先说一下爬取的思路
1,随便打开一首能波的歌播放,找到它的播放地址:
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=42447823290E80FD5318E8A195A169DD&album_id=28687022
多播放几首发现只要hash和album_id不同就能播放不同的歌
所以只要找到所有歌的hash和album_id就行了,OK打开开发者模式点这个文件
找到它的头文件点开哈哈哈就包含了hash和album_id
后来发现拿到也没用不是歌曲播放的真实地址,继续找它的歌曲文件的地址终于发现藏在了这个文件下

把它头文件打开就是歌曲的文件的播放地址且发现在最后面有歌曲的真实播放地址play_backup_url,所以只要改变hash和album_id不就所有歌曲的文件都有了吗
所以总结下来就是:
1,打开播放一首歌的开发者模式找到所有歌曲的album_id和hash
2,同样在此开发者模式中找到歌曲的真实播放地址
3,改变不同的hash和album_id就能得到所有歌曲的真实播放地址
思路缕清开始撸代码
1,先模拟浏览器环境,使得能够打开网页得到数据(hash和album_id)
public static String httpGetCallbackData(String url, List<NameValuePair> params) {//1.获取连接客户端工具BasicHttpClientConnectionManager connManager = new BasicHttpClientConnectionManager();CloseableHttpClient httpclient = HttpClients.custom().setConnectionManager(connManager).build();//网址返回的json数据。创建一个空的引用。String entityStr = null;//请求 response:响应CloseableHttpResponse response = null;try {URIBuilder uriBuilder = new URIBuilder(url);uriBuilder.setParameters(params);//创建GET请求对象HttpGet httpGet = new HttpGet(uriBuilder.build());RequestConfig requestConfig = RequestConfig.custom().setSocketTimeout(5000).setConnectTimeout(50000).setConnectionRequestTimeout(50000).build();httpGet.setConfig(requestConfig);//添加请求头信息httpGet.setHeader("content-type", "application/x-www-form-urlencoded; charset=UTF-8");httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36");//执行请求response = httpclient.execute(httpGet);HttpEntity entity = response.getEntity();//.使用Apache提供的工具类进行转换成字符串entityStr = EntityUtils.toString(entity, "UTF-8");} catch (ClientProtocolException e) {System.err.println("Http协议出现问题");e.printStackTrace();} catch (ParseException e) {System.err.println("解析错误");e.printStackTrace();} catch (URISyntaxException e) {System.err.println("URI解析异常");e.printStackTrace();} catch (IOException e) {System.err.println("IO异常");e.printStackTrace();} finally {// 释放连接if (null != response) {try {response.close();httpclient.close();} catch (IOException e) {System.err.println("释放连接出错:"+e.getMessage());}}}return entityStr;}
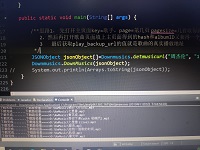
这里返回的是字符串,要把它转化为json数据得到album_id和hash
2,通过album_id和hash打开index中头文件的地址得到歌曲真实播放地址play_backup_url
//打开存放歌曲播放地址的页面List<NameValuePair> params2 = new ArrayList<NameValuePair>();params2.add(new BasicNameValuePair("r", "play/getdata"));params2.add(new BasicNameValuePair("hash", filehash));params2.add(new BasicNameValuePair("album_id", String.valueOf(albumid)));String result2= Downmusic.httpGetCallbackData("https://wwwapi.kugou.com/yy/index.php", params2);JSONObject jsonObjectmusci=JSONObject.parseObject(result2);JSONObject jsonObjectmuscidata=jsonObjectmusci.getJSONObject("data");String musicUrl=jsonObjectmuscidata.getString("play_backup_url");3,得到歌曲的真实播放地址后就可以用流把它下载到磁盘中了
try {URL url = new URL(musicUrl);URLConnection urlconn = url.openConnection();InputStream inputStream = urlconn.getInputStream();int len = 0;byte[] b = new byte[1024*4];OutputStream out = new FileOutputStream("G:\\xxx\\"+songname+".mp3");while ((len = inputStream.read(b)) != -1) {out.write(b, 0, len);}out.close();inputStream.close();System.out.println("下载完成........下载路径是====>"+"G:\\xxx\\"+songname+".mp3");} catch (IOException e) {e.printStackTrace();}
以上就是爬一音乐的所有代码,要爬所有的歌写个循环就轻松搞定
注意:
1.打开图片中的头文件看它的参数有page和pagesize这是页数和该页数中有几首歌,默认是1,30,刚开始得先从爬一首开始所以要把pagesize改为1.
2,再爬的过程中入的大坑,在获取play_backup_url时程序能正常运行,但是返回的结果却是错误的,苦恼我好久终于在网上找到解决方法,就是在模拟浏览器环境时请求头信息是带上Cookie参数且它的参数不为空就行,我也不知道为啥要这样。
3,一段完整的网址放在URL是打不开的需要把后面的人工拼接
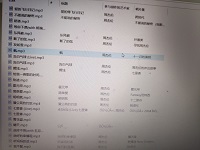
效果图: