目录
- 1 介绍
- 2 工具箱导入
- 3 导入数据 数据分析
- 4 拆分标签和特征
- 5 ocean_proximity特征编码
- 6 划分训练集-测试集
- 7 模型训练和验证
1 介绍
我们使用California Housing Prices数据集进行预测,数据集地址:https://download.csdn.net/download/ww596520206/87506282
2 工具箱导入
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
from sklearn.metrics import mean_squared_error,r2_score
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
np.random.seed(123)
3 导入数据 数据分析
data = pd.read_csv("housing.csv")
print(data.describe())
print(data.shape)
print(data.info())
data.dropna(inplace= True) #剔除空值
data.hist(bins=60, figsize=(15,9))
plt.show()
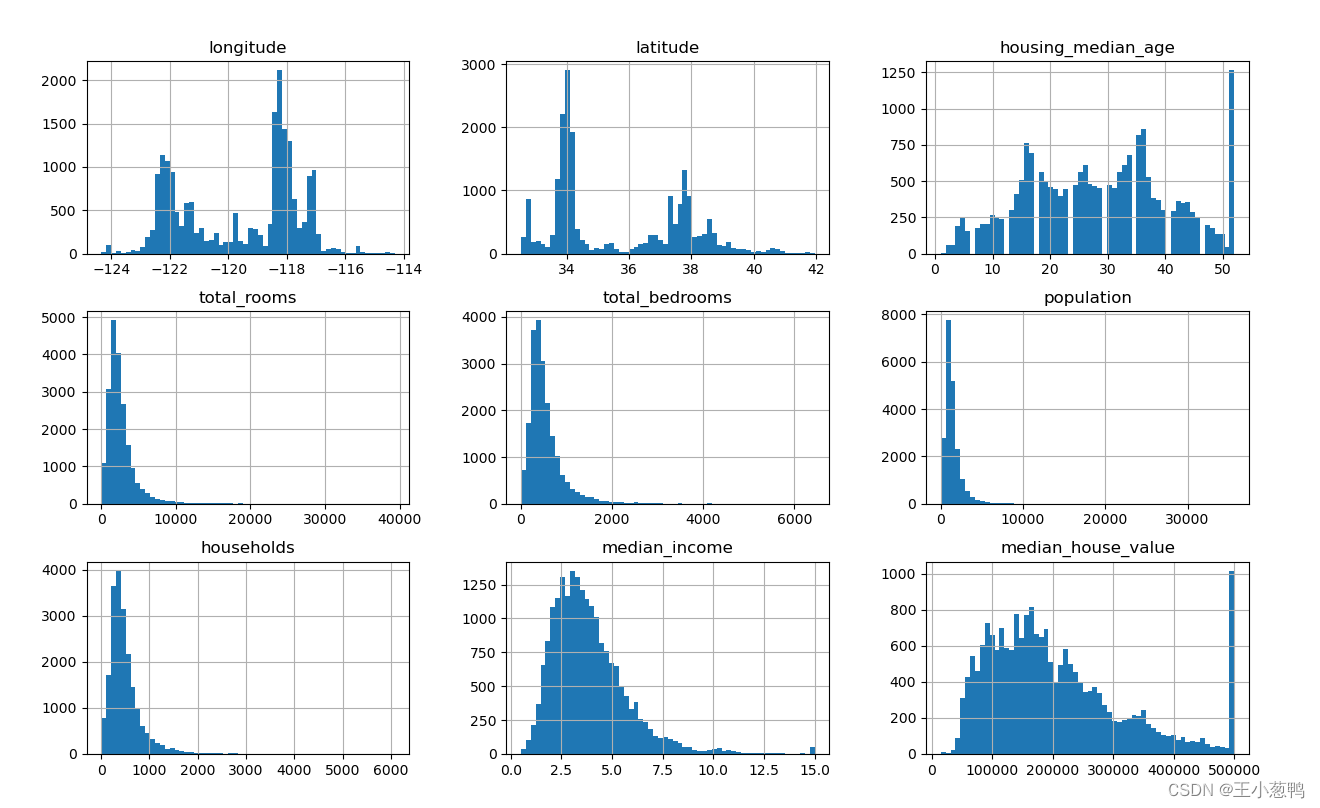
4 拆分标签和特征
x = data.drop(["median_house_value"],axis=1)
y = data["median_house_value"]
5 ocean_proximity特征编码
from category_encoders import MEstimateEncoder
encoder = MEstimateEncoder(cols=['ocean_proximity'],m=0.5)
encoder.fit(x,y)
x= encoder.transform(x)
6 划分训练集-测试集
X_train, X_test, y_train, y_test = train_test_split(x, y,train_size=0.7,shuffle = True,random_state=123)
7 模型训练和验证
from sklearn.linear_model import LinearRegression
rf = LinearRegression()
rf.fit(X_train, y_train)
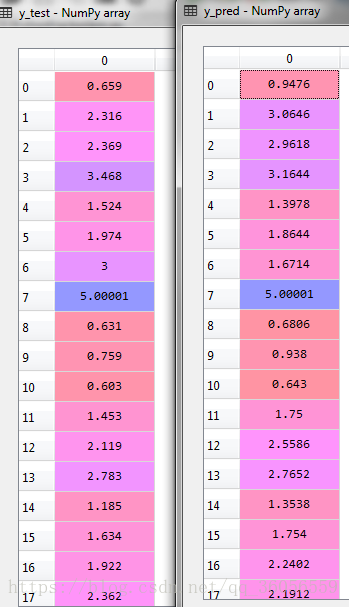
y_pred = rf.predict(X_test)
print("mse:{}".format(mean_squared_error(y_test, y_pred)))
print("r2-score:{}".format(r2_score(y_test, y_pred)))from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
print("mse:{}".format(mean_squared_error(y_test, y_pred)))
print("r2-score:{}".format(r2_score(y_test, y_pred)))
mse:4628881884.279629
r2-score:0.6444582617950347
mse:2428501108.0044303
r2-score:0.8134682355786766