
一、过滤法(Filter)
特点:过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法
过程:
目标对象:需要遍历特征或升维的算法。最近邻算法KNN,支持向量机SVM,决策树,神经网络,回归算法等遍历特征或升维运算,本身的运算量很大,需要的时间很长,因此特征选择很重要。随机森林不需要遍历特征,每次选的特征就很随机,并非用到所有的特征,所以特征选择作用不大。
思考:过滤法对随机森林无效,却对树模型有效?
解释:传统决策树需遍历所有特征,计算不纯度后分枝,而随机森林却是随机选择特征进行计算和分枝,因此随机森林的运算更快,过滤法对随机森林无用,对决策树有用。
二、嵌入法(Embedded)
特点:结合后续分类(或者回归)模型,根据评估结果进行选择每次遍历所有的特征(包括选择和未选择的)
过程:类似于Filter,只不过系数是通过训练得来的。嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。设置的阈值threshold决定最后选择出的特征的个数,阈值threshold是个超参数,选取比较不易控。
注意:后续的评估器必须可以得到相关特征的权值系数,比如随机森林和树模型中的feature_importances,逻辑回归的l1和l2惩罚项,线性支持向量机的l2惩罚项等。
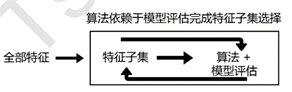
说明:此处的算法为分类(或者回归)的算法,如SVM,逻辑回归等。
三、包装法(Wrapper)
特点:结合后续分类(或者回归)模型,根据评估结果进行选择 每次遍历剩余所有未选择的特征
过程:特征选择和算法训练同时进行的方法,依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择。对于每一个待选的特征子集,都在训练集上训练一遍模型,然后在测试集上根据误差大小选择出特征子集。前提是要选好后续要用的分类(或者回归)算法,如Random Forest,SVM,kNN等等。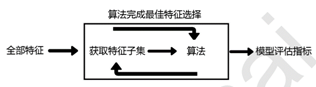
包装法与嵌入法的区别:包装法根据预测效果评分来选择,而嵌入法根据预测后的特征权重值系数来选择。
————————————————
版权声明:本文为CSDN博主「一弦-sring」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42846157/article/details/106749951



















