目录
1. 概述
2. 原理
2.1 概述
2.2 分片存储机制
2.3 Epoch Week机制
2.4 时空索引机制
2.5 Fid机制
2.6 多个数据的封装
3. 代码实现
3.1 获取分片
3.2 获取Epoch Week
3.3 获取时空索引
3.4 获取Fid
3.5 多个数据的封装
1. 概述
在大量的场景当中,我们不仅仅需要进行时间的查询、空间的查询,也需要对时间和空间的组合进行查询。在以往的机制当中,往往使用的是多级过滤或者多级索引的机制,这样的话很多时候无法对数据进行精确定位,会产生一些冗余的过程。Z3索引就是为了解决这个问题而产生的。
在Z3索引当中,我们将时间和空间的数据进行类似GeoHash算法的分片和穿插,最后形成一个能够承担索引任务的数据,最后将这个数据进行一系列的封装,以适应具体的业务场景。
2. 原理
2.1 概述
在Z3索引当中,为了解决将时间空间数据进行综合索引的功能,其内部可以分为如下几个机制:
- 分片存储机制
- Epoch Week机制
- 时空索引机制
- Fid机制
- 多个数据的封装
2.2 分片存储机制
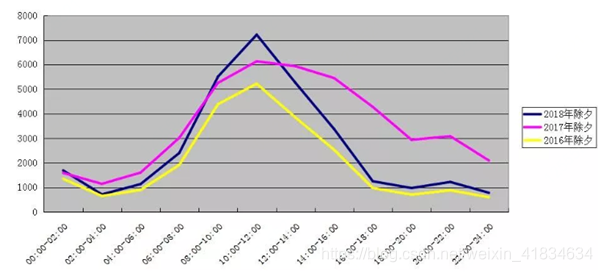
由于我们存储的数据主要针对的是时间数据和空间数据。对时间数据来说,每天的数据量随着时间的分布是不均匀的。例如:在2016年、2017年、2018年三年的大年初一的沪昆高速上车流量的统计图中,可以看出,在不同时段、不同年份的车流量数据都是分布不均的,这样也会导致这些车辆产生的数据量会有所不同。这样如果直接将数据存入,很可能会在Hbase里面产生数据倾斜的问题。
为了解决这个问题,geomesa当中会在key值的第一个字节存储一个shard值,这个值主要是通过分片的方式,将这些数据随机分配到不同的shard当中,这样就可以尽量避免数据倾斜的问题。
2.3 Epoch Week机制
在前文当中已经描述了关于空间方面的geohash算法。而对于时间数据来说,这样就很难直接通过二分的方式来进行划分和编码了。因为大地坐标系当中,经纬度是有明确的范围的,经度的范围就是从东经180°到西经180°,维度的范围就是从南纬90°到北纬90°。
但是对于时间来说,这个量度是无限的,因此为了给时间的编码提供一种相对明确的范围,geomesa当中采用了Epoch机制。这种机制就是以1970年1月1日0点的时间作为起点,将feature当中的时间与这个起点的距离包含多少个星期作为Epoch Week。在每一个week内部,可以进行类似于geohash算法当中的二分法,最终形成一个可以标定时间的唯一数据 。
2.4 时空索引机制
在Z2索引以及geohash算法当中,可以看出,我们利用到了一种四叉树的索引结构,首先将限定范围的空间进行横向和纵向的二分,当分出来的每一个小区域满足精度需求的时候,就可以利用空间填充曲线将这些小区域进行串联,最终实现二维空间向一维数据的降维。
在Z3索引当中,同样通过类似的方法,但是前提是在经过上一步中对于Epoch week的限定,这样就可以确定时间数据的范围。而在下一步的操作中,同样是对经度、维度、时间数据进行规范化,然后在二进制当中进行穿插,最终形成的数据就是我们需要的时空索引。
这种索引方式利用的是八叉树的结构,同样也能够实现数据的唯一对应,但是也存在geohash算法当中的突变问题。另一方面,geomesa采用的依然是Z-order填充曲线,因此这个矛盾就会显得尤为突出了。


上述的这些索引过程可以分为一下几个步骤:
- 首先对于经度、维度、时间数据进行规范化的操作,将这些数据进行类型的统一。
- 在类型统一过后,将三个结果值当中没两位之间插入两个0,这样就会将这些数值的位数扩充为原来的3倍,而插入的0就是其他维度数据插入的位置。
- 将扩充位数之后的数据进行适当移位,然后做位运算,得出一个整合了多个数据的数值
- 将这个数值按照一定的位数规则,转化为字节数组,以便于进一步转化为索引字符串。
2.5 Fid机制
在具体数据的设定当中,每一行feature在插入时都需要一个id作为标识符,这个标识符可以是用户设定好的,如果用户没有进行设定,geomesa底层会给这个feature随机生成一个uuid值作为标识feature的id。
2.6 多个数据的封装
最终的封装过程比较简单,首先为了最大程度的实现rowkey在hbase当中的散列,geomesa将shard值放在了rowkey的开头,最大程度避免数据倾斜的问题。
接下来是Epoch Week,这个值相对于时空数据来说,变化是相对均匀的,可以实现rowkey排列的时序性相对较强。但是这样也会导致一个现象,当利用geomesa进行取数据的时候,从同一个week里的数据相对来说查询速度较快,而不同week里的数据查询速度相对较慢。
接下来是时空索引和Fid,这部分的数据是最可能出现数据倾斜的部分,将这些数据放在最后也是为了尽可能避免这个问题的发生。
3. 代码实现
建立索引的过程其实都是整合在写流程当中的,整体的写流程见源码篇(写流程)。这一节主要选取跟建立索引相关的部分进行介绍。建立索引的方法入口在org.locationtech.geomesa.index.index.BaseFeatureIndex特性当中的writer方法当中。
override def writer(sft: SimpleFeatureType, ds: DS): F => Seq[W] = { val sharing = sft.getTableSharingBytes val shards = shardStrategy(sft) val toIndexKey = keySpace.toIndexKeyBytes(sft) mutator(sharing, shards, toIndexKey, createInsert)
}
第二行当中的sharing跟table sharing机制有关。第三行中的shards参数就是选取的分片位置,第四行当中的toIndexKey主要是对于时空索引的数据,第五行当中的mutator方法包含了对分片信息、时空索引、每一行的value等数据的封装。
3.1 获取分片
在writer方法当中的sharing机制是跟accumulo本身的机制密切相关的,hbase没有类似的机制,因此如果使用Hbase DataStore,这个参数返回一个空的byte数组。
val sharing = sft.getTableSharingBytes 具体调用的方法如下:
def getTableSharingBytes: Array[Byte] = if (sft.isTableSharing) { sft.getTableSharingPrefix.getBytes(StandardCharsets.UTF_8) } else { Array.empty[Byte]
}
在writer方法当中的的shards参数表示的是选取的分片标号。
val shards = shardStrategy(sft) 之后的方法调用会根据索引类型的不同调用相应的方法。在此处,针对Z3索引机制,geomesa调用的是org.locationtech.geomesa.index.index.z3.Z3Index中的shardStrategy方法,在这里封装了一个SimpleFeatureType对象,返回一个ShardStrategy,也就是封装了分片策略的对象。
override protected def shardStrategy(sft: SimpleFeatureType): ShardStrategy = ZShardStrategy(sft) 接下来调用ZshardStrategy的apply方法,获取具体的shard值:
object ZShardStrategy { def apply(sft: SimpleFeatureType): ShardStrategy = ShardStrategy(sft.getZShards)
}
Z_SPLITS_KEY里面封装了切片的相关属性,例如在示例当中,这个值其实是“geomesa.z.splits”字符串,最后的4指的是切片的总数。用户可以通过调节这里的参数,可以根据自己的业务场景从Java API当中直接进行设置,也可以在源码级别进行修改。
def getZShards: Int = userData[String](Z_SPLITS_KEY).map(_.toInt).getOrElse(4) 之后回到shardStrategy方法以后会调用org.locationtech.geomesa.index.index.ShardStrategy伴生对象当中的apply方法,在这个方法当中,会传入前面设定的分片数量。此时底层会对这个分片数量进行一个判断,如果分片数少于2,这个方法就会返回一个空的Array,也就是会使这个分片机制失效,如果count大于等于2,geomesa才会执行接下来的分配分片的操作。
def apply(count: Int): ShardStrategy = { if (count < 2) { NoShardStrategy } else { var strategy = instances.get(count) if (strategy == null) { strategy = new ShardStrategyImpl(SplitArrays(count)) instances.put(count, strategy) } strategy }
}
在程序执行到第5行时,程序会进一步进入org.locationtech.geomesa.index.utils.SplitArrays类的伴生对象,调用其apply方法,进行进一步的切片操作。在这个方法中有多个参数,其中splitArraysMap参数本质上是一个concurrentHashMap,因此这个操作也是具有一定的并发能力的。
def apply(numSplits: Int): IndexedSeq[Array[Byte]] = { if (numSplits < 2) { EmptySplits } else { var splits = splitArraysMap.get(numSplits) if (splits == null) { splits = (0 until numSplits).map(_.toByte).toArray.map(Array(_)).toIndexedSeq splitArraysMap.put(numSplits, splits) } splits }
}
最终返回给writer方法的其实是一个Array[byte],里面对于分片机制进行了预处理。
3.2 获取Epoch Week
在前述的writer方法当中,进一步执行到toIndexKey参数。
val toIndexKey = keySpace.toIndexKeyBytes(sft) 在这里调用到了org.locationtech.geomesa.index.index.z3.Z3IndexKeySpace类的伴生对象当中的toIndexKeyBytes方法。在这个方法当中,封装了很多信息。第2到第4行只是在获取Epoch Week之前的数据预处理过程,其中z3参数封装了空间填充曲线的相关信息,geomIndex参数表示了地理元素的索引元数据,dtgIndex参数表示了时间元素的索引元数据,真正获取Epoch Week的是timeToIndex参数。最后由getZValueBytes方法将上述这些参数进行封装。
override def toIndexKeyBytes(sft: SimpleFeatureType, lenient: Boolean): ToIndexKeyBytes = { val z3 = sfc(sft.getZ3Interval) val geomIndex = sft.indexOf(sft.getGeometryDescriptor.getLocalName) val dtgIndex = sft.getDtgIndex.getOrElse(throw new IllegalStateException("Z3 index requires a valid date")) val timeToIndex = BinnedTime.timeToBinnedTime(sft.getZ3Interval) getZValueBytes(z3, geomIndex, dtgIndex, timeToIndex, lenient) }
首先关于Z3参数,内部首先调用了org.locationtech.geomesa.utils.geotools.Conversions类当中的getZ3Interval方法,这里会对时间分割的单位进行设置,默认情况下是使用“week”作为时间分割的基本单位,不过为了适应更多的应用场景,用户在具体使用时也可以选择“day”、“month”、“year”作为时间分割的基本单位。和之前的“geomesa.z.splits”相类似,用户也可以在Java API当中设定“geomesa.z3.initerval”来对这个参数进行定义。
def getZ3Interval: TimePeriod = userData[String](Z3_INTERVAL_KEY) match { case None => TimePeriod.Week case Some(i) => TimePeriod.withName(i.toLowerCase) }
最后利用空间填充曲线的类对于这个时间间隔数据进行匹配和封装,在此处其实本质上调用的是Z3SFC类,最后返回的是一个Z3SFC对象,里面包含了经度、纬度、时间以及whole Period四个对象,其中经度(NomarlizedLon)、纬度(NormalizedLat)、时间(NormalizedTime)三个参数都各自封装了如下数据。
| 参数 | 含义 |
|---|---|
| Precicion | 精确度(默认是21) |
| Min | 最小值 |
| Max | 最大值 |
| Bins | 二进制的值(默认是2097152,即21位二进制数的最大值) |
| Normalizer | 规范化器(由Double转为Int) |
| Denormalizer | 反规范化器(由Int转为Double) |
| MaxIndex | 索引的最大值(默认是2097152,即21位二进制数的最大值) |
接下来的geomIndex参数主要是获取了一些地理空间参考相关的信息。
val geomIndex = sft.indexOf(sft.getGeometryDescriptor.getLocalName)这个参数的数据来源于org.geotools.feature.type.FeatureTypeImpl类的getGeometryDescriptor方法,这个方法就封装了地理学相关的信息。
public GeometryDescriptor getGeometryDescriptor() { if (defaultGeometry == null) { for (PropertyDescriptor property : getDescriptors()) { if (property instanceof GeometryDescriptor) { defaultGeometry = (GeometryDescriptor) property; break; } } } return defaultGeometry; }
例如示例demo当中,这个参数就封装了一个CRS变量,这个变量跟一些地理学方面的知识有关,在此不再详述,这个变量内部的内容如下:
GEOGCS["WGS 84", DATUM["World Geodetic System 1984", SPHEROID["WGS 84", 6378137.0, 298.257223563, AUTHORITY["EPSG","7030"]], AUTHORITY["EPSG","6326"]], PRIMEM["Greenwich", 0.0, AUTHORITY["EPSG","8901"]], UNIT["degree", 0.017453292519943295], AXIS["Geodetic longitude", EAST], AXIS["Geodetic latitude", NORTH], AUTHORITY["EPSG","4326"]]
而最终返回到geomIndex参数的数值则是将上述数据进行索引之后的一个数值。
接下来对于时间信息相关的dtgIndex,则调用了Conversions类当中的getDtgFeild方法。在这里,geomesa会对之前用户设定的默认日期值进行获取,最终获得一个类似于geomIndex的与时间相关的数值,返回给dtgIndex参数。
def getDtgField: Option[String] = userData[String](DEFAULT_DATE_KEY)
def getDtgIndex: Option[Int] = getDtgField.map(sft.indexOf).filter(_ != -1)
执行到timeToIndex参数,在此获取了设定的时间的分段间隔(Interval)。
val timeToIndex = BinnedTime.timeToBinnedTime(sft.getZ3Interval) 由于时间需要转换为Int类型,因此需要设定一个最小的时间单位。根据不同的分段间隔,geomesa选取了不同的时间单位。例如,如果大的分段间隔选取为Week,那么相对应的时间单位就是秒。具体的实现方法就是BinnedTime类当中的timeToBinnedTime方法内。
def timeToBinnedTime(period: TimePeriod): TimeToBinnedTime = { period match { case TimePeriod.Day => toDayAndMillis case TimePeriod.Week => toWeekAndSeconds case TimePeriod.Month => toMonthAndSeconds case TimePeriod.Year => toYearAndMinutes } }
最终封装这些参数的是getZValueBytes方法,这个方法最终会将这些参数转换为byte数组,执行下一步的操作。
getZValueBytes(z3, geomIndex, dtgIndex, timeToIndex, lenient) 3.3 获取时空索引
上述的getZValueBytes方法内容如下,内部的操作比较多,主要包含两个部分:参数准备(第9行到第20行)、封装数据(第22行到29行),最后将各种数据封装成为一个byte数组,返回给系统作为rowkey,进行下一步与数据库的交互。
private def getZValueBytes(z3: Z3SFC, geomIndex: Int, dtgIndex: Int, timeToIndex: TimeToBinnedTime, lenient: Boolean) (prefix: Seq[Array[Byte]], feature: SimpleFeature, suffix: Array[Byte]): Seq[Array[Byte]] = { val geom = feature.getAttribute(geomIndex).asInstanceOf[Point] if (geom == null) { throw new IllegalArgumentException(s"Null geometry in feature ${feature.getID}") } val dtg = feature.getAttribute(dtgIndex).asInstanceOf[Date] val time = if (dtg == null) { 0 } else { dtg.getTime } val BinnedTime(b, t) = timeToIndex(time) // 创建Z填充曲线val z = try { z3.index(geom.getX, geom.getY, t, lenient).z } catch { case NonFatal(e) => throw new IllegalArgumentException(s"Invalid z value from geometry/time: $geom,$dtg", e) } // 创建一个byte数组,将所有的信息都封装起来 val bytes = Array.ofDim[Byte](prefix.map(_.length).sum + 10 + suffix.length) var i = 0 prefix.foreach { p => System.arraycopy(p, 0, bytes, i, p.length); i += p.length } ByteArrays.writeShort(b, bytes, i) ByteArrays.writeLong(z, bytes, i + 2) System.arraycopy(suffix, 0, bytes, i + 10, suffix.length) Seq(bytes) } 这一节我们重点介绍时空索引的生成机制,在这个方法里,对应的是第17行到19行代码。参数z就是我们最终需要的封装了时空数据的时空索引。而产生这个索引需要穿入三个参数,即经度(Double)、维度(Double)、时间(Long)的数据,调用org.locationtech.geomesa.curve.Z3SFC类当中的index方法,方法内容如下:
override def index(x: Double, y: Double, t: Long, lenient: Boolean = false): Z3 = { try { require(x >= lon.min && x <= lon.max && y >= lat.min && y <= lat.max && t >= time.min && t <= time.max, s"Value(s) out of bounds ([${lon.min},${lon.max}], [${lat.min},${lat.max}], [${time.min},${time.max}]): $x, $y, $t") Z3(lon.normalize(x), lat.normalize(y), time.normalize(t)) } catch { case _: IllegalArgumentException if lenient => lenientIndex(x, y, t) } } 其中最重要的是第五行,创建了Z3对象,并将经纬度、时间的数据经过规范化操作后的数据进行封装,返回给getZValueBytes方法。
此处的规范化操作主要是通过org.locationtech.geomesa.curve.NormalizedDimension.BitNormalizedDimension类当中的normalize方法实现的,主要的目的是将经度、维度、时间都进行二分操作转换成为Int类型的数据,以利于下一步的整合操作。
override def normalize(x: Double): Int = if (x >= max) { maxIndex } else { math.floor((x - min) * normalizer).toInt }
在Z3对象传入参数之后,接着就会调用其apply方法。在这个方法内部,系统对于这三个数据进行了第二次的封装。
def apply(x: Int, y: Int, z: Int): Z3 = { new Z3(split(x) | split(y) << 1 | split(z) << 2) }
在这个过程当中,每一个数据又经过了split方法的处理,其源码如下,实现的功能是在原本数据的二进制每一位的后面添加两个0,将原来数据的二进制位数扩大为原来的三倍。
例如,15的二进制形式是1111,经过这个方法处理以后,这个数据就会变成100100100100
override def split(value: Long): Long = { var x = value & MaxMask x = (x | x << 32) & 0x1f00000000ffffL x = (x | x << 16) & 0x1f0000ff0000ffL x = (x | x << 8) & 0x100f00f00f00f00fL x = (x | x << 4) & 0x10c30c30c30c30c3L (x | x << 2) & 0x1249249249249249L } 经过处理以后的三个数据在apply方法当中经过移位以及位运算,最终整合成为一个64位的数据,其中就将经度、纬度、时间的数据整合成为一个时空索引了,其每一位的数据可以看做“tyxtyx…”
但是这个时空索引是空间优先的,虽然在apply当中,时间对应的数据左移了两位,维度对应的数据左移了一位,在逻辑上时间对应的应该是第一位的。但是实际上在实际操作当中,时间所形成的数据长度会比经纬度形成的数据长度少一位,在第一位,时间往往填不满。因此这个索引依然是空间优先的,基于时间的检索和查询性能可能会受到一些影响。
3.4 获取Fid
获取Fid的方法与写流程当中的过程比较类似。同样是调用从UserData当中取出Hints.PROVIDED_FID,如果用户没有设定id,就会随机生成一个uuid作为存储时用到的id。
override def createId(sft: SimpleFeatureType, sf: SimpleFeature): String = { if (sft.getGeometryDescriptor == null) { // no geometry in this feature type - just use a random UUID UUID.randomUUID().toString } else { Z3UuidGenerator.createUuid(sft, sf).toString } } 除此以外,为了使其能够整合进rowKey当中,还需要对这个id值进行序列化的操作。这个操作是在wrapper当中实现的,在第3行的代码当中。
def wrapper(sft: SimpleFeatureType): (SimpleFeature) => HBaseFeature = { val serializers = HBaseColumnGroups.serializers(sft) val idSerializer = GeoMesaFeatureIndex.idToBytes(sft) (feature) => new HBaseFeature(feature, serializers, idSerializer) } 进入idToBytes方法内部,可以看出geomesa此时还会对id进行一个判断。根据进一步的追踪可以知道,如果是此处的id是uuid,会使用其本身的序列化机制;如果此处的id不是uuid,那么它的序列化是按照UTF-8的编码规则来操作的,在此不再赘述了。
def idToBytes(sft: SimpleFeatureType): String => Array[Byte] = if (sft.isUuidEncoded) { uuidToBytes } else { stringToBytes }
3.5 多个数据的封装
接下来继续分析getZValueBytes方法,在这个方法的最后几行当中,geomesa创建了一个byte数组,从第11行可以看出这个byte数组的容量是根据传入的参数来确定的,因此这个数组的容量也是不确定的。
private def getZValueBytes(z3: Z3SFC, geomIndex: Int, dtgIndex: Int, timeToIndex: TimeToBinnedTime, lenient: Boolean) (prefix: Seq[Array[Byte]], feature: SimpleFeature, suffix: Array[Byte]): Seq[Array[Byte]] = { … // 创建一个byte数组,将所有的信息都封装起来 val bytes = Array.ofDim[Byte](prefix.map(_.length).sum + 10 + suffix.length) var i = 0 prefix.foreach { p => System.arraycopy(p, 0, bytes, i, p.length); i += p.length } ByteArrays.writeShort(b, bytes, i) ByteArrays.writeLong(z, bytes, i + 2) System.arraycopy(suffix, 0, bytes, i + 10, suffix.length) Seq(bytes) } 决定这个容量的参数主要有两个,其中prefix里面封装了数据分配到的分片标号,因为geomesa对于分片数量的默认设置是4,因此这个数据占用的位数是相对比较确定的,而suffix里面则封装了FeatureId的序列化结果,这个序列化方式利用的是UTF-8编码形式,但是这个参数的容量是会有变化的,因此用户在设计的时候需要注意FeatureId的长度,以免超出数据库对于key值长度的要求。
剩下的那个10个位置主要包含了两方面的内容,其中2个位置是分配给Epoch Week的,主要记录了该条记录与1970年历元时间的间隔里面包含了多少周。这个数据本来是Short类型,在第14行,geomesa将这个数据转换成了两个byte类型的数据。在这里调用了org.locationtech.geomesa.utils.index.ByteArrays类当中的writeShort方法,具体实现如下:
def writeShort(short: Short, bytes: Array[Byte], offset: Int = 0): Unit = { bytes(offset) = (short >> 8).asInstanceOf[Byte] bytes(offset + 1) = short.asInstanceOf[Byte] }
在这里我们可以看到一个现象,在这个过程当中,geomesa仅仅是将short类型数据进行了八位和八位的切分,直接按照顺序转换成了byte类型的数据。例如,在提供的案例demo中,这里的short值其实是1987,转换为二进制就是0000 0111 1100 0011,如果直接利用geomesa的机制来转换就得到了0000 0111和1100 0011,转换为两个byte就是7和-61。这样的话虽然保留了原有数据的顺序,但是没有很好地起到散列的作用,因为前8位因为位数比较高,而后8位明显会出现更大的随机性,如果将这两个byte数据交换顺序,这样的话,就能够实现数据的散列,更容易避免数据倾斜的问题。
其实类似的做法在HashMap的源码当中也可以看到,在HashMap底层,它会对传入的key值进行哈西操作,这样是为了让这个key值更加离散,防止过多的数据存入到一个entry当中。为了提升这种离散的效果,HashMap会对key值进行二次Hash,在这个过程当中,除了进行hash算法的操作,它还会将key的二进制数据的前半部分和后半部分进行交换,因为后半部分会有更大的随机性。这样的话就能够实现数据的离散化。
剩下8位的数据则是时空索引的位置。根据前文所述,时空索引的数据长度总共有64位,而一个字节总共有8位,因此如果转化为byte数组,就需要占用8个位置。具体实现在BytesArray类当中的writeLong方法中,可以看出,这个方法就是将时空索引通过位运算转化为byte类型的数据,然后再将这些数据存放进之前创建的byte数组当中。
def writeLong(long: Long, bytes: Array[Byte], offset: Int = 0): Unit = { bytes(offset ) = ((long >> 56) & 0xff).asInstanceOf[Byte] bytes(offset + 1) = ((long >> 48) & 0xff).asInstanceOf[Byte] bytes(offset + 2) = ((long >> 40) & 0xff).asInstanceOf[Byte] bytes(offset + 3) = ((long >> 32) & 0xff).asInstanceOf[Byte] bytes(offset + 4) = ((long >> 24) & 0xff).asInstanceOf[Byte] bytes(offset + 5) = ((long >> 16) & 0xff).asInstanceOf[Byte] bytes(offset + 6) = ((long >> 8) & 0xff).asInstanceOf[Byte] bytes(offset + 7) = (long & 0xff).asInstanceOf[Byte] } 最终经过getZValueBytes方法以后,相关的数据就都封装进这个byte数组当中了,接下来geomesa就会依次为Key来创建跟数据库交互的请求,例如在于Hbase的交互当中,这个byte数组会作为rowKey封装进一个Put对象当中,最终将相关的数据存储进Hbase当中。而在Hbase当中显示出来的rowKey是一个长字符串,这个过程是通过org.apache.hadoop.hbase.util.Bytes类当中的toStringBinary方法。具体的测试代码如下:
public static void main(String[] args) { byte[] source = {2, 7, -61, 58, -66, -122, 113, -2, -27, 3, -114, -23, -69, -111, 65, 32, 83, 65, 50, 51, 52, 50}; String a = Bytes.toStringBinary(source); System.out.println(a); } 测试结果如下,这个就是我们真正在Hbase当中看到的rowKey:
\x02\x07\xC3:\xBE\x86q\xFE\xE5\x03\x8E\xE9\xBB\x91A SA2342
Process finished with exit code 0












![[Excel函数] 计算统计类函数](https://img-blog.csdnimg.cn/344cc052283b493fb5825ecf9bc2dbc1.png)