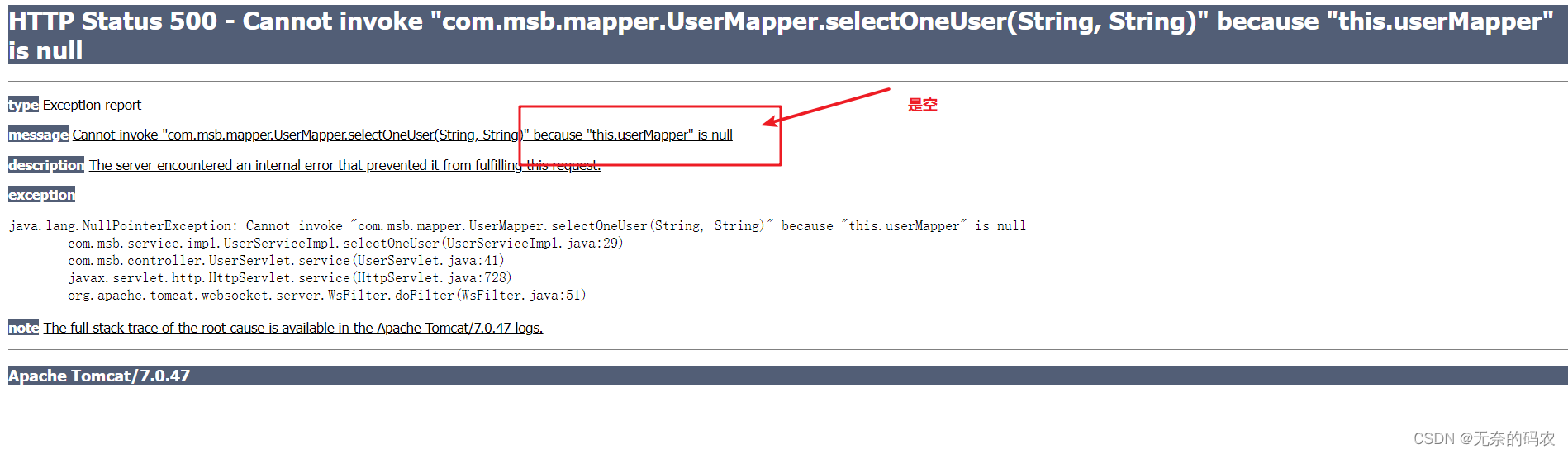
1.主流机器与应用Prometheus,skywalking监控体系分享介绍
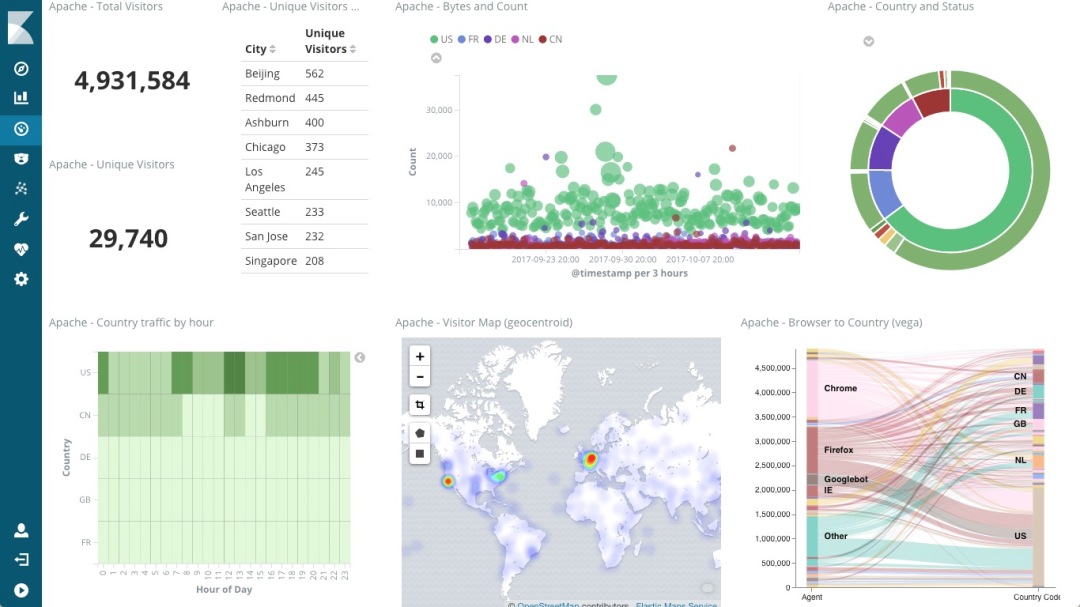
应用监控介绍
- 目前市面上开源应用的APM系统主要有CAT、Zipkin、Pinpoint、SkyWalking。
- 目前市面上机器监控软件有zabbix,Prometheus(也能监控应用,及其他中间件产品)。
- Zipkin是Twitter开源的调用链路分析工具,目前基于Spingcloud sleuth得到了广泛的应用,特点是轻量,部署简单。
Pinpoint一个韩国团队开源的产品,运用了字节码增强技术,只需要在启动时添加启动参数即可,对代码无侵入,目前支持Java和PHP语言,底层采用HBase来存储数据,探针收集的数据粒度非常细,但性能损耗大,因其出现的时间较长,完成度也很高,应用的公司较多
- Skywalking是本土开源的基于字节码注入的调用链路分析以及应用监控分析工具,特点是支持多种插件,UI功能较强,接入端无代码侵入。
CAT是由国内美团点评开源的,基于Java语言开发,目前提供Java、C/C++、Node.js、Python、Go等语言的客户端,监控数据会全量统计,国内很多公司在用,例如美团点评、携程、拼多多等,CAT跟下边要介绍的Zipkin都需要在应用程序中埋点,对代码侵入性强。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7LyoSSzs-1668243114386)(images/监控对比.png)]在这里插入图片描述



机器及中间件监控介绍
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kPtIAVYD-1668243114388)(images/zabbix-promet.png)]
- Prometheus开始成为主导及容器监控方面的标配,并且在未来可见的时间内被广泛应用。如果是刚刚要上监控系统的话,不用犹豫了,Prometheus 准没错。
- Zabbix 使用外部数据库来存储数据。Zabbix 数据库必须在安装期间创建。当前支持以下数据库:MySQL、PostgreSQL、Oracle、IBM DB2 和 SQLite
- Prometheus 将数据存储在自己的时间序列数据库 (TSDB)中。Prometheus 拥有自己的 TSDB,可以接收和处理比许多其他监控系统更多的指标。Prometheus
甚至可以使用毫秒分辨率时间戳写入数据。Prometheus 本身最多只能存储 14 天的数据,如需更长的数据存储时间,您可以配置远程存储。 - Prometheus社区生态,及对常用中间件监控组件比较多。
2.Prometheus监控
2.1架构及组件介绍

- Prometheus server组件介绍,它是prometheus的主程序,本身也是一个时序数据库,它来负责整个监控集群的数据拉取、处理、计算和存储。和zabbix采取push监控数据的方式不同,
- 1、prometheus的设计是使用pull方式由服务端主动拉取监控数据。关于push和pull两种方式的优缺点争论一直存在,这里不再过多赘述,只需知道即可。
当prometheus拉取到数据之后首先进行的操作是数据的处理:根据配置的数据格式或者标签转换/删除等操作。 - 2、数据处理完成后是根据rule中配置的规则进行计算:比如CPU使用率达到80%是一条告警规则,则prometheus会对数据进行计算看是否命中规则,命中则发送消息给alertmanager组件,否则不做操作。
- 3、完成上面的一些操作之后,prometheus会根据配置时间周期保存数据到本地或者是第三方存储中。
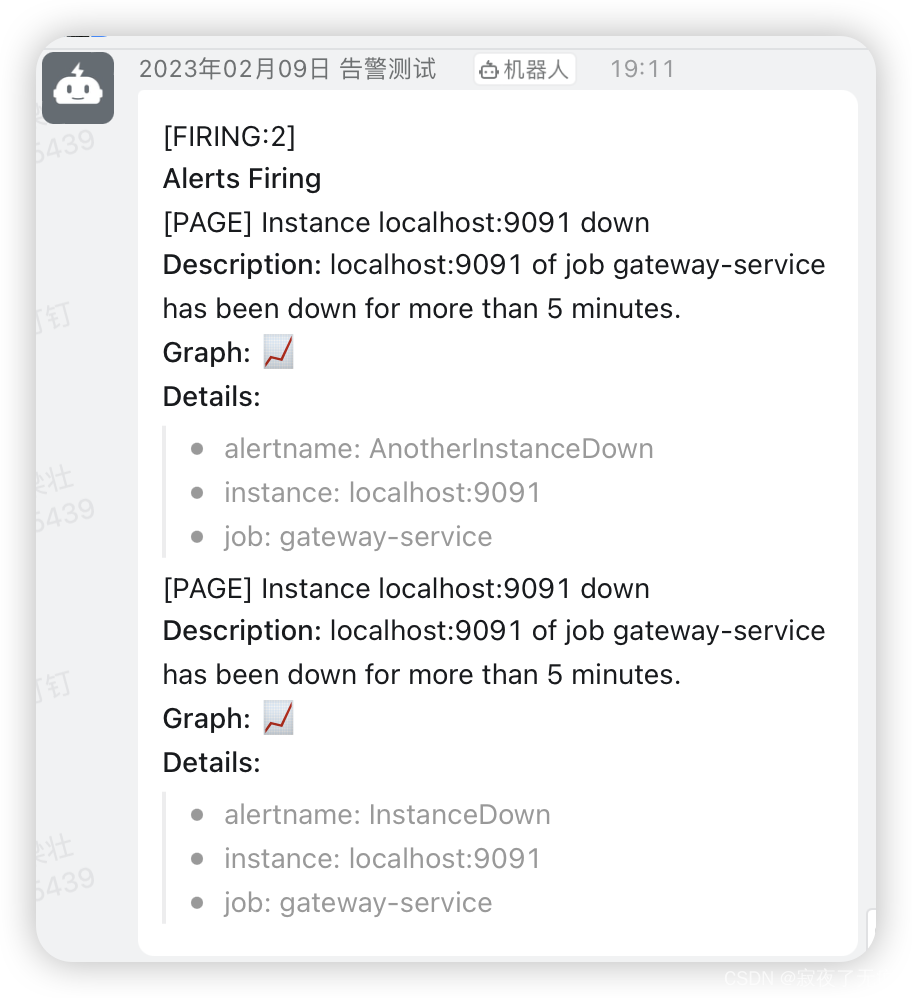
- Alertmanager 组件介绍,它是prometheus的告警组件,负责整个集群的告警发送、分组、调度、警告抑制等功能。
- 需要知道的是alertmanager本身是不做告警规则计算的,简单来说就是,alertmanager不去计算当前的监控取值是否达到我设定的阈值,上面已经提过该部分规则计算是prometheus server来计算的,
- alertmanager监听prometheus
server发来的消息,然后在结合自己的配置,比如等待周期,重复发送告警时间,路由匹配等配置项,然后把接收到的消息发送到指定的接收者。同时他还支持多种告警接收方式,常见的如邮件、企业微信、钉钉等。
- Pushgateway
组件介绍,它是prometheus的一个中间网管组件,类似于zabbix的zabbix-proxy。它主要解决的问题是一些不支持pull方式获取数据的场景,比如:自定义shell脚本来监控服务的健康状态,这个就没办法直接让prometheus来拉数据,这时就可以借助pushgateway,它是支持推送数据的,我们可以把对应的数据按照prometheus的格式推送到pushgateway,然后配置prometheus
server拉取pushgateway即可。 - 数据展示组件介绍
上图右下角的几个组件,grafana、prometheus-ui是用来图形化展示数据的组件,其中prometheus-ui是prometheus项目原生的ui界面,但是在数据展示方面不太好用,因此推荐grafana来展示你的数据,grafana支持prometheus的PromQL语法,能够和prometheus数据库交互,加上grafana强大的ui功能,我们可以很轻松的获取到很多好看的界面,同时也有很多做好的模版可以使用。 - 服务发现组件介绍
对一个监控系统来说,自动发现肯定是一个最基础的功能,试想如果没有自动发现,添加10000台主机到监控系统该是中什么体验?还好,prometheus是有该组件的,而且还很多,支持多种自动发现机制,比如基于文件、DNS、consul、zookeeper、etcd、kuberbetes等服务自动发现的方式,这些服务发现方式后面都会写到。 - exporter 简单说是采集端,通过http服务的形式保留一个 url 地址,prometheus server 通过访问该 exporter
提供的endpoint端点url,即可获取到需要采集的监控数据。该终端有mysql-exporter,linux-exporter,redis-exporter。
2.2物理机安装及演示
- node_exporter 安装
# 可以去官网下载最新版:https://prometheus.io/download/
tar -zxvf node_exporter-0.16.0.linux-amd64.tar.gz
# 后台运行node_exporter
./node_exporter &-
在浏览器输入监控端ip及端口进行访问,进入页面如下
http://182.43.165.162:9100/metrics -
prometheus 服务端安装
# 可以去官网下载最新版:https://prometheus.io/download/ 解压
tar -zxf prometheus-2.3.2.linux-amd64.tar.gz## 启动
./prometheus --config.file=./prometheus.yml &## 控制页面访问
http://182.43.165.162:9090/targets
- 演示界面
- 演示sql 查询
- rate(jvm_buffer_memory_used_bytes {instance="182.43.165.162:18087"}[5m])[10m:1m]rate(jvm_buffer_memory_used_bytes {job="my-cpn-test"}[5m])[10m:1m]
./prometheus.yml配置
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["182.43.165.162:9090"]- job_name: 'my-server' #新增的配置static_configs:- targets: ['182.43.165.162:9100']- job_name: 'pushgateway' # 配置pushgatewaystatic_configs:- targets: ['182.43.165.162:9091']# labels:# instance:pushgateway- job_name: 'my-cpn-test' # 配置metrics_path: "/bmp-cpn-service/actuator/prometheus"static_configs:- targets: ['gateway.test.vevor.net']- job_name: 'my-test-local' #metrics_path: "/actuator/prometheus"static_configs:- targets: ['182.43.165.162:18087']
sql简单查询
jvm_memory_used_bytes{application="learn_app_test",area="heap",id="PS Old Gen",}
2.3spring-boot应用监控安装
<!-- spring boot health健康检查包 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!-- prometheus监控 --><dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId><version>1.3.16</version></dependency>- 开启actuator配置
management:endpoints:web: #开启web监控端点exposure:include: '*' #自定义端点的启用和关闭enabled-by-default: trueserver:port: 18087 #自定义端口号。正常是首位为1后面加上服务端口号,具体和运维商量metrics:tags: #对外暴露tagapplication: ${spring.application.name}
-
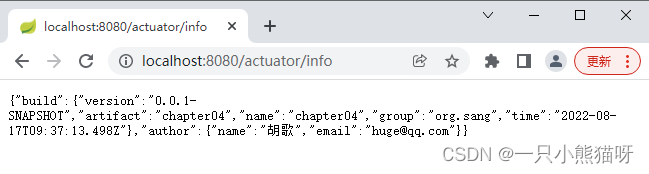
访问地址
http://182.43.165.162:18087/actuator/prometheus -
在prometheus.yml配置
-
指标学习
| 类型 | 描述 | 例如 |
|---|---|---|
| Counter | counter 是一个累积计数的指标,仅支持增加或者重置为0(只增不减 )。例如:可以用来统计服务请求的数量,任务完成数量,或者出错的数量。 | |
| Gauge | gauge是一个纯数值型的能够经常进行增加或者减少的指标。例如用来做温度的计数,内存的使用,同样也可以用来使用计算服务请求数量。 | |
| Histogram | histogram 在一段时间内进行采样,并能够对指定区间以及总数进行统计. | |
| Summary | summary与histogram类似,用于表示一段时间内的采样数据,但它直接存储了分位数,而不是通过区间来计算。 |

1. 实际演示机器的几个指标
1. node_load1
2. node_memory_memFree_bytes
3. node_filesystem_free_bytes
2.4 UI-Grafana


- 演示
2.5 扩展支持
- Pushgateway 是一种中介服务,它允许您从无法抓取的作业中推送指标。有关详细信息。【演示】
- 第三方mysql的支持,mysqld_exporter服务配置数据库的账号来采集mysql自带各种指标。
- redis监控redis_exporter
- Third-party exporters
https://prometheus.io/docs/instrumenting/exporters/