我们上次已经把公式给推导了出来。还举了例子,不懂的理论的点击这里,老师的代码
这回我们将要用Java进行初步实现,这个代码是我参考老师的,里面附带了详细的注解。要成功运行需要一些包,需要的可以联系我。
public static void main(String[] args) {int[] tempLayerNodes = { 4, 8, 8, 3 };SimpleAnn tempNetwork = new SimpleAnn("D:/data/iris.arff", tempLayerNodes, 0.01,0.6);for (int round = 0; round < 5000; round++) {tempNetwork.train();} // Of for ndouble tempAccuracy = tempNetwork.test();System.out.println("The accuracy is: " + tempAccuracy);}// Of main
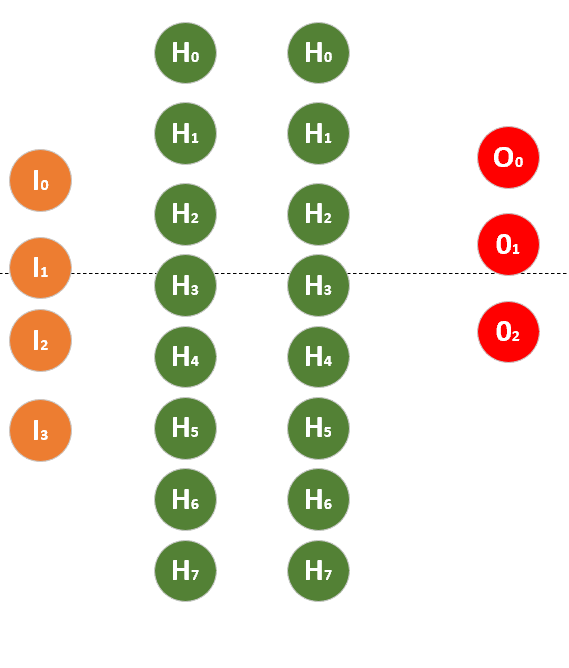
我们来看主函数,开始就是层次数组。共三层,4,8,8,3 的意思是输入层4个神经元,两个隐层各8个神经元,输出层3个神经元。用权重的线连接起来,由于节点多连起来不好看,就自己脑补了哈。
 接下来就是读入数据,然后一个for循环对数据进行训练,这里我们用的BP算法。后面两句就是把预测精度打印出来。
接下来就是读入数据,然后一个for循环对数据进行训练,这里我们用的BP算法。后面两句就是把预测精度打印出来。
这里我们用了两个类,一个抽象的父类GeneralAnn和具体实现的子类SimpleAnn.两部分的代码在这里,子类涉及BP算法的核心代码,注释我已经给好了。但是一定要要对公式熟悉,不行的话就看着公式慢慢对下去。硬骨头很难啃下去。
package machinelearning.ann;import java.io.FileReader;
import java.security.PublicKey;
import java.util.Arrays;
import java.util.Random;import weka.core.Instances;
import weka.datagenerators.Test;public abstract class GeneralAnn {/*** 整个数据集*/Instances dataset;/*** 层数,根据结点计算*/int numLayers;/*** 每层的节点数, e.g., [3, 4, 6, 2] 意思是*三个输出层结点 (也是条件判断的属性), 两个隐层分别有4和6个结点* , 两个类别属性 (就是二元分类,只有是与非).*/int[] layerNumNodes;/*** 动量系数。*/public double mobp;/*** 学习率*/public double learningRate;/*** 用于生成随机数*/Random random = new Random();/*********************** 第一个构造函数* * @param paraFilename* arff 类型的文件* @param paraLayerNumNodes* 每层结点的数目(可能不相同)* @param paraLearningRate* 学习率* @param paraMobp* 动量系数*********************/public GeneralAnn(String paraFilename, int[] paraLayerNumNodes, double paraLearningRate,double paraMobp) {// Step 1. 读数据try {FileReader tempReader = new FileReader(paraFilename);dataset = new Instances(tempReader);// 最后一个类别是一个做抉择的类别dataset.setClassIndex(dataset.numAttributes() - 1);tempReader.close();} catch (Exception ee) {System.out.println("Error occurred while trying to read \'" + paraFilename+ "\' in GeneralAnn constructor.\r\n" + ee);System.exit(0);} // Of try// Step 2. 接受参数layerNumNodes = paraLayerNumNodes;// 把参数层的结点数传过来numLayers = layerNumNodes.length;// 必要时进行调整layerNumNodes[0] = dataset.numAttributes() - 1;layerNumNodes[numLayers - 1] = dataset.numClasses();//意思就是把空数组填入[3, 4, 6, 2]数据learningRate = paraLearningRate;// 学习率传参mobp = paraMobp;// 学习动量系数传参 }//Of the first constructor /*********************** 前瞻性预测* * @param paraInput* 一个实例的输入数据。* @return 输出端的数据。*********************/public abstract double[] forward(double[] paraInput);/*********************** 反向传播。* * @param paraTarget* For 3-class data, it is [0, 0, 1], [0, 1, 0] or [1, 0, 0].* *********************/public abstract void backPropagation(double[] paraTarget);/*********************** 使用数据集进行训练。*********************/public void train() {//是一个一个数据进行训练的double[] tempInput = new double[dataset.numAttributes() - 1];// 输入层+隐层double[] tempTarget = new double[dataset.numClasses()];//类别的数目,比如我们这里是二元的,那么就是2for (int i = 0; i < dataset.numInstances(); i++) {// 填装数据for (int j = 0; j < tempInput.length; j++) {tempInput[j] = dataset.instance(i).value(j);} // Of for j// 填装数据标签Arrays.fill(tempTarget, 0);//使决策值全部为零tempTarget[(int) dataset.instance(i).classValue()] = 1;//我们把这个目标训练的对象类型取整数作为数组索引,值为一。用于判断// Train with this instance.forward(tempInput);//第一次就相当于初始化。backPropagation(tempTarget);} // Of for i}// Of train/*********************** 获取与数组的最大值对应的索引。* * @return the index.*********************/public static int argmax(double[] paraArray) {int resultIndex = -1;double tempMax = -1e10;for (int i = 0; i < paraArray.length; i++) {if (tempMax < paraArray[i]) {tempMax = paraArray[i];resultIndex = i;} // Of if} // Of for ireturn resultIndex;}// Of argmax/*********************** 使用数据集进行测试。* * @return The precision.*********************/public double test() {double[] tempInput = new double[dataset.numAttributes() - 1];//输入层double tempNumCorrect = 0;double[] tempPrediction; //预测数组int tempPredictedClass = -1; //被预测的类型先置为0for (int i = 0; i < dataset.numInstances(); i++) { //一个一个数据进行训练// 填装数据for (int j = 0; j < tempInput.length; j++) {tempInput[j] = dataset.instance(i).value(j);} // Of for j// 训练这个数据tempPrediction = forward(tempInput);System.out.println("prediction: " + Arrays.toString(tempPrediction));tempPredictedClass = argmax(tempPrediction);//选择预测最大的哪个if (tempPredictedClass == (int) dataset.instance(i).classValue()) {tempNumCorrect++;} // Of if} // Of for iSystem.out.println("Correct: " + tempNumCorrect + " out of " + dataset.numInstances());return tempNumCorrect / dataset.numInstances();}// Of test}//Of class GeneralAnn
下面是子类
package machinelearning.ann;// 第二天 固定激活函数的BP神经网络
public class SimpleAnn extends GeneralAnn{/*** 在转发过程中更改的每个节点的值。 * 第一个维度代表层,第二个维度代表节点。*/public double[][] layerNodeValues;/*** 在反向传播过程中每个节点上更改的错误。* 第一个维度代表层,第二个维度代表节点。* */public double[][] layerNodeErrors;/*** 边的权重。第一个维度代表层, * 第二个代表层的节点索引, * 第三个维度代表下一层的节点索引值。*/public double[][][] edgeWeights;/*** 边权重的变化. 它的大小和edgeWeights一致.*/public double[][][] edgeWeightsDelta;/*********************** 第一个构造函数* * @param paraFilename* 文件名* @param paraLayerNumNodes* 每层的结点数目* @param paraLearningRate* 学习率* @param paraMobp* 动量系数*********************/public SimpleAnn(String paraFilename, int[] paraLayerNumNodes, double paraLearningRate,double paraMobp) {super(paraFilename, paraLayerNumNodes, paraLearningRate, paraMobp);// Step 1. 跨层初始化。layerNodeValues = new double[numLayers][];layerNodeErrors = new double[numLayers][];// 第一个维度长度是层数edgeWeights = new double[numLayers - 1][][];// 不要输入层?edgeWeightsDelta = new double[numLayers - 1][][];// Step 2. 内层初始化。for (int l = 0; l < numLayers; l++) {layerNodeValues[l] = new double[layerNumNodes[l]];//给每一层分配空间layerNodeErrors[l] = new double[layerNumNodes[l]];// 误差层和layerNodeValues一致// 减少一层,因为每条边跨越两层。if (l + 1 == numLayers) {// 到三停止break;} // of if // In layerNumNodes[l] + 1, 最后一个是为偏移量保留的,多增加了一个,偏移项不会指向自己edgeWeights[l] = new double[layerNumNodes[l] + 1][layerNumNodes[l + 1]];// 每一个元素对应8个结点edgeWeightsDelta[l] = new double[layerNumNodes[l] + 1][layerNumNodes[l + 1]];for (int j = 0; j < layerNumNodes[l] + 1; j++) {//加一是因为多了一个偏移量for (int i = 0; i < layerNumNodes[l + 1]; i++) {// 初始化权重edgeWeights[l][j][i] = random.nextDouble();//这个也太随意了。} // Of for i} // Of for j} // Of for l}// Of the constructor/*********************** 前瞻性预测。* * @param paraInput* 一个一个实例输入* @return The data at the output end.*********************/public double[] forward(double[] paraInput) {// 初始化输入层for (int i = 0; i < layerNodeValues[0].length; i++) {// 输出层在第一层,这里初始化它的数据layerNodeValues[0][i] = paraInput[i];} // Of for i// 计算每个层的节点值。double z;for (int l = 1; l < numLayers; l++) {for (int j = 0; j < layerNodeValues[l].length; j++) {// 根据偏移量初始化,偏移量总是为+1,因为edgeWeights没有包含偏移量所以要先算。z = edgeWeights[l - 1][layerNodeValues[l - 1].length][j];//此节点是所有边上的加权和。for (int i = 0; i < layerNodeValues[l - 1].length; i++) {// 对i进行循环z += edgeWeights[l - 1][i][j] * layerNodeValues[l - 1][i];// 这个边乘以权的和,edgeWeights[第几层][第几个结点][权值]} // Of for i// Sigmoid 函数激活处理// 对于其他激活功能,应更改此行。layerNodeValues[l][j] = 1 / (1 + Math.exp(-z));} // Of for j} // Of for lreturn layerNodeValues[numLayers - 1];//就会把每个结点的值算出来。}// Of forward/*********************** 反向传播和更改边权重。(BP)* * @param paraTarget* For 3-class data, it is [0, 0, 1], [0, 1, 0] or [1, 0, 0].*********************/public void backPropagation(double[] paraTarget) {// Step 1. 初始化输出层的误差int l = numLayers - 1;//反向的所以索引在输出层for (int j = 0; j < layerNodeErrors[l].length; j++) {// 求导之后layerNodeErrors[l][j] = layerNodeValues[l][j] * (1 - layerNodeValues[l][j])* (paraTarget[j] - layerNodeValues[l][j]);// 这个输出层gi 没有涉及偏移量,他没有偏移项} // Of for j 先初始化了输出层// Step 2.即使对于l(L)==0,反向传播也是如此while (l > 0) {l--;//开始减一指向倒数第一个隐层。// 层l(L),用于每个节点。for (int j = 0; j < layerNumNodes[l]; j++) {// 第l层第j个结点和后一层第i个结点的权重,double z = 0.0;// 对于下一层的每个节点。for (int i = 0; i < layerNumNodes[l + 1]; i++) {// 这个循环建立在输出层if (l > 0) {z += layerNodeErrors[l + 1][i] * edgeWeights[l][j][i]; // sigma(求和) gi*bh +1选择后一层第一次是输出层的gi,这里是算隐层所以有求和} // Of if// 权重调整edgeWeightsDelta[l][j][i] = mobp * edgeWeightsDelta[l][j][i]+ learningRate * layerNodeErrors[l + 1][i] * layerNodeValues[l][j];// 后一层的giedgeWeights[l][j][i] += edgeWeightsDelta[l][j][i];// 这个公式还不一样,v=mv+n△vif (j == layerNumNodes[l] - 1) {// 当j等于层的节点数,除去偏移项// 调整偏置零件的权值。顺带更新bedgeWeightsDelta[l][j + 1][i] = mobp * edgeWeightsDelta[l][j + 1][i]+ learningRate * layerNodeErrors[l + 1][i];// j+1表示偏执项索引edgeWeights[l][j + 1][i] += edgeWeightsDelta[l][j + 1][i];} // Of if} // Of for i 把一层的权重搞完了// 根据Sigmoid的微分记录误差。// 对于其他激活功能,应更改此行.layerNodeErrors[l][j] = layerNodeValues[l][j] * (1 - layerNodeValues[l][j]) * z;// 什么意思?->隐层公式:} // Of for j} // Of while}// Of backPropagation/*********************** Test the algorithm.*********************/public static void main(String[] args) {int[] tempLayerNodes = { 4, 8, 8, 3 };SimpleAnn tempNetwork = new SimpleAnn("D:/data/iris.arff", tempLayerNodes, 0.01,0.6);for (int round = 0; round < 5000; round++) {tempNetwork.train();} // Of for ndouble tempAccuracy = tempNetwork.test();System.out.println("The accuracy is: " + tempAccuracy);}// Of main
}// Of class SimpleAnn
这里有一个问题我们得提出来,我的理论讲的需要一个阈值。这里把阈值换成了线性函数,激活函数的自变量本应该是 输入值-阈值 。理论中我们举例也用的 y= x+b 这种形式 ,多了一个结点。实际上隐层的结点有九个了。
还有一点就是在更新b的时候,我没有在理论将,代码在这里。当然你还是要根据自己的有一个大局观才看得懂,哈哈哈。
if (j == layerNumNodes[l] - 1) {// 当j等于层的节点数,更新到了b结点的前一个。// 调整偏置零件的权值。顺带更新bedgeWeightsDelta[l][j + 1][i] = mobp * edgeWeightsDelta[l][j + 1][i]+ learningRate * layerNodeErrors[l + 1][i];// j+1表示偏执项索引edgeWeights[l][j + 1][i] += edgeWeightsDelta[l][j + 1][i];} // Of if










![[保研/考研机试] KY3 约数的个数 清华大学复试上机题 C++实现](https://img-blog.csdnimg.cn/img_convert/82d71aeda7fab7ebdbf5811783e32db0.png)