out")flatten = tf.reshape(conv5_out, (-1, 8*8*1024))logits = tf.layers.dense(inputs=flatten,units=1,activation=None)out = tf.sigmoid(logits)return out, logits # 模型损失
def model_loss(input_real, input_z, output_channel_dim):g_model = generator(input_z, output_channel_dim, True)noisy_input_real = input_real + tf.random_normal(shape=tf.shape(input_real),mean=0.0,stddev=random.uniform(0.0, 0.1),dtype=tf.float32)d_model_real, d_logits_real = discriminator(noisy_input_real, reuse=False)d_model_fake, d_logits_fake = discriminator(g_model, reuse=True)d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,labels=tf.ones_like(d_model_real)*random.uniform(0.9, 1.0)))d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,labels=tf.zeros_like(d_model_fake)))d_loss = tf.reduce_mean(0.5 * (d_loss_real + d_loss_fake))g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,labels=tf.ones_like(d_model_fake)))return d_loss, g_loss# 模型优化
def model_optimizers(d_loss, g_loss):t_vars = tf.trainable_variables()g_vars = [var for var in t_vars if var.name.startswith("generator")]d_vars = [var for var in t_vars if var.name.startswith("discriminator")]update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)gen_updates = [op for op in update_ops if op.name.startswith('generator')]with tf.control_dependencies(gen_updates):d_train_opt = tf.train.AdamOptimizer(learning_rate=LR_D, beta1=BETA1).minimize(d_loss, var_list=d_vars)g_train_opt = tf.train.AdamOptimizer(learning_rate=LR_G, beta1=BETA1).minimize(g_loss, var_list=g_vars) return d_train_opt, g_train_opt# 模型输入
def model_inputs(real_dim, z_dim):inputs_real = tf.placeholder(tf.float32, (None, *real_dim), name='inputs_real')inputs_z = tf.placeholder(tf.float32, (None, z_dim), name="input_z")learning_rate_G = tf.placeholder(tf.float32, name="lr_g")learning_rate_D = tf.placeholder(tf.float32, name="lr_d")return inputs_real, inputs_z, learning_rate_G, learning_rate_D# 展示样例
def show_samples(sample_images, name, epoch):figure, axes = plt.subplots(1, len(sample_images), figsize = (IMAGE_SIZE, IMAGE_SIZE))for index, axis in enumerate(axes):axis.axis('off')image_array = sample_images[index]axis.imshow(image_array)image = Image.fromarray(image_array)image.save(name+"_"+str(epoch)+"_"+str(index)+".png") plt.savefig(name+"_"+str(epoch)+".png", bbox_inches='tight', pad_inches=0)plt.show()plt.close()# 测试
def test(sess, input_z, out_channel_dim, epoch):example_z = np.random.uniform(-1, 1, size=[SAMPLES_TO_SHOW, input_z.get_shape().as_list()[-1]])samples = sess.run(generator(input_z, out_channel_dim, False), feed_dict={input_z: example_z})sample_images = [((sample + 1.0) * 127.5).astype(np.uint8) for sample in samples]show_samples(sample_images, OUTPUT_DIR + "samples", epoch)# 每个epoch的训练情况总结
def summarize_epoch(epoch, duration, sess, d_losses, g_losses, input_z, data_shape):minibatch_size = int(data_shape[0]//BATCH_SIZE)print("Epoch {}/{}".format(epoch, EPOCHS),"\nDuration: {:.5f}".format(duration),"\nD Loss: {:.5f}".format(np.mean(d_losses[-minibatch_size:])),"\nG Loss: {:.5f}".format(np.mean(g_losses[-minibatch_size:])))fig, ax = plt.subplots()plt.plot(d_losses, label='Discriminator', alpha=0.6)plt.plot(g_losses, label='Generator', alpha=0.6)plt.title("Losses")plt.legend()plt.savefig(OUTPUT_DIR + "losses_" + str(epoch) + ".png")plt.show()plt.close()test(sess, input_z, data_shape[3], epoch)# 获得批次
def get_batches(data):batches = []for i in range(int(data.shape[0]//BATCH_SIZE)):batch = data[i * BATCH_SIZE:(i + 1) * BATCH_SIZE]augmented_images = []for img in batch:image = Image.fromarray(img)if random.choice([True, False]):image = image.transpose(Image.FLIP_LEFT_RIGHT)augmented_images.append(np.asarray(image))batch = np.asarray(augmented_images)normalized_batch = (batch / 127.5) - 1.0batches.append(normalized_batch)return batches# 训练
def train(get_batches, data_shape, checkpoint_to_load=None):input_images, input_z, lr_G, lr_D = model_inputs(data_shape[1:], NOISE_SIZE)d_loss, g_loss = model_loss(input_images, input_z, data_shape[3])d_opt, g_opt = model_optimizers(d_loss, g_loss)with tf.Session() as sess:sess.run(tf.global_variables_initializer())d_losses = []g_losses = []for epoch in range(EPOCHS): start_time = time.time()for batch_images in get_batches:batch_z = np.random.uniform(-1, 1, size=(BATCH_SIZE, NOISE_SIZE))_ = sess.run(d_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_D: LR_D})_ = sess.run(g_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_G: LR_G})d_losses.append(d_loss.eval({input_z: batch_z, input_images: batch_images}))g_losses.append(g_loss.eval({input_z: batch_z}))if epoch%30==0:summarize_epoch(epoch, time.time()-start_time, sess, d_losses, g_losses, input_z, data_shape)# 参数设置
INPUT_DATA_DIR = "./faces"
OUTPUT_DIR = './newpics/'
if not os.path.exists(OUTPUT_DIR):os.makedirs(OUTPUT_DIR)IMAGE_SIZE = 128
NOISE_SIZE = 100
LR_D = 0.00003
LR_G = 0.0003
BATCH_SIZE = 64
EPOCHS = 300
BETA1 = 0.5
WEIGHT_INIT_STDDEV = 0.02
EPSILON = 0.00005
SAMPLES_TO_SHOW = 5# 正式训练
input_images = np.asarray([np.asarray(Image.open(file).resize((IMAGE_SIZE, IMAGE_SIZE))) for file in glob(INPUT_DATA_DIR + '/*.jpg')])
print ("Input: " + str(input_images.shape))np.random.shuffle(input_images)sample_images = random.sample(list(input_images), SAMPLES_TO_SHOW)
show_samples(sample_images, OUTPUT_DIR + "inputs", 0)with tf.Graph().as_default():train(get_batches(input_images), input_images.shape)
随机输出五张输入的图片

开始的loss

第15个epoch的loss以及生成的图片

这个时候女朋友已经初具雏形,继续训练,第30个epoch

轮廓更明显,但是整体还是很模糊。

生成的图片这哪里是女朋友,明明是阿姨,还带点异国风情的那种。。。
失败原因可能在于:
- 爬取的百度图片里面不全是美女,有卡通图片以及一些一场图片干扰,我没有对图片进行清理,下次可以用一下百度的api,颜值没有60分的pass掉。
- 网络训练提前结束,笔记本训练属实不给力,慢而且烫,明天用工作站试试。
- DCGAN中生成器网络设计还可以优化。
这一次制作女朋友应该算是以失败告终,下次用其它网络再试试!毕竟这可比现实中找女朋友容易多了,呜呜呜











![群星服务器id不显示,群星代码([群星]求助,领袖特性代号怎么查看啊 NGA玩家社区)...](https://img-blog.csdnimg.cn/img_convert/549c3edcd48c5e6e78b793c3e1195019.png)


