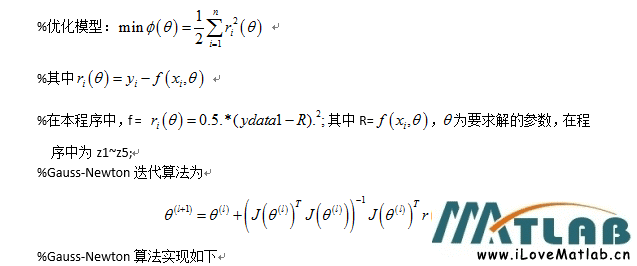Quantization Algorithms
量化算法
注意:
对于任何需要量化感知训练的以下方法,请参阅这里,了解如何使用Distiller的机制调用它。
基于范围的线性量化(Range-Based Linear Quantization)
让我们在此分解使用的术语:
- 线性(Linear): 表示通过乘以数字常数(比例因子)来量化浮点值。
- 基于范围(Range-Based): 意味着为了计算比例因子,我们查看张量值的实际范围。 在最原始的实现中,我们使用张量的实际最小/最大值。或者,我们使用一些基于张量范围/分布的推导来得出更窄的最小/最大范围,以便去除可能的异常值。这与此处描述的其他方法形成对比,我们可以将其称为基于截断的(clipping-based),因为它们在张量采用截断函数。
非对称(Asymmetric)与对称(Symmetric)
在这种方法中,我们可以使用两种模式 - 非对称和对称。
非对称模式

在非对称模式下,我们将浮点范围中的最小值/最大值映射到整数范围的最小值/最大值。除了比例因子之外,这通过使用零点(也称为量化偏差,或偏移)来完成。
让我们用 x f x_f xf表示原始浮点张量,用 x q x_q xq表示量化张量,用 q x q_x qx表示比例因子,用 z p x zp_x zpx表示零点,以及用 n n n表示量化的比特。然后,我们得到:
x q = r o u n d ( ( x f − m i n x f ) 2 n − 1 m a x x f − m i n x f ⎵ q x ) = r o u n d ( q x x f − m i n x f q x ) ⎵ z p x = r o u n d ( q x x f − z p x ) x_q = round\left ((x_f - min_{x_f})\underbrace{\frac{2^n - 1}{max_{x_f} - min_{x_f}}}_{q_x} \right) = round(q_x x_f - \underbrace{min_{x_f}q_x)}_{zp_x} = round(q_x x_f - zp_x)\ xq=round⎝⎜⎜⎛(xf−minxf)qx maxxf−minxf2n−1⎠⎟⎟⎞=round(qxxf−zpx minxfqx)=round(qxxf−zpx)
我们实际上使用 z p x = r o u n d ( m i n x f q x ) zp_x = round(min_{x_f}q_x) zpx=round(minxfqx)。这意味着零可以通过量化范围中的整数精确表示。例如,对于具有零填充的层(zero-padding),这很重要。通过四舍五入零点,我们有效地“微调”浮动范围中的最小值/最大值,以获得零的精确量化。
请注意,在上面的推导中,我们使用无符号整数来表示量化范围。也就是说, x q ∈ [ 0 , 2 n − 1 ] x_q \in [0,2 ^ n-1] xq∈[0,2n−1]。如果需要,可以使用有符号整数(可能由于硬件考虑因素。这可以通过减去 2 n − 1 2 ^ {n-1} 2n−1来实现。
让我们看看卷积或全连接层如何在非对称模式下量化(我们分别用 x , y , w x,y,w x,y,w和 b b b表示输入,输出,权重和偏置):
y f = ∑ x f w f + b f = ∑ x q + z p x q x w q + z p w q w + b q + z p b q b = y_f = \sum{x_f w_f} + b_f = \sum{\frac{x_q + zp_x}{q_x} \frac{w_q + zp_w}{q_w}} + \frac{b_q + zp_b}{q_b} = yf=∑xfwf+bf=∑qxxq+zpxqwwq+zpw+qbbq+zpb=
= 1 q x q w ( ∑ ( x q + z p x ) ( w q + z p w ) + q x q w q b ( b q + z p b ) ) = \frac{1}{q_x q_w} \left( \sum { (x_q + zp_x) (w_q + zp_w) + \frac{q_x q_w}{q_b}(b_q + zp_b) } \right) =qxqw1(∑(xq+zpx)(wq+zpw)+qbqxqw(bq+zpb))
因此有:
y q = r o u n d ( q y y f ) = r o u n d ( q y q x q w ( ∑ ( x q + z p x ) ( w q + z p w ) + q x q w q b ( b q + z p b ) ) ) y_q = round(q_y y_f) = round\left(\frac{q_y}{q_x q_w} \left( \sum { (x_q+zp_x) (w_q+zp_w) + \frac{q_x q_w}{q_b}(b_q+zp_b) } \right) \right) yq=round(qyyf)=round(qxqwqy(∑(xq+zpx)(wq+zpw)+qbqxqw(bq+zpb)))
注意:
- 可以看到,必须重新调整偏置以匹配求和的比例。
- 在适当的全整数HW(宽高)通道中,我们希望我们的主要累积项简单地表示为 ∑ x q w q \sum {x_q w_q} ∑xqwq。为了实现这一点,我们需要进一步发展上面得出的表达式。有关详细信息,请参阅gemmlowp。
对称模式

在对称模式中,我们选择最小/最大值之间的最大绝对值,而不是将浮点范围的精确最小值/最大值映射到量化范围。另外,我们不使用零点。因此,我们有效量化的浮点范围相对于零是对称的,量化范围也是如此。
用同样的符号,我们得到:
x q = r o u n d ( x f 2 n − 1 − 1 max ∣ x f ∣ ⎵ q x ) = r o u n d ( q x x f ) x_q = round\left (x_f \underbrace{\frac{2^{n-1} - 1}{\max|x_f|}}_{q_x} \right) = round(q_x x_f) xq=round⎝⎜⎜⎛xfqx max∣xf∣2n−1−1⎠⎟⎟⎞=round(qxxf)
卷积或全连接层如何在对称模式下量化:
y f = ∑ x f w f + b f = ∑ x q q x w q q w + b q q b = 1 q x q w ( ∑ x q w q + q x q w q b b q ) y_f = \sum{x_f w_f} + b_f = \sum{\frac{x_q}{q_x} \frac{w_q}{q_w}} + \frac{b_q}{q_b} = \frac{1}{q_x q_w} \left( \sum { x_q w_q + \frac{q_x q_w}{q_b}b_q } \right) yf=∑xfwf+bf=∑qxxqqwwq+qbbq=qxqw1(∑xqwq+qbqxqwbq)
因此:
y q = r o u n d ( q y y f ) = r o u n d ( q y q x q w ( ∑ x q w q + q x q w q b b q ) ) y_q = round(q_y y_f) = round\left(\frac{q_y}{q_x q_w} \left( \sum { x_q w_q + \frac{q_x q_w}{q_b}b_q } \right) \right) yq=round(qyyf)=round(qxqwqy(∑xqwq+qbqxqwbq))
模式对比
这两种模式之间的主要权衡是简单性与量化范围的利用。
- 当使用非对称量化时,充分利用量化范围。这是因为我们精确地将浮点范围中的最小值/最大值映射到量化范围的最小值/最大值。使用对称模式,如果浮动范围偏向一侧,则可能导致量化范围,其中显着的动态范围专用于我们将永远看不到的值。最极端的例子是在ReLU之后,整个张量是正的。在对称模式下量化它意味着我们实际上失去了1位。
- 另一方面,如果我们查看上面的卷积/全连接层的偏差,我们可以看到对称模式的实际实现要简单得多。在非对称模式下,零点需要宽高中的附加逻辑。在延迟和/或功率方面,这种额外逻辑的成本当然取决于具体的实现。
其他特点
- 删除异常值: 如这里所讨论的,在某些情况下,激活的浮动范围包含异常值。在这些异常值上花费动态范围会损害我们准确表达我们实际关注的值的能力。

目前,Distiller支持在训练后量化期间通过平均来截断激活。即对于每批数据(batch),而不是计算全局最小/最大值,而是批次中每个样品的最小/最大值的平均值。 - 比例因子范围: 对于权重张量,Distiller支持每通道量化(每个输出通道)。
在Distiller中的实现
训练后
对于训练后量化,目前使用此方法支持卷积和全连接。
- 它们是通过利用量化和去量化操作包装现有PyTorch层来实现的。也就是说,计算是在浮点张量上完成的,但值本身仅限于整数值。在
RangeLinearQuantParamLayerWrapper类中实现。 - 所有其他层不受影响,并使用其原始FP32实现执行。
- 要使用此方法将现有模型自动转换为量化模型,请使用
PostTrainLinearQuantizer类。 有关如何执行此操作的示例,请参阅compress_classifier.py。此示例提供命令行参数以调用训练后量化。详阅这里。 - 对于权重和偏置,在量化设置(“离线”)处确定一次比例因子和零点,并且对于激活,在运行时(“在线”)动态地确定比例因子和零点。计算出的量化参数作为缓冲区存储在模块中,因此在保存模型检查点时会自动序列化。
- 由于这是训练后量化,因此使用位数<8的情况可能会导致精确度降低。
Quantization-Aware训练
要在训练中应用基于范围的线性量化,请使用QuantAwareTrainRangeLinearQuantizer类。它将权重量化应用于卷积和全连接模块。 对于激活量化,它将在ReLU之后插入实例FakeLinearQuantization模块。 该模块遵循Benoit et al., 2018中描述的方法,并使用指数移动平均值来跟踪激活范围。
与post-training类似,计算出的量化参数(比例因子,零点,跟踪激活范围)作为缓冲区存储在各自的模块中,因此在创建检查点时会保存它们。
注意,尚不支持从量化感知训练模型到训练后量化模型的转换。这种转换将使用在训练期间跟踪的激活范围,因此将不需要额外的离线或在线计算量化参数。
DoReFa
(方法提出在 DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients)
在这个方法中,我们首先定义量化函数 q u a n t i z e k quantize_k quantizek,输入实数值 a f ∈ [ 0 , 1 ] a_f \in [0, 1] af∈[0,1]并且输出离散值 a q ∈ { 0 2 k − 1 , 1 2 k − 1 , . . . , 2 k − 1 2 k − 1 } a_q \in \left\{ \frac{0}{2^k-1}, \frac{1}{2^k-1}, ... , \frac{2^k-1}{2^k-1} \right\} aq∈{2k−10,2k−11,...,2k−12k−1},其中 k k k 是量化比特数。
a q = q u a n t i z e k ( a f ) = 1 2 k − 1 r o u n d ( ( 2 k − 1 ) a f ) a_q = quantize_k(a_f) = \frac{1}{2^k-1} round \left( \left(2^k - 1 \right) a_f \right) aq=quantizek(af)=2k−11round((2k−1)af)
激活值被截断为 [ 0 , 1 ] [0, 1] [0,1]的范围并遵循下式量化:
x q = q u a n t i z e k ( x f ) x_q = quantize_k(x_f) xq=quantizek(xf)
对于权重,我们定义以下函数 f f f,它接受无界实值输入并在 [ 0 , 1 ] [0,1] [0,1]中输出实数值:
f ( w ) = t a n h ( w ) 2 m a x ( ∣ t a n h ( w ) ∣ ) + 1 2 f(w) = \frac{tanh(w)}{2 max(|tanh(w)|)} + \frac{1}{2} f(w)=2max(∣tanh(w)∣)tanh(w)+21
现在我们可以使用 q u a n t i z e k quantize_k quantizek来获得量化的权重值,如下所示:
w q = 2 q u a n t i z e k ( f ( w f ) ) − 1 w_q = 2 quantize_k \left( f(w_f) \right) - 1 wq=2quantizek(f(wf))−1
该方法需要用量化感知训练训练模型,如这里所讨论的。 使用DorefaQuantizer类将现有模型转换为使用DoReFa进行量化训练的模型。
注意:
- 本文提出的梯度量化尚不支持。
- 本文定义了二进制权重的特殊处理,但Distiller尚不支持。
PACT
(方法提出在 PACT: Parameterized Clipping Activation for Quantized Neural Networks)
此方法类似于DoReFa,但激活函数的截断上界 α \alpha α是学习的参数而不是直接设置为1。请注意,根据论文的建议, α \alpha α是每层共享的。
该方法需要用量化感知训练训练模型,如这里所讨论的。 使用PACTQuantizer类将现有模型转换为使用PACT进行量化训练的模型。
WRPN
(方法提出在 WRPN: Wide Reduced-Precision Networks)
在这种方法中,激活被剪切为 [ 0 , 1 ] [0,1] [0,1]并按照如下方式量化( k k k是用于量化的比特数):
x q = 1 2 k − 1 r o u n d ( ( 2 k − 1 ) x f ) x_q = \frac{1}{2^k-1} round \left( \left(2^k - 1 \right) x_f \right) xq=2k−11round((2k−1)xf)
权重被剪切为 [ − 1 , 1 ] [ -1,1] [−1,1]并量化如下:
w q = 1 2 k − 1 − 1 r o u n d ( ( 2 k − 1 − 1 ) w f ) w_q = \frac{1}{2^{k-1}-1} round \left( \left(2^{k-1} - 1 \right)w_f \right) wq=2k−1−11round((2k−1−1)wf)
注意, k − 1 k-1 k−1位用于量化权重,留下一位用于符号。
该方法需要用量化感知训练训练模型,如这里所讨论的。 使用WRPNQuantizer类将现有模型转换为使用WRPN进行量化训练的模型。
注意:
- 该论文提出扩大层作为降低精度损失的手段。 目前,这不是作为
WRPNQuantizer的一部分实现的。 要试验这一点,请修改模型实现以获得更宽的层。 - 本文定义了二进制权重的特殊处理,但Distiller尚不支持。