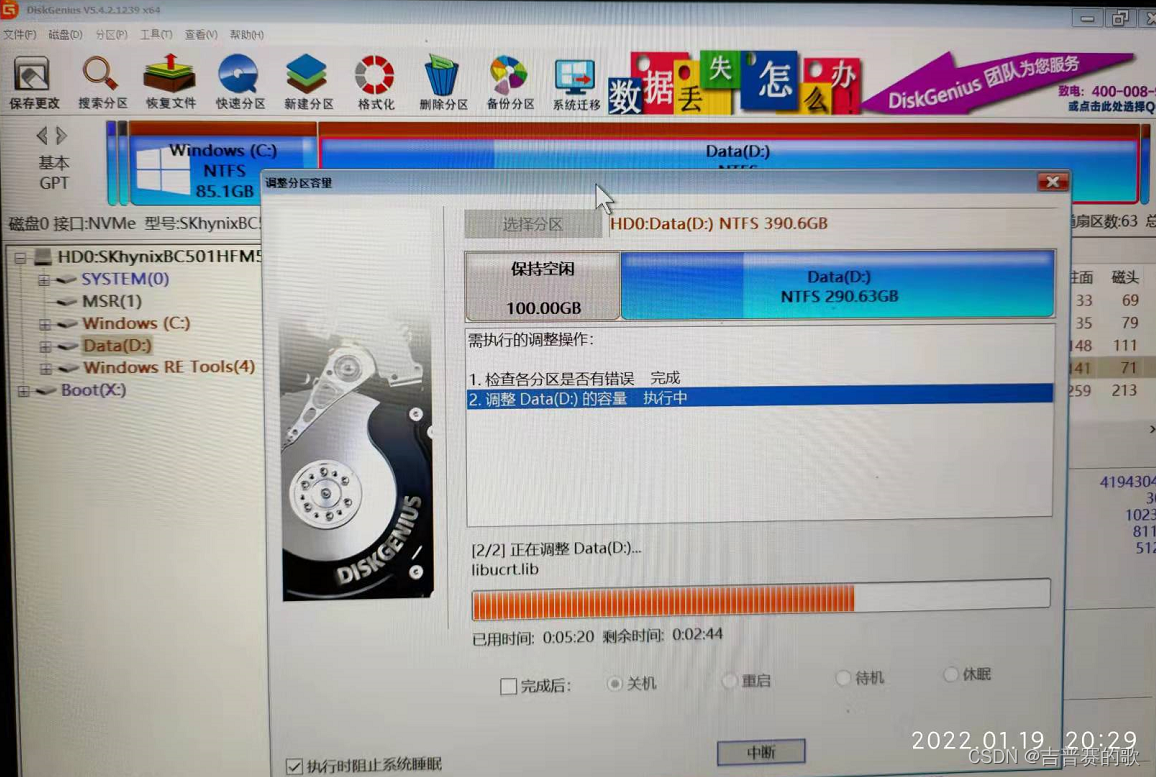
将昨日取得的众多的沪深龙虎榜数据整一整
提取文件夹内所有抓取下来的沪深龙虎榜数据,整理出沪深两市(含中小创)涨幅榜股票及前5大买入卖出资金净值,保存到csv文件
再手动使用数据透视表进行统计
原始数据:
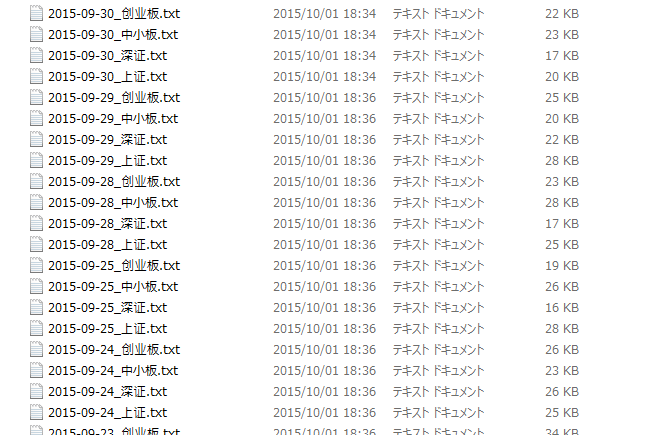

整理后数据:

代码如下(如果觉得对于炒股又用,敬请使用):
1 #coding=utf-8 2 3 import re 4 import os 5 import time 6 import datetime 7 8 def writeFile(file,stocks,BS,day): 9 for s in stocks: 10 allfile.write('\n') 11 allfile.write(day 12 +',"\''+s['code'] 13 +'","'+s['name'] 14 +'",'+str(float(BS[s['code']]['buy'])-float(BS[s['code']]['sell'])) 15 +','+BS[s['code']]['buy'] 16 +','+BS[s['code']]['sell'] 17 +','+s['偏离值'] 18 +',"'+s['成交量'] 19 +'","'+s['成交金额(万元)']+'"') 20 21 ''' 22 allfile.write(day 23 +",'"+s["code"] 24 +"','"+s["name"] 25 +"',"+str(float(BS[s["code"]]["buy"])-float(BS[s["code"]]["sell"])) 26 +","+BS[s["code"]]["buy"] 27 +","+BS[s["code"]]["sell"] 28 +","+s["偏离值"] 29 +",'"+s["成交量"] 30 +"','"+s["成交金额(万元)"]+"'") 31 ''' 32 33 path=r'./files' 34 #path=r'./a' 35 files = os.listdir(path) 36 files.sort() 37 38 nowDayStr = '' 39 now = datetime.datetime.now() 40 nowStr = now.strftime("%Y-%m-%d") 41 42 allfile = open(r'./沪深龙虎榜统计_'+nowStr+'.csv','w') 43 allfile.write('"日期","代码","名称","净流入流出","流入","流出","偏离值","成交量","成交金额(万元)"') 44 for f in files: 45 if(os.path.isfile(path+'/'+f) & 46 f.endswith('.txt')): 47 #print(path+'/'+f.replace('.txt','')) 48 a = f.replace('.txt','').split('_') 49 print('读取文件:'+path+'/'+f) 50 ''' 51 if(nowDayStr!=a[0]): 52 #print('a') 53 else: 54 #print('b') 55 nowDayStr = a[0] 56 ''' 57 nowDayStr = a[0] 58 59 f=open(path+'/'+f,'rt') 60 infos = f.readlines() 61 f.close() 62 63 if(a[1]=='上证'): 64 #continue #test jump 65 #上证 66 readStocks = 1 67 readBS = 0 68 readBuy = 0 69 readSell = 0 70 nowStock = '' 71 stocks = [] 72 BS = dict() 73 buy = 0 74 sell = 0 75 for info in infos: 76 77 info = re.sub('\ +', '_',info) 78 info = re.sub('\n', '',info) 79 80 #print('line:' +info) 81 if(readStocks==1 and 82 info.startswith('_2')): 83 break 84 if(readStocks==1 and 85 (not info.startswith('_证券代码:')) and 86 info.startswith('_(')): 87 88 tmp = info.split('_') 89 dictTmp = {'code':tmp[2],'name':tmp[3],'偏离值':tmp[4],'成交量':tmp[5],'成交金额(万元)':tmp[6]} 90 stocks.append(dictTmp) 91 92 elif(readStocks==1 and 93 info.startswith('_证券代码:')): 94 95 readStocks = 0 96 readBS = 1 97 #continue 98 99 if(readBS==1 and 100 info.startswith('_证券代码')): 101 tmp = info.split('_') 102 #print('code:'+tmp[2]) 103 nowStock = tmp[2] 104 readBS = 0 105 readBuy = 1 106 continue 107 108 if(readBuy == 1 and 109 info.startswith('_(') and 110 (not info.startswith('_卖出'))): 111 tmp = info.split('_') 112 buy = buy + float(tmp[3]) 113 #print('buy:'+str(buy)) 114 elif(readBuy == 1 and 115 info.startswith('_卖出')): 116 readBuy = 0 117 readSell = 1 118 continue 119 120 if(readSell == 1 and 121 info.startswith('_(') and 122 ((not info.startswith('_2')) or 123 (not info.startswith('_证券')))): 124 tmp = info.split('_') 125 sell = sell + float(tmp[3]) 126 #print('sell:'+str(sell)) 127 elif(readSell == 1 and 128 (info.startswith('_2') or 129 info.startswith('_证券'))): 130 readSell = 0 131 if(info.startswith('_证券')): 132 readBS = 1 133 #dictTmp = {nowStock:{'buy':str(buy),'sell':str(sell)}} 134 BS[nowStock]={'buy':str(buy),'sell':str(sell)}; 135 buy = 0 136 sell = 0 137 138 if(readBS==1 and 139 info.startswith('_证券代码')): 140 tmp = info.split('_') 141 #print('code:'+tmp[2]) 142 nowStock = tmp[2] 143 readBS = 0 144 readBuy = 1 145 continue 146 147 else: 148 #dictTmp = {nowStock:{'buy':str(buy),'sell':str(sell)}} 149 BS[nowStock]={'buy':str(buy),'sell':str(sell)}; 150 #write to doc 151 #print(stocks[0]['成交金额(万元)']) 152 #print(BS) 153 154 writeFile(allfile,stocks,BS,nowDayStr); 155 break; 156 157 else: 158 #深证,中小创 159 160 readStocks = 0 161 #readBS = 0 162 readBuy = 0 163 readSell = 0 164 nowStock = '' 165 stocks = [] 166 BS = dict() 167 buy = 0 168 sell = 0 169 threeBlank = 0 170 for info in infos: 171 172 173 if(info.startswith('--') and readStocks==1 and len(stocks)>1): 174 readStocks=1 175 readSell=0 176 BS[nowStock]={'buy':str(buy),'sell':str(sell)}; 177 buy = 0 178 sell = 0 179 writeFile(allfile,stocks,BS,nowDayStr); 180 break; 181 182 #print('-----'+info) 183 if(threeBlank==3): 184 threeBlank = 0 185 haveBreaked = True 186 else: 187 haveBreaked = False 188 189 info = re.sub('\ +', '_',info) 190 info = re.sub('\n', '',info) 191 192 #print('line:' +info) 193 if(info == ''): 194 threeBlank = threeBlank + 1 195 continue 196 if((not info.startswith('日涨幅偏离值达到7%的前五只证券')) and 197 readStocks==0 and readBuy==0 and readSell==0): 198 continue 199 elif(readStocks==0 and readBuy==0 and readSell==0): 200 201 if(info.endswith('无')): 202 203 break 204 readStocks=1 205 continue 206 207 if(#haveBreaked and 208 readStocks==1 and 209 len(info.split('(代码'))>1): 210 211 if(info.startswith('--')): 212 #print(stocks) 213 #print(BS) 214 writeFile(allfile,stocks,BS,nowDayStr); 215 break; 216 #print('1'+info) 217 code = info.split('(代码')[1].split(')')[0] 218 name = info.split('(代码')[0] 219 plz = info.split('涨幅偏离值:')[1].split('_')[0] 220 cjl = info.split('成交量:')[1].split('_')[0] 221 cje = info.split('成交金额:_')[1]#.split('万元')[0] 222 nowStock = code 223 dictTmp = {'code':code,'name':name,'偏离值':plz,'成交量':cjl,'成交金额(万元)':cje} 224 stocks.append(dictTmp) 225 #print(dictTmp) 226 readStocks = 0 227 readBuy = 1 228 continue 229 230 if(readBuy == 1 and info!='' and 231 (not info.startswith('买入金额最大的前5名')) and 232 (not info.startswith('营业部或交易单元名称')) ): 233 #print('1'+info) 234 if(info.startswith('卖出金额最大的前5名')): 235 readBuy=0 236 readSell=1 237 continue 238 else: 239 buy = buy + float(info.split('_')[1]) - float(info.split('_')[2]) 240 continue 241 242 if(readSell == 1 and info!='' and 243 (not info.startswith('营业部或交易单元名称')) ): 244 #print('2'+info) 245 246 if(info.startswith('--')): 247 readStocks=1 248 readSell=0 249 250 #dictTmp = {nowStock:{'buy':str(buy),'sell':str(sell)}} 251 #print(nowStock) 252 BS[nowStock]={'buy':str(buy),'sell':str(sell)}; 253 254 buy = 0 255 sell = 0 256 #print(stocks) 257 #print(BS) 258 writeFile(allfile,stocks,BS,nowDayStr); 259 break; 260 261 if(len(info.split('代码'))>1): 262 readStocks=1 263 readSell=0 264 265 #dictTmp = {nowStock:{'buy':str(buy),'sell':str(sell)}} 266 #print(nowStock) 267 BS[nowStock]={'buy':str(buy),'sell':str(sell)}; 268 269 buy = 0 270 sell = 0 271 272 #read code 273 #print('2'+info) 274 code = info.split('(代码')[1].split(')')[0] 275 name = info.split('(代码')[0] 276 plz = info.split('涨幅偏离值:')[1].split('_')[0] 277 cjl = info.split('成交量:')[1].split('_')[0] 278 cje = info.split('成交金额:_')[1]#.split('万元')[0] 279 nowStock = code 280 dictTmp = {'code':code,'name':name,'偏离值':plz,'成交量':cjl,'成交金额(万元)':cje} 281 stocks.append(dictTmp) 282 #print(dictTmp) 283 readStocks = 0 284 readBuy = 1 285 continue 286 287 else: 288 sell = sell - float(info.split('_')[1]) + float(info.split('_')[2]) 289 continue 290 291 #break 292 293 294 allfile.close(); 295 print('统计完成!'+'文件:'+'./沪深龙虎榜统计_'+nowStr+'.csv')