目录
引言
1. 爬虫基础知识
1.1 什么是爬虫
1.2 HTTP协议
1.2.1 HTTP请求方法
1.GET请求
1.2.2 请求头常见字段
1.2.3 响应状态码
1.3 HTML解析
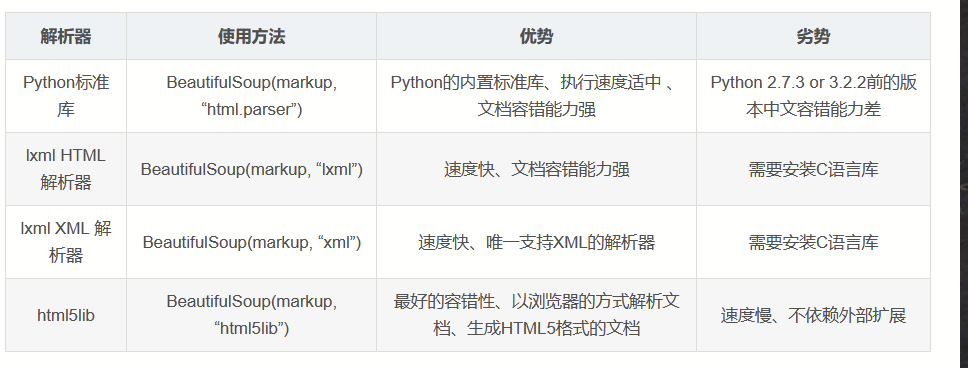
1.3.1 Beautiful Soup
解析库
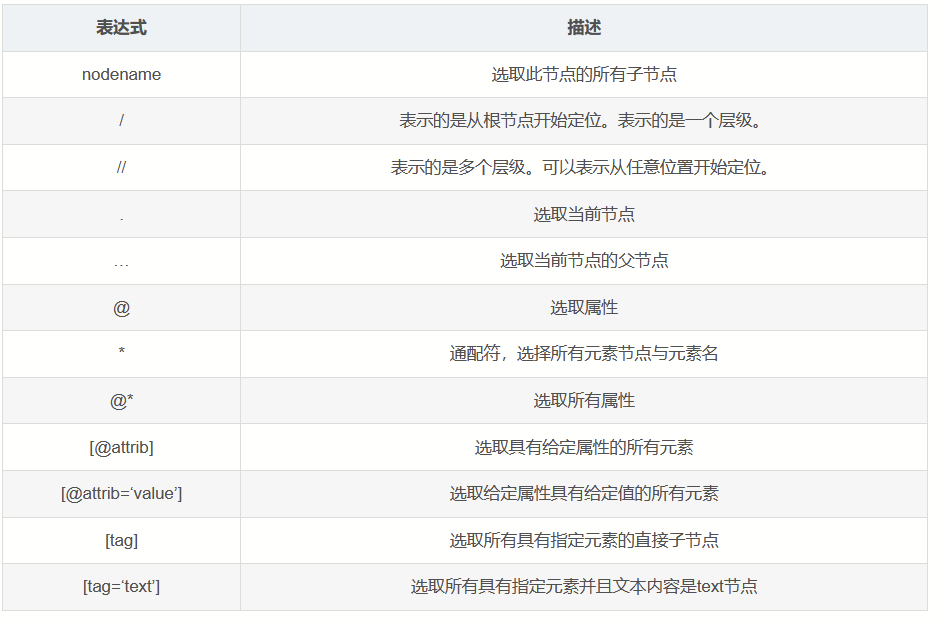
1.3.2 XPath
xpath解析原理:
xpath 表达式
2. 爬虫进阶技巧
2.1 防止被反爬虫
2.1.1 User-Agent伪装
2.1.2 IP代理
2.2 登录和验证码处理
2.2.1 登录处理
2.2.2 验证码处理
结论
引言
网络上的数据量庞大且不断增长,因此,掌握爬虫技术成为了一项重要的能力。Python作为一门功能强大且易于学习的编程语言,被广泛应用于爬虫领域。本文将介绍如何精通Python爬虫,从基础知识到高级技巧,帮助您成为一名优秀的爬虫工程师。
1. 爬虫基础知识
1.1 什么是爬虫
爬虫是一种自动化程序,它模拟人的行为,在Web上浏览并收集相关数据。爬虫通过HTTP协议获取网页内容,解析并提取感兴趣的数据。
1.2 HTTP协议
了解HTTP协议对于编写爬虫很重要。本节将介绍HTTP请求和响应的基本知识,以及常见的请求头和响应状态码。
1.2.1 HTTP请求方法
-
GET:获取资源
1.GET请求
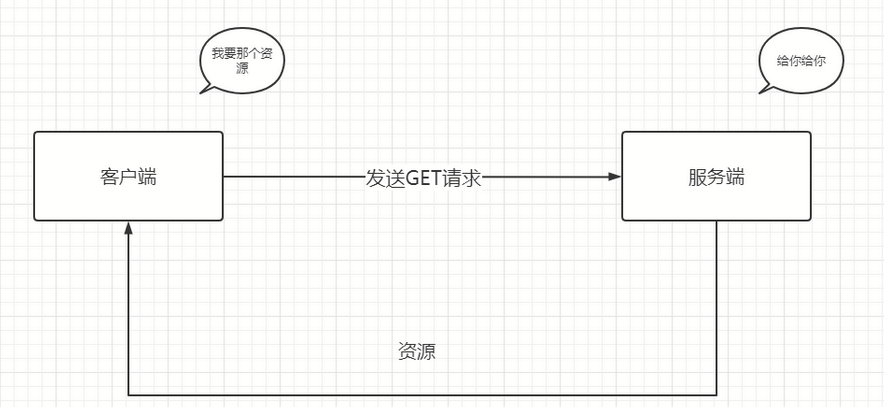
GET方法是最常见也是最简单的http请求方法,它主要用作于获取资源。也就是说我客户端请求什么,你服务器就原样给我返回什么。我请求的是文本,你就保持原样返回;我请求的是像CGI那样的程序,你就给我返回运行结果。
-
POST:提交数据

POST方法主要用来传输实体的主体.也就是说,当客户端需要向服务器传输一些东西的时候呢,这个时候就可以用POST方法了。那GET方法可以不可以呢?当然也可以,但是我们不推荐使用GET方法来对实体的主体进行传输。
-
PUT:更新资源
PUT方法主要用来传输文件,就像FTP协议的文件上传一样。但是由于Http/1.1的PUT方法不带验证机制,存在安全性问题,所以一般的网站都不用这个方法来进行文件传输。
-
DELETE:删除资源
DELETE方法主要是用来删除某个资源,是和PUT完全相反的方法。
同时该方法也不带认证机制,所以一般网站并不会对它进行开放使用。
- OPTIONS请求

OPTIONS方法用来查询:请求的指定资源都支持什么http方法。
1.2.2 请求头常见字段
-
User-Agent:标识客户端类型
-
Referer:表示请求的来源链接
-
Cookie:存储会话信息的字段
1.2.3 响应状态码
- 200 OK:表示请求成功。服务器成功处理了请求,并返回所请求的资源。
- 201 Created:表示成功创建了新的资源。通常在 POST 请求后返回。
- 202 Accepted:表示服务器已接受请求,但尚未处理完成。通常用于异步操作的情况下。
- 204 No Content:表示服务器成功处理了请求,但没有返回任何内容。一般用于删除操作或只需要确认操作是否成功而无需返回具体数据的情况下。
- 400 Bad Request:表示请求有误,服务器无法理解。通常是由于请求参数错误、格式错误等引起的。
- 401 Unauthorized:表示请求需要身份验证,但用户未提供有效的身份凭证。
- 403 Forbidden:表示服务器理解请求,但拒绝执行。常见的原因包括权限不足、资源被禁止访问等。
- 404 Not Found:表示请求的资源不存在。
- 500 Internal Server Error:表示服务器内部错误,无法完成请求。
1.3 HTML解析
在爬虫过程中,通常需要从HTML页面中提取数据。本节将介绍两种常用的HTML解析库:Beautiful Soup和XPath。
1.3.1 Beautiful Soup
Beautiful Soup是Python中常用的HTML解析库之一。它可以根据标签、类名、属性等进行检索,并提供了多种方法来提取数据。
解析库
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>示例页面</title></head><body><h1>标题</h1><p class="content">内容1</p><p class="content">内容2</p></body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
title = soup.title.text
contents = soup.findAll('p', {'class': 'content'})
print(title) # 输出:示例页面
print(contents) # 输出:[<p class="content">内容1</p>, <p class="content">内容2</p>]1.3.2 XPath
XPath是一种用于选择XML和HTML节点的语言。在Python中,可以使用lxml库进行XPath解析。
xpath解析原理:
1.实现标签的定位:实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。
xpath 表达式
from lxml import etree
html_doc = """
<html><head><title>示例页面</title></head><body><h1>标题</h1><p class="content">内容1</p><p class="content">内容2</p></body>
</html>
"""
html = etree.HTML(html_doc)
title = html.xpath('//title/text()')
contents = html.xpath('//p[@class="content"]/text()')
print(title) # 输出:['示例页面']
print(contents) # 输出:['内容1', '内容2']2. 爬虫进阶技巧
2.1 防止被反爬虫
在爬虫过程中,有些网站会采取反爬虫措施。本节将介绍一些常用的反爬虫手段及其应对策略。
2.1.1 User-Agent伪装
有些网站会根据User-Agent字段识别爬虫,因此,我们可以通过修改User-Agent字段来伪装成浏览器发送请求。
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)2.1.2 IP代理
有些网站会根据IP地址限制访问频率或者封禁某些IP地址,我们可以使用代理IP来规避这些限制。
import requests
proxies = {'http': 'http://127.0.0.1:1080','https': 'http://127.0.0.1:1080'
}
response = requests.get(url, proxies=proxies)2.2 登录和验证码处理
有些网站需要登录或者输入验证码才能访问特定页面。本节将介绍如何处理这些场景。
2.2.1 登录处理
对于需要登录的网站,我们可以使用Session对象来模拟登录和保持会话。
import requests
url = 'http://example.com/login'
login_data = {'username': 'your_username','password': 'your_password'
}
# 创建Session对象
session = requests.Session()
# 发送登录请求
session.post(url, data=login_data)
# 使用Session对象发送其他请求,保持会话
response = session.get('http://example.com/protected_page')2.2.2 验证码处理
对于包含验证码的网站,可以使用第三方库,如tesseract-OCR,来识别验证码。
import requests
from PIL import Image
import pytesseract
url = 'http://example.com/captcha.jpg'
# 下载验证码图片
response = requests.get(url)
with open('captcha.jpg', 'wb') as f:f.write(response.content)
# 使用tesseract-OCR识别验证码
image = Image.open('captcha.jpg')
captcha_text = pytesseract.image_to_string(image)结论
本文介绍了如何精通Python爬虫,从基础知识到高级技巧,涵盖了爬虫的基本原理、HTTP协议、HTML解析、防止被反爬虫、登录和验证码处理等内容。
文末送书

内容简介
《Python数据清洗》详细阐述了与Python数据清洗相关的基本解决方案,主要包括将表格数据导入Pandas中、将HTML和JSON导入Pandas中、衡量数据好坏、识别缺失值和离群值、使用可视化方法识别意外值、使用Series操作清洗和探索数据、聚合时修复混乱数据、组合DataFrame、规整和重塑数据、用户定义的函数和类等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
前言/序言
本书是一本实用的数据清洗指南。从广义上说,数据清洗被定义为准备数据进行分析所需的所有任务。它通常由在数据清洗过程中完成的任务组成,即导入数据、以诊断方式查看数据、识别异常值和意外值、估算和填充缺失值、规整数据等。本书每个秘笈都会引导读者对原始数据执行特定的数据清洗任务。
目前市面上已经有许多非常好的Pandas书籍,但是本书有自己的特色,我们将重点放在实战操作和原理解释上。
由于Pandas还相对较新,因此我们所学到的有关清洗数据的经验是受使用其他工具的经验影响的。大约在2012年,作者开始使用Python和R适应其时的工作需要,在21世纪初主要使用的是C#和T-SQL,在20世纪90年代主要使用的是SAS和Stata,在20世纪80年代主要使用的是FORTRAN和Pascal。本书的大多数读者可能都有使用各种数据清洗和分析工具的经验。
无论你喜欢使用什么工具,其重要性都比不上数据准备任务和数据属性。如果让作者撰写《SAS数据清洗秘笈》或《R数据清洗秘笈》,那么讨论的主题也几乎是一样的。本书只是采用与Python/Pandas相关的方法来解决分析师数十年来面临的相同数据清洗挑战。
在讨论如何使用Python生态系统中的工具(Pandas、NumPy、Matplotlib和SciPy等)进行处理之前,作者会在每章的开头介绍如何思考特定的数据清洗任务。在每个秘笈中,作者会介绍它对于数据发现的含义。
本书尝试将工具和目的连接起来。例如,我们阐释偏度和峰度之类的概念,这对于处理离群值是非常重要的,同时我们又介绍箱形图等可视化工具,强化读者对于偏度和峰度等概念的理解。
参与活动
1️⃣参与方式:关注、点赞、收藏,评论:人生苦短,我用python(每人最多可评论三条)
2️⃣获奖方式:程序随机抽取 3位,每位小伙伴将获得一本书
3️⃣活动时间:截止到 2023-08-19 22:00:00