Day 10
本节主要讲解的是Python中文件操作(IO 技术)方面的知识。
文章目录
- 1.文件的处理
- 1.1.1 文本文件和二进制文件
- 1.1.2 文件操作相关模块概述
- 1.3 创建文件对象 open()
- 1.4 文本文件的写入
- 1.5 常用编码介绍
- 1.5.1 中文乱码问题
- 1.5.2 write()/writelines()写入数据
- 1.5.3 close()关闭文件流与with 语句(上下文管理器)
- 1.6 文本文件的读取
- 1.7 二进制文件的读取和写入
- 1.8 文件对象的常用属性和方法
- 1.9 使用 pickle 序列化
- 1.10 CSV 文件的操作
- 1.11 os 和 os.path 模块
一个完整的程序一般都包括数据的存储和读取;我们在前面写的程序数据都没有进行实际的存储,因此 python 解释器执行完数据就消失了。实际开发中,我们经常需要从外部存储介质(硬盘、光盘、U 盘等)读取数据,或者将程序产生的数据存储到文件中,实现“持久化”保存。
1.文件的处理
1.1.1 文本文件和二进制文件
按文件中数据组织形式,我们把文件分为文本文件和二进制文件两大类。
- 文本文件
文本文件存储的是普通“字符”文本,python 默认为 unicode 字符集(两个字节表示一个字符,最多可以表示:65536 个),可以使用记事本程序打开。但是,像 word 软件编辑的文档不是文本文件。 - 二进制文件
二进制文件把数据内容用“字节”进行存储,无法用记事本打开。必须使用专用的软件解码。常见的有:MP4 视频文件、MP3 音频文件、JPG 图片、doc 文档等等。
1.1.2 文件操作相关模块概述
Python 标准库中,如下是文件操作相关的模块,我们会陆续给大家介绍。
名称 说明
io 模块 文件流的输入和输出操作 input
os 模块 基本操作系统功能,包括文件操作
glob 模块 查找符合特定规则的文件路径名
fnmatch 模块 使用模式来匹配文件路径名
fileinput 模块 处理多个输入文件
filecmp 模块 用于文件的比较
cvs 模块 用于 csv 文件处理
pickle 和 cPickle 用于序列化和反序列化
xml 包 用于 XML 数据处理
bz2、gzip、zipfile、zlib、tarfile 用于处理压缩和解压缩文件(分别对应不同的算法)
1.3 创建文件对象 open()
open()函数用于创建文件对象,基本语法格式如下:
open(文件名[,打开方式])
如果只是文件名,代表在当前目录下的文件。文件名可以录入全路径,比如:D:\a\b.txt。
为了减少“\”的输入,可以使用原始字符串:r“d:\b.txt”。示例如下:
f = open(r"d:\b.txt",“w”)
打开方式有如下几种:
| 模式 | 对应的功能 |
|---|---|
| r | 读 read 模式 |
| w | 写 write 模式。如果文件不存在则创建;如果文件存在,则重写新内容; |
| a | 追加 append 模式。如果文件不存在则创建;如果文件存在,则在文件末尾追加内容 |
| b | 二进制 binary 模式(可与其他模式组合使用) |
| + | 读、写模式(可与其他模式组合使用) |
文本文件对象和二进制文件对象的创建:
如果我们没有增加模式“b”,则默认创建的是文本文件对象,处理的基本单元是“字符”。如果是二进制模式“b”,则创建的是二进制文件对象,处理的基本单元是“字节”。
1.4 文本文件的写入
文本文件的写入一般就是三个步骤:
- 创建文件对象
- 写入数据
- 关闭文件对象
f = open(r"a.txt","a")
s = "kaikai\n666\n"
f.write(s)
f.close()
1.5 常用编码介绍
在操作文本文件时,经常会操作中文,这时候就经常会碰到乱码问题。为了让大家有能力解决中文乱码问题,这里简单介绍一下各种编码之间的关系。

1.5.1 中文乱码问题
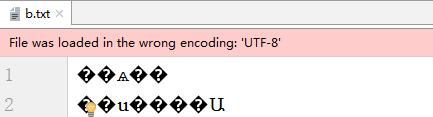
windows 操作系统默认的编码是 GBK,Linux 操作系统默认的编码是 UTF-8。当我们用 open()时,调用的是操作系统打开的文件,默认的编码是GBK。
#测试中文写入
f = open(r"b.txt","w")
f.write("谭松韵天下第一美\n谭松韵是楷楷的偶像\n")
f,close()
运行结果(Linux 环境中不存在这个问题):
 我们在文件编辑区单击右键,选择FileEncoding,选择 GBK 即可:
我们在文件编辑区单击右键,选择FileEncoding,选择 GBK 即可:
 再选择 Reload,文件即显示正常。
再选择 Reload,文件即显示正常。
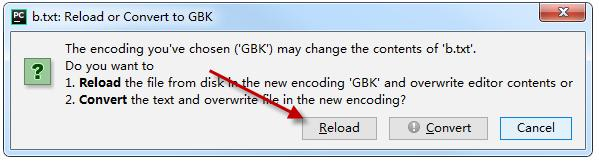 我们也可以通过下面的方法进行解决
我们也可以通过下面的方法进行解决
f = open(r"b.txt","w",encoding = "utf-8")
f.write("谭松韵天下第一美\n谭松韵是楷楷的偶像\n")
f.close()
1.5.2 write()/writelines()写入数据
write(a):把字符串 a 写入到文件中。
writelines(b):把字符串列表写入文件中,不添加换行符。
#添加字符串列表数据到文件中
f = open(r"b.txt","w",encoding = "utf-8")
s = ["谭松韵\n","耿耿\n","袁今夏\n"]
f.writelines(s)
f.close()
1.5.3 close()关闭文件流与with 语句(上下文管理器)
由于文件底层是由操作系统控制,所以我们打开的文件对象必须显式调用 close()方法关闭文件对象。当调用 close()方法时,首先会把缓冲区数据写入文件(也可以直接调用 flush()方法),再关闭文件,释放文件对象。
为了确保打开的文件对象正常关闭,一般结合异常机制的 finally 或者 with 关键字实现,无论何种情况都能关闭打开的文件对象。
try:f = open(r"b.txt","a")str = "kaikia"f.write(str)
except BaseException as e:print(e)
finally:
f.close()
with 关键字(上下文管理器)可以自动管理上下文资源,不论什么原因跳出 with 块,都能确保文件正确的关闭,并且可以在代码块执行完毕后自动还原进入该代码块时的现场。
s = ["谭松韵\n","耿耿\n","袁今夏\n"]
with open(r"d:\bb.txt","w") as f:
f.writelines(s)
1.6 文本文件的读取
文件的读取一般使用如下三个方法:
- read([size])
从文件中读取 size 个字符,并作为结果返回。如果没有 size 参数,则读取整个文件。读取到文件末尾,会返回空字符串。 - readline()
读取一行内容作为结果返回。读取到文件末尾,会返回空字符串。 - readlines()
文本文件中,每一行作为一个字符串存入列表中,返回该列表。
with open(r"bb","r",encoding="utf-8") as f:print(f.read(4))
######下面这种方法是全部读入,而不是只读前四个字符######
with open(r"d:\bb.txt","r") as f:print(f.read())
示例:按行读取一个文件
with open(r"bb.txt","r") as f:while True:fragment = f.readline()if not fragment:breakelseprint(fragment,end"")
示例:为文本文件每一行的末尾增加行号
with open(r"d:\bb.txt","r") as f:print(f.read())
示例:为文本文件每一行的末尾增加行号
with open("e.txt","r",encoding="utf-8") as f:lines = f.readlines()lines = [ line.rstrip()+" #"+str(index+1)+"\n" for index,line in enumerate(lines)]
#推导式生成列表
with open("e.txt","w",encoding="utf-8") as f:f.writelines(lines)
1.7 二进制文件的读取和写入
二进制文件的处理流程和文本文件流程一致。首先还是要创建文件对象,不过,我们需要指定二进制模式,从而创建出二进制文件对象。例如:
f = open(r"d:\a.txt", ‘wb’) #可写的、重写模式的二进制文件对象
f = open(r"d:\a.txt", ‘ab’) #可写的、追加模式的二进制文件对象
f = open(r"d:\a.txt", ‘rb’) #可读的二进制文件对象
with open('aa.gif', 'rb') as f:with open('aa_copy.gif', 'wb') as w:for line in f.readlines():w.write(line)
print('图片拷贝完成!')
1.8 文件对象的常用属性和方法
name 返回文件的名字
mode 返回文件的打开模式
closed 若文件被关闭则返回 True
方法名 说明
read([size]) 从文件中读取 size 个字节或字符的内容返回。若省略[size],则读取到文件末尾,即一次读取文件所有内容
readline() 从文本文件中读取一行内容
readlines() 把文本文件中每一行都作为独立的字符串对象,并将这些对象放入列表返回
write(str) 将字符串 str 内容写入文件
writelines(s) 将字符串列表 s 写入文件文件,不添加换行符
seek(offset[,whence]) 把文件指针移动到新的位置,offset 表示相对于 whence 的多少个字节的偏移量;
offset:
off 为正往结束方向移动,为负往开始方向移动
whence 不同的值代表不同含义:
0: 从文件头开始计算(默认值)
1:从当前位置开始计算
2:从文件尾开始计算
tell() 返回文件指针的当前位置
truncate([size]) 不论指针在什么位置,只留下指针前 size 个字节的内容,其余全部删除;
如果没有传入 size,则当指针当前位置到文件末尾内容全部删除
flush() 把缓冲区的内容写入文件,但不关闭文件
close() 把缓冲区内容写入文件,同时关闭文件,释放文件对象相关资源
1.9 使用 pickle 序列化
Python 中,一切皆对象,对象本质上就是一个“存储数据的内存块”。有时候,我们需要将“内存块的数据”保存到硬盘上,或者通过网络传输到其他的计算机上。这时候,就需要“对象的序列化和反序列化”。 对象的序列化机制广泛的应用在分布式、并行系统上。
序列化指的是:将对象转化成“串行化”数据形式,存储到硬盘或通过网络传输到其他地方。反序列化是指相反的过程,将读取到的“串行化数据”转化成对象。
我们可以使用 pickle 模块中的函数,实现序列化和反序列操作。
序列化我们使用:
pickle.dump(obj, file),obj 就是要被序列化的对象,file 指的是存储的文件
pickle.load(file),从 file 读取数据,反序列化成对象
#将对象序列化到文件中
import pickle
with open(r"d:\data.dat","wb") as f:a1 = "谭松韵"a2 = 234a3 = [20,30,40]pickle.dump(a1,f)pickle.dump(a2, f)pickle.dump(a3, f)
#将获得的数据反序列化成对象
with open(r"d:\data.dat","rb") as f:a1 = pickle.load(f)a2 = pickle.load(f)a3 = pickle.load(f)print(a1)print(a2)print(a3)
1.10 CSV 文件的操作
csv (Comma Separated Values) 是逗号分隔符文本格式,常用于数据交换、Excel文件和数据库数据的导入和导出。 与 Excel 文件不同,CSV 文件中:
值没有类型,所有值都是字符串
不能指定字体颜色等样式
不能指定单元格的宽高,不能合并单元格
没有多个工作表
不能嵌入图像图表
Python 标准库的模块 csv 提供了读取和写入 csv 格式文件的对象。
我们在 excel 中建立一个简单的表格:
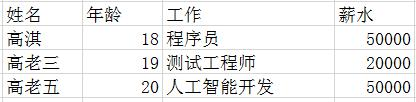 另存为"csv(逗号分隔)",我们打开查看这个 csv 文件内容:
另存为"csv(逗号分隔)",我们打开查看这个 csv 文件内容:
姓名,年龄,工作,薪水
高淇,18,程序员,50000
高老三,19,测试工程师,20000
高老五,20,人工智能开发,50000
1.11 os 和 os.path 模块
os 模块可以帮助我们直接对操作系统进行操作。我们可以直接调用操作系统的可执行文件、命令,直接操作文件、目录等等。在系统运维的核心基础。
os.system 可以帮助我们直接调用系统的命令
import os
os.system("notepad.exe")
os.system("ping www.baidu.com")
注:Linux 是命令行操作更容易,我们可以通过 os.system 可以更加容易的调用相关的命令;
注:控制台输出中文可能会有乱码问题,可以在 file–>setting 中设置:
 os 模块-文件和目录操作
os 模块-文件和目录操作
| 方法名 | 描述 |
|---|---|
| remove(path) | 删除指定的文件 |
| rename(src,dest) | 重命名文件或目录 |
| stat(path) | 返回文件的所有属性 |
| listdir(path) | 返回 path 目录下的文件和目录列表 |
| mkdir(path) | 创建目录 |
| makedirs(path1/path2/path3/…) | 创建多级目录 |
| getcwd() | 返回当前工作目录:current work dir |
| chdir(path) | 把 path 设为当前工作目录 |
| walk() | 遍历目录树 |
| sep | 当前操作系统所使用的路径分隔符 |
使用格式如下:
#coding=utf-8
#测试 os 模块中,关于文件和目录的操作
import os
#############获取文件和文件夹相关的信息################
print(os.name)
print(os.sep)
print(repr(os.linesep))
os.path 模块
os.path 模块提供了目录相关(路径判断、路径切分、路径连接、文件夹遍历)的操作
| 名称 | 描述 |
|---|---|
| isabs(path) | 判断 path 是否绝对路径 |
| isdir(path) | 判断 path 是否为目录 |
| isfile(path) | 判断 path 是否为文件 |
| exists(path) | 判断指定路径的文件是否存在 |
| getsize(filename) | 返回文件的大小 |
| abspath(path) | 返回绝对路径 |
| dirname§ | 返回目录的路径 |
| getatime(filename) | 返回文件的最后访问时间 |
| getmtime(filename) | 返回文件的最后修改时间 |
| walk(top,func,arg) | 递归方式遍历目录 |
| join(path,*paths) | 连接多个 path |
| split(path) | 对路径进行分割,以列表形式返回 |
| splitext(path) | 从路径中分割文件的扩展名 |
使用格式如下:
#测试 os.path 常用方法
import os
import os.path
#################获得目录、文件基本信息
######################
print(os.path.isabs("d:/a.txt"))
print(os.path.isdir("d:/a.txt"))
print(os.path.isfile("d:/a.txt"))
print(os.path.exists("a.txt"))
#是否绝对路径
#是否目录
#是否文件
#文件是否存在
os.walk()方法:
返回一个 3 个元素的元组,(dirpath, dirnames, filenames),
dirpath:要列出指定目录的路径
dirnames:目录下的所有文件夹
filenames:目录下的所有文件
示例:使用 walk()递归遍历所有文件和目录
import os
all_files = []
path = os.getcwd()
list_files = os.walk(path)
for dirpath,dirnames,filenames in list_files:for dir in dirnames:all_files.append(os.path.join(dirpath,dir))for name in filenames:all_files.append(os.path.join(dirpath,name))
#打印子目录和子文件
for file in all_files:
print(file)